開発者は、多様なアプリケーションで堅牢なパフォーマンスを発揮する強力な言語モデルを常に求めています。Zhipu AIは、人工知能の能力の限界を押し広げるGLMシリーズの先進的な反復であるGLM-4.6を発表します。このモデルは、コンテキスト処理、推論、および実用性における大幅な強化を組み込むことにより、以前のバージョンを基盤として構築されています。エンジニアはGLM-4.6をワークフローに統合し、コード生成からコンテンツ作成まで、複雑なタスクをより高い効率と精度で処理しています。
Zhipu AIは、GLM-4.6を、手頃な価格帯から始まるサブスクリプションベースのサービスであるGLMコーディングプランの一部として設計しています。ユーザーは、Claude Code、Cline、OpenCodeなどの統合ツールを通じてこのモデルにアクセスでき、シームレスなAI支援開発を可能にします。このモデルは、広範なコンテキストを処理し、高品質な出力を生成する実世界のシナリオで優れています。さらに、GLM-4.6はベンチマークで優れたパフォーマンスを発揮し、Claude Sonnet 4のような国際的なリーダーに匹敵します。これにより、信頼性の高いAIサポートを必要とする中国内外の開発者にとって最有力候補となっています。
モデルの基盤を理解することから、そのコア機能とそれが技術的な実装にどのように役立つかを見ていきましょう。
GLM-4.6とは?
Zhipu AIはGLM-4.6を開発しました。これは、幅広い技術的および創造的なタスクに最適化された大規模言語モデルです。このモデルは、355BパラメータのMixture of Experts (MoE) アーキテクチャを特徴としており、高いパフォーマンスを維持しながら効率的な計算を可能にします。ユーザーは、以前のバージョンの128K制限から大幅にアップグレードされた200Kトークンの拡張コンテキストウィンドウを高く評価しています。この拡張により、モデルは一貫性を失うことなく、複雑で長文のインタラクションを管理できます。
さらに、GLM-4.6はテキスト入力および出力モダリティをサポートしており、正確な言語処理を必要とするアプリケーションに多用途性をもたらします。最大出力トークン制限は128Kに達し、詳細な応答に十分なスペースを提供します。開発者はこれらの仕様を活用して、ドキュメント分析や多段階推論チェーンなど、広範なデータを処理するシステムを構築します。
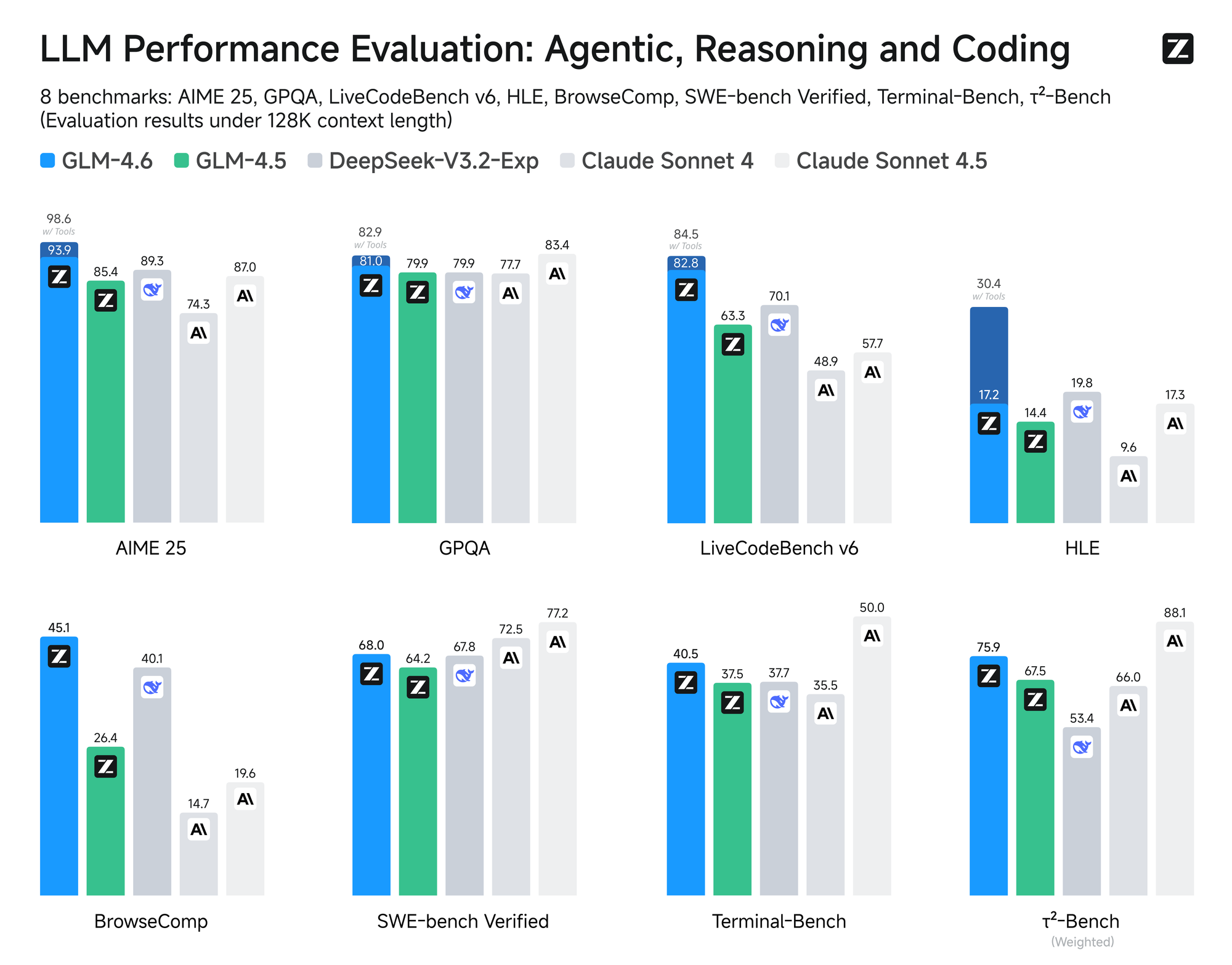
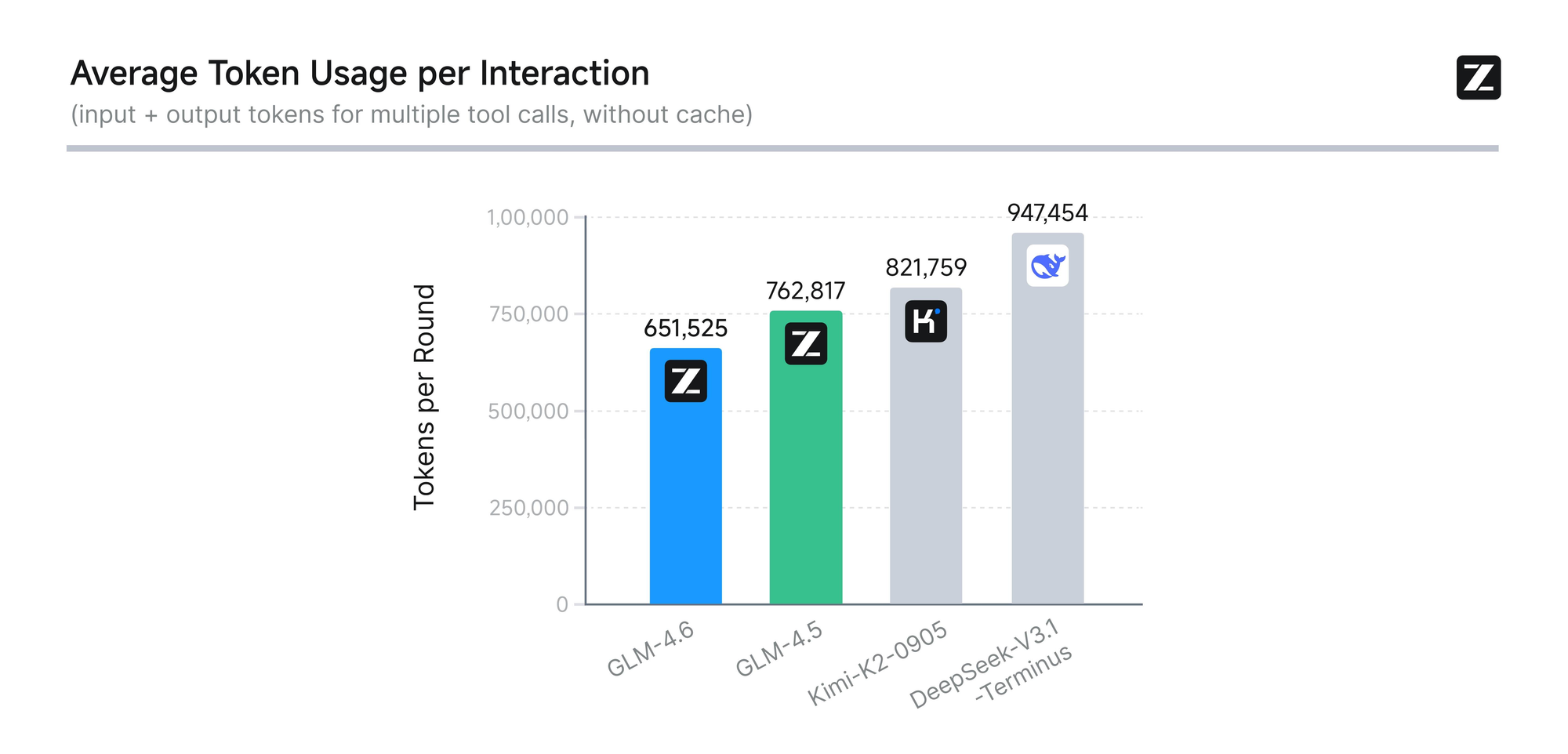
