
オープンソースAIの分野で、またしても大きな変化が起こりました。かつてZhipuとして知られていた中国のAI企業Z.aiは、DeepSeekを凌駕し、AIのパフォーマンスとアクセシビリティの新たな基準を打ち立てることを約束するGLM-4.5とGLM-4.5 Airをリリースしました。これらのモデルは、単なる漸進的な改善にとどまらず、ハイブリッド推論とエージェント機能が本番環境でどのように機能すべきかという根本的な再考を具現化したものです。
このリリースは、開発者が機能性を犠牲にすることなく、プロプライエタリモデルに代わる費用対効果の高い選択肢をますます求める重要な時期に行われました。GLM-4.5とGLM-4.5 Airはどちらも、推論、コーディング、マルチモーダルタスクにおいて最先端のパフォーマンスを維持しつつ、効率を最大化する洗練されたアーキテクチャ革新によって、この約束を実現しています。
GLM-4.5アーキテクチャ革命の理解
GLM-4.5シリーズは、従来のトランスフォーマーアーキテクチャからの大きな脱却を意味します。完全に自社開発されたアーキテクチャに基づいて構築されたGLM-4.5は、競合他社と一線を画すいくつかの主要な革新により、オープンソースモデルでSOTA(最先端)のパフォーマンスを達成しています。
GLM-4.5は合計3550億のパラメータを持ち、そのうち320億がアクティブパラメータです。一方、GLM-4.5 Airは、合計1060億のパラメータと120億のアクティブパラメータを持つ、よりコンパクトな設計を採用しています。このパラメータ構成は、計算効率とモデル能力の間の慎重なバランスを反映しており、両モデルが妥当な推論コストを維持しながら、印象的なパフォーマンスを提供できるようにしています。
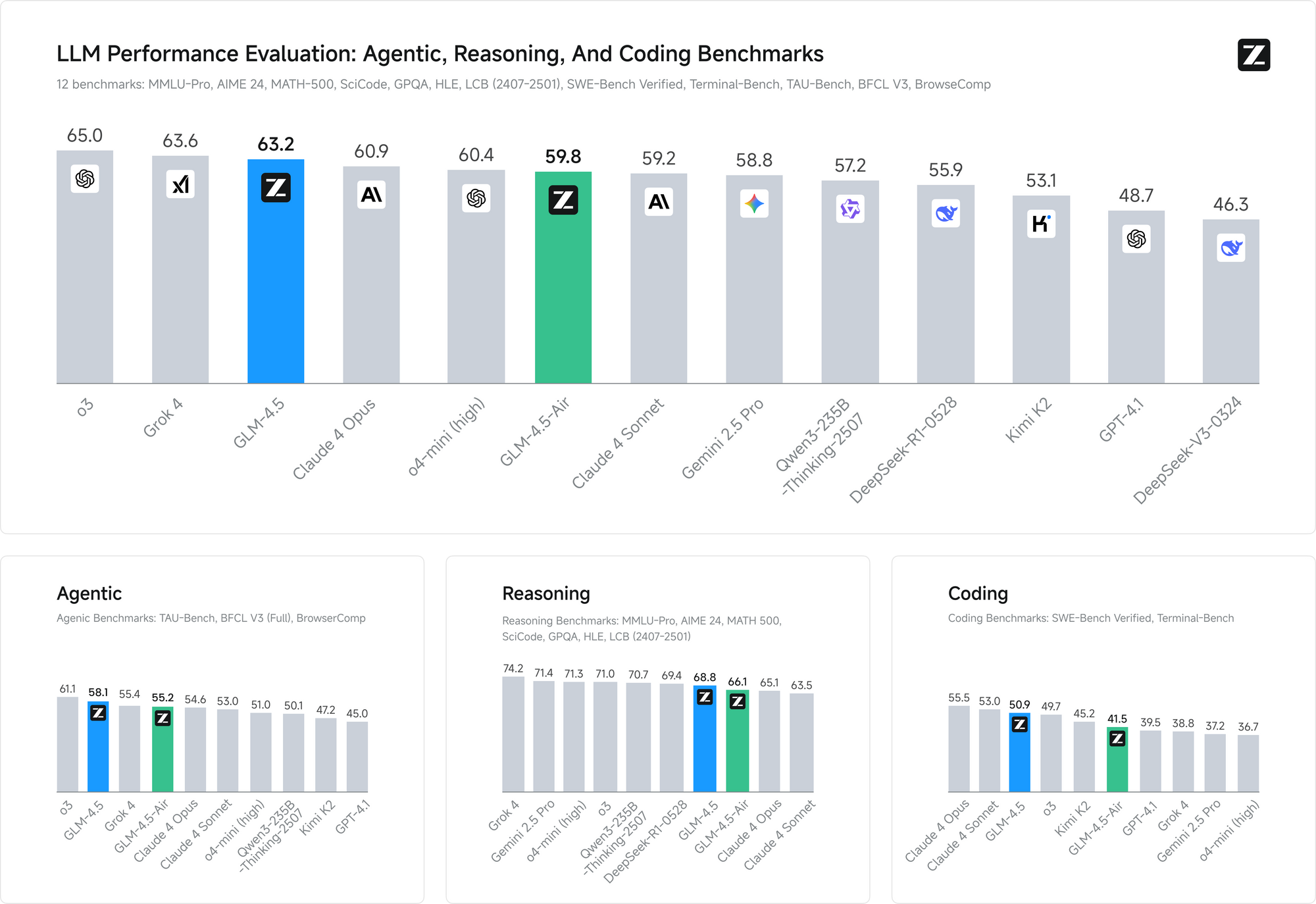
これらのモデルは、推論中にパラメータの一部のみをアクティブにする洗練されたMixture of Experts(MoE)アーキテクチャを利用しています。どちらのモデルも、最適な効率のためにMixture of Experts設計を活用しており、GLM-4.5は3550億のパラメータのうち320億のみを使用して複雑なタスクを処理できます。一方、GLM-4.5 Airは、合計1060億のパラメータプールからわずか120億のアクティブパラメータで、同等の推論能力を維持しています。
このアーキテクチャのアプローチは、大規模言語モデルの展開における最も喫緊の課題の一つである、推論の計算オーバーヘッドに直接対処しています。従来の密なモデルは、すべての推論操作に対してすべてのパラメータをアクティブにする必要があり、より単純なタスクでは不必要な計算負荷を生み出していました。GLM-4.5シリーズは、計算の複雑さをタスクの要件に合わせるインテリジェントなパラメータルーティングによってこれを解決します。
さらに、これらのモデルは最大128kの入力と96kの出力コンテキストウィンドウをサポートしており、洗練された長文推論と包括的なドキュメント分析を可能にする、実質的なコンテキスト処理能力を提供します。この拡張されたコンテキストウィンドウは、モデルが複雑な多段階のインタラクションを認識し続ける必要があるエージェントアプリケーションにおいて特に価値があることが証明されています。
