
2025年のAI開発に注目してきた方なら、GPT-5と競合し(時にはそれを上回る)ように設計された次世代マルチモーダルAIモデル、Google Gemini 3に関する膨大な話題を聞いたことがあるでしょう。ソフトウェアエンジニア、スタートアップの創業者、AI愛好家、あるいは単にGemini 3が何ができるのか知りたい人であろうと、Google Gemini 3 APIの操作方法を学ぶことで、はるかに賢くダイナミックなアプリケーションを構築する道が開かれます。
しかし正直に言って、Googleのドキュメントは、始めたばかりの人にとっては少し難解かもしれません。そこで、このガイドでは、すべてを分かりやすく、親しみやすく、初心者にも優しい方法で解説していきます。
button
さあ、Googleの最も高度なAIモデルの力を解き放ちましょう!
Google Gemini 3とは?
Google Gemini 3は、GoogleのマルチモーダルAIファミリーの最新モデルです。以前のモデルとは異なり、Gemini 3は以下の用途に最適化されています。
- 推論と問題解決
- マルチモーダルな入力/出力(テキスト、画像、音声、動画の埋め込み)
- ツール利用とエージェントワークフロー
- 低遅延エンドポイントによる高速推論
- タスクに応じた動的なモデル切り替え
しかし、最大の注目点はこれです。
Gemini 3は2つの主要な「思考モード」を導入しています。
thinking_levelパラメータは、モデルが応答を生成する前の内部推論プロセスの最大深度を制御します。Gemini 3は、これらのレベルを厳密なトークン保証ではなく、思考のための相対的な許容量として扱います。thinking_levelが指定されていない場合、Gemini 3 Proはデフォルトでhighになります。
- 高/動的思考(High/Dynamic Thinking):推論深度を最大化します。モデルが最初のトークンに到達するまでにかかる時間が大幅に長くなる可能性がありますが、出力はより慎重に推論されたものになります。
- 低思考(Low Thinking):遅延とコストを最小限に抑えます。単純な指示の実行、チャット、高スループットのアプリケーションに最適です。
多くの初心者はまだこのことを知りませんが、正しいモードを選択することで、出力品質が劇的に向上し、コストを抑えることができます。
APIを使ってモードを選択する方法については、後ほど詳しく説明します。
UIツールではなくGemini 3 APIを使用する理由
もちろん、Google AI Studio内でGeminiを使用することもできます。しかし、以下のことを行いたい場合は、
- アプリケーションを構築する
- タスクを自動化する
- モデルをワークフローに統合する
- チャットボットを作成する
- データを処理する
- エージェントをトレーニングする
- マルチモーダルなタスクを実行する
Gemini 3 APIが必要です。
このガイドではREST APIに焦点を当てています。その理由は、
- 初心者にとってより簡単であること
- クライアントライブラリが不要であること
- ApidogやPostmanで素早くテストできること
- どのバックエンド環境でも動作すること
Gemini 3 APIの仕組み(簡単な概要)
Geminiは高度な機能を備えていますが、API自体は非常にシンプルです。
あなたはPOSTリクエストを…に送信します
