
開発者は、不要な複雑さを招くことなく生産性を向上させるツールを求めています。DeepSeek-V3.2およびDeepSeek-V3.2-Specialeは、推論およびエージェントタスク向けに最適化された強力なオープンソースモデルとして登場し、プロプライエタリなシステムに代わる魅力的な選択肢を提供します。これらのモデルは、コード生成、問題解決、長文コンテキスト処理に優れており、Claude Codeのようなターミナルベースのコーディング環境への統合に最適です。
DeepSeek-V3.2の理解:推論タスクのためのオープンソースの強力なツール
開発者は、透明性と柔軟性のためにオープンソースモデルを高く評価しています。DeepSeek-V3.2は、論理推論、コード合成、エージェント機能を優先する推論ファーストのLLM(大規模言語モデル)として際立っています。MITライセンスの下でリリースされたこのモデルは、DeepSeek-V3.1のような以前のバージョンに基づいて構築されており、最大128,000トークンの拡張コンテキストを処理するためにスパースアテンションメカニズムの進歩を取り入れています。
DeepSeek-V3.2には、主にHugging Faceを通じてアクセスします。そこでは、deepseek-ai/DeepSeek-V3.2のリポジトリにモデルの重み、設定ファイル、トークナイザーの詳細がホストされています。モデルをローカルにロードするには、pip経由でTransformersライブラリをインストールし、簡単なスクリプトを実行します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
# Example inference
inputs = tokenizer("Write a Python function to compute Fibonacci sequence:", return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
この設定では、効率的な推論のために少なくとも16GBのVRAMを搭載したGPUが必要ですが、bitsandbytesのようなライブラリを介した量子化技術によりメモリフットプリントが削減されます。DeepSeek-V3.2のアーキテクチャは、2360億のパラメータを持つ混合エキスパート(MoE)設計を採用しており、トークンごとに一部のみをアクティブ化して計算を最適化します。その結果、競合するパフォーマンスを維持しながら、コンシューマーハードウェアで高いスループットを実現します。
ローカルでの実験から本番規模での使用への移行には、しばしばAPIアクセスが必要です。この移行により、ハードウェア管理なしでスケーラビリティが提供され、Claude Codeのような統合への道が開かれます。
DeepSeek-V3.2-Speciale:高度なエージェントワークフローのための強化された機能