GLM-4.5 Airの最適化されたパフォーマンス特性
GLM-4.5 Airは、計算リソースの慎重な管理が必要なシナリオのために特別に設計された、このシリーズの効率性のチャンピオンとして登場しました。GLM-4.5 Airは、AIエージェントアプリケーション向けに特別に設計された基盤モデルであり、コア機能を損なうことなく速度とリソースの最適化を優先するMixture-of-Experts(MoE)アーキテクチャに基づいて構築されています。
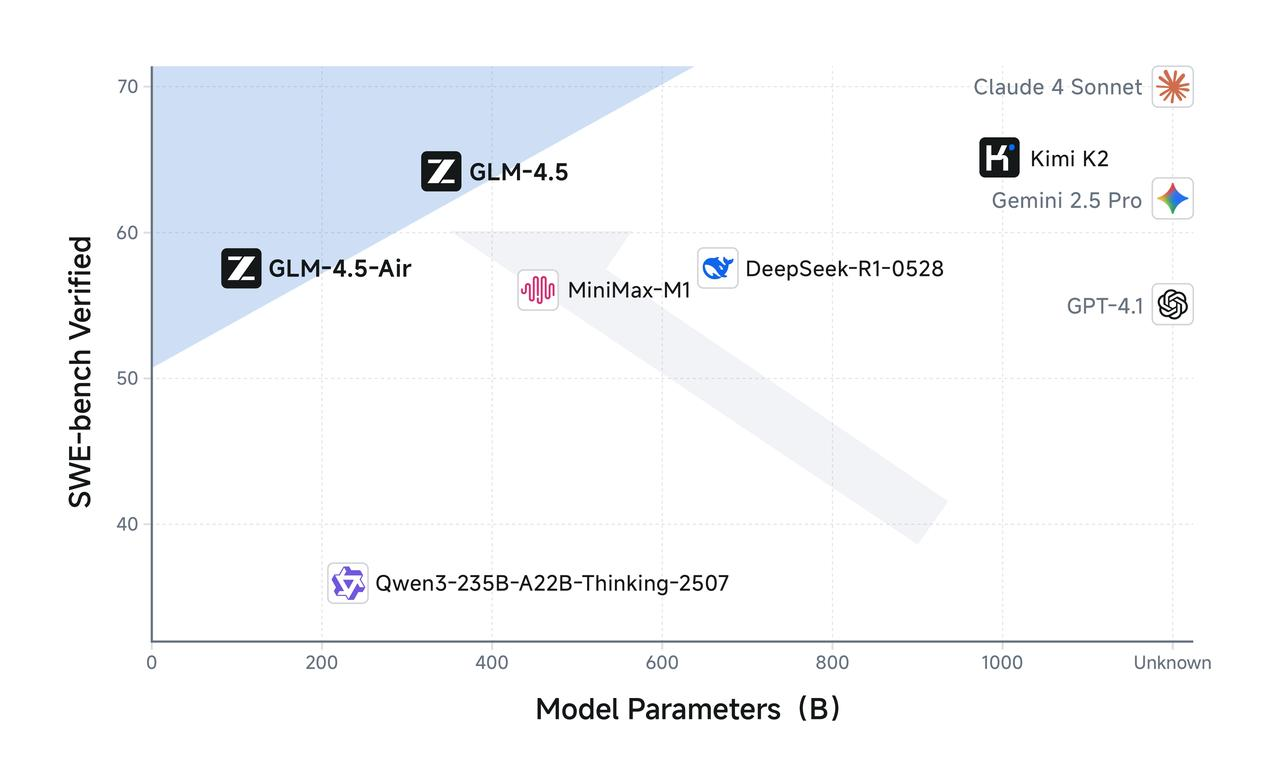
Airバリアントは、思慮深いパラメータ削減がモデル品質を維持しつつ、デプロイの実現可能性を劇的に向上させる方法を示しています。合計1060億のパラメータと120億のアクティブパラメータにより、GLM-4.5 Airは、推論コストの削減と応答時間の高速化に直結する驚くべき効率向上を達成しています。
メモリ要件もまた、GLM-4.5 Airが優れている分野です。GLM-4.5 Airは16GBのGPUメモリ(INT4量子化で約12GB)を必要とし、中程度のハードウェア制約を持つ組織でも利用可能です。このアクセシビリティは、多くの開発チームがより大きなモデルに関連するインフラコストを正当化できないため、広範な採用にとって極めて重要であることが証明されています。
最適化は、純粋なパラメータ効率を超えて、エージェント指向タスクのための特殊なトレーニングにまで及んでいます。ツール使用、ウェブブラウジング、ソフトウェア開発、フロントエンド開発のために広範に最適化されており、コーディングエージェントとのシームレスな統合を可能にします。この専門化は、GLM-4.5 Airが同サイズの汎用モデルと比較して、実用的な開発タスクにおいて優れたパフォーマンスを発揮することを意味します。
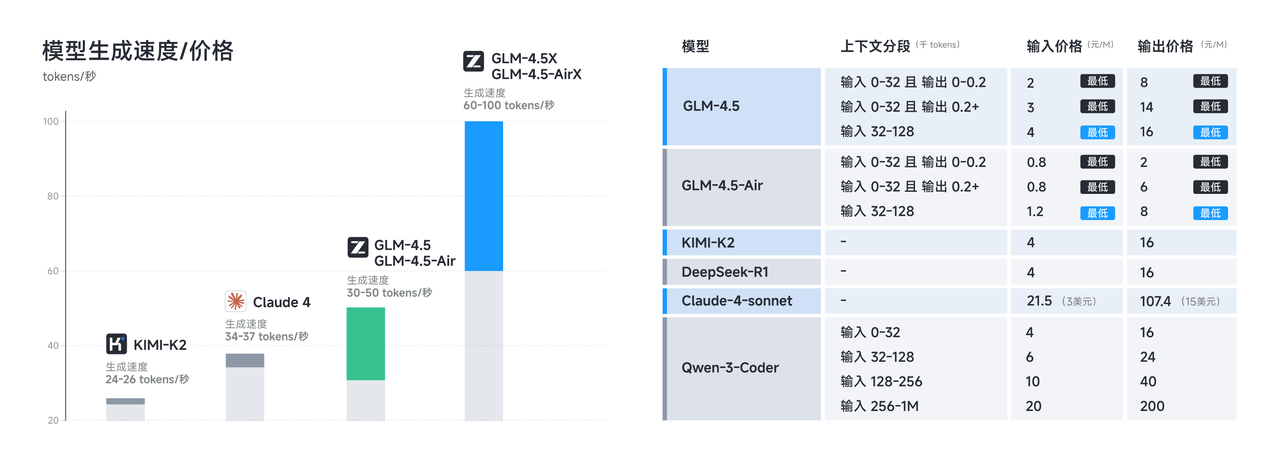
応答レイテンシは、ユーザーがほぼ瞬時のフィードバックを期待するインタラクティブなアプリケーションにおいて特に重要になります。GLM-4.5 Airの削減されたパラメータ数と最適化された推論パイプラインは、ほとんどのクエリで1秒未満の応答時間を可能にし、コード補完、インタラクティブデバッグ、ライブドキュメント生成などのリアルタイムアプリケーションに適しています。
ハイブリッド推論の実装と利点
GLM-4.5モデル両方の決定的な特徴は、そのハイブリッド推論能力にあります。GLM-4.5とGLM-4.5 Airはどちらもハイブリッド推論モデルであり、複雑な推論とツール使用のための思考モードと、即時応答のための非思考モードの2つのモードを提供します。このデュアルモードアーキテクチャは、AIモデルが異なる種類の認知タスクを処理する方法における根本的な革新を意味します。
