
Claude Code内でOpen AIのオープンウェイトモデルであるGPT-OSSを使って、コーディングワークフローを強化したいと思いませんか?きっと気に入るはずです!2025年8月にリリースされたGPT-OSS(20Bまたは120Bのバリアント)は、コーディングと推論のための強力なツールであり、Claude Codeの洗練されたCLIインターフェースと組み合わせて、無料で、または低コストでセットアップできます。この対話形式のガイドでは、Hugging Face、OpenRouter、またはLiteLLMを使用してGPT-OSSをClaude Codeと統合する3つの方法をご紹介します。さあ、AIコーディングの相棒を稼働させましょう!
最大限の生産性で開発チームが協力できる統合されたオールインワンプラットフォームをお探しですか?
Apidogは、お客様のあらゆる要求に応え、Postmanをはるかに手頃な価格で置き換えます!
GPT-OSSとは?Claude Codeで使う理由とは?
GPT-OSSはOpen AIのオープンウェイトモデルファミリーであり、20Bおよび120Bのバリアントは、コーディング、推論、エージェントタスクにおいて優れたパフォーマンスを提供します。128KトークンのコンテキストウィンドウとApache 2.0ライセンスにより、柔軟性と制御を求める開発者に最適です。AnthropicのCLIツール(バージョン0.5.3以降)であるClaude Codeは、その対話型コーディング機能により、開発者のお気に入りです。Claude CodeをOpenAI互換API経由でGPT-OSSにルーティングすることで、Anthropicのサブスクリプション費用なしで、Claudeの使い慣れたインターフェースを楽しみながら、GPT-OSSのオープンソースのパワーを活用できます。実現する準備はできましたか?セットアップオプションを見ていきましょう!

Claude CodeでGPT-OSSを使用するための前提条件
始める前に、以下が揃っていることを確認してください。
- Claude Code ≥ 0.5.3:
claude --versionで確認してください。pip install claude-codeでインストールするか、pip install --upgrade claude-codeで更新してください。 - Hugging Faceアカウント: huggingface.coでサインアップし、読み書きトークンを作成してください(Settings > Access Tokens)。
- OpenRouter APIキー: オプション(パスBの場合)。openrouter.aiで取得してください。
- Python 3.10+とDocker: ローカルセットアップまたはLiteLLM(パスC)の場合。
- 基本的なCLIの知識: 環境変数とターミナルコマンドに慣れていると役立ちます。
方法1: Hugging FaceでGPT-OSSをセルフホストする
完全に制御したいですか?Hugging FaceのInference EndpointsでGPT-OSSをホストし、プライベートでスケーラブルなセットアップを実現しましょう。方法は以下の通りです。
ステップ1: モデルを入手する
- Hugging FaceのGPT-OSSリポジトリにアクセスします(openai/gpt-oss-20bまたはopenai/gpt-oss-120b)。
- Apache 2.0ライセンスに同意してモデルにアクセスします。
