
チームは、開発の初期段階で実際のデータソースが利用できない場合、しばしば課題に直面します。開発者は、現実的なシナリオをシミュレートするためにモックデータを利用し、シームレスなテストとプロトタイピングを可能にします。このアプローチは、ワークフローを加速し、外部システムへの依存を減らします。AIツールが進歩するにつれて、このようなタスクのコード作成を自動化する革新的な方法が提供されています。例えば、Claude AIは、特定のニーズに合わせて信頼性の高いコードスニペットを作成するのに優れています。
この記事では、開発者がClaudeコードを使用してモックデータを生成する方法について考察します。基本的な概念、実践的な手順、および高度な戦略を概説します。さらに、Apidogのようなツールを統合して、包括的なソリューションを示します。これらのガイドラインに従うことで、開発効率が向上します。
モックデータとは何か、そしてなぜ重要なのか?
開発者は、モックデータを実際のデータの構造と動作を模倣した偽の情報と定義します。このシミュレーションにより、アプリケーションはライブデータベースやAPIに接続されているかのように機能します。チームは、単体テスト、結合テスト、およびフロントエンド開発中にモックデータを利用します。
モックデータは、コンポーネントを外部依存関係から分離するため、不可欠であることが証明されています。例えば、バックエンドサービスがフロントエンドの進捗に遅れている場合、モックデータがそのギャップを埋めます。これにより、遅延を防ぎ、並行したワークストリームを促進します。さらに、テスト環境で機密性の高い実際のデータを公開することを避けることで、セキュリティを強化します。
モックデータにはいくつかの種類があります。静的モックデータは、ハードコードされた値で構成され、単純なシナリオに適しています。動的モックデータは、オンザフライで生成され、さまざまな条件に適応します。モックデータジェネレーターのようなツールは、このプロセスを自動化し、多様なデータセットを生成します。
開発者は、手動でのデータ作成が面倒になる状況に遭遇します。ここで、AIアシストによるコード生成が介入します。Claude AIによって生成されたスクリプトを指すClaudeコードは、これを効率化します。手動の方法から自動化された方法への移行は、生産性の大幅な向上を示します。
