
開発者は、インテリジェントなアプリケーションを構築するために、常に強力なツールを求めています。OpenAIは、高度な推論機能を提供するオープンウェイト言語モデルのシリーズであるGPT-OSSのリリースにより、このニーズに応えます。gpt-oss-120bやgpt-oss-20bを含むこれらのモデルは、さまざまな環境でのカスタマイズとデプロイを可能にします。ユーザーはホスティングプラットフォームが提供するAPIを通じてこれらにアクセスし、プロジェクトへのシームレスな統合を実現できます。
GPT-OSS APIの使用を開始するには、開発者はOpenRouterやTogether AIなどのプロバイダーを通じてアクセスを取得します。これらのプラットフォームはモデルをホストし、OpenAIのAPI形式と互換性のある標準エンドポイントを公開しています。この互換性により、プロプライエタリモデルからの移行が簡素化されます。
GPT-OSSとは?主な機能と能力
OpenAIはGPT-OSSを、Mixture-of-Experts (MoE) モデルのファミリーとして設計しています。このアーキテクチャは、トークンごとにパラメータのサブセットのみをアクティブ化し、効率を向上させます。例えば、gpt-oss-120bは合計1,170億のパラメータを持ちますが、トークンあたり51億しかアクティブ化しません。同様に、gpt-oss-20bは210億のパラメータを使用し、36億がアクティブです。
これらのモデルは、Transformerベースの構造を採用しており、密なアテンション層と疎なアテンション層を交互に配置しています。最大128,000トークンの長文コンテキストを処理するために、Rotary Positional Embeddings (RoPE) を組み込んでいます。開発者は、文書要約など、広範な入力を必要とするアプリケーションでこの恩恵を受けます。
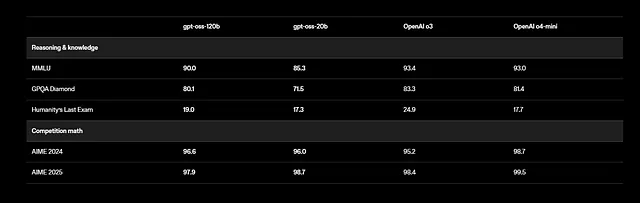
さらに、GPT-OSSは多言語タスクをサポートしていますが、トレーニングは英語に焦点を当て、STEMおよびコーディングデータに重点を置いています。ベンチマークでは目覚ましい結果が示されており、gpt-oss-120bはMMLU(Massive Multitask Language Understanding)で94.2%、AIME(American Invitational Mathematics Examination)で96.6%を記録しています。健康関連のクエリや競技数学において、o4-miniのようなモデルを上回っています。
開発者は、モデルがウェブ検索やコード実行などの外部関数を呼び出すツール呼び出し機能を利用します。このエージェント機能により、自律システムの構築が可能になります。例えば、モデルは単一の応答内で複数のツール呼び出しを連鎖させ、問題を段階的に解決します。
さらに、これらのモデルはApache 2.0ライセンスに準拠しており、自由に改変およびデプロイできます。OpenAIはHugging Faceで重みを提供しており、メモリ使用量を削減するためにMXFP4形式で量子化されています。ユーザーはこれらをローカルまたはクラウドプロバイダー経由で実行できます。
ただし、安全上の考慮事項が適用されます。OpenAIは、誤情報などのリスクをテストするために、Preparedness Frameworkに基づいて評価を実施しています。開発者は、出力のフィルタリングなどの安全策を実装して問題を軽減します。
要するに、GPT-OSSはパワーとアクセシビリティを兼ね備えています。そのオープンな性質はコミュニティの貢献を促進し、急速な改善につながります。次に、これらのモデルへのAPIアクセスを提供するプロバイダーを特定します。
GPT-OSS APIアクセスプロバイダーの選択
いくつかのプラットフォームがGPT-OSSモデルをホストし、APIエンドポイントを提供しています。開発者は、速度、コスト、スケーラビリティなどのニーズに基づいて選択します。例えば、OpenRouterはgpt-oss-120bを競争力のある価格と簡単な統合で提供しています。
Together AIは、エンタープライズ対応のデプロイメントを重視した別の選択肢を提供します。OpenAIクライアントと互換性のある/v1/chat/completionsエンドポイントを通じてモデルをサポートします。開発者は、メッセージ、max_tokens、およびtemperatureを指定するJSONペイロードを送信します。
