
知能アプリケーションを構築する開発者は、速度や精度を損なうことなく多様なデータタイプを処理できるモデルをますます求めています。GLM-4.6Vはこのニーズに正面から応えます。Z.aiは、このシリーズをオープンソースのマルチモーダル大規模言語モデルとしてリリースし、テキスト、画像、ビデオ、ファイルをシームレスなインタラクションに融合させます。このAPIは、ドキュメント分析であろうとビジュアル検索エージェントであろうと、これらの機能をプロジェクトに直接統合することを可能にします。
GLM-4.6Vのアーキテクチャ、アクセス方法、料金を検証することで、ベンチマークにおいて競合他社をいかに凌駕しているかをご覧いただけます。さらに、Apidogのようなツールとの統合ヒントは、より迅速なデプロイに役立ちます。まずは、モデルのコア設計から始めましょう。
GLM-4.6Vの理解:アーキテクチャとコア機能
Z.aiはGLM-4.6Vを開発し、マルチモーダル入力をネイティブに処理し、構造化されたテキスト応答を出力します。このモデルシリーズには、高性能タスク向けのフラッグシップモデルGLM-4.6V(106Bパラメータ)と、効率的なローカルデプロイメント向けのGLM-4.6V-Flash(9Bパラメータ)の2つのバリアントが含まれています。どちらも128Kトークンのコンテキストウィンドウをサポートしており、最大150ページの膨大なドキュメントや1時間にも及ぶビデオを一度で分析できます。

その核となるGLM-4.6Vは、長文コンテキストプロトコルに合わせたビジュアルエンコーダを搭載しています。このアライメントにより、モデルは入力全体で詳細な情報を保持します。例えば、テキストと画像が混在するシーケンスを処理し、写真内のオブジェクト座標など特定の視覚要素に基づいて応答を生成します。ネイティブ関数呼び出しが特徴的で、開発者は画像パラメータを使用してツールを直接呼び出し、モデルは視覚的なフィードバックループを解釈します。
さらに、強化学習はツール呼び出しを洗練させます。モデルは、スクリーンショットで検索ツールを照会し、結果について推論するといったアクションを連鎖的に実行することを学習します。これにより、認識から意思決定までのエンドツーエンドのワークフローが実現します。その結果、アプリケーションは脆い後処理なしに自律性を獲得します。

実際には、これらの機能は実世界のデータを堅牢に処理することにつながります。このモデルはリッチテキストの作成に優れており、レポートやインフォグラフィック用に画像とテキストが混在する出力を生成します。また、拡張モデルコンテキストプロトコル(MCP)もサポートしており、スケーラブルな処理のためにURLベースのマルチモーダル入力を可能にします。
ベンチマークとパフォーマンス:GLM-4.6Vと競合製品の比較
定量データはGLM-4.6Vの優位性を裏付けています。MMBenchでは、マルチモーダルQAで82.5%を記録し、LLaVA-1.6を4ポイント上回りました。MathVistaでは、アラインされたエンコーダのおかげで、視覚方程式で68%の精度を示しています。