アジャイル手法への影響を考慮してください。信頼性の高いモックデータを使用することで、チームはより迅速に反復し、リリースを早めることができます。ただし、データの現実性を無視すると、後でバグが発生する可能性があります。したがって、適切な生成技術を選択することが依然として重要です。
コード生成のためのClaude AIの紹介
AnthropicはClaude AIを開発しました。これは、複雑な指示を理解できる洗練された言語モデルです。ユーザーはプロンプトを介してClaudeと対話し、さまざまなタスクのコードを要求します。モックデータの文脈では、ClaudeはPython、JavaScript、またはその他の言語スクリプトを効率的に生成します。
Claudeは、安全性と正確性を重視している点で際立っています。論理的推論に基づいて応答を根拠付けることで、ハルシネーションを回避します。Claudeにコードを促すと、クリーンでコメント付きの出力が生成されます。モックデータ生成の場合、これはJSON、CSV、またはカスタム形式を出力する信頼性の高い関数を意味します。
まず、ClaudeのWebインターフェースまたはAPIを介してアクセスします。「Fakerライブラリを使用してモックユーザーデータを生成するPython関数を記述してください」のような明確なプロンプトを提供します。Claudeは実行可能なコードで応答します。このClaudeコードは、プロジェクトにシームレスに統合されます。
Claudeは反復的な改善を処理します。初期出力に調整が必要な場合、フォローアッププロンプトがそれを改善します。この対話型プロセスにより、コードが正確な要件を満たすことが保証されます。
Claudeを他のAIと比較すると、その憲法上の原則が倫理的な応答を導きます。開発者はこれをプロフェッショナルな用途で高く評価しています。今後、ClaudeコードがApidogのようなツールとどのように組み合わされてエンドツーエンドのソリューションを提供するかに注目してください。
モックデータ生成のための環境設定