思考モードは、モデルが多段階の推論、ツール使用、または広範な分析を必要とする複雑な問題に遭遇したときにアクティブになります。思考モード中、モデルは開発者には見えるがエンドユーザーには隠された中間推論ステップを生成します。この透明性により、クリーンなユーザーインターフェースを維持しつつ、推論プロセスのデバッグと最適化が可能になります。
逆に、非思考モードは、拡張された推論オーバーヘッドなしに即時応答から利益を得る、単純なクエリを処理します。モデルは、クエリの複雑さとコンテキストに基づいて、どちらのモードを使用するかを自動的に決定し、多様なユースケース全体で最適なリソース利用を保証します。
このハイブリッドアプローチは、本番AIシステムにおける長年の課題、すなわち応答速度と推論品質のバランスを解決します。従来のモデルは、包括的な推論のために速度を犠牲にするか、高速だが潜在的に浅い応答を提供していました。GLM-4.5のハイブリッドシステムは、推論の複雑さをタスクの要件に合わせることで、このトレードオフを解消します。
どちらのモデルも、複雑なタスクには思考モードを、即時応答には非思考モードを提供し、多様な認知要求に適応するシームレスなユーザーエクスペリエンスを創出します。開発者は、特定のアプリケーション要件に基づいて、速度と推論の深さのバランスを微調整するために、モード選択パラメータを設定できます。
思考モードは、モデルが多段階の行動を計画し、ツール使用オプションを評価し、長期間のインタラクション全体で一貫した推論を維持する必要があるエージェントアプリケーションにおいて特に価値があることが証明されています。一方、非思考モードは、事実の検索や単純なコード補完タスクのような簡単なクエリに対して、応答性の高いパフォーマンスを保証します。
技術仕様とトレーニングの詳細
GLM-4.5の印象的な能力を支える技術的基盤は、広範なエンジニアリング努力と革新的なトレーニング手法を反映しています。最大128kの入力と96kの出力コンテキストウィンドウをサポートし、15兆のトークンでトレーニングされたこれらのモデルは、最先端のパフォーマンスに必要な規模と洗練度を示しています。
トレーニングデータのキュレーションは、特にコード生成やエージェント推論のような特殊なアプリケーションにおいて、モデル品質の重要な要素となります。15兆トークンのトレーニングコーパスには、コードリポジトリ、技術文書、推論例、マルチモーダルコンテンツなど、多様なソースが組み込まれており、ドメイン全体にわたる包括的な理解を可能にしています。
コンテキストウィンドウの機能は、GLM-4.5を多くの競合モデルと区別します。GLM-4.5は128kのコンテキスト長とネイティブ関数呼び出し能力を提供し、コンテキストの切り捨てなしに洗練された長文分析と多段階の会話を可能にします。96kの出力コンテキストウィンドウは、モデルが人為的な長さの制限なしに包括的な応答を生成できることを保証します。
ネイティブ関数呼び出しは、外部オーケストレーションレイヤーの必要性を排除するもう一つのアーキテクチャ上の利点です。モデルは、推論プロセスの一部として外部ツールやAPIを直接呼び出すことができ、より効率的で信頼性の高いエージェントワークフローを構築します。この機能は、モデルがデータベース、外部サービス、開発ツールと連携する必要がある本番アプリケーションにとって不可欠であることが証明されています。
