
夢の7Bモデルは、香港大学のNLPチームとHuawei Noah's Ark Labの共同開発による画期的な言語モデル技術の進展を表しています。従来の自己回帰方式の代わりに拡散ベースのアプローチを利用してテキスト生成を行う夢の7Bは、より一貫性があり柔軟で強力な言語処理の新たな可能性を提示します。
このAPIツールを使えば、モデルのエンドポイントを簡単にテストおよびデバッグできます。今日、Apidogを無料でダウンロードし、Mistral Small 3.1の能力を探求しながらワークフローを効率化してください!
夢の7Bアーキテクチャの理解
夢の7B(「Dream」はDiffusion REAsoning Modelの略)は、テキスト生成のために離散的な拡散モデリングを利用した70億パラメータの言語モデルです。左から右へと逐次的にテキストを生成する従来の自己回帰モデル(GPTやLLaMAなど)とは異なり、夢の7Bは完全にノイズ状態から出発し、全シーケンスを動的に並行処理します。
この根本的なアーキテクチャの違いにより、夢の7Bは両方向の文脈情報をより効率的に処理し、一貫性と推論能力の向上を実現します。モデルはQwen2.5 7Bの重みで初期化され、Dolma v1.7、OpenCoder、DCLM-Baselineなどのデータセットから取得した約5800億トークンで訓練されました。
夢の7Bが従来のモデルを上回る理由
夢の7Bモデルは、従来の自己回帰型言語モデルに比べていくつかの重要な利点を示しています:
- 双方向コンテキストモデリング:夢の7Bは全シーケンスを同時に洗練することで、両方向からの情報を統合し、グローバルな一貫性を高めることができます。
- より強力な計画能力:複雑なタスクでの評価では、計画と制約満足を必要とする問題において、夢の7Bは同規模の自己回帰モデルよりも大幅に高いパフォーマンスを発揮します。
- 柔軟な生成制御:拡散ベースのアーキテクチャは、任意の順序でのテキスト生成を可能にし、テキストの補完、埋め込み、制御生成などの多様なアプリケーションを可能にします。
- 調整可能な質-速度トレードオフ:ユーザーは拡散ステップの数を動的に制御し、生成品質と計算効率のバランスを取ることができます。
ベンチマークテストにおける夢の7Bの性能

夢の7Bモデルはさまざまなベンチマークで広範な評価を受け、同規模の自己回帰モデルと比較して競争力のある性能を一貫して示しています。一般的な言語タスク、数学的推論、およびコード生成において、夢の7BはLLaMA3 8BやQwen2.5 7Bなどのトップモデルの能力に匹敵するか、これを超えています。
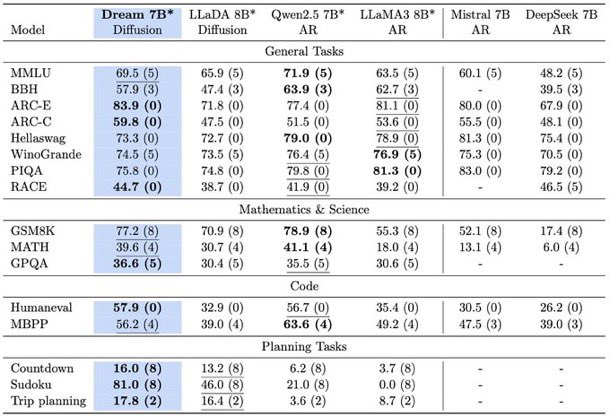
特に、CountdownやSudokuなどの計画を重視したタスクでは、夢の7Bは同様のサイズのモデルを大幅に上回り、時にはDeepSeek V3 671Bのようなはるかに大きなモデルの性能に近づくこともあります。これは、複雑な制約と目標を扱う際のモデルの優れた推論能力を強調しています。

夢の7Bの背後にある訓練の革新
夢の7Bの開発には、その卓越した性能に寄与したいくつかの重要な革新が取り入れられています:
自己回帰型重みの初期化
夢の7Bチームは、一からの訓練ではなく、Qwen2.5 7Bの自己回帰モデルの重みを使用してモデルを初期化しました。このアプローチは、言語理解の強力な基盤を提供し、必要な訓練時間とリソースを大幅に削減しました。学習率の慎重な選択は、初期化からの貴重な知識を保持しながら効果的な拡散訓練を可能にするために重要でした。
文脈適応型トークンレベルノイズ再調整
夢の7Bで導入された新しい技術は、文脈適応型トークンレベルノイズ再調整メカニズムです。このアプローチは、各トークンの文脈情報に基づいてノイズレベルを動的に再割り当てし、学習プロセスに対してより正確な指導を提供します。従来の拡散訓練アプローチは文全体に均一なノイズレベルを適用していましたが、夢の7Bのより細かいアプローチはより効果的な学習をもたらします。
夢の7Bモデルの実用的なアプリケーション