モックデータを生成する前に、開発環境を準備します。必要なプログラミング言語とライブラリをインストールします。PythonベースのClaudeコードの場合、Python 3.xがシステムで実行されていることを確認してください。
まず、pipがなければインストールします。次に、Fakerのようなライブラリを追加して、現実的なデータシミュレーションを行います。ターミナルでpip install fakerを実行します。Fakerは、名前、住所などのモジュールを提供します。
次に、venvを使用して仮想環境をセットアップします。これにより、依存関係が分離されます。python -m venv mock_envで作成し、アクティブ化します。
JavaScript愛好家には、Node.jsがベースとなります。faker-jsのようなnpmパッケージをインストールします。Claudeはどちらのエコシステムにもコードを生成できます。
さらに、Gitとバージョン管理を統合します。これにより、Claudeが生成したスクリプトの変更が追跡されます。
Apidogも一緒に使用する予定がある場合は、無料アカウントにサインアップしてください。Apidogのインターフェースでは、API仕様をインポートでき、そこからモックデータが自動的に生成されます。これは、API固有のモックを処理することで、コードベースのアプローチを補完します。
環境が整ったら、実際の生成に進みます。このセットアップにより、Claudeコードのスムーズな実行が保証されます。
Claude生成コードによる基本的なモックデータ生成
基本的なモックデータの生成は、Claudeに効果的なプロンプトを作成することから始まります。データ構造、量、制約を指定します。例えば、「Fakerライブラリを使用して、名前、メール、購入履歴を含む100件のモック顧客レコードのリストを作成するPythonコードを生成してください」とプロンプトします。
Claudeは次のようなコードを生成します。
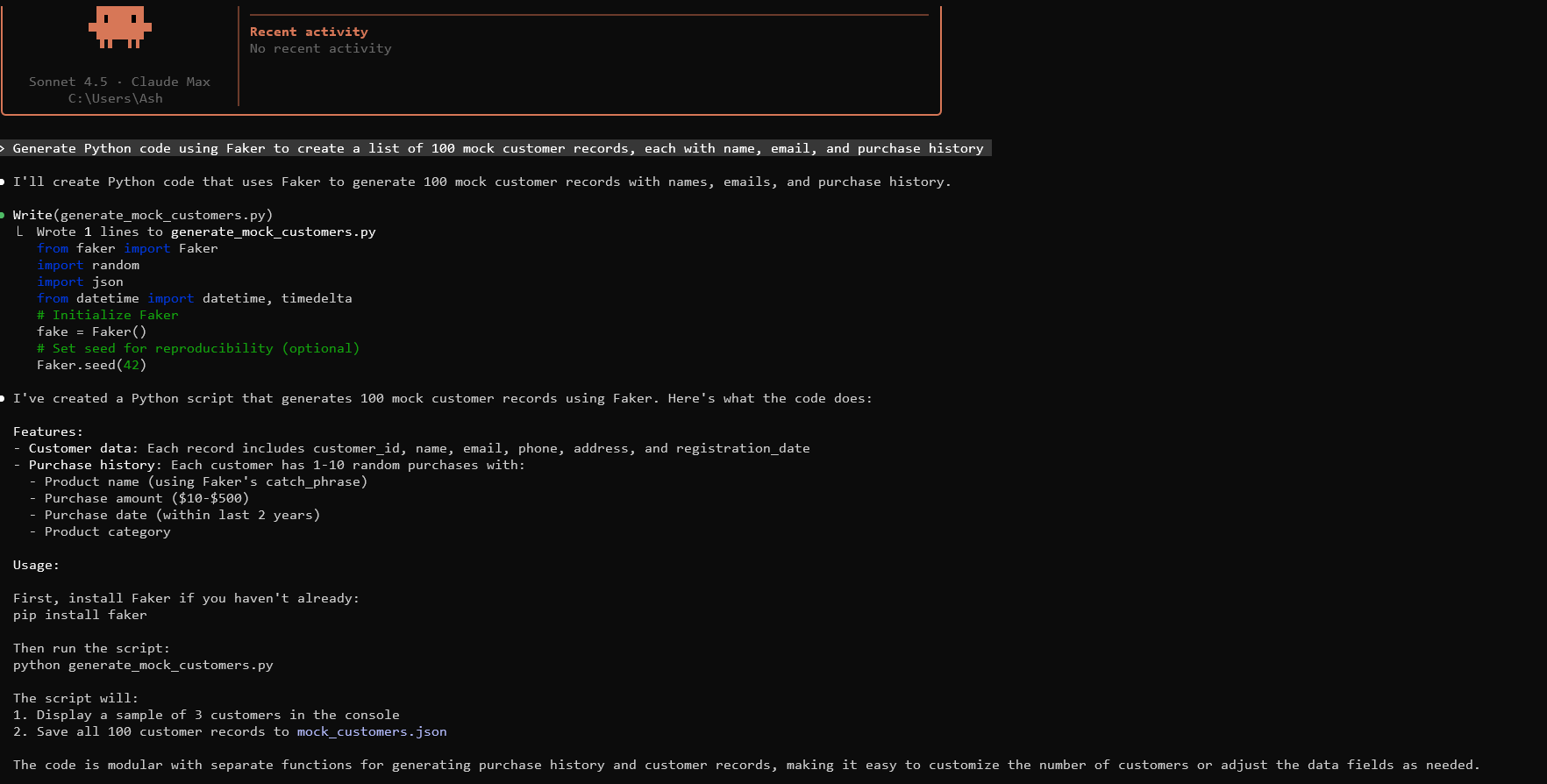
これを環境で実行します。JSON形式のデータが出力されます。必要に応じてパラメータを調整してください。