このモデルは、AIME 25、GPQA、LCB v6、HLE、SWE-Bench Verifiedを含む8つの権威あるベンチマークで厳格な評価を受けています。結果は、GLM-4.6がClaude Sonnet 4および4.6のような主要モデルと同等の性能を発揮することを示しています。例えば、Claude Code環境内で実施された実世界のコーディングテストでは、GLM-4.6は74の実用的なシナリオで競合他社を上回っています。これは、トークン消費において30%以上の効率向上を達成し、大量ユーザーの運用コストを削減しています。
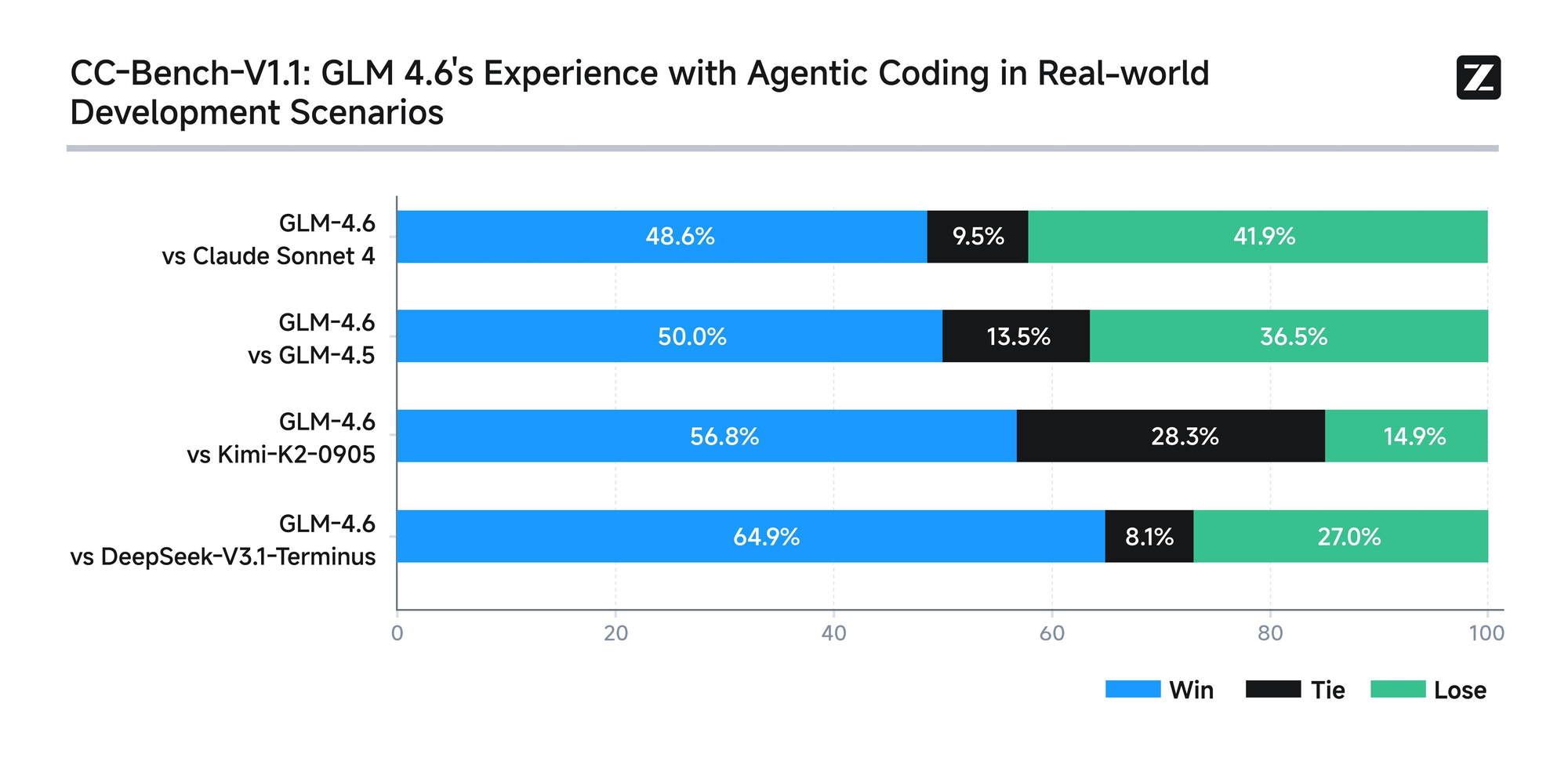
さらに、Zhipu AIは、すべてのテスト問題とエージェントの軌跡を公開することで透明性を確保しています。この慣行により、開発者は主張を検証し、結果を再現することができ、テクノロジーへの信頼を育みます。GLM-4.6は、推論中のツール使用をサポートする高度な推論機能も統合しています。この機能は、モデルが自律的にタスクを計画および実行するエージェントフレームワークでの有用性を高めます。
コーディング以外にも、GLM-4.6は他の分野でも優れた能力を発揮します。人間の好みに合わせて文章を洗練させ、スタイル、可読性、ロールプレイングの信頼性を向上させます。翻訳タスクでは、フランス語、ロシア語、日本語、韓国語などのマイナー言語に最適化し、非公式な文脈での意味的一貫性を保証します。コンテンツクリエーターは、コンテキストの拡張と感情のニュアンスから恩恵を受け、小説、脚本、コピーライティングにそれを使用します。
仮想キャラクター開発は、GLM-4.6が複数ターンの会話で一貫したトーンを維持するため、もう1つの強みです。これにより、ソーシャルAIやブランドの擬人化に理想的です。インテリジェント検索と詳細な調査では、モデルは意図の理解と結果の統合を強化し、洞察に富んだ出力を提供します。
全体として、GLM-4.6は開発者がよりスマートなアプリケーションを作成するのを支援します。長文コンテキスト処理、効率的なトークン使用、および幅広い適用性の組み合わせにより、AI分野で際立っています。モデルの本質を理解したところで、実用的な実装のためにそのAPIにアクセスする方法に移りましょう。
GLM-4.6 APIへのアクセス方法
Zhipu AIは、オープンプラットフォームを通じてGLM-4.6 APIへの簡単なアクセスを提供しています。開発者は、Zhipu AIのウェブサイト(具体的にはopen.bigmodel.cnまたはz.ai)でアカウントにサインアップすることから始めます。安全な登録を確実にするために、メールアドレスまたは電話番号の確認が必要です。