- または、コーディングに特化したモデルとしてQwen3-Coder-480B-A35B-Instruct(Qwen/Qwen3-Coder-480B-A35B-Instruct)を試してください(より軽量なハードウェアの場合はGGUFバージョンを使用してください)。
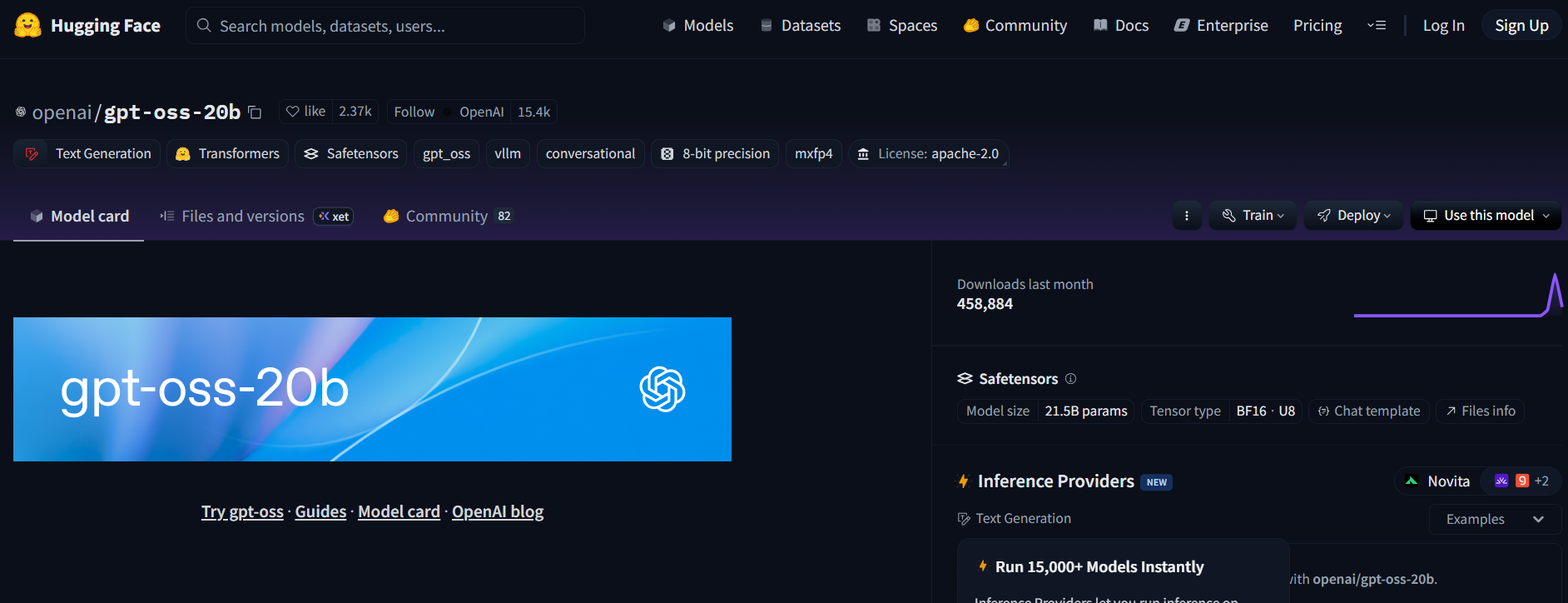
ステップ2: テキスト生成推論エンドポイントをデプロイする
- モデルページで、Deploy > Inference Endpointをクリックします。
- Text Generation Inference (TGI)テンプレート(v1.4.0以降)を選択します。
- Enable OpenAI compatibilityにチェックを入れるか、詳細設定で
--enable-openaiを追加してOpenAI互換性を有効にします。 - ハードウェアを選択します: 20BにはA10GまたはCPU、120BにはA100。エンドポイントを作成します。
ステップ3: 認証情報を収集する
- エンドポイントのステータスがRunningになったら、以下をコピーします。
- ENDPOINT_URL:
https://<your-endpoint>.us-east-1.aws.endpoints.huggingface.cloudのようになります。 - HF_API_TOKEN: Settings > Access TokensにあるHugging Faceトークン。
2. モデルID(例: gpt-oss-20bまたはgpt-oss-120b)をメモします。
ステップ4: Claude Codeを設定する
- ターミナルで環境変数を設定します。
export ANTHROPIC_BASE_URL="https://<your-endpoint>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # or gpt-oss-120b
<your-endpoint>とhf_xxxxxxxxxxxxxxxxxをあなたの値に置き換えてください。
2. セットアップをテストします。
claude --model gpt-oss-20b
Claude Codeは、TGIの/v1/chat/completions APIを介して応答をストリーミングし、OpenAIのスキーマを模倣して、あなたのGPT-OSSエンドポイントにルーティングします。
ステップ5: コストとスケーリングに関する注意点
- Hugging Faceのコスト: 推論エンドポイントは自動スケーリングされるため、クレジットの使いすぎを防ぐために使用状況を監視してください。A10Gは1時間あたり約0.60ドル、A100は1時間あたり約3ドルかかります。
- ローカルオプション: クラウドコストをゼロにするには、DockerでTGIをローカルで実行します。
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
次に、ANTHROPIC_BASE_URL="http://localhost:8080"を設定します。
方法2: OpenRouter経由でGPT-OSSをプロキシする
DevOpsは不要です!最小限のセットアップでGPT-OSSにアクセスするには、OpenRouterを使用します。高速で、課金も処理してくれます。
ステップ1: 登録してモデルを選択する
- openrouter.aiでサインアップし、KeysセクションからAPIキーをコピーします。
- モデルのスラッグを選択します。