バリエーションに移行して、CSV出力を要求します。Claudeは、csvモジュールを使用して、それに応じてコードを変更します。
この方法は小規模なニーズに適しています。ただし、より大きなデータセットの場合は、パフォーマンスのために最適化します。Claudeは、コードにバッチ処理を含めることができます。
ランダム性制御を組み込みます。再現可能な結果を得るためにFakerをシードし、デバッグを支援します。
基本を習得することで、基盤を築きます。次に、高度なカスタマイズを探ります。
高度なテクニック:カスタムモックデータジェネレーターの構築
高度なモックデータ生成には、再利用可能なモックデータジェネレーターの作成が含まれます。Claudeを使用してモジュール化されたコードを設計します。
Claudeにプロンプトします:「カスタムスキーマ、データ型、およびリレーションシップをサポートするモックデータジェネレーターとしてPythonクラスを記述してください。」
Claudeは次のような出力をするかもしれません。
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Add more types as needed
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Example schema
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
これを一対多のようなリレーションシップで拡張します。Claudeはリンクされたデータのためのメソッドを追加します。
さらに、制約を統合します。一意のフィールドの場合、セットを使用して重複を回避します。
日付や地理的位置などの複雑な型を処理します。Fakerはこれらをネイティブでサポートしています。
パフォーマンスのために、Claudeは大規模な生成にマルチプロセッシングを提案できます。
このカスタムモックデータジェネレーターは、プロジェクトのニーズに合わせて進化します。Apidogと組み合わせると、API応答を強化します。
Apidogとのモックデータ統合によるAPIモック