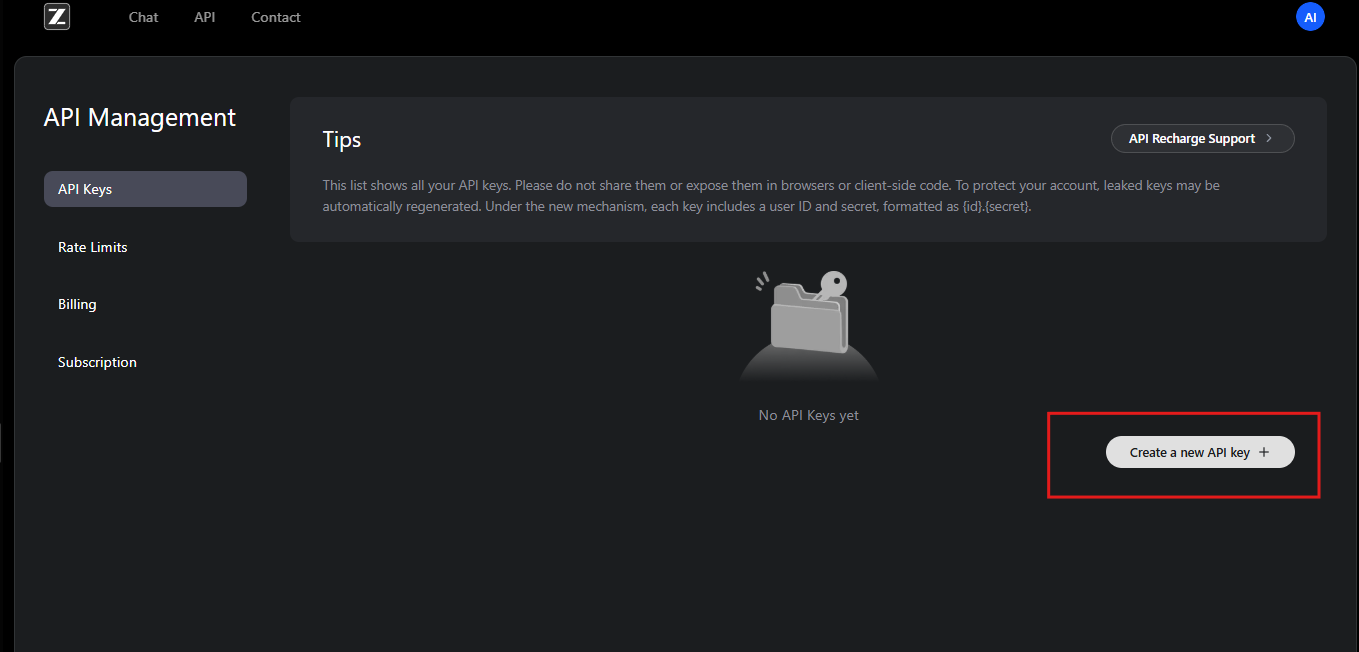
登録後、ユーザーはGLMコーディングプランに加入します。このプランにより、GLM-4.6および関連モデルが利用可能になります。加入者はAPIダッシュボードにアクセスでき、そこでAPIキーを生成します。これらのキーは、リクエストを認証するための資格情報として機能します。
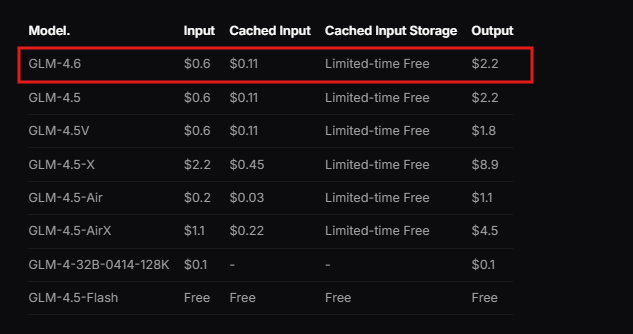
さらに、Zhipu AIは統合手順を詳述したドキュメントを提供しています。開発者はこのリソースを確認して、互換性のあるプログラミング環境などの前提条件を理解します。APIはRESTful設計に従っており、標準的なHTTPクライアントと互換性があります。
開始するには、ユーザーはアカウントのAPI管理セクションに移動します。ここで、新しいAPIキーを作成し、その値を安全に記録します。Zhipu AIはセキュリティのために定期的なキーのローテーションを推奨しています。さらに、プラットフォームはサブスクリプションティアに基づいて使用量クォータを提供し、過剰な使用を防ぎます。
開発者が問題に遭遇した場合、Zhipu AIのサポートチームがメールまたはフォーラムを通じて支援します。また、一般的なアクセス問題のトラブルシューティングのためのコミュニティリソースも提供しています。アクセスが確保されたら、次のステップはGLM-4.6 APIと効果的にやり取りするための認証を設定することです。
GLM-4.6 APIの認証とセットアップ
認証は、安全なAPIインタラクションのバックボーンを形成します。Zhipu AIは、GLM-4.6 APIにBearerトークン認証を採用しています。開発者は、各リクエストのAuthorizationヘッダーにAPIキーを含めます。
セットアップのために、開発環境に必要なライブラリをインストールします。例えばPythonユーザーは、requestsライブラリを利用します。これをインポートし、次のようにヘッダーを設定します。
import requests
api_key = "your-api-key"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
このコードは、リクエストを送信するための環境を準備します。同様に、Node.jsを使用するJavaScriptでは、開発者はfetch APIまたはaxiosライブラリを使用します。これらはオプションオブジェクトにヘッダーを設定します。