DeepSeek-V3.2は幅広い用途に対応していますが、DeepSeek-V3.2-Specialeは、特定の要求に合わせてこれらの基盤を洗練しています。このバリアントは、競技レベルの推論やリスクの高いシミュレーション向けに調整されており、数学、コーディングコンテスト、複数ステップのエージェントタスクにおける限界を押し広げます。deepseek-ai/DeepSeek-V3.2-SpecialeのHugging Faceリポジトリから入手でき、コアのMoEアーキテクチャを共有していますが、精度を高めるための追加の事後トレーニングアライメントが組み込まれています。
DeepSeek-V3.2-Specialeも同様にロードします。
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
そのパラメータ数はベースモデルを反映していますが、スパースアテンション(DeepSeek Sparse Attention (DSA))の最適化により、長いシーケンスで最大50%速い推論を実現します。DSAは、品質を維持しながらアテンション層における二次的な複雑さを低減する、きめ細かいスパース性を採用しています。
実際には、DeepSeek-V3.2-Specialeは、競技プログラミングのアルゴリズム最適化など、連鎖的な推論が必要なシナリオで威力を発揮します。例えば、「このLeetCodeの難しい問題を解決してください:[説明]。手順を追ってアプローチを説明してください。」とプロンプトを与えると、モデルは時間計算量分析を含む構造化されたソリューションを出力し、エッジケースでは汎用モデルを15~20%上回るパフォーマンスを示すことがよくあります。
ただし、ローカル実行にはより多くのリソースが必要で、フル精度では24GB以上のVRAMが推奨されます。より軽量なセットアップでは、4ビット量子化を適用します。
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
この設定は、元の忠実度を90%維持しながら、メモリ使用量を半分にします。ベースモデルと同様に、思考モードを有効にして、推論中に仮定を自己修正するメタ認知トレースを活用します。
オープンソースアクセスはカスタマイズを可能にしますが、共同作業環境やスケーリングされた環境では、APIエンドポイントが信頼性を提供します。次に、これらのモデルをクラウドベースのインタラクションにどのように橋渡しするかを調べます。
DeepSeek APIへのアクセス:スケーラブルな開発のためのシームレスな統合
DeepSeek-V3.2やDeepSeek-V3.2-Specialeのようなオープンソースモデルはローカル環境で活躍しますが、APIアクセスはより幅広いアプリケーションを可能にします。DeepSeekのプラットフォームは、OpenAIおよびAnthropic SDKをサポートする互換性のあるインターフェースを提供し、容易な移行を可能にします。
platform.deepseek.comでサインアップしてAPIキーを取得します。
ダッシュボードは使用状況分析と課金管理を提供します。標準のエンドポイントを介してモデルを呼び出します。DeepSeek-V3.2の場合、deepseek-chatエイリアスを使用します。DeepSeek-V3.2-Specialeには、特定のベースURLが必要です:https://api.deepseek.com/v3.2_speciale_expires_on_20251215 — この一時的なルーティングは2025年12月15日に期限切れとなることに注意してください。