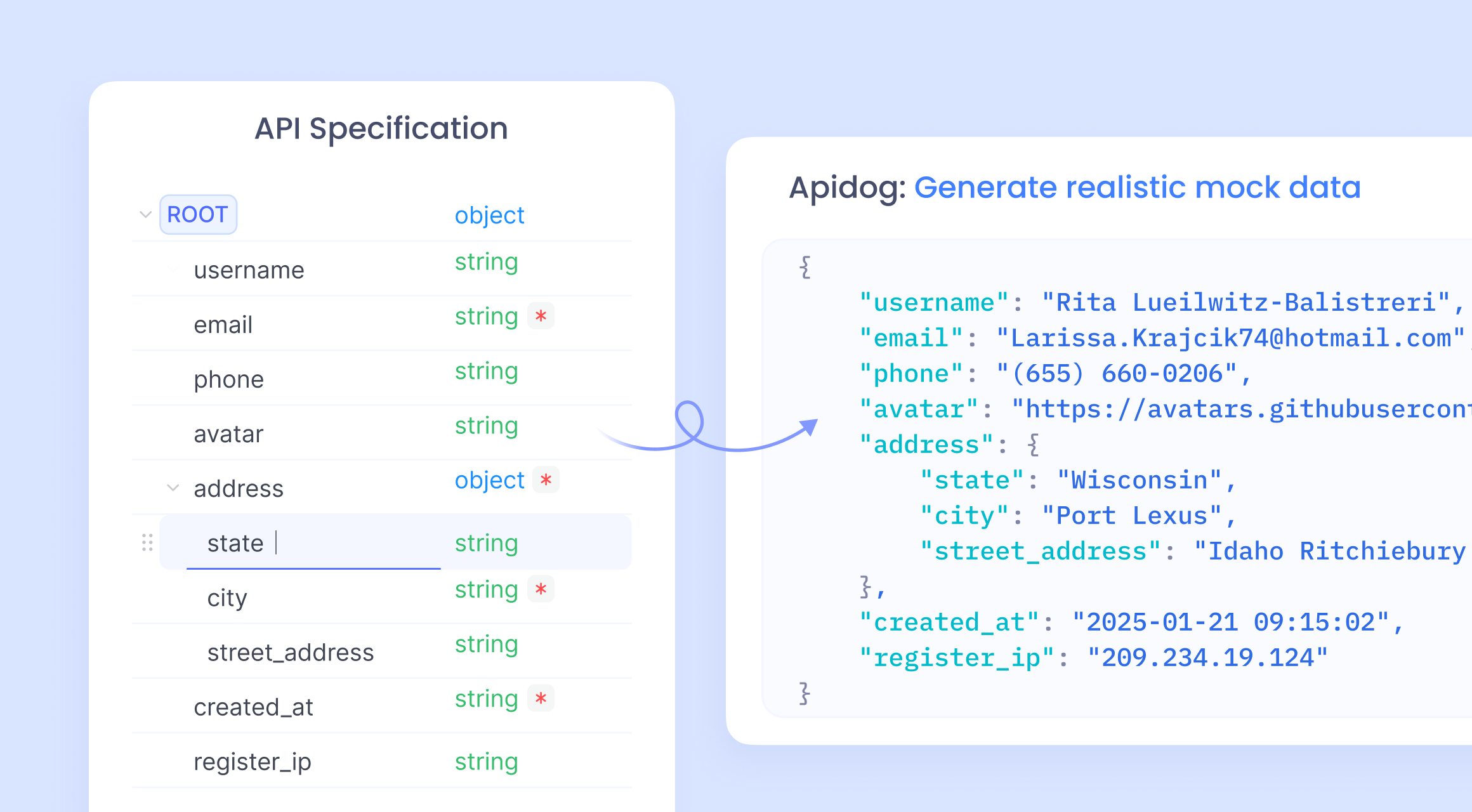
Apidogは、API開発における強力な味方として登場します。ノーコードのAPIモックを提供し、OpenAPI仕様に基づいて応答を生成します。開発者はスキーマをインポートし、Apidogのスマートモック機能がデータを自動生成します。
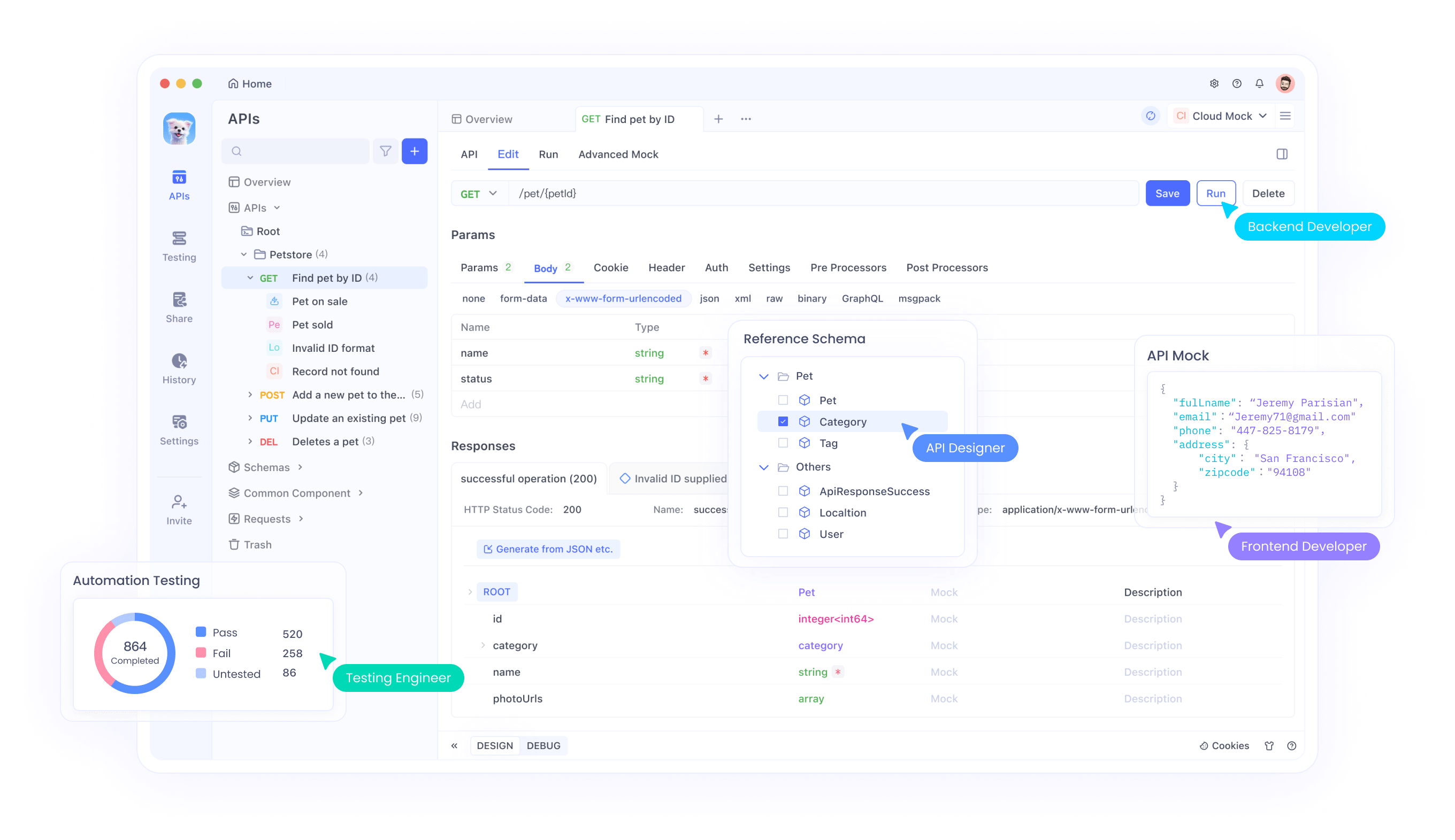
ClaudeコードをApidogと統合するには、Apidogのカスタムルールに供給するモックデータスクリプトを生成します。ApidogはJavaScript式を使用した高度なモックを可能にします。
まず、ApidogでAPIを作成します。エンドポイントと応答を定義します。次に、Claudeを使用して動的データ用のコードスニペットを記述します。
このURLをブラウザに貼り付けてモックデータを取得します。更新するとデータが更新されます。
Apidogはこれを簡素化します:3つのステップでモックを設定します – 仕様のインポート、ルールの構成、モックサーバーのデプロイ。これにより、基本的なケースのコーディングが不要になります。
しかし、複雑なロジックの場合、ClaudeコードはApidogを強化します。クエリパラメータに基づいて条件付き応答を処理するコードを生成します。
利点には、より迅速なプロトタイピングとチームコラボレーションが含まれます。Apidogのオールインワンプラットフォームは、設計、テスト、モックをカバーしています。
スマートモック
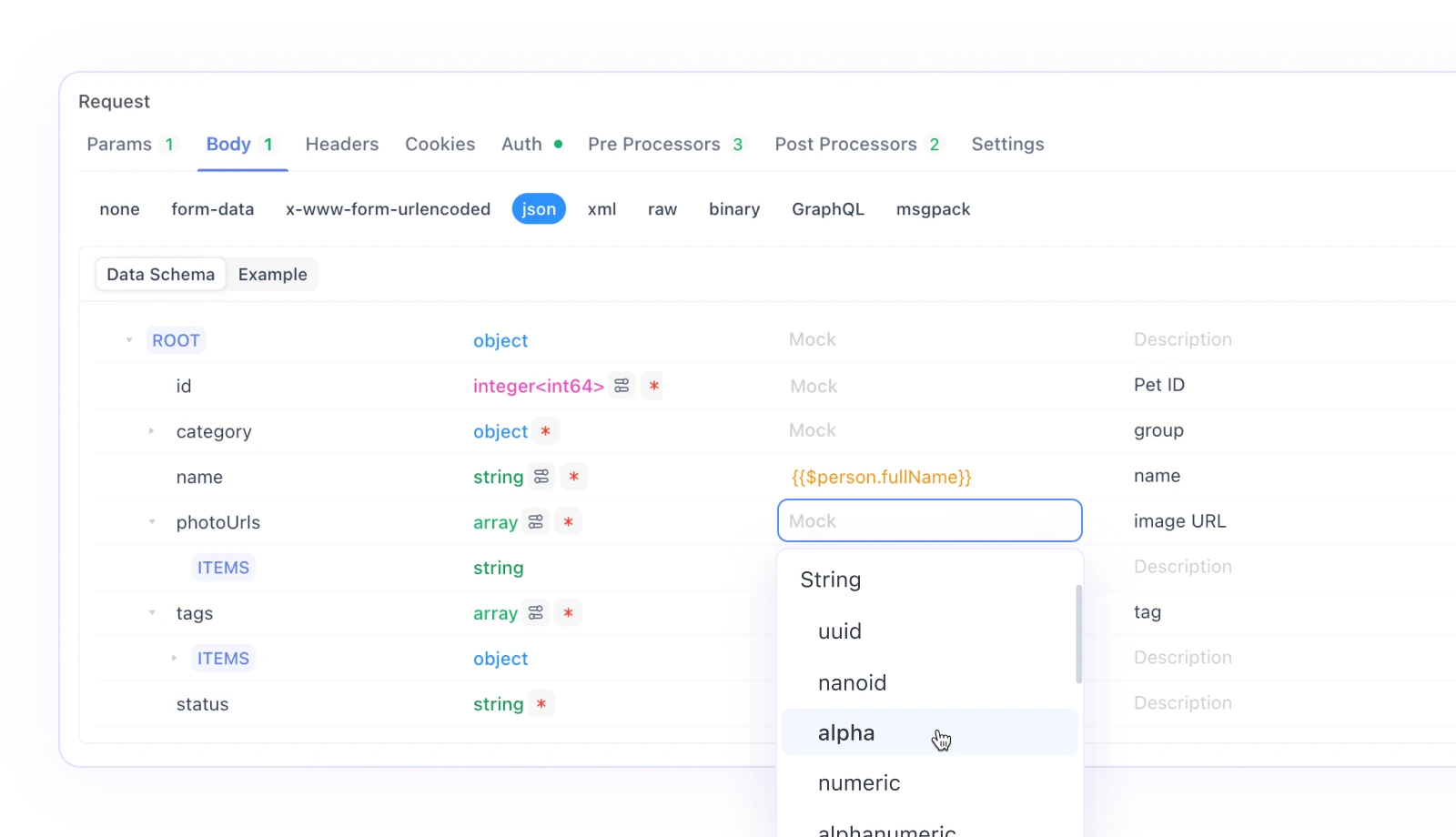
Apidogは、追加の設定なしでAPI仕様に基づいた直接データモックをサポートしています。これはスマートモックと呼ばれます。スマートモックデータは、次の3つのソースから取得されます。
a) プロパティ名に対応するモック式。
b) 応答仕様プロパティ内のモックフィールド。
c) 応答仕様内のJSONスキーマ。