さらに、システムがネットワーク要件を満たしていることを確認してください。GLM-4.6 APIエンドポイントはhttps://api.z.ai/api/paas/v4/chat/completionsにあります。ドメインにpingを打つか、簡単なリクエストを送信して接続をテストしてください。
セットアップ中、開発者はAPIキーを安全に保存するために環境変数を設定します。この方法は、スクリプトに機密情報をハードコーディングすることを避けます。PythonのdotenvやNode.jsのprocess.envのようなツールがこれを容易にします。
プロキシまたはVPNを使用している場合は、それがZhipu AIのサーバーへのトラフィックを許可していることを確認してください。認証の失敗は、多くの場合、キーのフォーマットが間違っているか、サブスクリプションの期限切れに起因します。Zhipu AIは応答でエラーをログに記録し、問題の診断を支援します。
認証が完了したら、開発者はエンドポイントの探索に進みます。このセットアップにより、GLM-4.6の機能への信頼性の高い安全なアクセスが保証されます。
GLM-4.6 APIエンドポイントの探索
GLM-4.6 APIは、チャット補完のための主要なエンドポイントを中心に展開しています。開発者は、https://api.z.ai/api/paas/v4/chat/completionsにPOSTリクエストを送信して応答を生成します。
このエンドポイントは、基本モードとストリーミングモードの両方を処理します。基本モードでは、サーバーはリクエスト全体を処理し、完全な応答を返します。一方、ストリーミングモードでは、リアルタイムアプリケーションに理想的なように、出力を段階的に配信します。
エンドポイントを呼び出すには、必要なパラメータを含むJSONペイロードを構築します。モデルフィールドは「glm-4.6」を指定します。メッセージ配列には、会話をシミュレートするロールとコンテンツのペアが含まれます。
例えば、基本的なcurlリクエストは次のようになります。
curl -X POST "https://api.z.ai/api/paas/v4/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer your-api-key" \
-d '{
"model": "glm-4.6",
"messages": [
{"role": "user", "content": "Generate a Python function for sorting a list."}
]
}'