さらに、Fireworks AIとCerebrasは高速な推論を提供します。Cerebrasは1秒あたり最大3,000トークンを達成し、リアルタイムアプリケーションに最適です。価格は異なります。OpenRouterは入力トークン100万あたり約0.15ドルを請求しますが、Together AIはボリュームディスカウント付きで同様の料金を提供します。
開発者はプライバシーのためにセルフホスティングも検討します。vLLMやOllamaのようなツールを使用すると、GPT-OSSをローカルサーバーで実行し、APIを公開できます。例えば、vLLMはOpenAI互換のルートでモデルを提供し、単一のコマンドで起動できます。
ただし、クラウドプロバイダーはスケーリングを簡素化します。AWS、Azure、Vercelは、OpenAIとの提携を通じてGPT-OSSを統合しています。これらのオプションは、ロードバランシングと自動スケーリングを自動的に処理します。
さらに、レイテンシを評価します。gpt-oss-20bは要件の低いエッジデバイスに適していますが、gpt-oss-120bはNVIDIA H100のようなGPUを必要とします。プロバイダーはハードウェアを最適化し、一貫したパフォーマンスを保証します。
要するに、適切なプロバイダーはプロジェクトの目標と一致します。選択したら、APIクレデンシャルを取得するに進みます。
APIアクセスと環境設定の取得
開発者は、プロバイダーのサイトに登録することから始めます。OpenRouterの場合、openrouter.aiにアクセスし、アカウントを作成して「Keys」セクションに移動します。参照用に名前を付けて新しいAPIキーを生成し、安全にコピーします。
次に、クライアントライブラリをインストールします。Pythonでは、pipを使用してopenaiを追加します: pip install openai。ベースURLとキーでクライアントを設定します。例:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
この設定により、gpt-ossモデルへのリクエストを送信できます。
さらに、Together AIの場合、彼らのSDKを使用します: pip install together。以下で初期化します:
import together
together.api_key = "your_together_api_key"
モデルをリストしたり、簡単なクエリを送信したりして接続をテストします。
ただし、セルフホスティングの場合はハードウェアを確認してください。Hugging Faceから重みをダウンロードします: huggingface-cli download openai/gpt-oss-120b。次に、vLLMを使用して提供します: vllm serve openai/gpt-oss-120b。
さらに、セキュリティのために環境変数を設定します。.envファイルにキーを保存し、dotenvライブラリでロードします。
問題が発生した場合は、プロバイダーのドキュメントでレート制限や認証エラーを確認してください。この準備により、スムーズなAPIインタラクションが保証されます。
GPT-OSSへの最初のAPI呼び出しを行う
開発者は、チャット補完エンドポイントを使用してリクエストを作成します。ペイロードで「openai/gpt-oss-120b」などのモデルを指定します。
基本的な呼び出しの場合、メッセージを辞書のリストとして準備します。それぞれにロール(システム、ユーザー、アシスタント)とコンテンツが含まれます。
Pythonの例を以下に示します:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
これにより、その概念を技術的に説明する応答が生成されます。
さらに、制御のためにパラメータを調整します。Temperatureは創造性に影響を与えます。値が低いほど決定論的な出力が生成されます。Top_pはトークンサンプリングを制限し、presence_penaltyは繰り返しの発生を抑制します。
次に、ツール呼び出しを組み込みます。リクエストでツールを定義します:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
モデルはツール呼び出しで応答し、開発者はそれを実行してフィードバックします。
ただし、応答は慎重に処理してください。コンテンツ、finish_reason、およびトークン数などの使用状況統計についてJSONを解析します。
さらに、思考の連鎖のために、「Think step by step.」とプロンプトします。システムメッセージで推論の労力を設定します: 「reasoning_effort: medium」。