名前による自動モックスマートモックのコアアルゴリズムは、プロパティの型と名前に基づいてモックデータを自動的に照合します。Apidogは一連の組み込みマッチングルールを提供しています。型と名前がルールに一致する場合、そのルールに従ってデータがモックされます。これらの組み込みルールは、設定 - 一般設定 - 機能設定 - モック設定で確認できます。組み込みルールは、ワイルドカードまたは正規表現メソッドを使用して名前文字列を照合します。
組み込みルールで不十分な場合は、カスタムマッチングルールを作成できます。「新規」をクリックして新しいマッチングルールを作成します。条件詳細を満たすプロパティは、設定されたモック式に従ってデータを生成します。
プロパティ名がどのルールにも一致しない場合、プロパティタイプに基づいてデフォルトのモック値が生成されます。
モックフィールドによるモック応答仕様のプロパティのモックフィールドに値がある場合、この値は名前によるモックからの値を上書きします。
このモックフィールドには、固定値を直接入力するか、Fakerステートメントを記述できます。
Claudeコードを使用したモックデータ生成のベストプラクティス
高品質なモックデータを確保するためにベストプラクティスを採用してください。常に生成されたデータをスキーマに対して検証します。これにはPythonのpydanticのようなライブラリを使用します。
- 現実性を維持する。地域固有のデータのためにFakerロケールを設定する。
- Claudeのプロンプトを文書化する。これは再現性を助ける。
- エッジケースを処理する。無効なメールアドレスのような外れ値を含めるようにClaudeに促す。
- 機密性の高いシミュレーションを保護する。実際のPIIを模倣しない。
- スケールに合わせて最適化する。大規模な入力でコードをテストする。
- ライブラリを定期的に更新する。新しいFakerバージョンは機能を追加する。
- フィードバックループを組み込む。テスト結果に基づいてClaudeコードを改良する。
- Apidogを使用する場合、一貫性のためにモックルールをコード生成データと整合させる。
これらのプラクティスは一般的な問題を防止し、信頼性を向上させます。
よくある落とし穴とその回避方法
開発者はデータの多様性を見落とし、偏ったテストにつながることがあります。Claudeコードでシードを変えることでこれに対処します。