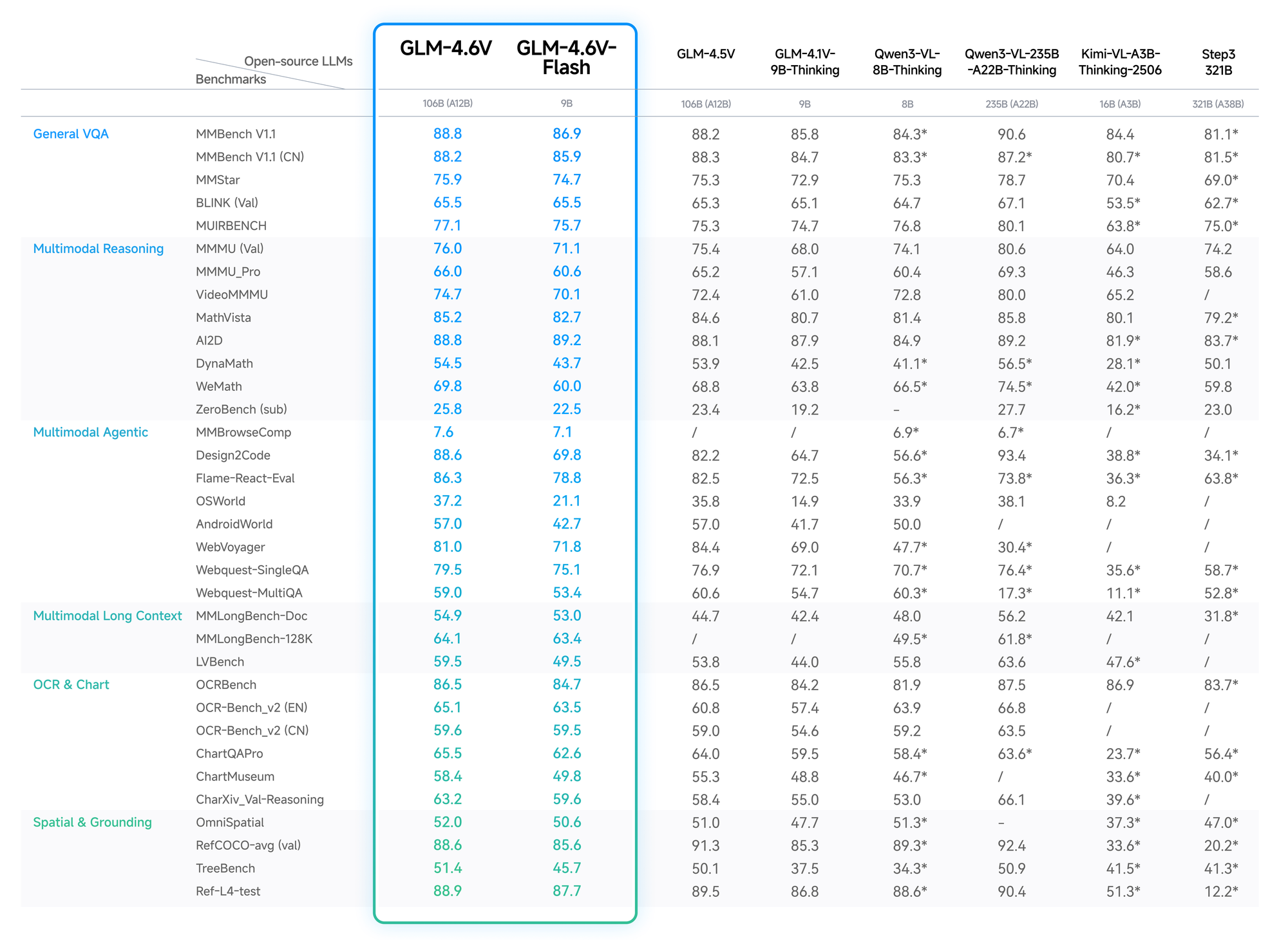
OCRBenchテストでは、歪んだ画像からのテキスト抽出で91%を達成し、オープンソースのランキングでGPT-4Vを上回りました。Video-MMEのような長文コンテキスト評価では、1時間にも及ぶクリップで75%を記録し、フレーム間の詳細を保持しています。
Flashバリアントは、わずかな精度低下(2〜3%)と引き換えに5倍の高速化を実現し、リアルタイムアプリケーションに理想的です。Z.aiのブログで、Hugging Faceで再現可能なセットアップとともに詳細が説明されています。
このように、開発者は信頼性が高く、費用対効果の高いパフォーマンスのためにGLM-4.6Vを選択します。
GLM-4.6Vモデルシリーズの主な機能
GLM-4.6Vは、マルチモーダルAIを向上させる高度な機能を備えています。まず、その入力モダリティはテキスト、画像、ビデオ、ファイルをカバーし、出力は正確なテキスト生成に焦点を当てています。開発者はその柔軟性を高く評価しています。財務PDFをアップロードすると、モデルはテーブルを抽出し、傾向について推論し、視覚化を提案します。
ネイティブツール使用は画期的な機能です。外部オーケストレーションを必要とする従来のモデルとは異なり、GLM-4.6Vは関数呼び出しを埋め込んでいます。リクエストでツール(例えば画像のトリミングツール)を定義すると、モデルは視覚データをパラメータとして渡します。そして、必要に応じて結果を理解し、反復します。これにより、視覚的なウェブ検索のようなタスクのループが閉じられます。クエリ画像から意図を認識し、取得を計画し、結果を統合し、推論された洞察を出力します。
さらに、128Kのコンテキストは長文分析を可能にします。プレゼンテーションから200枚のスライドを処理すると、モデルは主要なテーマを要約しながら、サッカーの試合でのゴールのようなビデオイベントにタイムスタンプを付けます。フロントエンド開発の場合、スクリーンショットからUIを複製し、ピクセル精度のHTML/CSS/JSコードを出力します。その後、自然言語による編集が行われ、プロトタイプがインタラクティブに洗練されます。
Flashバリアントはレイテンシを最適化します。9Bパラメータで、vLLMまたはSGLang推論エンジンを介して消費者向けハードウェアで動作します。Hugging Faceで利用可能なウェイトはファインチューニングを可能にしますが、コレクションはまだ広範な統計情報なしのベースモデルに焦点を当てています。全体として、これらの機能により、GLM-4.6Vはビジネスインテリジェンスやクリエイティブツールにおけるエージェントの多用途なバックボーンとして位置付けられています。
GLM-4.6V APIへのアクセス方法:ステップバイステップのセットアップ
