
ElevenLabsはテキストを自然な音声に変換し、幅広い音声、言語、スタイルに対応しています。このAPIを利用すると、アプリへの音声埋め込み、ナレーションパイプラインの自動化、音声エージェントのようなリアルタイム体験の構築が容易になります。HTTPリクエストを送信できるなら、数秒で音声を生成できます。
button
ElevenLabs APIとは?
ElevenLabs APIは、音声を生成、変換、分析するAIモデルへのプログラムによるアクセスを提供します。このプラットフォームはテキスト読み上げサービスとして始まりましたが、完全なオーディオAIスイートへと拡大しました。
主要な機能:
- テキスト読み上げ (TTS):書かれたテキストを、声の特徴、感情、ペースを制御しながら音声に変換します
- 音声変換 (STS):元のイントネーションとタイミングを保持したまま、ある音声を別の音声に変換します
- 音声クローン:わずか60秒のクリアな音声から、あらゆる音声のデジタルレプリカを作成します
- AIダビング:話者の声の特徴を維持したまま、オーディオ/ビデオコンテンツを異なる言語に翻訳・ダビングします
- 効果音:テキスト記述から効果音を生成します
- 音声認識:音声を高い精度でテキストに転写します
このAPIは標準のHTTPおよびWebSocketプロトコル上で動作します。どの言語からも呼び出すことができますが、PythonおよびJavaScript/TypeScript向けには、型安全性とストリーミングサポートが組み込まれた公式SDKが提供されています。
ElevenLabs APIキーの取得
APIコールを行う前に、APIキーが必要です。取得方法は以下の通りです。
ステップ1:無料アカウントを作成します。無料プランでも、毎月10,000文字のAPIアクセスが含まれています。
ステップ2:ログインし、「プロフィール + APIキー」セクションに移動します。これは左下隅のプロフィールアイコンをクリックするか、開発者設定に直接アクセスすることで見つけることができます。
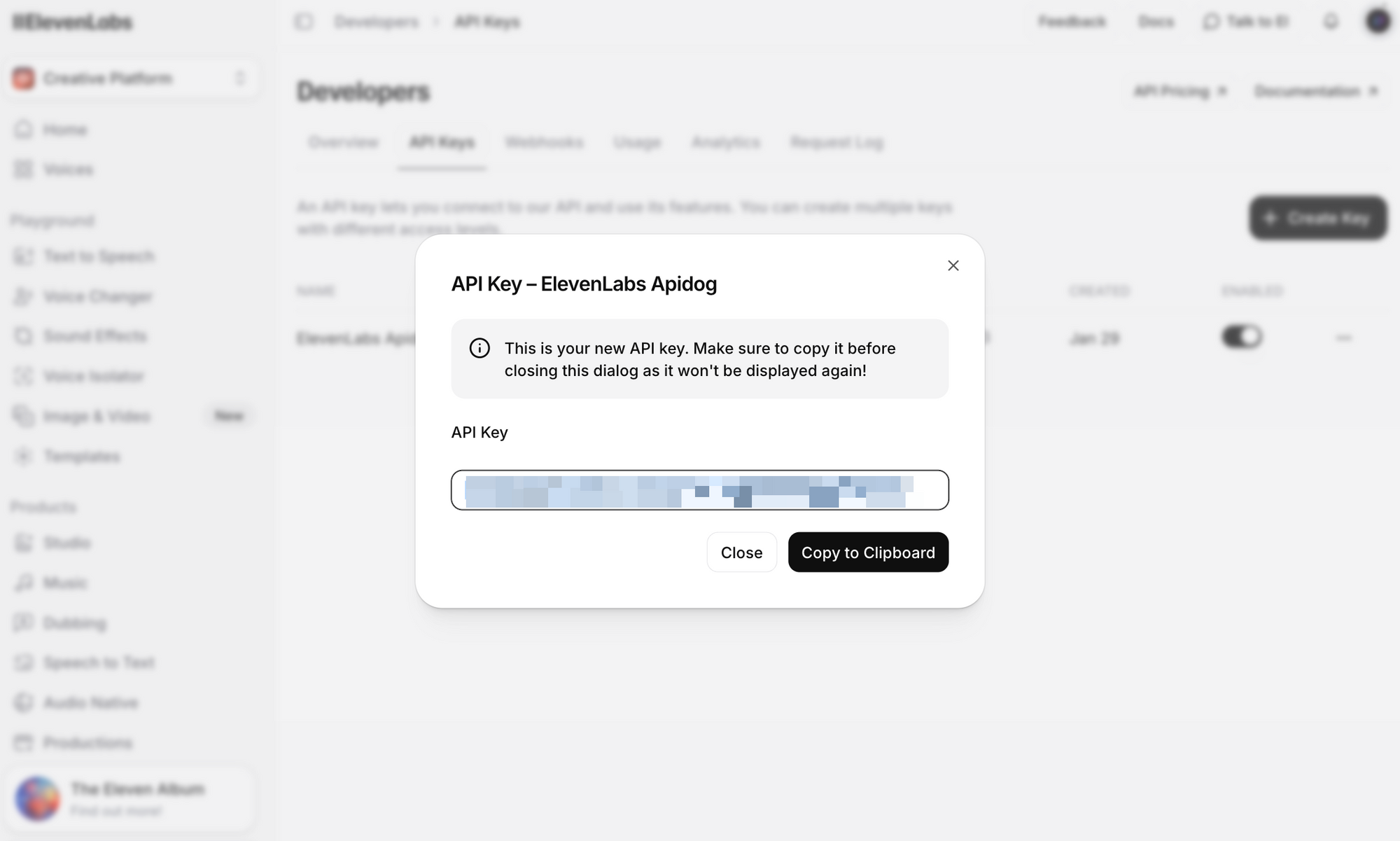
ステップ3:「APIキーを作成」をクリックします。キーをコピーし、安全に保管してください。一度生成すると、完全なキーを再度見ることはできません。
重要なセキュリティに関する注意点:
- APIキーをバージョン管理システムにコミットしないでください
- 本番環境では環境変数またはシークレットマネージャーを使用してください
- チーム環境では、APIキーを特定のワークスペースに限定することができます
- キーは定期的にローテーションし、侵害されたキーは直ちに失効させてください
このガイドの例のために、環境変数として設定してください:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
ElevenLabs APIエンドポイントの概要
このAPIはいくつかのリソースグループを中心に構成されています。最も一般的に使用されるエンドポイントは以下の通りです。
| エンドポイント | メソッド | 説明 |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | テキストを音声に変換 |