サーバーは、生成されたコンテンツを含むJSONで応答します。開発者はこれを解析してアシスタントメッセージを抽出します。
さらに、このエンドポイントは思考ステップのような高度な機能をサポートしています。thinkingオブジェクトを設定して、出力に詳細な推論を可能にします。
このエンドポイントを理解することで、開発者はインタラクティブなAIシステムを構築できます。次に、リクエストパラメータを詳細に見ていきましょう。
GLM-4.6 APIリクエストパラメータの詳細な説明
リクエストパラメータは、GLM-4.6 APIの動作を制御します。モデルパラメータは、この特定のバージョンを選択するために「glm-4.6」を必須とします。
メッセージ配列が会話を駆動します。各オブジェクトには、入力用の「user」、以前の応答用の「assistant」としてのロールと、テキスト文字列としてのコンテンツが含まれます。開発者は、ロールを交互にすることで複数ターンの対話を構築します。
さらに、max_tokensは応答の長さを制限し、過剰な出力を防ぎます。バランスの取れた結果を得るには4096に設定します。Temperatureはランダム性を調整します。0.6のような低い値は決定論的な出力を生成し、高い値は創造性を促進します。
ストリーミングの場合、「stream」: trueを含めます。これにより、応答形式がチャンクデータに変更されます。
thinkingパラメータは、段階的な推論を可能にします。「thinking」: {"type": "enabled"}を設定すると、中間思考が応答に含まれます。
その他のオプションパラメータには、ニュークリアスサンプリング用のtop_pと、繰り返しを抑制するためのpresence_penaltyがあります。開発者はユースケースに基づいてこれらを調整します。
無効なパラメータは、不正なリクエストに対して400などのコードを含むエラー応答をトリガーします。送信する前に常にペイロードを検証してください。
これらのパラメータを習得することで、開発者は最適なパフォーマンスのためにGLM-4.6 API呼び出しをカスタマイズできます。
GLM-4.6 APIからの応答の処理
GLM-4.6 APIからの応答はJSON形式で届きます。開発者は、生成されたコンテンツにアクセスするためにchoices配列を解析します。
基本モードでは、応答には以下が含まれます。
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1694123456,