基本的なcurlリクエストがアクセス方法を示します。
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Generate a REST API endpoint in Node.js for user authentication."}],
"max_tokens": 500,
"temperature": 0.7
}'
これは、エラー処理とJWT統合を含む、生成されたコードのJSONを返します。Anthropicとの互換性(Claude Codeにとって重要)のためには、ベースURLをhttps://api.deepseek.com/anthropicに設定し、anthropic Python SDKを使用します。
import anthropic
client = anthropic.Anthropic(base_url="https://api.deepseek.com/anthropic", api_key="your_deepseek_key")
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
messages=[{"role": "user", "content": "Explain quantum entanglement in code terms."}]
)
print(message.content[0].text)
このような互換性により、ドロップインでの置き換えが保証されます。標準ティアでのレート制限は1分あたり10,000トークンであり、エンタープライズプランを介してスケーリング可能です。
Apidogを使用してこれらの呼び出しをプロトタイプ化します。DeepSeekドキュメントからOpenAPI仕様をApidogにインポートし、可変ペイロードでリクエストをシミュレートします。このツールはテストスイートを自動生成し、スキーマに対するレスポンスを検証します。これは、モデルの出力がコードベースの標準に合致していることを確認するために不可欠です。
APIアクセスが確保されたら、これらのエンドポイントを開発ツールに統合します。特にClaude Codeは、後述するようにこのセットアップから恩恵を受けます。
料金の内訳:DeepSeek API使用のための費用対効果の高い戦略
予算を意識する開発者は、予測可能なコストを高く評価します。DeepSeekの価格モデルは、効率的なプロンプティングとキャッシュを奨励し、Claude Codeセッションに直接影響を与えます。
構造を分解します。キャッシュヒットは繰り返されるプレフィックスに適用され、セッション間でプロンプトを洗練する反復的なコーディングに最適です。ミスは完全な入力料金がかかるため、再利用を最大化するように会話を構成します。出力は生成長に比例してスケールするため、max_tokensを制限して費用を管理します。
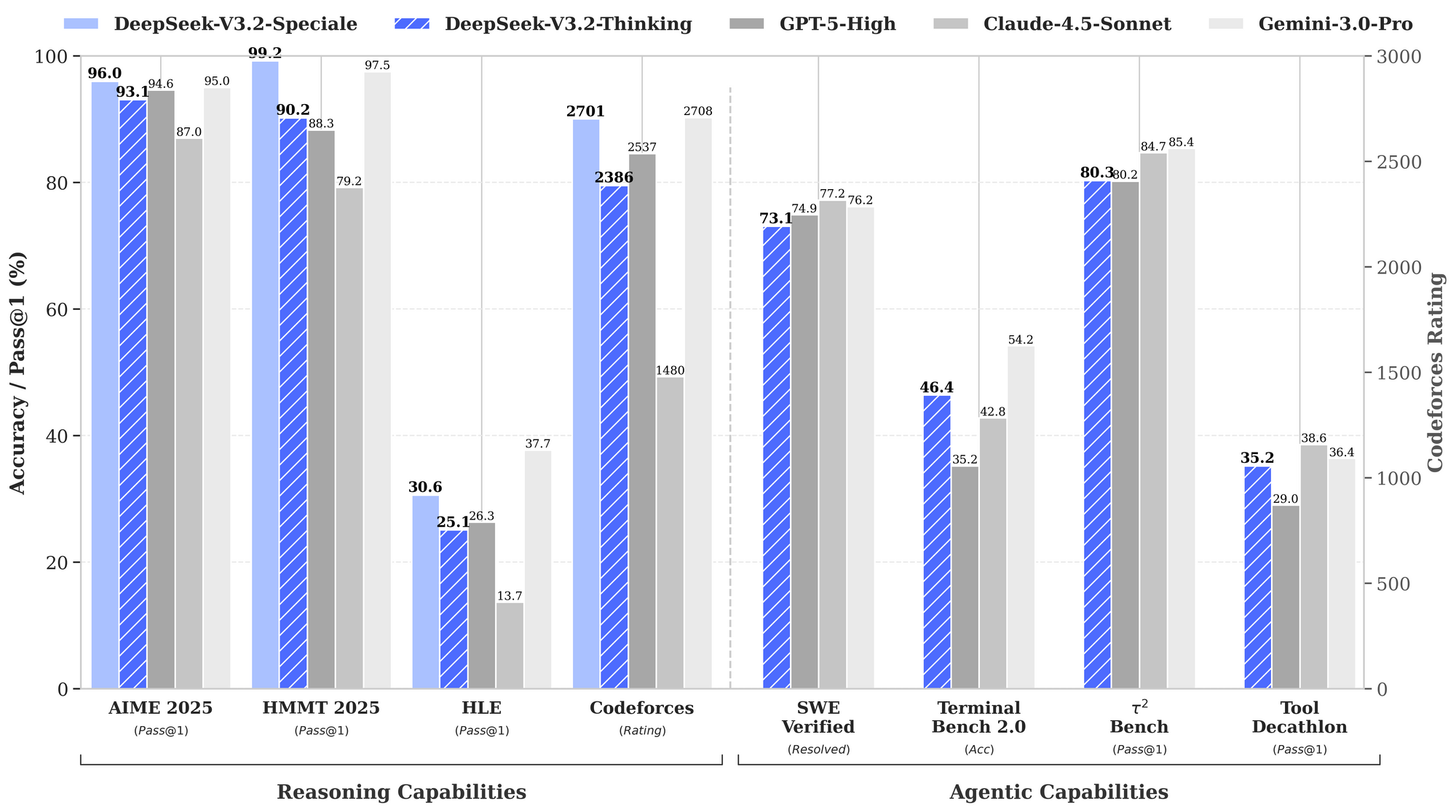
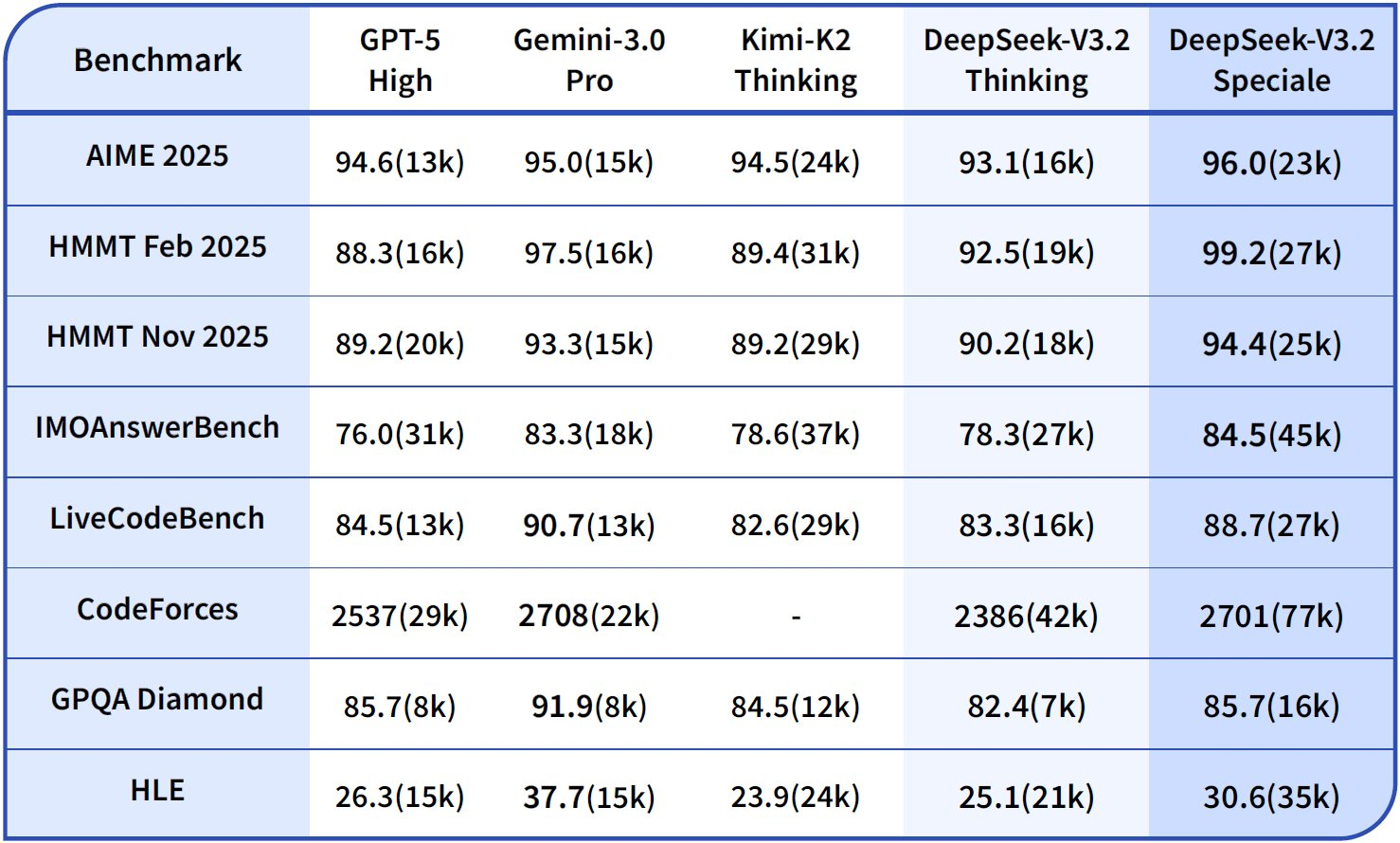