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(Qwenのコーダーモデル用)
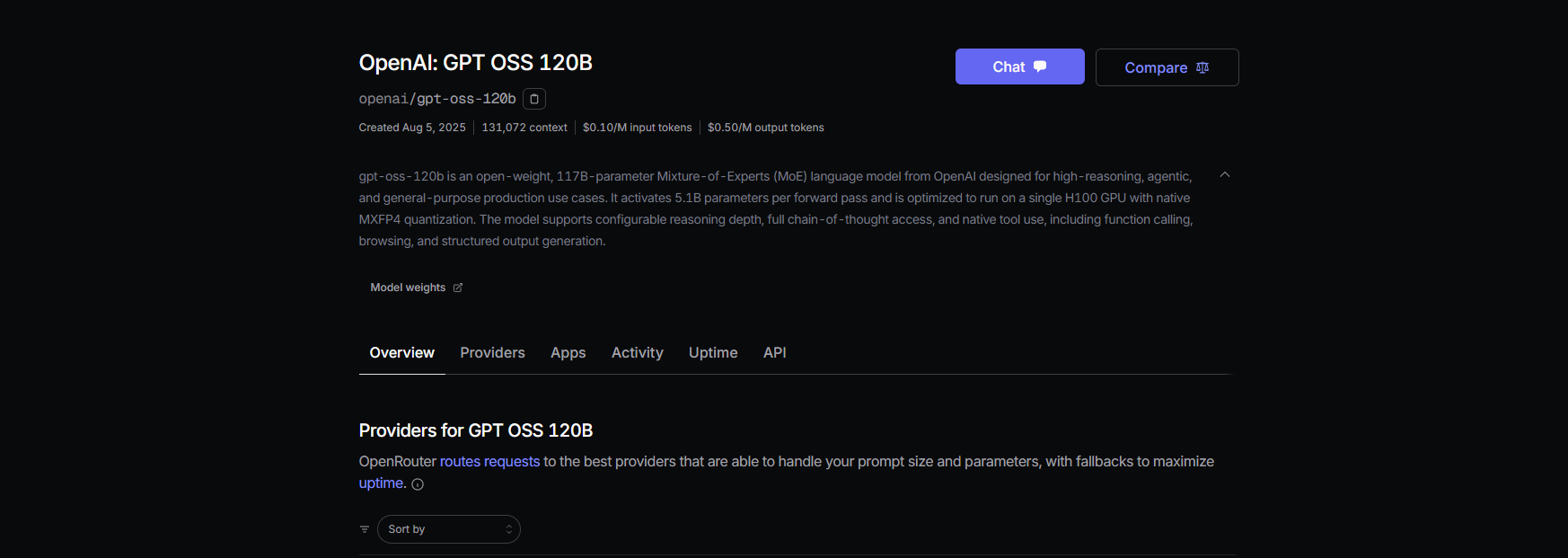
ステップ2: Claude Codeを設定する
- 環境変数を設定します。
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
or_xxxxxxxxxをあなたのOpenRouter APIキーに置き換えてください。
2. テストします。
claude --model openai/gpt-oss-20b
Claude Codeは、OpenRouterの統合APIを介してGPT-OSSに接続し、ストリーミングとフォールバックをサポートします。
ステップ3: コストに関する注意点
- OpenRouterの料金: GPT-OSS-120Bの場合、入力トークン100万あたり約0.50ドル、出力トークン100万あたり約2.00ドルで、GPT-4のようなプロプライエタリモデル(100万あたり約20.00ドル)よりも大幅に安価です。
- 請求: OpenRouterが使用量を管理するため、使用した分だけ支払います。
方法3: LiteLLMで混合モデルフリートを使用する
GPT-OSS、Qwen、Anthropicモデルを1つのワークフローで切り替えたいですか?LiteLLMは、モデルをシームレスにホットスワップするためのプロキシとして機能します。
ステップ1: LiteLLMをインストールして設定する
- LiteLLMをインストールします。
pip install litellm
2. 設定ファイル(litellm.yaml)を作成します。
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # OpenRouter key
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
or_xxxxxxxxxをあなたのOpenRouterキーに置き換えてください。
3. プロキシを開始します。
litellm --config litellm.yaml
ステップ2: Claude CodeをLiteLLMに向ける
- 環境変数を設定します。
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. テストします。
claude --model gpt-oss-20b
LiteLLMは、コストログと信頼性のためのシンプルシャッフルルーティングを使用して、OpenRouter経由でGPT-OSSにリクエストをルーティングします。
ステップ3: 注意点
- レイテンシールーティングを避ける: Anthropicモデルとの問題を避けるため、LiteLLMでシンプルシャッフルモードを使用してください。
- コスト追跡: LiteLLMは透明性のために使用状況をログに記録します。

Claude CodeでGPT-OSSをテストする
GPT-OSSが動作していることを確認しましょう!Claude Codeを開いて、以下のコマンドを試してください。
コード生成:
claude --model gpt-oss-20b "Write a Python REST API with Flask"
次のような応答が期待できます。
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "Hello from GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