"model": "glm-4.6",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Your generated text here."
},
"finish_reason": "stop"
}
]
}
アプリケーションで使用するためにcontentフィールドを抽出します。
ストリーミングモードでは、応答はServer-Sent Events (SSE) としてストリームされます。各チャンクは次のようになります。
data: {"id":"chatcmpl-...","choices":[{"delta":{"content":" partial text"}}]}
開発者は、deltasを蓄積して完全な出力を構築します。
エラー処理にはステータスコードの確認が含まれます。401は認証失敗を示し、429はレート制限を示します。
デバッグのために応答をログに記録します。このアプローチにより、GLM-4.6 APIとの堅牢な統合が保証されます。
GLM-4.6 API統合のためのコード例
開発者は、GLM-4.6 APIをさまざまな言語で実装します。Pythonでは、requestsを使用して基本的な呼び出しを行います。
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
payload = {
"model": "glm-4.6",
"messages": [{"role": "user", "content": "Explain quantum computing."}],
"max_tokens": 500,
"temperature": 0.7
}
headers = {
"Authorization": "Bearer your-api-key",
"Content-Type": "application/json"
}
response = requests.post(url, data=json.dumps(payload), headers=headers)
print(response.json()["choices"][0]["message"]["content"])
このコードはクエリを送信し、応答を出力します。
Node.jsを使用したJavaScriptでは:
const fetch = require('node-fetch');
const url = 'https://api.z.ai/api/paas/v4/chat/completions';
const payload = {
model: 'glm-4.6',
