
開発者は、高度なAIモデルをアプリケーションに統合するための効率的な方法を常に模索しています。Gemini 3 Flash APIは、高い知能と速度、費用対効果のバランスが取れた強力なオプションを提供します。
Googleは、生成AIの提供を継続的に進化させています。さらに、Gemini 3 Flashモデルは現在のラインナップの中で際立っています。エンジニアはGemini APIを介してこれにアクセスし、迅速なプロトタイピングと本番環境へのデプロイを可能にします。
Gemini APIキーの取得
まず、APIキーを取得することから始めます。最初に、aistudio.google.comにあるGoogle AI Studioにアクセスします。必要に応じてGoogleアカウントでサインインしてください。次に、利用可能なオプションからGemini 3 Flashプレビューモデルを選択します。その後、APIキーを生成するオプションをクリックします。
Googleはこのキーを即座に提供します。さらに、機密情報として扱い、安全に保管してください。すべてのリクエストでx-goog-api-keyヘッダーにこれを使用します。あるいは、スクリプトでの利便性のために環境変数として設定することもできます。
有効なキーがない場合、リクエストは認証エラーにより即座に失敗します。そのため、Google AI Studioのインタラクティブインターフェースでテストすることにより、キーの機能を早期に確認してください。
Gemini 3 Flashの機能の理解
Gemini 3 Flashは、Flashの速度でプロレベルの知能を提供します。具体的には、プレビュー期間中、モデルIDはgemini-3-flash-previewのままです。これは、1,048,576トークンの大規模な入力コンテキストウィンドウと、65,536トークンの出力制限をサポートします。
さらに、マルチモーダル入力を効果的に処理します。テキスト、画像、ビデオ、オーディオ、PDFを提供できます。出力は主にテキストで構成され、スキーマ強制による構造化JSONのオプションもあります。
主な機能には、組み込みの推論制御が含まれます。開発者は、thinking_levelパラメーターを使用して思考の深さを調整します: minimal、low、medium、または high (デフォルト)。highは推論の品質を最大化し、低いレベルでは高スループットシナリオでのレイテンシーを優先します。
さらに、ビジョンタスクのメディア解像度を制御します。オプションはlowからultra_highまであり、フレームまたは画像あたりのトークン消費に影響を与えます。適切に選択してください — 詳細な画像にはhigh、ドキュメントにはmediumです。
このモデルは、Google検索のグラウンディング、コード実行、関数呼び出しなどのツールを統合しています。ただし、画像生成や特定の高度なロボティクスツールは除外されています。
Gemini 3 Flash APIの料金
API統合においてコスト管理は重要です。Gemini 3 Flashは従量課金制モデルで動作します。入力トークンは100万トークンあたり$0.50、出力トークン(思考トークンを含む)は100万トークンあたり$3です。
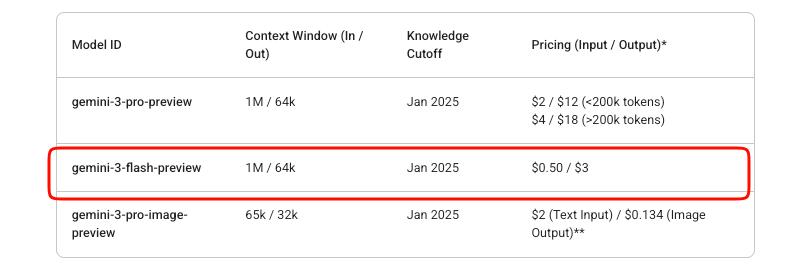
GoogleはAI Studioで無料の実験を提供しています。ただし、本番APIの使用は、課金が有効になると料金が発生します。このプレビューモデルには、Studio試用版以外の無料枠は存在しません。
コンテキストキャッシングとバッチ処理は、コストをさらに最適化するのに役立ちます。キャッシングは、繰り返されるコンテキストの冗長なトークン処理を削減します。バッチAPIは、非同期の大容量ジョブに適しています。
Google Cloud Billingダッシュボードを介して使用状況を監視してください。急激な使用量増加は、多くの場合、高いmedia_resolution設定または広範な推論に起因します。
最初のAPIリクエストの作成
まず、単純なテキスト生成から始めます。エンドポイントはhttps://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContentです。
POSTリクエストを構築します。APIキーをヘッダーに含めます。ボディには、role-partオブジェクトの配列としてコンテンツが含まれます。
基本的なcURLの例は次のとおりです。
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-X POST \
-d '{
"contents": [{
"parts": [{"text": "Explain quantum entanglement briefly."}]
}]
}'
レスポンスはテキストパートを含む候補を返します。さらに、トークン数の使用状況メタデータを処理します。
ストリーミングレスポンスの場合、:streamGenerateContentエンドポイントを使用します。これにより、部分的な結果が段階的に生成され、アプリケーションの体感レイテンシーが向上します。
公式SDKとの統合
Googleは、インタラクションを簡素化するSDKを維持しています。pip install google-generativeaiでPythonパッケージをインストールします。
クライアントを初期化します。
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-flash-preview")
response = model.generate_content("Summarize recent AI advancements.")