/v1/text-to-speech/{voice_id}/stream | POST | 生成されながら音声をストリーミング |
/v1/speech-to-speech/{voice_id} | POST | ある音声を別の音声に変換 |
/v1/voices | GET | 利用可能なすべての音声をリストアップ |
/v1/voices/{voice_id} | GET | 特定の音声の詳細を取得 |
/v1/models | GET | 利用可能なすべてのモデルをリストアップ |
/v1/user | GET | ユーザーアカウント情報と使用状況を取得 |
/v1/voice-generation/generate-voice | POST | 新しいランダムな音声を生成 |
ベースURL: https://api.elevenlabs.io
認証: すべてのリクエストにはxi-api-keyヘッダーが必要です:
xi-api-key: your_api_key_here
cURLによるテキスト読み上げ
APIをテストする最も速い方法はcURLコマンドを使用することです。この例では、すべてのプランで利用可能なデフォルトの音声の1つであるRachelの音声(ID: 21m00Tcm4TlvDq8ikWAM)を使用します。
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to our application. This audio was generated using the ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
成功した場合、生成された音声を含むspeech.mp3ファイルが得られます。任意のメディアプレーヤーで再生してください。
リクエストの内訳:
- voice_id (URL内): 使用する音声のIDです。ElevenLabsのすべての音声には固有のIDがあります。
- text: 音声に変換するコンテンツです。Flash v2.5モデルは、1リクエストあたり最大40,000文字をサポートします。
- model_id: 使用するAIモデルです。
eleven_flash_v2_5は速度と品質の最適なバランスを提供します。 - voice_settings: オプションの微調整パラメータ(詳細は下記参照)。
レスポンスは生のオーディオデータを返します。デフォルトの形式はMP3ですが、output_formatクエリパラメータを追加することで他の形式をリクエストできます。
# MP3の代わりにPCMオーディオを取得
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Python SDKの使用
公式のPython SDKは、型ヒント、組み込みの音声再生、ストリーミングサポートにより統合を簡素化します。
インストール
pip install elevenlabs
スピーカーから直接音声を再生するには、mpvまたはffmpegが必要になる場合があります:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