トレーニングプロセスには、エージェントタスクに特化した最適化が組み込まれており、モデルがツール使用、多段階推論、コンテキスト維持において強力な能力を開発することを保証します。推論、コーディング、マルチモーダルな知覚-行動ワークフローのための統合されたアーキテクチャにより、単一のインタラクション内で異なるタスクタイプ間のシームレスな移行が可能になります。
パフォーマンスベンチマークは、これらのトレーニングアプローチの有効性を検証しています。両方のベンチマークにおいて、GLM-4.5はエージェント能力評価でClaudeのパフォーマンスに匹敵し、オープンソースのアクセシビリティを維持しながら、主要なプロプライエタリモデルに対する競争力のある能力を示しています。
ライセンスと商用展開の利点
オープンソースライセンスは、現在のAI分野におけるGLM-4.5の最も重要な競争優位性の一つです。ベースモデル、ハイブリッド(思考/非思考)モデル、およびFP8バージョンはすべて、MITライセンスの下で無制限の商用利用と二次開発のためにリリースされており、商用展開に前例のない自由を提供します。
このライセンスアプローチは、他のオープンソースモデルを制限する多くの制約を排除します。組織は、ライセンス料や使用制限なしにGLM-4.5の実装を修正、再配布、商用化できます。MITライセンスは、エンタープライズAIの展開を複雑にすることが多い商用上の懸念に特に対処しています。
複数のアクセス方法とプラットフォーム統合
GLM-4.5とGLM-4.5 Airは、開発者向けに複数のアクセスパスを提供しており、それぞれ異なるユースケースと技術要件に合わせて最適化されています。これらのデプロイオプションを理解することで、チームは特定のアプリケーションに最適な統合方法を選択できます。
公式サイトと直接APIアクセス
主要なアクセス方法は、chat.z.aiにあるZ.aiの公式プラットフォームを使用することです。これは、即座のモデルインタラクションのためのユーザーフレンドリーなインターフェースを提供します。このウェブベースのインターフェースは、技術的な統合作業を必要とせずに、迅速なプロトタイピングとテストを可能にします。開発者は、API実装にコミットする前に、モデルの能力を評価し、プロンプトエンジニアリング戦略をテストし、ユースケースを検証できます。
Z.aiの公式エンドポイントを介した直接APIアクセスは、包括的なドキュメントとサポートを備えた本番環境レベルの統合機能を提供します。公式APIは、ハイブリッド推論モードの選択、コンテキストウィンドウの利用、応答フォーマットオプションなど、モデルパラメータに対するきめ細かな制御を可能にします。
簡素化されたアクセスのためのOpenRouter統合
OpenRouterは、openrouter.ai/z-aiにある統一APIプラットフォームを介して、GLM-4.5モデルへの合理化されたアクセスを提供します。この統合方法は、OpenRouterのマルチモデルインフラストラクチャをすでに使用している開発者にとって特に価値があります。なぜなら、個別のAPIキー管理や統合パターンが不要になるからです。