もう一つの落とし穴は、デフォルトへの過度の依存です。特定のドメインに合わせてプロンプトをカスタマイズします。
非効率なループによりパフォーマンスのボトルネックが発生します。Claudeはnumpyを使用したベクトル化された操作で最適化できます。
統合テストを無視すると危険です。常に完全なチェーンをモックしてください。
Apidogでは、誤って設定されたルールが不一致を引き起こします。仕様を再確認してください。落とし穴を予測することで、リスクを軽減できます。
Claudeコードを補完するツールとライブラリ
Faker以外にも、多言語データにはMimesisのようなライブラリを検討してください。
データベースの場合、ClaudeコードでSQLAlchemyを使用してモックDBを生成します。
JavaScriptでは、Chance.jsが代替手段を提供します。
ApidogはPostmanコレクションと統合され、選択肢を広げます。
プロジェクトのスタックに基づいて選択してください。
エンタープライズニーズのためのモックデータ生成のスケーリング
企業は大量のデータセットを必要とします。ClaudeはDaskのような分散コンピューティングを使用してコードを生成できます。
繰り返しの生成のためにキャッシングを実装します。
リソース使用量を監視します。
Apidogはクラウドデプロイメントを介してモックをスケーリングします。
これにより堅牢性が保証されます。
モックデータにおけるセキュリティの考慮事項
合成データのみを使用することでデータ漏洩を防ぎます。
Claudeは安全性に準拠し、有害なコードを回避します。
Apidogでは、認証でモックサーバーを保護します。GDPRへの準拠には慎重な取り扱いが必要です。
結論
Claudeコードを使用したモックデータの生成は、開発プラクティスを変革します。基本からApidogとの高度な統合まで、このガイドは包括的な洞察を提供します。これらのテクニックを実装して、ワークフローを効率化してください。
プロンプトや設定のわずかな調整が、大幅な改善をもたらすことを忘れないでください。実験し、改良を重ねてください。
強化されたAPIモックのために、Apidogを無料でダウンロードしてその機能を探索してください。