<https://generativelanguage.googleapis.com/v1beta/models/{MODEL_ID}:generateContent?key=YOUR_API_KEY>
あなたは以下のようなJSONを含めます。
- テキストプロンプト
- メッセージのリスト(オプション)
- モデル設定
- 安全設定
あなたは以下を受け取ります。
- モデルの出力テキスト
- 推論構造(高/動的思考の場合)
- 引用
- メタデータ
- マルチモーダルオブジェクト(該当する場合)
この構造を理解すれば、他のすべてが簡単になります。
はじめに:Gemini APIの最初のステップ
ステップ1:APIキーを取得する
APIキーは、Googleに「はい、私はGeminiを使用できます」と伝える特別なパスワードだと考えてください。取得方法は次のとおりです。
- Google AI Studioにアクセスします
- Googleアカウントでサインインします
- 左サイドバーの「Create API Key」をクリックします
- キーに名前を付けて作成します
- このキーをコピーして安全な場所に保存してください!もう一度見ることはできません。
重要:APIキーを共有したり、公開コードリポジトリにコミットしたりしないでください。パスワードのように扱ってください。
ステップ2:アプローチを選択する
Geminiと対話するには、主に2つの方法があります。
- REST API:普遍的なアプローチ。HTTPリクエストを作成できるあらゆるプログラミング言語で動作します。この方法に焦点を当てます。
- 公式SDK:Googleは、HTTPの詳細を処理するPython、Node.js、その他の言語用の便利なライブラリを提供しています。
基本的な部分に焦点を当てているため、裏側で何が起こっているかを理解するのに役立つREST APIアプローチを使用します。これはどこでも機能します。
Geminiの思考モードを理解する
Geminiの最も強力な機能の一つは、異なる「思考モード」で動作する能力です。これは単なるマーケティングではなく、モデルがリクエストを処理する方法を根本的に変えます。
低思考(スピードの悪魔)
いつ使用するか:単純なタスク、素早い応答、速度とコストを最適化したい場合。
- 速度:非常に高速な応答
- コスト:より手頃な価格
- ユースケース:簡単なQ&A、テキスト分類、基本的な要約、分かりやすい翻訳
例:
gemini-3-flash
gemini-3-mini
低思考モードは、知識豊富な友人と簡単な会話をして、すぐに答えをもらうようなものだと考えてください。
高/動的思考(思慮深いアナリスト)
いつ使用するか:複雑な推論、多段階の問題、深い分析を必要とするタスクの場合。
- 速度:遅い(応答する前により「考える」ため)
- コスト:より高価
- ユースケース:複雑な数学の問題、論理的推論、コードのデバッグ、創造的なライティング、戦略的計画
高/動的思考は、あらゆる角度を検討してから、よく推論された答えを提供する専門家と相談するようなものです。
例:
gemini-3-pro
gemini-3-pro-thinking
これらのモデルは、より深い推論、より長い注意ウィンドウ、より優れた計画機能を提供します。
素晴らしいのは、特定のニーズに応じて高/動的思考と低思考の両方のモデルを選択できることです。ほとんどの単純なアプリケーションでは、低思考で十分です。より深い推論が必要な場合は、高思考に切り替えます。
経験則として:
| タスクの種類 | モデルモード |