OpenRouterの実装は、認証、レート制限、エラー処理を自動的に行い、開発チームの統合の複雑さを軽減します。さらに、OpenRouterの標準化されたAPI形式により、コードの変更なしにGLM-4.5と他の利用可能なモデル間の簡単なモデル切り替えとA/Bテストが可能になります。
OpenRouterの統一された課金システムにより、コスト管理がより透明になります。このシステムは、複数のモデルプロバイダーにわたる詳細な使用状況分析と支出管理を提供します。この一元化されたアプローチは、アプリケーションで複数のAIモデルを使用する組織の予算管理を簡素化します。
オープンソース展開のためのHugging Face Hub
Hugging Face HubはGLM-4.5モデルをホストしており、包括的なモデルカード、技術文書、コミュニティ主導の使用例を提供しています。このプラットフォームは、オープンソースのデプロイパターンを好む開発者や、広範なモデルカスタマイズを必要とする開発者にとって不可欠であることが証明されています。
Hugging Faceの統合により、Transformersライブラリを使用してローカルデプロイが可能になり、組織はモデルのホスティングとデータプライバシーを完全に制御できます。開発者はモデルの重みを直接ダウンロードし、カスタム推論パイプラインを実装し、特定のハードウェア環境に合わせてデプロイ構成を最適化できます。
セルフホスト型デプロイオプション
厳格なデータプライバシー要件や特殊なインフラストラクチャニーズを持つ組織は、セルフホスト型構成を使用してGLM-4.5モデルをデプロイできます。MITライセンスにより、プライベートクラウド環境、オンプレミスインフラストラクチャ、またはハイブリッドアーキテクチャ全体での無制限のデプロイが可能になります。
セルフホスト型デプロイは、モデルの動作、セキュリティ構成、および統合パターンに対する最大限の制御を提供します。組織は、外部依存関係なしに、カスタム認証システム、特殊な監視インフラストラクチャ、およびドメイン固有の最適化を実装できます。
DockerまたはKubernetesを使用したコンテナベースのデプロイにより、変化するワークロード要求に適応できるスケーラブルなセルフホスト型実装が可能になります。これらのデプロイパターンは、既存のコンテナオーケストレーションの専門知識を持つ組織にとって特に価値があることが証明されています。
Apidogを使用した開発ワークフローとの統合
現代のAI開発では、これらの様々なアクセス方法全体でモデルの統合、テスト、デプロイワークフローを効果的に管理するために、洗練されたツールが必要です。Apidogは、選択されたデプロイアプローチに関係なくGLM-4.5の統合を合理化する包括的なAPI管理機能を提供します。
