
データを任意のウェブサイトから抽出し、スケールで洞察を得る能力を想像してみてください—すべて数行のコードで実現できます。まるで魔法のようですよね?実際に、Firecrawlがこれを可能にします。
この初心者向けガイドでは、Firecrawlについて知っておくべきすべてのことを、インストールから高度なデータ抽出技術まで案内します。あなたが開発者であれ、データアナリストであれ、ウェブスクレイピングに興味があるだけの方であれ、このチュートリアルはFirecrawlの使い始めとワークフローへの統合を手助けします。

Firecrawlとは?
Firecrawlは、ウェブサイトのコンテンツをマークダウン、HTML、構造化データなどの形式に変換する革新的なウェブスクレイピングおよびクロールエンジンです。これは大規模言語モデル(LLM)やAIアプリケーションに最適です。Firecrawlを使用すれば、ウェブサイトから構造化データと非構造化データの両方を効率的に収集し、データ分析のワークフローを簡素化できます。
Firecrawlの主な機能
クロール:包括的なウェブクロール
Firecrawlの/crawlエンドポイントを使用すると、ウェブサイトを再帰的にトラバースし、すべてのサブページからコンテンツを抽出できます。この機能は、大量のウェブデータを発見して整理し、LLM対応形式に変換するのに最適です。
スクレイプ:ターゲットデータ抽出
スクレイプ機能を使って、単一のURLから特定のデータを抽出します。Firecrawlは、マークダウン、構造化データ、スクリーンショット、HTMLを含むさまざまな形式でコンテンツを提供できます。これは、既知のURLから特定の情報を抽出するのに特に便利です。
マップ:迅速なサイトマッピング
マップ機能は、特定のウェブサイトに関連するすべてのURLを迅速に取得し、その構造の包括的な概要を提供します。これはコンテンツの発見と整理にとって非常に貴重です。
抽出:非構造化データを構造化フォーマットに変換
/extractエンドポイントは、FirecrawlのAIを活用した機能で、ウェブサイトから構造化データを収集するプロセスを簡素化します。これにより、クロール、解析、データを構造化された形式に整理する重労働を行います。
Firecrawlの始め方
ステップ1:サインアップしてAPIキーを取得
Firecrawlの公式ウェブサイトにアクセスしてアカウントにサインアップします。ログインしたら、ダッシュボードに移動してAPIキーを見つけます。
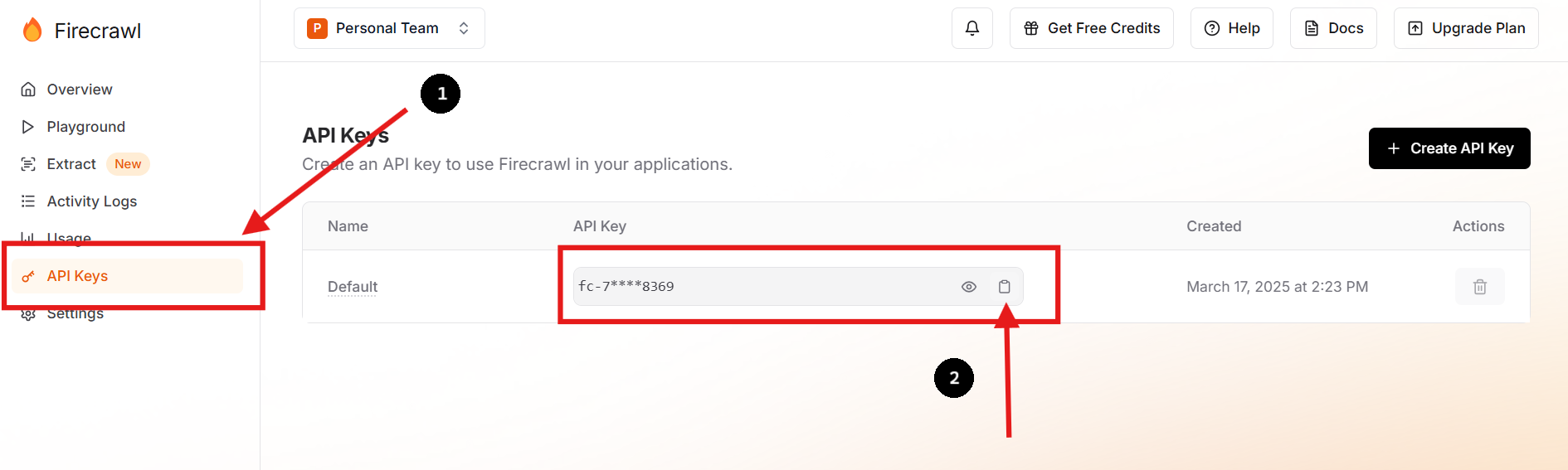
必要に応じて新しいAPIキーを作成し、以前のものを削除することもできます。

ステップ2:環境を設定
プロジェクトのディレクトリ内に.envファイルを作成し、APIキーを環境変数として安全に保存します。次のコマンドをターミナルで実行することでこれを行うことができます:
touch .env
echo "FIRECRAWL_API_KEY='fc-YOUR-KEY-HERE'" >> .envこの方法は、重要な情報をメインのコードベースから隠し、安全性を高め、設定管理を簡素化します。
ステップ3:Firecrawl SDKをインストール
Pythonユーザーは、pipを使ってFirecrawl SDKをインストールします:
pip install firecrawl ステップ4:Firecrawlの"スクレイプ"機能を使用
Python SDKを使用してウェブサイトをスクレイピングする方法の簡単な例を示します:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .envファイルから環境変数をロード