夢の7Bモデルのユニークな能力は、従来の自己回帰モデルが苦しむさまざまな実用的アプリケーションを可能にします:
柔軟なテキスト補完と埋め込み
夢の7Bは任意の順序でテキストを生成できるため、既存のコンテンツのギャップを埋めたり、特定の制約に沿ってテキストを補完したりするタスクに特に効果的です。モデルは、正確なターゲット文で終了するテキストを生成するよう指示されることもでき、その双方向の理解能力を示しています。
制御された生成順序
ユーザーは、夢の7Bのデコード動作を異なるタスクに合わせて調整でき、従来の左から右への生成から完全にランダムな順序の生成まで柔軟に対応できます。この柔軟性により、モデルはさまざまなアプリケーション要件に適応できます。
質-速度の最適化
拡散ステップの数を調整できる能力は、実世界のアプリケーションに特有のメリットを提供します。ユーザーは、より少ないステップを選んで迅速なドラフト品質の出力を得たり、より多くのステップを選んでより高品質の結果を得たりすることができ、特定のニーズに基づいた動的なリソース配分を可能にします。
夢の7Bの監視付きファインチューニング
ユーザーの指示との整合性を高めるために、夢の7BチームはTulu 3とSmolLM2からの1.8百万の指示ペアを含むキュレーションされたデータセットを使用して監視付きファインチューニングを行いました。3エポックのファインチューニングの後、夢の7Bはユーザーの指示に従う強い性能を示し、自己回帰モデルと同等です。
結果として得られたモデル、Dream-v0-Instruct-7Bは、研究者や実践者が実験や発展を行うために、基本モデル(Dream-v0-Base-7B)と共に公開されています。
夢の7Bを実行するための技術要件
夢の7Bを実装するには、特定の技術的構成が必要です:
- 最低20GBメモリを持つGPU
- Transformersライブラリ(バージョン4.46.2)
- SdpaAttentionサポートを持つPyTorch(バージョン2.5.1)
モデルは、生成制御に関してさまざまなパラメータをサポートします:
steps:拡散のタイムステップを制御します(ステップ数が少ないと、より迅速で粗い結果が得られます)temperature:次のトークン確率を調整します(より正確な結果には低い値、より多様性には高い値が必要です)top_pとtop_k:生成の多様性を制御しますalg:拡散サンプリングにおける再マスキング戦略を決定します
夢の7B技術の今後の方向性
夢の7Bの成功は、拡散ベースの言語モデルの将来の発展に多数の可能性を開きます:
- さらなるスケーリング:7Bパラメータでの印象的なパフォーマンスに続いて、より大きなサイズにスケールアップすることで、現在のトップ級の自己回帰モデルの支配を挑戦する可能性があります。
- 高度なポストトレーニング技術:チームは、拡散型言語モデル専用に設計されたより洗練されたアラインメントおよび指示調整手法を探求する予定です。
- 専門的なアプリケーション:夢の7Bのユニークな計画能力と柔軟な推論は、具現化されたAI、自律エージェント、長期的意思決定システムなどの分野でのアプリケーションにとって有望です。
- マルチモーダル拡張:拡散モデルの並列処理特性は、同時に複数のモダリティを扱うために拡張される可能性があります。
結論:AIの風景における夢の7Bの可能性
夢の7Bは言語モデルの進化における重要なマイルストーンを示し、拡散ベースのアプローチが従来の自己回帰方式と同等またはそれを超えることができ、柔軟性と推論能力においてユニークな利点を提供できることを示しています。
人工知能の分野が進化し続ける中で、夢の7Bのようなモデルは、自己回帰アーキテクチャが言語モデリングの最適なアプローチであるという従来の知恵に挑戦します。夢の7Bの印象的なパフォーマンスと独自の能力は、拡散ベースの言語モデルが次世代のAIシステムにおいてますます重要な役割を果たす可能性を示唆しています。
モデルの重みと実装コードをオープンソースリソースとして提供することで、夢の7Bチームはこの有望な方向でのより広範な実験と革新を促進し、将来的により能力が高く、柔軟で効率的な言語モデルの開発を加速することができます。