GLM-4.6V APIへのアクセスは、OpenAI互換インターフェースのおかげで簡単です。まず、Z.ai開発者ポータル(z.ai)でサインアップしてください。アカウントダッシュボードでAPIキーを生成します。このベアラートークンがすべてのリクエストを認証します。
ベースエンドポイントはhttps://api.z.ai/api/paas/v4/chat/completionsにあります。JSONペイロードでPOSTメソッドを使用します。認証ヘッダーにはAuthorization: Bearer <your-api-key>とContent-Type: application/jsonが含まれます。メッセージ配列は会話を構造化し、マルチモーダルコンテンツをサポートします。
例えば、テキストプロンプトと一緒に画像URLを送信します。ペイロードは"model": "glm-4.6v"または"glm-4.6v-flash"を指定します。透明な推論トレースのために"thinking": {"type": "enabled"}で思考ステップを有効にします。ストリーミングモードは、サーバー送信イベントを介したリアルタイム応答のために"stream": trueを追加します。
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Describe the key elements in this image and suggest improvements."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
このコードは、根拠付きの説明を取得します。ビデオやファイルの場合、同様にコンテンツ配列を拡張します。URLまたはBase64エンコーディングが機能します。レート制限はプランに基づいて適用されます。ダッシュボード経由で監視してください。
Apidogはこのプロセスを強化します。Z.aiドキュメントからOpenAPI仕様をApidogにインポートし、視覚的にリクエストをモックします。コードなしで関数呼び出しをテストし、本番環境に移行する前にペイロードを検証します。その結果、より迅速に反復し、エラーを早期に発見できます。
ローカルアクセスはクラウド利用を補完します。Hugging FaceのGLM-4.6Vコレクションからウェイトをダウンロードし、互換性のあるフレームワークを介して提供します。このセットアップはプライバシーに敏感なアプリに適していますが、106Bモデルの場合はGPUリソースが必要です。
料金の内訳:GLM-4.6Vによる費用対効果の高いスケーリング
Z.aiはGLM-4.6Vの料金設定を、アクセスしやすさとパフォーマンスのバランスを考慮して行っています。フラッグシップモデルは、入力トークン100万あたり0.6ドル、出力トークン100万あたり0.9ドルを請求します。この階層型モデルはマルチモーダルの複雑さを考慮しており、画像やビデオは解像度と長さに応じてトークンを消費します。