load_dotenv()
# .envからAPIキーを使用してFirecrawlAppを初期化
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# スクレイプするURLを定義
url = "https://www.python-unlimited.com/webscraping/hotels.php?page=1"
# ウェブサイトをスクレイプ
response = app.scrape_url(url)
# レスポンスを表示
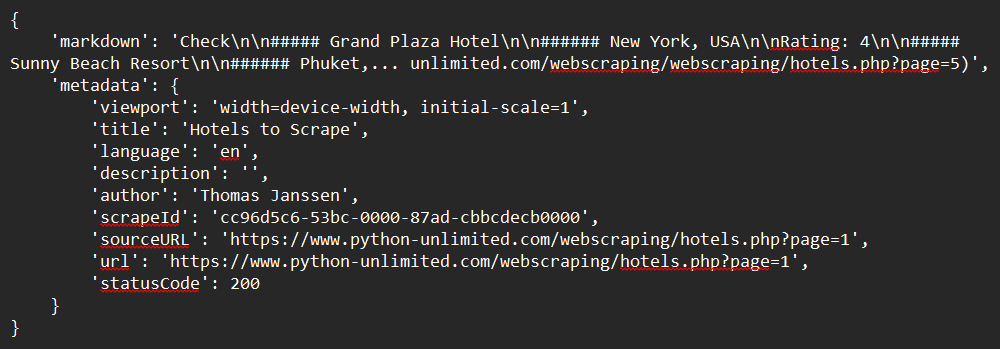
print(response)サンプル出力:
ステップ5:Firecrawlの"クロール"機能を使用
Python SDKを使用してウェブサイトをクロールする方法の簡単な例を示します:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .envファイルから環境変数をロード
load_dotenv()
# .envからAPIキーを使用してFirecrawlAppを初期化
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# ウェブサイトをクロールし、レスポンスを取得:
crawl_status = app.crawl_url(
'https://www.python-unlimited.com/webscraping/hotels.php?page=1',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
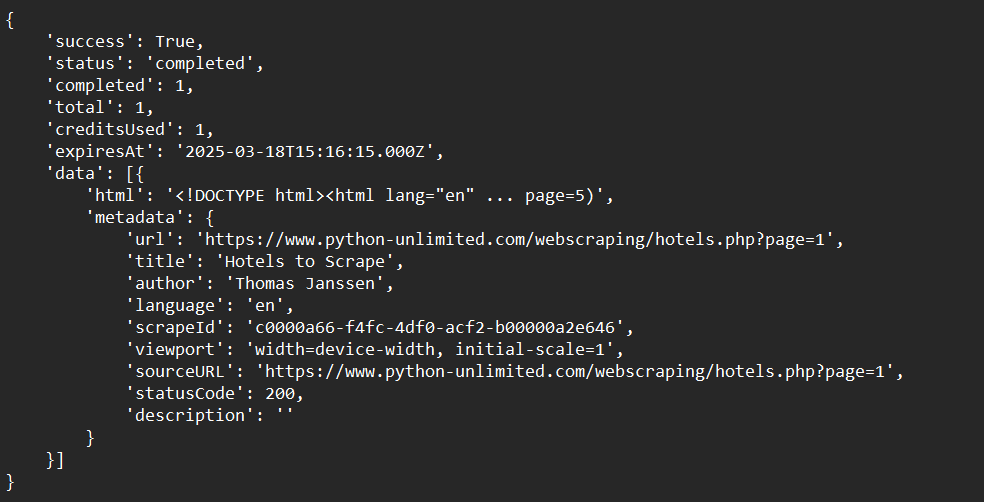
print(crawl_status)サンプル出力:
ステップ6:Firecrawlの"マップ"機能を使用
Python SDKを使用してウェブサイトデータをマッピングする方法の簡単な例を示します:
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# .envファイルから環境変数をロード
load_dotenv()
# .envからAPIキーを使用してFirecrawlAppを初期化
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
# ウェブサイトをマップ:
map_result = app.map_url('https://www.python-unlimited.com/webscraping/hotels.php?page=1')
print(map_result)サンプル出力:

ステップ7:Firecrawlの"抽出"機能を使用(オープンベータ)
以下は、Python SDKを使用してウェブサイトデータを抽出する方法の簡単な例です:
from firecrawl import FirecrawlApp
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import os
# .envファイルから環境変数をロード
load_dotenv()
# .envからAPIキーを使用してFirecrawlAppを初期化
app = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
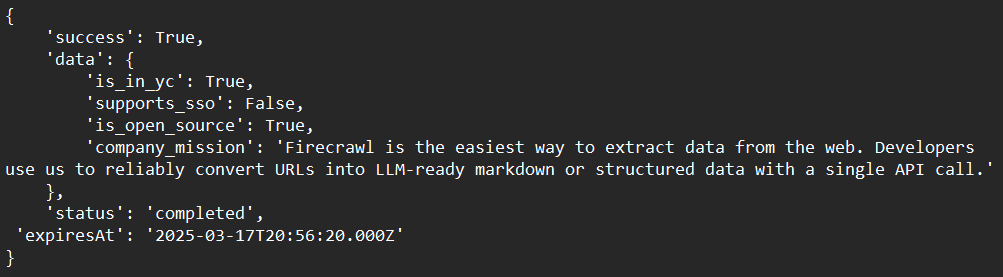