基本的なテキスト読み上げ
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="The ElevenLabs API makes it easy to add realistic voice output to any application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # George音声
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
音声をファイルに保存
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="This audio will be saved to a file.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("音声はoutput.mp3に保存されました")
利用可能な音声のリストアップ
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Category: {voice.category}")
これにより、あらかじめ用意された音声、クローンされた音声、追加したコミュニティ音声など、アカウントで利用可能なすべての音声が出力されます。
非同期サポート
asyncioを使用するアプリケーション向けに、SDKはAsyncElevenLabsを提供します。
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="This was generated asynchronously.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("非同期音声が保存されました。")
asyncio.run(generate_speech())
JavaScript SDKの使用
公式のNode.js SDK(@elevenlabs/elevenlabs-js)は、完全なTypeScriptサポートを提供し、Node.js環境で動作します。
インストール
npm install @elevenlabs/elevenlabs-js
基本的なテキスト読み上げ
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // Rachelの音声ID
{
text: "Hello from the ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
ファイルに保存 (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "This audio will be written to a file using Node.js streams.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("音声はoutput.mp3に保存されました");
エラーハンドリング
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Testing error handling.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`APIエラー: ${error.message}, ステータス: ${error.statusCode}`);
} else {
console.error("予期せぬエラー:", error);
}
}
SDKはデフォルトで、失敗したリクエストを最大2回まで、60秒のタイムアウトで再試行します。これらの値はどちらも設定可能です。
リアルタイム音声ストリーミング
チャットボット、音声アシスタント、またはレイテンシが重要なあらゆるアプリケーションでは、ストリーミングにより、応答全体が生成される前に音声の再生を開始できます。これは、ユーザーがほぼ即時の応答を期待する会話型AIにとって非常に重要です。
Pythonストリーミング
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Streaming allows you to start hearing audio almost instantly, without waiting for the entire generation to complete.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# ストリーミングされた音声をリアルタイムでスピーカーから再生
stream(audio_stream)
JavaScriptストリーミング
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "This audio streams in real time with minimal latency.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
WebSocketストリーミング
最低限のレイテンシを実現するには、WebSocket接続を使用します。これは、テキストがチャンクで到着する(例:LLMから)リアルタイム音声エージェントに最適です。
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Send initial config
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Send text chunks as they arrive (e.g., from an LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"Each chunk is sent separately."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signal end of input
await ws.send(json.dumps({"text": ""}))
# Receive audio chunks
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("WebSocket音声が保存されました。")