より高速なテストのためにgpt-oss-20bを試してください: 呼び出しでモデル名を置き換えます。
高度なシナリオでは、リアルタイム出力のためにstream=Trueを使用して応答をストリーミングします。
これらの手順は基礎的なスキルを構築します。次に、Apidogのようなテストツールを統合します。
効率的なGPT-OSS APIテストのためのApidogの統合
開発者は、APIインタラクションのテストとデバッグにApidogを利用しています。このツールは、gpt-ossエンドポイントにリクエストを送信するためのユーザーフレンドリーなインターフェースを提供します。
まず、Apidogをウェブサイトからインストールします。新しいプロジェクトを作成し、https://openrouter.ai/api/v1/chat/completionsのようなAPIエンドポイントを追加します。
次に、ヘッダーを設定します: BearerトークンでAuthorizationを追加し、Content-Typeをapplication/jsonとします。
さらに、リクエストボディを構築します。ApidogのJSONエディタを使用して、モデル、メッセージ、パラメータを入力します。例えば、コード生成のためのgpt-oss呼び出しをテストします。
Apidogは応答を視覚化し、エラーや成功を強調表示します。プロバイダー間でAPIキーを切り替えるための環境変数をサポートしています。
ただし、テストを整理するためにコレクションを活用します。推論やツール使用などのタスクごとにGPT-OSSクエリをグループ化し、バッチで実行します。
さらに、ApidogはリクエストからPythonやcURLなどの言語でコードスニペットを生成し、開発を加速します。
共同作業のために、プロジェクトをチームと共有します。これにより、gpt-oss統合の一貫したテストが保証されます。
実際には、Apidogを使用してトークンの使用状況を監視し、プロンプトを最適化してコストを削減します。
全体として、ApidogはGPT-OSS APIを使用する際の生産性を向上させます。
高度な使用法:ファインチューニングとデプロイメント
開発者は、特定のドメイン向けにGPT-OSSをファインチューニングします。Hugging Faceのtransformersライブラリを使用して重みをロードし、カスタムデータセットでトレーニングします。
例えば、プロンプトと補完のペアを含むJSONL形式でデータを準備します。GitHubリポジトリからファインチューニングスクリプトを実行します。
さらに、APIサービスのためにvLLM経由で調整済みモデルをデプロイします。これは、動的バッチ処理などの機能により、本番環境の負荷をサポートします。
次に、マルチモーダル拡張を探ります。テキスト中心ですが、ハイブリッドアプリのためにビジョンモデルと統合します。
ただし、ファインチューニング中の過学習に注意してください。検証セットと早期停止を使用します。
さらに、クラスターでの分散推論でスケールします。AWSのようなプロバイダーはマネージドオプションを提供しています。
エージェント設定では、GPT-OSSを外部APIと連鎖させ、自動化された調査などのワークフローを実現します。
これらの技術は、基本的な呼び出しを超えて機能を拡張します。
ベストプラクティス、制限事項、トラブルシューティング
開発者は、最適な結果を得るためにベストプラクティスに従います。明確なプロンプトを作成し、少数ショットの例を使用し、出力に基づいて反復します。
さらに、レート制限を尊重してください。スロットリングを避けるためにプロバイダーのダッシュボードを確認してください。
ただし、制限事項を認識してください。GPT-OSSは幻覚を起こす可能性があるため、重要な応答は検証してください。リアルタイムの知識更新はありません。
さらに、APIキーを保護し、コスト管理のために使用状況をログに記録します。
エラーコードを確認してトラブルシューティングします。401は無効な認証、429はレート制限に達したことを意味します。
要約すると、信頼性の高いパフォーマンスのためにこれらのガイドラインに従ってください。
結論:GPT-OSS APIでプロジェクトを強化する
開発者は、GPT-OSSを効果的に統合するためのツールを手に入れました。セットアップから高度な機能まで、このガイドは成功のためにあなたを支援します。gpt-ossとApidogで実験し、洗練させ、革新して、影響力のあるAIソリューションを作成してください。