# 抽出する内容のスキーマを定義
class ExtractSchema(BaseModel):
company_mission: str
supports_sso: bool
is_open_source: bool
is_in_yc: bool
# 抽出関数を呼び出してレスポンスを取得
response = app.extract([
'https://docs.firecrawl.dev/*',
'https://firecrawl.dev/',
'https://www.ycombinator.com/companies/'
], {
'prompt': "スキーマに提供されたデータを抽出します。",
'schema': ExtractSchema.model_json_schema()
})
# レスポンスを表示
print(response)サンプル出力:
Firecrawlの高度な技術
動的コンテンツの処理
Firecrawlは、ヘッドレスブラウザを使用してページをレンダリングすることで、動的なJavaScriptベースのコンテンツを処理できます。これにより、動的に読み込まれるコンテンツもすべてキャプチャできます。
ウェブスクレイピングブロッカーの回避
Firecrawlの組み込み機能を使用して、CAPTCHAやレート制限などの一般的なウェブスクレイピングブロッカーを回避します。これには、ユーザーエージェントやIPアドレスを回転させて自然なトラフィックを模倣することが含まれます。
LLMとの統合
FirecrawlをLangChainなどのLLMと組み合わせて、強力なAIワークフローを構築します。例えば、Firecrawlを使ってデータを収集し、それをLLMに供給して分析や生成タスクを行うことができます。
一般的な問題のトラブルシューティング
問題:"APIキーが認識されない"
解決策:APIキーが環境変数または.envファイルに正しく保存されていることを確認してください。
問題:"クロールが遅すぎる"
解決策:非同期クロールを使用してプロセスを高速化します。Firecrawlは、効率を高めるために同時リクエストをサポートしています。
問題:"コンテンツが正しく抽出されない"
解決策:ウェブサイトが動的コンテンツを使用しているかどうかを確認します。その場合、FirecrawlがJavaScriptのレンダリングを処理できるように設定されていることを確認してください。
結論
この包括的な初心者向けガイドを完了したことをお祝いしますFirecrawl!私たちは、Firecrawlが何であるか、詳細なインストール手順、使用例、高度なカスタマイズオプションまで、すべてをカバーしました。今や、以下のことを明確に理解しているはずです:
- Firecrawlを開発環境に設定・インストールすること
- Firecrawlを構成・実行して、データを効率的にスクレイピング、クロール、マッピング、抽出すること
- 特定のニーズを満たすために、クロールプロセスをトラブルシューティングすること
Firecrawlは、データ抽出ワークフローを大幅に効率化できる非常に強力なツールです。その柔軟性、効率性、および統合の容易さは、現代のウェブクロールの課題に対する理想的な選択肢です。
さあ、あなたの新しいスキルを実践に移す時です。さまざまなウェブサイトで実験を始め、パーサーを調整し、追加ツールと統合して、あなたのユニークな要件に合ったカスタマイズされたソリューションを作成してください。
ウェブスクレイピングのワークフローを10倍にする準備はできましたか?今日Apidogを無料でダウンロードして、Firecrawlとの統合をどのように強化できるかを発見してください!