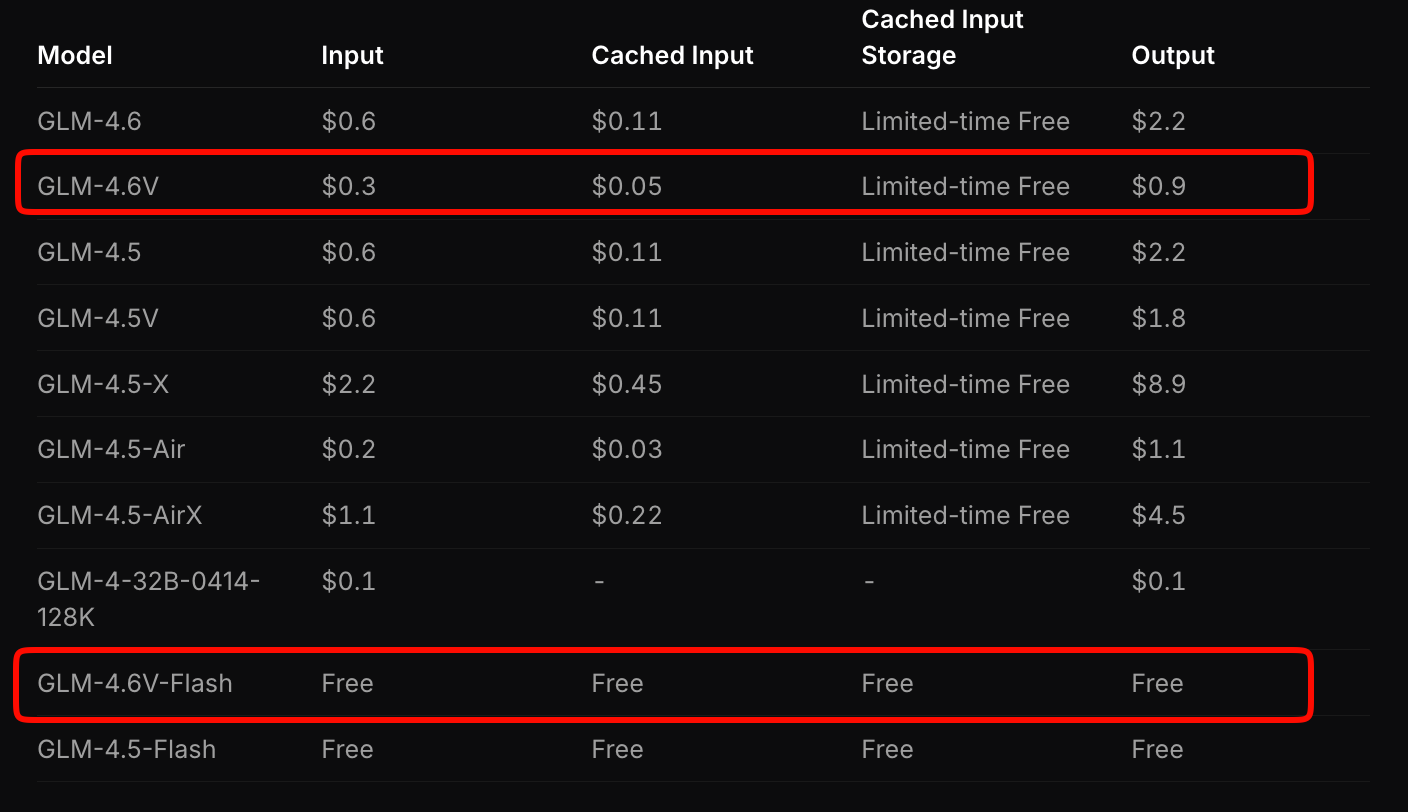
対照的に、GLM-4.6V-Flashは無料でアクセスでき、プロトタイピングやエッジデプロイメントに理想的です。トークン料金は適用されませんが、推論コストはハードウェアに依存します。期間限定のプロモーションでは、有料ティアの7分の1のコストで利用クォータが3倍になり、実験を手頃な価格で行うことができます。
競合他社と比較してください:GLM-4.6Vは、同様のマルチモーダルAPIよりも20〜30%安価でありながら、優れたベンチマークを提供します。高容量のアプリケーションの場合、Z.aiの見積もりツールを使用してコストを計算できます。例えば、1日あたり100件のドキュメント分析といったサンプルワークロードを入力すると、月額費用が予測されます。
さらに、オープンソースのウェイトは長期的なコストを削減します。独自のデータでファインチューニングすることで、クラウド呼び出しへの依存度を低減できます。全体として、この料金設定により、スタートアップ企業は予算の制約なしにスケールできます。
GLM-4.6V APIとApidogの統合:実用的なワークフロー最適化
Apidogは、GLM-4.6Vの統合を手作業の苦役から効率的なコラボレーションへと変革します。APIクライアントおよび設計ツールとして、Z.aiの仕様をインポートし、リクエストテンプレートを自動生成します。マルチモーダルペイロードをドラッグ&ドロップし、応答をプレビューし、Python、Node.js、cURLのコードスニペットとしてエクスポートできます。
Apidogで新しいプロジェクトを作成することから始めます。エンドポイントURLを貼り付け、キーで認証します。ビジュアルグラウンディングタスクの場合、リクエストを作成します。image_urlタイプを追加し、座標プロンプトを入力して送信します。Apidogは出力を視覚化し、思考ステップを強調表示します。
ここでコラボレーションが輝きます。チームとコレクションを共有し、ツールを追加する際にエンドポイントをバージョン管理します。環境変数により、開発、ステージング、本番環境間でキーが保護されます。結果として、デプロイサイクルが短縮され、完全なエージェントチェーンを数分でテストできます。
監視にも拡張できます。Apidogはレイテンシとエラーを記録し、マルチモーダルフローのボトルネックを特定します。GLM-4.6V-Flashと組み合わせて無料のローカルテストを行い、その後クラウドにスケールします。開発者は、このようなツールを使用することでプロトタイピングが40%高速化すると報告しています。
リアルワールドユースケース:GLM-4.6Vの本番環境での適用
GLM-4.6Vはドキュメントを多用する業界で威力を発揮します。金融アナリストはレポートをアップロードし、モデルはチャートを解析し、比率を計算し、埋め込みビジュアルを含むエグゼクティブサマリーを生成します。ある企業では、年間報告書に128Kのコンテキストを活用することで、分析時間を数時間から数分に短縮しました。