|---|---|
| 調査 | 高/動的思考 |
| 数学/論理 | 高/動的思考 |
| コード生成 | 高/動的思考 |
| 顧客チャット | 低思考 |
| 基本的なテキスト生成 | 低思考 |
| UIアシスタント | 低思考 |
| リアルタイムアプリ | 低思考 |
REST APIで各モデルを選択する方法をご紹介します。
最初のGemini 3 REST API呼び出しを構築する
最も簡単な例から始めましょう。
エンドポイント
POST <https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>
リクエストボディの例(JSON)
{
"contents": [
{ "role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}
サンプルCurlコマンド
curl -X POST \\
-H "Content-Type: application/json" \\
-d '{
"contents": [
{
"role": "user",
"parts": [{ "text": "Explain how airplanes fly." }]
}
]
}' \\
"<https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro:generateContent?key=YOUR_API_KEY>"
高/動的思考モードの使用
推論モードを有効にするには、gemini-3-pro-thinkingのように、それをサポートするモデルを使用する必要があります。
REST APIの例
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Find the race condition in this multi-threaded C++ snippet: [code here]"}]
}]
}'高/動的思考モードを使用する場合、多くの場合以下を受け取ります。
- 思考の連鎖構造(要求しない限り非表示)
- より一貫性のある回答
- 応答時間の遅延
- より高価な推論コスト
このモードは、長文の推論やコードの計画など、本当に重要な場合にのみ使用することをお勧めします。
低思考モードの使用
低思考モデルは速度に最適化されており、以下の用途に最適です。
- オートコンプリート
- 短いメッセージ
- UI応答
- 小型アシスタント
- チャットボットのサイド機能
「Flash」を使用したREST APIの例
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "How does AI work?"}]
}],
"generationConfig": {
thinkingConfig: {
thinkingLevel: "low"
}
}
}'低思考モデルはコストがはるかに安く、ほぼ瞬時に応答を返します。
マルチモーダル入力(画像、PDF、音声、動画)の処理
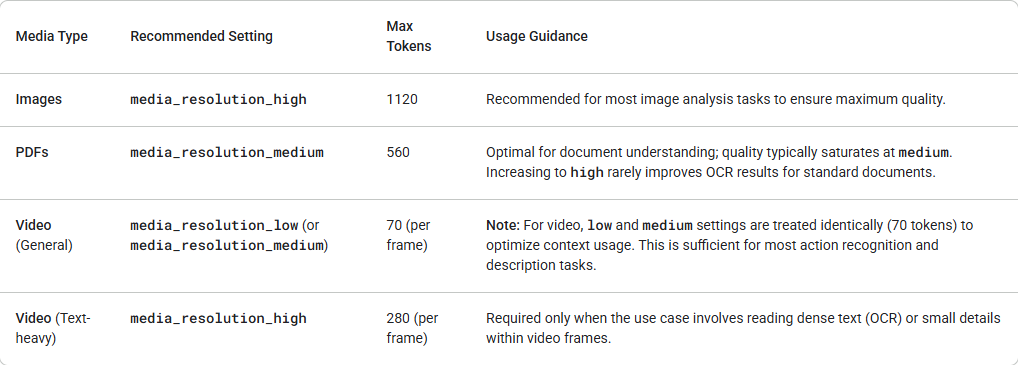
Gemini 3は、media_resolutionパラメータを介して、マルチモーダルな視覚処理をきめ細かく制御できるようになりました。解像度が高いほど、モデルは細かいテキストを読んだり、小さな詳細を識別したりする能力が向上しますが、トークン使用量と遅延が増加します。media_resolutionパラメータは、入力画像または動画フレームごとに割り当てられる最大トークン数を決定します。