print(response.text)
SDKは、複数ターンの会話やツールの使用における思考シグネチャを自動的に管理します。したがって、本番コードでは生のHTTPよりもSDKを推奨します。
Node.jsユーザーは、@google/generative-aiを通じて同様の利便性を利用できます。
マルチモーダル入力の処理
Gemini 3 Flashはマルチモーダル処理に優れています。ファイルをアップロードするか、インラインデータURIを提供します。
Pythonの場合:
model = genai.GenerativeModel("gemini-3-flash-preview")
image = genai.upload_file("diagram.png")
response = model.generate_content(["Describe this image in detail.", image])
print(response.text)
トークン効率のために、生成設定でmedia_resolutionを調整します。
generation_config = {
"media_resolution": "media_resolution_high"
}
ビデオやPDFも同様のパターンに従います。さらに、複雑な分析タスクのために、複数のモダリティを1つのリクエストに組み合わせることもできます。
高度な機能:思考レベルとツール
推論を明示的に制御します。高速な応答のためにthinking_levelを"low"に設定します。
"generationConfig": {
"thinking_level": "low"
}
高レベルの思考は、内部でのより深い思考連鎖処理を可能にします。
関数呼び出しのようなツールを有効にします。リクエストで関数を定義すると、モデルは適切な場合に呼び出しを返します。
構造化された出力はJSONスキーマを強制します。
"generationConfig": {
"response_mime_type": "application/json",
"response_schema": {...}
}
これらを組み合わせてエージェントワークフローを構築します。たとえば、リアルタイム検索で応答をグラウンディングします。
Apidogでのテストとデバッグ
効果的なテストは、信頼性の高い統合を保証します。Apidogは、この目的のための堅牢なツールとして登場しました。API設計、デバッグ、モック、自動テストを一つのプラットフォームに統合しています。