messages: [{ role: 'user', content: 'Write a haiku about AI.' }],
max_tokens: 100
};
const headers = {
'Authorization': 'Bearer your-api-key',
'Content-Type': 'application/json'
};
fetch(url, {
method: 'POST',
body: JSON.stringify(payload),
headers
})
.then(res => res.json())
.then(data => console.log(data.choices[0].message.content));
Pythonでのストリーミングには、sseclientのようなSSE解析ライブラリを使用します。
これらの例は、実用的な統合を示しており、開発者が迅速にプロトタイプを作成できるようにします。
GLM-4.6 APIテストのためのApidogの使用
Apidogは、GLM-4.6 APIをテストするための優れたツールとして機能します。このオールインワンプラットフォームにより、開発者はAPIインタラクションの設計、デバッグ、モック、自動化を行うことができます。
apidog.comからApidogをダウンロードし、プロジェクトを作成することから始めます。URL https://api.z.ai/api/paas/v4/chat/completionsで新しいAPIを追加して、GLM-4.6 APIエンドポイントをインポートします。
Apidogのヘッダーセクションで認証を設定し、「Authorization: Bearer your-api-key」を追加します。モデルやメッセージなどのJSONパラメータでリクエストボディを設定します。
Apidogを使用すると、ユーザーフレンドリーなインターフェースでリクエストを送信し、応答を表示できます。開発者は、リクエストを複製してパラメータを調整することで、バリエーションをテストします。
さらに、Apidogでシナリオを作成してテストを自動化します。応答コンテンツを検証するためのアサーションを定義し、GLM-4.6 APIが期待どおりに動作することを確認します。
Apidogのモックサーバーは、オフライン開発のために応答をシミュレートします。この機能は、ライブAPI呼び出しなしでプロトタイピングを加速します。

Apidogを組み込むことで、開発者はGLM-4.6 APIのワークフローを効率化し、エラーを削減し、デプロイメントを高速化します。
GLM-4.6 APIのベストプラクティスとレート制限