asyncio.run(stream_tts_websocket())
音声の選択と管理
ElevenLabsは何百もの音声を提供しています。アプリケーションのユーザーエクスペリエンスには、適切な音声を選択することが重要です。
デフォルトの音声
これらの音声は、無料ティアを含むすべてのプランで利用可能です。
| 音声名 | 音声ID | 説明 |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | 落ち着いた若い女性 |
| Drew | 29vD33N1CtxCmqQRPOHJ | バランスの取れた男性 |
| Clyde | 2EiwWnXFnvU5JabPnv8n | 退役軍人のキャラクター |
| Paul | 5Q0t7uMcjvnagumLfvZi | 現場レポーター |
| Domi | AZnzlk1XvdvUeBnXmlld | 力強く、自己主張の強い女性 |
| Dave | CYw3kZ02Hs0563khs1Fj | 会話的なイギリス人男性 |
| Fin | D38z5RcWu1voky8WS1ja | アイルランド人男性 |
| Sarah | EXAVITQu4vr4xnSDxMaL | 柔らかな若い女性 |
音声IDの検索
APIを使用して、利用可能なすべての音声を検索します。
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
またはカテゴリ(既成、クローン、生成)でフィルタリングします。
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# 既成の音声のみリストアップ
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
ElevenLabsのウェブサイトから直接音声IDをコピーすることもできます。音声を選択し、三点リーダーメニューをクリックして「音声IDをコピー」を選択します。
適切なモデルの選択
ElevenLabsは、それぞれ異なるユースケースに最適化された複数のモデルを提供しています。

# 詳細付きで利用可能なすべてのモデルをリストアップ
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"モデル: {model.name}")
print(f" ID: {model.model_id}")
print(f" 言語: {len(model.languages)}")
print(f" 最大文字数: {model.max_characters_request_free_user}")
print()
ApidogによるElevenLabs APIのテスト
統合コードを書く前に、APIエンドポイントを対話的にテストすることは役立ちます。Apidogを使えばこれは簡単です。リクエストを視覚的に設定し、応答(音声を含む)を検査し、満足したらクライアントコードを生成できます。
button
ステップ1:新しいプロジェクトのセットアップ