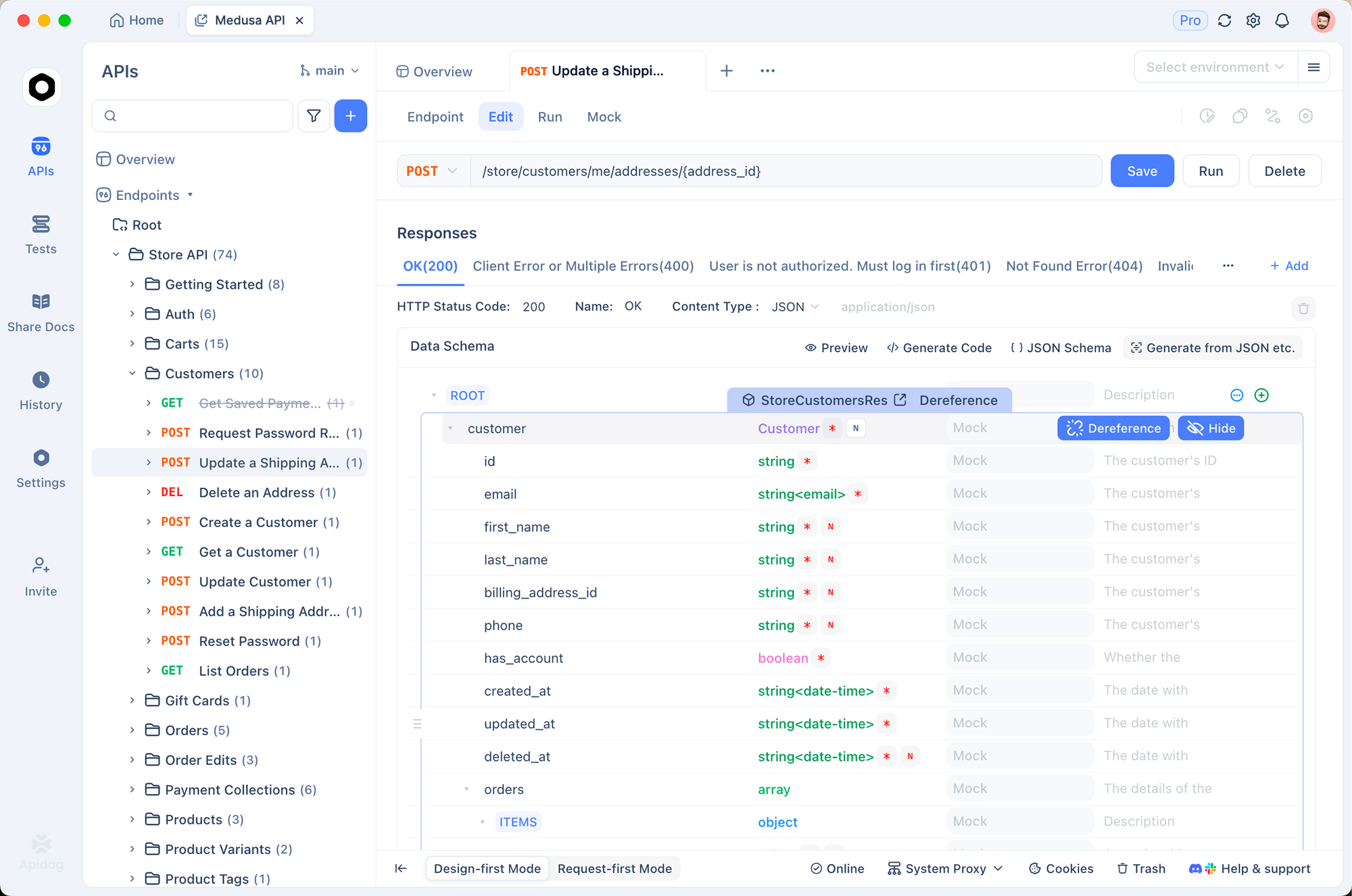
まず、GeminiエンドポイントをApidogにインポートします。generateContentメソッドを指す新しいリクエストを作成します。APIキーを環境変数として保存します。Apidogは、開発、ステージング、本番用の複数の環境をサポートしています。
リクエストを視覚的に送信します。Apidogは応答を明確に表示し、トークン使用量とエラーを強調表示します。さらに、応答構造を自動的に検証するためにアサーションを設定します。
複数ターンのチャットの場合、Apidogのスクリプトまたは変数を使用して、リクエスト間で会話履歴を維持します。これにより、実際のユーザーセッションを効率的にシミュレートできます。
Apidogはモックサーバーも生成します。クォータを消費することなく、フロントエンド開発中にGeminiの応答をシミュレートします。
さらに、テストスイートを自動化します。異なる思考レベル、マルチモーダル入力、エラーケースをカバーするシナリオを定義します。それらをCI/CDパイプラインで実行します。
多くの開発者は、Apidogが生のcURLや基本的なクライアントと比較してデバッグ時間を大幅に削減することを見出しています。その直感的なインターフェースは、複雑なJSONボディを楽に処理します。
本番環境でのベストプラクティス
指数関数的バックオフを用いたリトライロジックを実装します。特にプレビュー版ではレート制限が適用されます。
トークンを最小限に抑えるために、可能な限りコンテキストをキャッシュします。検証エラーを避けるために、生のAPIリクエストでは思考シグネチャを正確に使用します。
コストを積極的に監視します。リクエストごとの入出力トークン数をログに記録します。
温度はデフォルトの1.0に保ちます。逸脱すると推論性能が低下します。
最後に、公式ドキュメントを通じて最新情報を入手してください。プレビューモデルは進化します。潜在的な互換性のない変更に備えて計画してください。
結論
これで、Gemini 3 Flashを効果的に統合するための知識が身につきました。シンプルなリクエストから始め、マルチモーダルでツールを強化したアプリケーションへとスケールアップしてください。Apidogのようなツールを活用して、開発ワークフローを効率化しましょう。
Gemini 3 Flashは、開発者がインテリジェントで応答性の高いシステムを低コストで構築することを可能にします。AI Studioで自由に実験し、その後、デプロイのためにAPIに移行してください。