ベストプラクティスに従うことで、GLM-4.6 APIの可能性を最大限に引き出すことができます。開発者は、サブスクリプションに基づいて通常1分あたりのトークン数または1日あたりのリクエスト数で定義されるレート制限内に収まるように使用状況を監視します。
429のようなエラーが発生した場合は、再試行のために指数バックオフを実装します。これにより、サーバーの過負荷を防ぎます。
応答の品質を向上させるために、プロンプトを明確にするように最適化します。システムメッセージを使用してコンテキストを設定し、モデルを効果的にガイドします。
本番環境でAPIキーを安全に保護します。クライアントサイドコードでそれらを公開しないようにします。
監査とパフォーマンス分析のためにインタラクションをログに記録します。このデータは改善に役立ちます。
空の応答やタイムアウトなどのエッジケースは、フォールバックメカニズムで処理します。
Zhipu AIはドキュメントでレート制限を更新します。定期的に確認してください。
これらのプラクティスに従うことで、GLM-4.6 APIの効率的で信頼性の高い使用が保証されます。
GLM-4.6 APIの高度な使用法
高度なユーザーは、インタラクティブなアプリケーションのためにストリーミングを探索します。「stream」: trueを設定し、チャンクをリアルタイムで処理します。
メッセージに関数呼び出しを含めることでツールを組み込みます。GLM-4.6はツール呼び出しをサポートしており、エージェントが外部アクションを実行できるようにします。
例えば、ペイロードにツールを定義します。
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {...}
}
}
]
モデルは必要に応じてツール呼び出しで応答します。
特定のタスクのために温度を微調整します。事実に関するクエリには低く、創造的なクエリには高く設定します。
文書要約のために長いコンテキストと組み合わせます。メッセージに大量のテキストを供給します。
複雑なワークフローのためにLangChainのようなエージェントフレームワークに統合します。
これらの技術は、洗練されたシステムでGLM-4.6の可能性を最大限に引き出します。
結論
GLM-4.6 APIは、AIイノベーションのための強力なツールを開発者に提供します。このガイドに従うことで、プロジェクトにシームレスに統合できます。機能を試し、Apidogを使用してテストし、成功のためにベストプラクティスを適用してください。Zhipu AIはGLM-4.6を進化させ続けており、今後さらに優れた機能が期待されます。