各メディアパートまたは全体(generation_config経由)で、解像度をmedia_resolution_low、media_resolution_medium、またはmedia_resolution_highに設定できるようになりました。指定しない場合、モデルはメディアタイプに基づいて最適なデフォルトを使用します。
Gemini 3は、以下のマルチモーダル埋め込みをサポートしています。
- 画像
- 音声
- 動画フレーム
- ドキュメント
画像をアップロードする例(base64):
curl "https://generativelanguage.googleapis.com/v1alpha/models/gemini-3-pro-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts": [
{ "text": "What is in this image?" },
{
"inlineData": {
"mimeType": "image/jpeg",
"data": "..."
},
"mediaResolution": {
"level": "media_resolution_high"
}
}
]
}]
}'Apidogを使ったテストとデバッグ
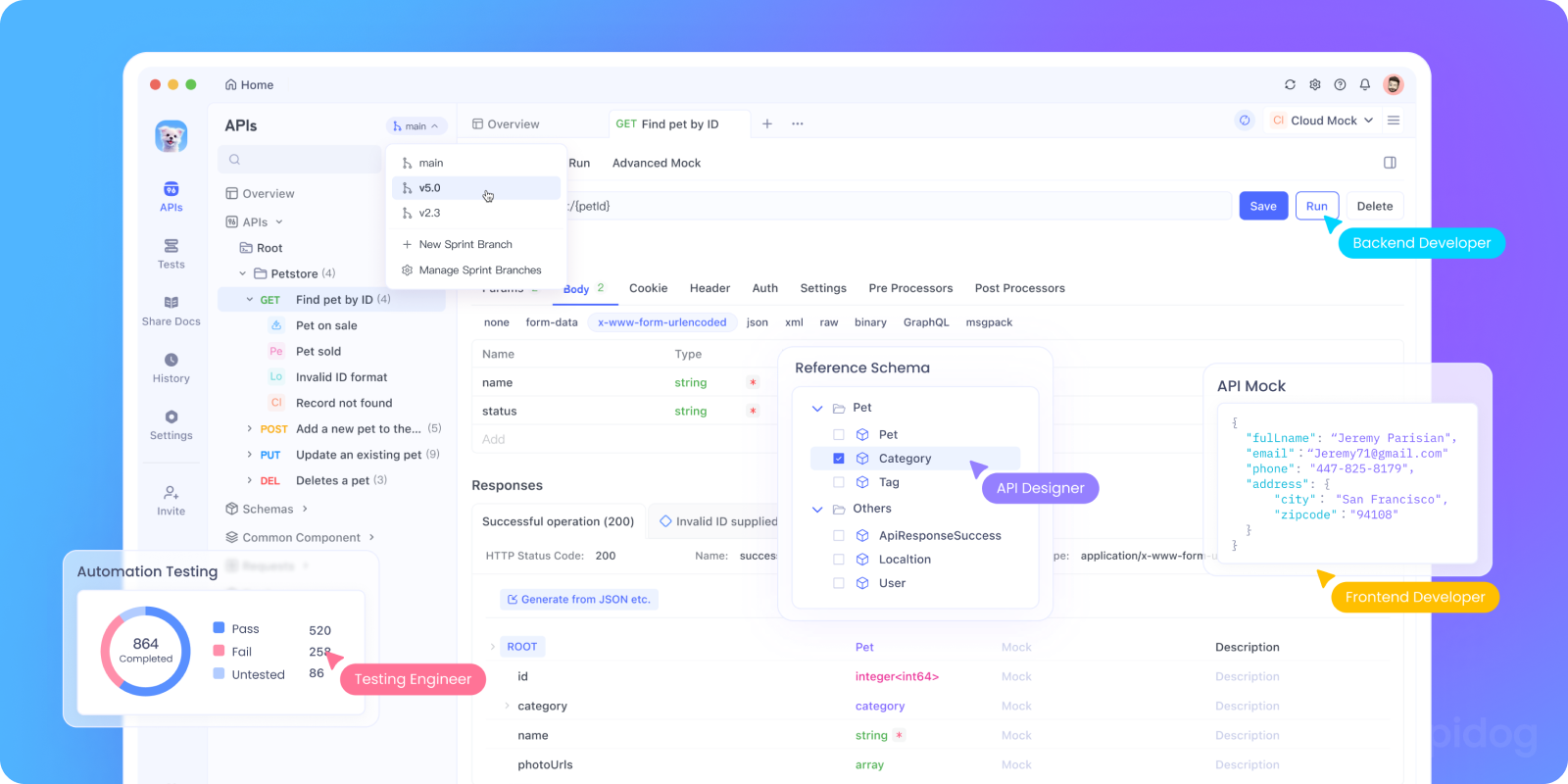
curlコマンドは迅速なテストには優れていますが、本格的なアプリケーションを開発する際には煩雑になります。ここでApidogが輝きを放ちます。
Apidogを使用すると、以下のことができます。
- API設定を保存:GeminiのエンドポイントとAPIキーを一度設定すれば、すべてのテストで再利用できます。
- リクエストテンプレートを作成:異なるタイプのプロンプト(会話の開始、分析リクエスト、創造的なライティング)をテンプレートとして保存します。
- 思考モードを並行してテスト:低思考モードと高思考モードを簡単に切り替えて、応答とパフォーマンスを比較できます。
- 会話履歴を管理:Apidogの環境変数を使用して、複数のリクエスト間で会話コンテキストを維持します。
- テストを自動化:Geminiの統合が正しく機能していることを確認するテストスイートを作成します。
button
ApidogでGeminiリクエストを設定する方法は次のとおりです。
- 新しいPOSTリクエストを以下に作成します:
https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent?key={{api_key}} - 実際のAPIキーで環境変数
api_keyを設定します - ボディにJSONを使用します:
{
"contents": [{
"parts": [{
"text": "{{prompt}}"
}]
}],
"generationConfig": {
"temperature": 0.7,
"maxOutputTokens": 800
}
}
4. Geminiに尋ねたい内容で別の環境変数promptを設定します
このアプローチにより、実験がはるかに高速かつ整理されます。
Gemini APIのベストプラクティス
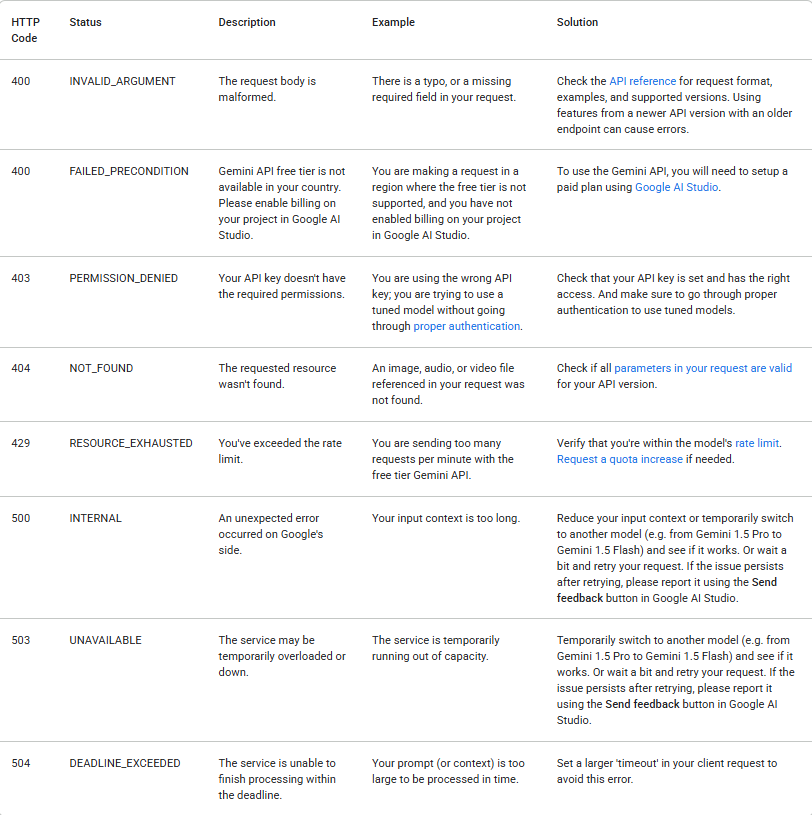
1. エラーを適切に処理する