コードベース分析:
claude --model gpt-oss-20b "Summarize src/server.js"
GPT-OSSは、128Kのコンテキストウィンドウを活用してJavaScriptファイルを分析し、要約を返します。
デバッグ:
claude --model gpt-oss-20b "Debug this buggy Python code: [paste code]"
87.3%のHumanEval合格率を持つGPT-OSSは、問題を正確に特定し修正するはずです。
トラブルシューティングのヒント
- /v1/chat/completionsで404エラー? TGI(パスA)で
--enable-openaiが有効になっているか、OpenRouterのモデルの可用性(パスB)を確認してください。 - 空の応答?
ANTHROPIC_MODELがスラッグ(例:gpt-oss-20b)と一致していることを確認してください。 - モデル交換後に400エラー? LiteLLM(パスC)でシンプルシャッフルルーティングを使用してください。
- 最初のトークンが遅い? スケールゼロにした後、小さなプロンプトでHugging Faceのエンドポイントをウォームアップしてください。
- Claude Codeがクラッシュする? 0.5.3以降に更新し、環境変数が正しく設定されていることを確認してください。
なぜClaude CodeでGPT-OSSを使用するのか?
GPT-OSSとClaude Codeを組み合わせることは、開発者にとって夢のようなことです。以下のメリットが得られます。
- コスト削減: OpenRouterの入力トークン100万あたり0.50ドルはプロプライエタリモデルよりも優れており、ローカルTGIセットアップはハードウェア費用を除けば無料です。
- オープンソースの力: GPT-OSSのApache 2.0ライセンスにより、プライベートでカスタマイズまたはデプロイできます。
- シームレスなワークフロー: Claude CodeのCLIはコーディング仲間とチャットしているような感覚で、GPT-OSSは94.2%のMMLUと96.6%のAIMEスコアで重い処理をこなします。
- 柔軟性: LiteLLMまたはOpenRouterを使用して、GPT-OSS、Qwen、Anthropicモデルを切り替えることができます。
ユーザーはGPT-OSSのコーディング能力を絶賛しており、「複数ファイルプロジェクト向けの予算に優しい野獣」と呼んでいます。セルフホストするにしても、OpenRouterを介してプロキシするにしても、このセットアップはコストを低く抑え、生産性を高く保ちます。
結論
これで、Claude CodeでGPT-OSSを使いこなす準備が整いました!Hugging Faceでセルフホストするにしても、OpenRouter経由でプロキシするにしても、LiteLLMでモデルを切り替えるにしても、強力で費用対効果の高いコーディング環境が手に入ります。REST APIの生成からコードのデバッグまで、GPT-OSSは期待に応え、Claude Codeはそれを楽々と感じさせます。ぜひ試して、お気に入りのプロンプトをコメントで共有し、AIコーディングについて語り合いましょう!
最大限の生産性で開発チームが協力できる統合されたオールインワンプラットフォームをお探しですか?
Apidogは、お客様のあらゆる要求に応え、Postmanをはるかに手頃な価格で置き換えます!