OpenRouter、直接APIアクセス、Hugging Faceデプロイ、またはセルフホスト型構成のいずれであっても、異なるプラットフォームでGLM-4.5モデルを実装する際、開発者は多様なユースケース全体でパフォーマンスを検証し、異なるパラメータ構成をテストし、信頼性の高いエラー処理を確保する必要があります。ApidogのAPIテストフレームワークは、これらすべてのデプロイ方法にわたるモデル応答、レイテンシ特性、リソース利用パターンの体系的な評価を可能にします。
プラットフォームのドキュメント生成機能は、複数のアクセス方法を介してGLM-4.5を同時にデプロイする場合に特に価値があることが証明されています。開発者は、OpenRouter、直接API、セルフホスト型デプロイにわたるGLM-4.5のハイブリッド推論機能に特化した、モデル構成オプション、入出力スキーマ、使用例を含む包括的なAPIドキュメントを自動的に生成できます。
Apidog内のコラボレーション機能は、GLM-4.5の実装に取り組む開発チーム間の知識共有を促進します。チームメンバーは、テスト構成を共有し、ベストプラクティスを文書化し、モデルの有効性を最大化する統合パターンについて協力できます。
環境管理機能は、チームがOpenRouterのマネージドサービス、直接API統合、またはセルフホスト型実装のいずれを使用しているかに関わらず、開発、ステージング、および本番環境全体で一貫したGLM-4.5のデプロイを保証します。開発者は、再現可能なデプロイパターンを確保しながら、異なる環境ごとに個別の構成を維持できます。
実装戦略とベストプラクティス
GLM-4.5モデルを成功裏にデプロイするには、インフラストラクチャ要件、パフォーマンス最適化手法、およびモデルの有効性を最大化する統合パターンを慎重に考慮する必要があります。組織は、モデルの能力に対して特定のユースケースを評価し、最適なデプロイ構成を決定する必要があります。
ハードウェア要件はGLM-4.5とGLM-4.5 Airの間で大きく異なり、組織はインフラストラクチャの制約に合ったバリアントを選択できます。堅牢なGPUインフラストラクチャを持つチームは、最大の能力のためにフルGLM-4.5モデルを活用できますが、リソースが限られた環境では、GLM-4.5 Airがインフラストラクチャコストを削減しつつ十分なパフォーマンスを提供すると考えられます。
モデルのファインチューニングは、特殊な要件を持つ組織にとってもう一つの重要な考慮事項です。MITライセンスにより、包括的なモデルカスタマイズが可能になり、チームはGLM-4.5をドメイン固有のアプリケーションに適応させることができます。ただし、ファインチューニングは、最適な結果を達成するために慎重なデータセットキュレーションとトレーニングの専門知識を必要とします。
ハイブリッドモード構成では、応答速度と推論品質のバランスを取るために、慎重なパラメータチューニングが必要です。厳格なレイテンシ要件を持つアプリケーションは、より積極的な非思考モードのデフォルトを好むかもしれませんが、推論品質を優先するアプリケーションは、より低い思考モードのしきい値から恩恵を受けるかもしれません。