API呼び出しはさまざまな理由で失敗することがあります。常に応答ステータスを確認し、エラーを適切に処理してください。以下の表は、遭遇する可能性のある一般的なバックエンドエラーコードと、その原因およびトラブルシューティングの手順をまとめたものです。
2. コストを管理する
Gemini APIの使用量は課金され、料金がかかります(無料枠の制限を超えた場合)。以下のヒントを念頭に置いてください。
- 実験には無料枠から始める
- 単純なタスクには可能な限り低思考モードを使用する
- 妥当な
maxOutputTokensの制限を設定する - Google AI Studioで利用状況を監視する
トークンはzのような単一の文字、またはcatのような単語全体であることがあります。長い単語は複数のトークンに分割されます。モデルが使用するすべてのトークンのセットをボキャブラリーと呼び、テキストをトークンに分割するプロセスをトークン化と呼びます。
課金が有効な場合、Gemini APIへの呼び出しのコストは、入力トークンと出力トークンの数によって部分的に決定されるため、トークン数を把握する方法を知っておくと役立ちます。
3. より良いプロンプトを作成する
出力の品質は、入力に大きく依存します。プロンプトエンジニアリングのヒントをいくつかご紹介します。
代わりに:「犬について書いてください」
試してみてください:「保護犬を飼うメリットについて、潜在的なペットオーナーに友好的で励ますようなトーンで書かれた200語の教育的なブログ記事を書いてください。」
代わりに:「このコードを修正してください」
試してみてください:「このPython関数は階乗を計算するはずですが、入力5に対して間違った結果を返します。何が問題なのか説明し、修正されたコードを提供してください。」

4. 適切なモデルを選択する
Googleは、それぞれ異なる強みを持ついくつかのGeminiモデルを提供しています。モデルパラメータが以下の値内にあることを確認してください。
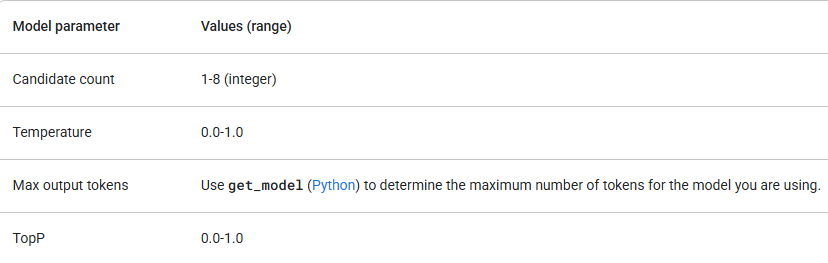
gemini-1.5-flashから始め、より高度な推論機能が必要な場合にのみアップグレードしてください。パラメータ値の確認に加えて、正しいAPIバージョン(例:/v1または/v1beta)と、必要な機能をサポートするモデルを使用していることを確認してください。たとえば、機能がベータ版リリースの場合、/v1beta APIバージョンでのみ利用可能です。
結論:AIの旅が始まる
これで、Google Gemini APIを使って構築を始めるために必要なすべてが揃いました。APIキーの取得方法、基本的なリクエストの作成方法、異なる思考モードの理解、さらにはいくつかの高度な例も見てきました。
AI APIを扱うことは反復的なプロセスであることを忘れないでください。練習を重ねることで、プロンプトの作成や適切な設定の選択が上手になるでしょう。恐れずに実験してください。それが、構築できるものの可能性を最大限に引き出す方法です。
最も重要な次のステップは、実験を始めることです。このガイドの例を参考に、変更を加えたり、壊してみたり、何が起こるか見てみましょう。学ぶ最善の方法は実践することです。
初心者の方には、REST APIテストツールとしてApidogの使用を強くお勧めします。それは以下の点で役立ちます。
- リクエストのデバッグ
- 環境変数の保存
- コレクションの実行
- モデル出力の迅速な比較
- チームメイトとのAPIテストケースの共有
そして無料なので、デメリットは一切ありません。
button