Apidogを開き、新しいプロジェクトを作成します。「ElevenLabs API」という名前を付けるか、既存のプロジェクトにエンドポイントを追加します。
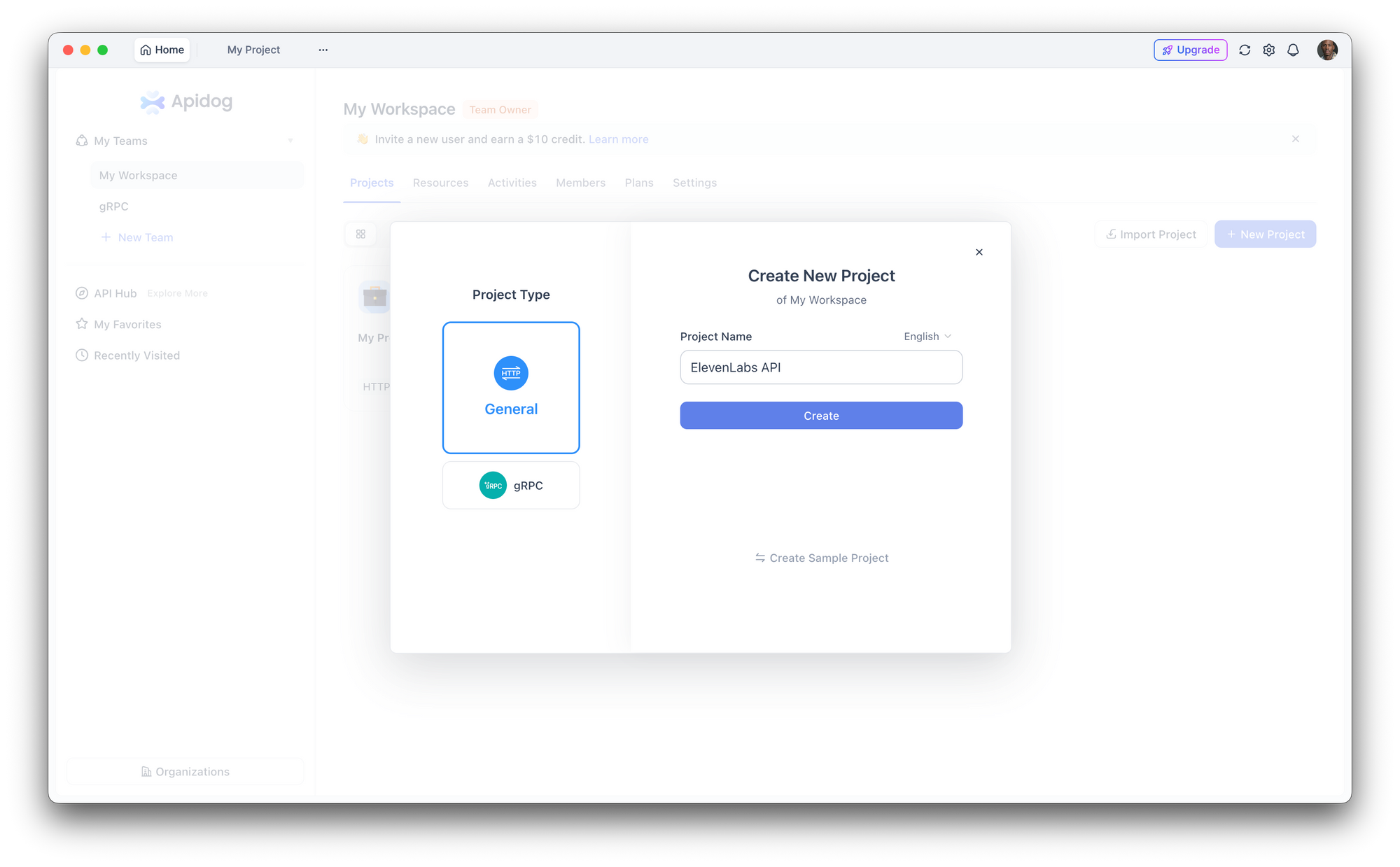
ステップ2:認証の設定
「プロジェクト設定 > 認証」に移動し、グローバルヘッダーを設定します。
- ヘッダー名:
xi-api-key - ヘッダー値: あなたのElevenLabs APIキー
これにより、プロジェクト内のすべてのリクエストに認証が自動的に付与されます。
ステップ3:テキスト読み上げリクエストの作成
新しいPOSTリクエストを作成します。
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - ボディ (JSON):
{
"text": "Testing the ElevenLabs API through Apidog. This makes it easy to experiment with different voices and settings.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
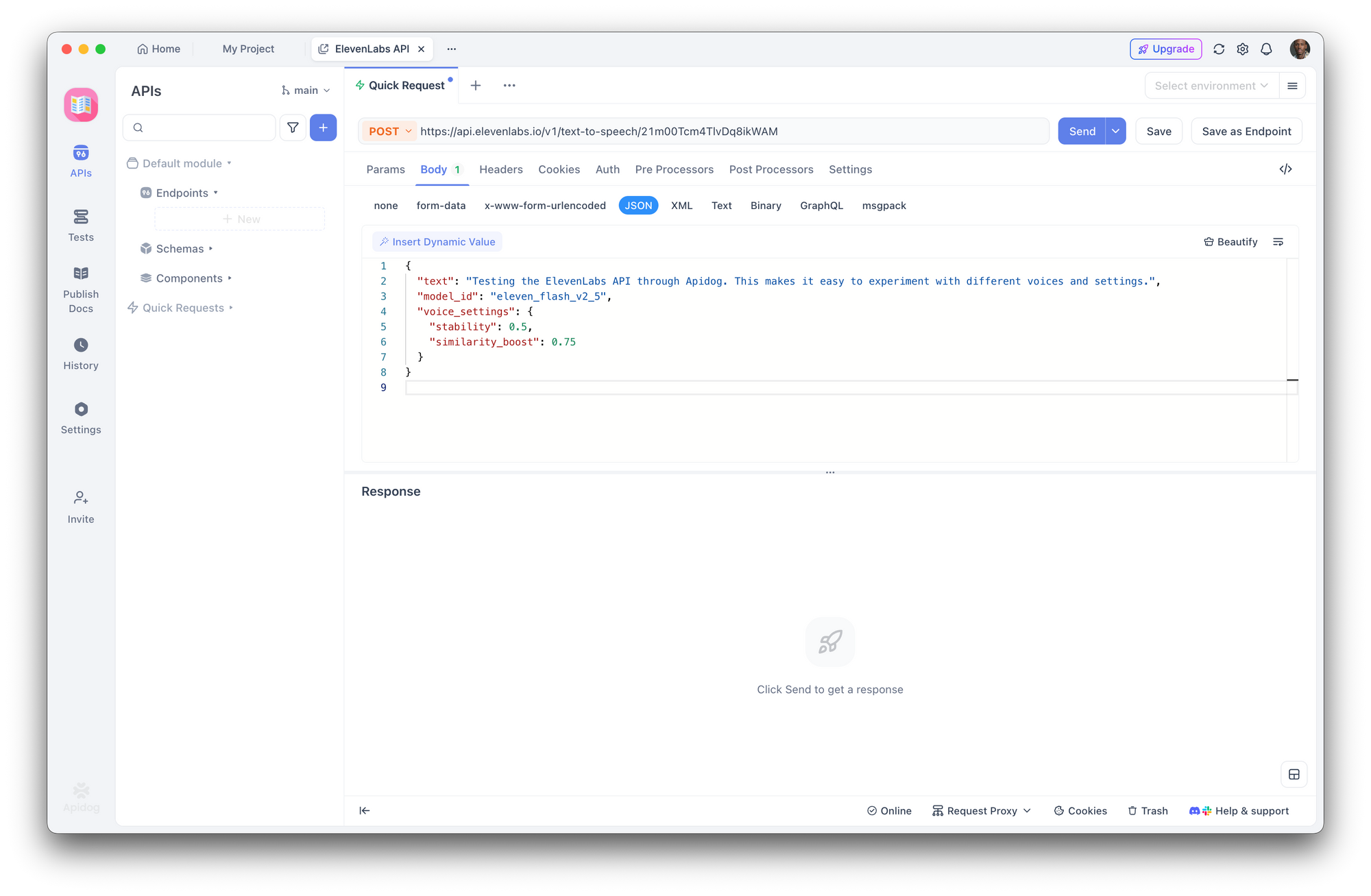
「送信」をクリックします。Apidogは応答ヘッダーを表示し、音声を直接ダウンロードまたは再生できます。
ステップ4:パラメータの実験
Apidogのインターフェースを使用すると、生のJSONを編集することなく、音声IDの切り替え、モデルの変更、音声設定の調整をすばやく行えます。比較しやすいように、異なる設定をコレクション内の別々のエンドポイントとして保存します。
ステップ5:クライアントコードの生成
リクエストが機能することを確認したら、Apidogで「コード生成」をクリックすると、Python、JavaScript、cURL、Go、Javaなどですぐに使えるクライアントコードが手に入ります。これにより、APIドキュメントから動作するコードへの手動変換が不要になります。
今すぐお試しください:Apidogを無料でダウンロード
音声設定と微調整
音声設定を使用すると、音声の聞こえ方を調整できます。これらのパラメータはvoice_settingsオブジェクトで送信されます。
| パラメータ | 範囲 | デフォルト | 効果 |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | 高いほど一貫性があり、表現力に乏しくなります。低いほど変化に富み、感情豊かになります。 |
similarity_boost | 0.0 - 1.0 | 0.75 | 高いほど元の音声に近くなります。低いほどバリエーションが増えます。 |
style | 0.0 - 1.0 | 0.0 | 高いほどスタイルが誇張されます。レイテンシが増加します。Multilingual v2のみ。 |
use_speaker_boost | boolean | true | 元の話者との類似性を高めます。わずかにレイテンシが増加します。 |
実用的な例:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# ナレーション音声:一貫性があり、安定している