API統合パターンは、GLM-4.5のネイティブ関数呼び出し機能を活用して、効率的なエージェントワークフローを作成する必要があります。外部オーケストレーションレイヤーを実装する代わりに、開発者はモデルに組み込まれたツール使用機能に頼ることで、システムの複雑さを軽減し、信頼性を向上させることができます。
セキュリティに関する考慮事項とリスク管理
GLM-4.5のようなオープンソースモデルをデプロイすることは、組織が包括的なリスク管理戦略を通じて対処しなければならないセキュリティ上の考慮事項を伴います。モデルの重みが利用可能であることは、徹底的なセキュリティ監査を可能にする一方で、不正アクセスや誤用を防ぐために慎重な取り扱いも必要とします。
モデル推論のセキュリティは、モデルの動作を損なったり、トレーニングデータから機密情報を抽出したりする可能性のある敵対的入力から保護することを必要とします。組織は、潜在的に問題のあるインタラクションを特定するために、入力検証、出力フィルタリング、および異常検出システムを実装する必要があります。
GLM-4.5モデルを本番環境でホストする場合、デプロイインフラストラクチャのセキュリティが重要になります。ネットワーク分離、アクセス制御、暗号化などの標準的なセキュリティプラクティスは、従来のアプリケーションと同様にAIモデルのデプロイにも適用されます。
データプライバシーに関する考慮事項は、アプリケーションとGLM-4.5モデル間の情報フローに細心の注意を払う必要があります。組織は、機密データ入力が適切に保護され、モデル出力が意図せず機密情報を漏洩しないようにする必要があります。
サプライチェーンセキュリティは、モデルの来歴と整合性検証にまで及びます。組織は、モデルのチェックサムを検証し、ダウンロード元を確認し、デプロイされたモデルが意図した構成と一致することを保証する制御を実装する必要があります。
GLM-4.5のオープンソースの性質は、セキュリティ特性が不透明なプロプライエタリモデルと比較して利点を提供する包括的なセキュリティ監査を可能にします。組織は、ベンダーのセキュリティ主張に頼るのではなく、直接的な調査を通じてモデルアーキテクチャ、トレーニングデータ特性、および潜在的な脆弱性を分析できます。
結論
GLM-4.5とGLM-4.5 Airは、オープンソースAIの能力における大きな進歩を意味し、成功したオープンソースプロジェクトを定義するアクセシビリティと柔軟性を維持しつつ、競争力のあるパフォーマンスを提供します。Z.aiは、現実世界のデプロイ課題に対処するアーキテクチャ革新を通じて、オープンソースモデルでSOTAパフォーマンスを達成した次世代ベースモデルGLM-4.5をリリースしました。
ハイブリッド推論アーキテクチャは、思慮深い設計が応答速度と推論品質の間の従来のトレードオフをどのように解消できるかを示しています。この革新は、純粋なベンチマークパフォーマンスよりも実用的な有用性を優先する将来のモデル開発のテンプレートを提供します。
コスト効率の利点により、GLM-4.5はこれまで高度なAI機能が法外に高価だと感じていた組織でも利用できるようになりました。推論コストの削減と寛容なライセンスの組み合わせは、多様な産業や組織規模にわたるAIデプロイの機会を創出します。