Eコマースでは、視覚検索エージェントが活躍します。顧客が製品写真をアップロードすると、GLM-4.6Vはクエリを計画し、一致するものを取得し、色のバリエーションなどの属性について推論します。これにより、早期導入者によると、コンバージョン率が15%向上しました。

フロントエンドチームはプロトタイピングを加速します。スクリーンショットを入力すると、編集可能なコードを受け取ります。「レスポンシブなナビゲーションバーを追加」といったプロンプトで反復します。モデルのピクセルレベルの忠実度により、修正が最小限に抑えられ、設計からデプロイまでの時間が半分に短縮されます。

ビデオプラットフォームは、時間的推論の恩恵を受けます。タイムスタンプ付きで講義を要約したり、監視フィード内のイベントを検出したりします。ネイティブツール使用はデータベースと統合され、異常を自動的にフラグ付けします。
これらの事例は、GLM-4.6Vの多用途性を示しています。ただし、成功はプロンプトエンジニアリングにかかっています。精度を最大化するためには、明確な指示を作成することが重要です。
GLM-4.6V API使用における課題とベストプラクティス
強みがあるにもかかわらず、マルチモーダルモデルには課題があります。高解像度の入力はトークン数を膨らませ、コストを増加させます。最初に画像を512x512ピクセルに圧縮してください。コンテキストオーバーフローはハルシネーションのリスクがあるため、長いビデオはセグメントに分割してください。
ベストプラクティスはこれらを軽減します。デバッグには思考モードを使用してください。これにより中間ステップが明らかになります。コード内のアサーションでツール出力を検証してください。Apidogユーザーの場合、スキーマを強制するためにエンドポイントで自動テストを設定してください。
クォータを注意深く監視してください。無料のFlashは予期せぬ事態を防ぎますが、有料ティアは予算編成が必要です。最後に、オープンウェイトを介してドメインデータでファインチューニングし、特異性を高めてください。
結論:今すぐGLM-4.6Vでプロジェクトを向上させましょう
GLM-4.6Vは、ネイティブツール、広範なコンテキスト、オープンなアクセシビリティを通じてマルチモーダルAIを再定義します。そのAPIは、フルモデルで入力100万トークンあたり0.6ドル、Flashは無料で提供され、Apidogのようなプラットフォームとシームレスに統合されます。ドキュメントエージェントからUIジェネレーターまで、イノベーションを推進します。
これらの洞察を今すぐ実行に移しましょう。APIキーを取得し、Apidogでテストし、構築を開始してください。AIの未来は、こうした機能を早期に活用する人々に有利に働きます。次に、どのアプリケーションを変革しますか?