narration = client.text_to_speech.convert(
text="Chapter One. It was a bright cold day in April.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# 会話音声:表現豊かで自然
conversational = client.text_to_speech.convert(
text="Oh wow, that's actually a great idea! Let me think about how we could make it work.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
ガイドライン:
- オーディオブックやナレーションでは、一貫した表現のために高めの安定性(0.7-0.9)を使用します。
- チャットボットや会話型AIでは、自然なバリエーションのために低めの安定性(0.3-0.5)を使用します。
- キャラクター音声では、異なる個性を生み出すために低めの類似性ブースト(0.4-0.6)を試します。
styleパラメータはMultilingual v2でのみ機能し、レイテンシが増加するため、リアルタイムアプリケーションでは使用を避けてください。
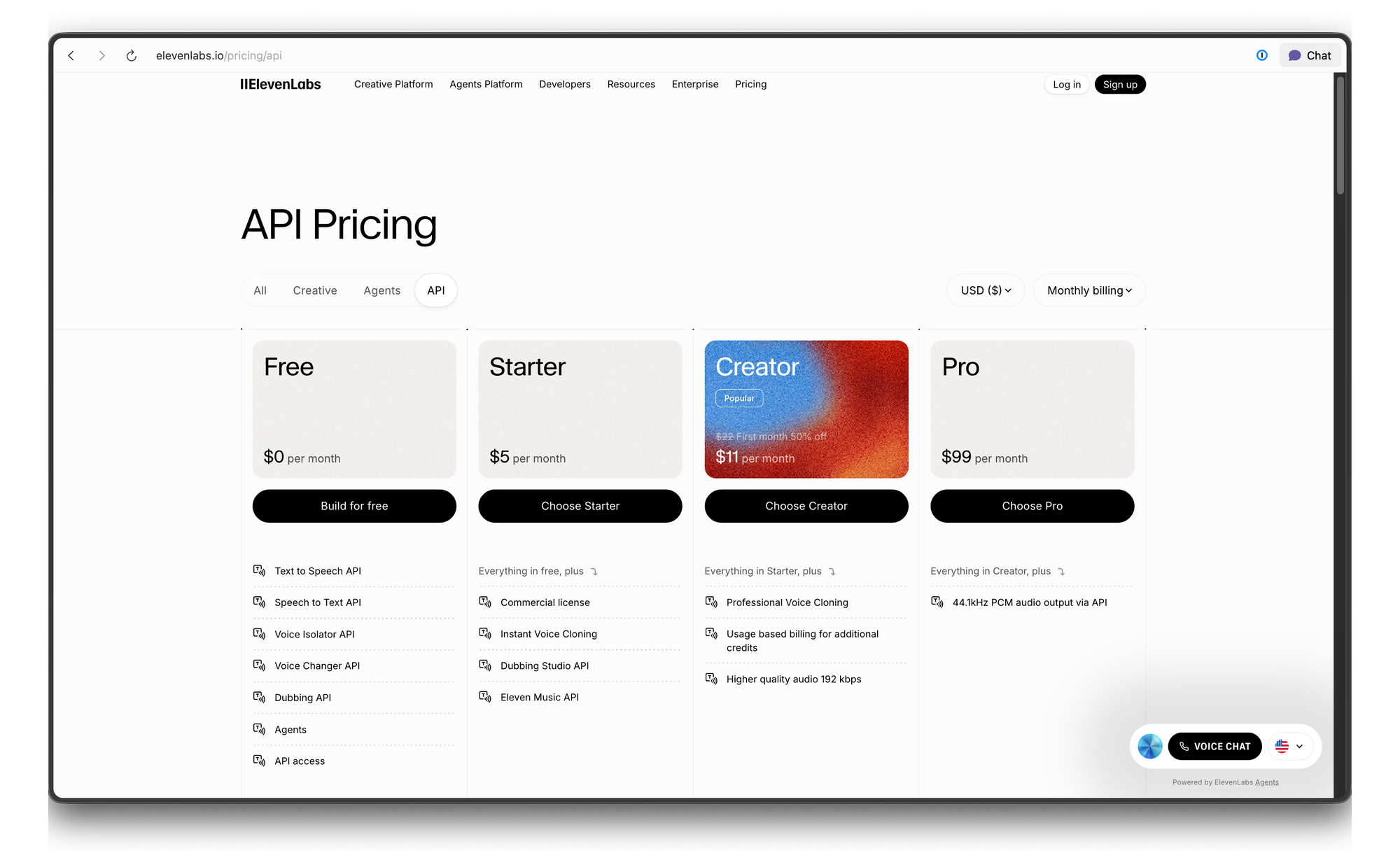
ElevenLabs APIの料金とレート制限
ElevenLabsはクレジットベースの料金体系を使用しています。内訳は以下の通りです。
トラブルシューティング
| エラー | 原因 | 解決策 |
|---|---|---|
| 401 Unauthorized | 無効または欠落しているAPIキー | xi-api-key ヘッダーの値を確認してください |
| 422 Unprocessable Entity | 無効なリクエストボディ | voice_idが存在し、textが空でないことを確認してください |
| 429 Too Many Requests | レート制限を超過しました | 指数バックオフを追加するか、プランをアップグレードしてください |
| Audio sounds robotic | 間違ったモデルまたは設定 | 安定性を0.5にしてMultilingual v2を試してください |
| Pronunciation errors | テキスト正規化の問題 | 数字/略語を完全に記述するか、SSMLのような書式設定を使用してください |
結論
ElevenLabs APIは、今日利用可能な最もリアルな音声合成技術のいくつかを開発者に提供します。数行のナレーションが必要な場合でも、完全なリアルタイム音声パイプラインが必要な場合でも、このAPIはシンプルなcURL呼び出しから本番環境のWebSocketストリームまで対応できます。
アプリケーションにリアルな音声を追加する準備はできていますか?Apidogを無料でダウンロードして、ElevenLabs APIエンドポイントをテストし、音声設定を実験し、クライアントコードを生成しましょう。すべて無料、クレジットカードは不要です。
button