| モデルバリアント | 入力キャッシュヒット(100万トークンあたりドル) | 入力キャッシュミス(100万トークンあたりドル) | 出力(100万トークンあたりドル) | コンテキスト長 |
|---|---|---|---|---|
| DeepSeek-V3.2 | 0.028 | 0.28 | 0.42 | 128K |
| DeepSeek-V3.2-Speciale | 0.028 | 0.28 | 0.42 | 128K |
エンタープライズユーザーはボリュームディスカウントを交渉できますが、無料ティアではテスト用に毎月100万トークンが提供されます。ダッシュボードで監視し、Claude Codeでロギングを統合してトークン使用量を追跡します。
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=$DEEPSEEK_API_KEY
claude --log-tokens
このコマンドはセッション後にメトリクスを出力し、プロンプトの最適化に役立ちます。長文コンテキストのコーディングでは、V3.2バリアントのDSAは、二次的に増加する密なモデルとは異なり、100K以上のトークンでもコストを安定させます。
DeepSeek-V3.2およびV3.2-SpecialeをClaude Codeに統合する:段階的なセットアップ
Claude Codeは、Anthropicのエージェントツールとして、ターミナルベースの開発に革命をもたらします。自然言語コマンドを解釈し、git操作を実行し、コードベースを説明し、ルーチンを自動化します。これらすべてをシェル内で実行します。DeepSeekモデルにリクエストをルーティングすることで、Claude Codeの直感的なインターフェースを犠牲にすることなく、費用対効果の高い推論を活用できます。

まず、前提条件から始めます。pip(pip install claude-code)またはGitHubのanthropics/claude-codeからClaude Codeをインストールします。Node.jsとgitがPATHに存在することを確認してください。
DeepSeek互換性のための環境変数を設定します。
export ANTHROPIC_BASE_URL="https://api.deepseek.com/anthropic"
export ANTHROPIC_API_KEY="sk-your_deepseek_key_here"
export ANTHROPIC_MODEL="deepseek-chat" # V3.2用
export ANTHROPIC_SMALL_FAST_MODEL="deepseek-chat"
export API_TIMEOUT_MS=600000 # 長い推論のために10分
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1 # API用に最適化
DeepSeek-V3.2-Specialeの場合、カスタムベースを追加します: export ANTHROPIC_BASE_URL="https://api.deepseek.com/v3.2_speciale_expires_on_20251215/anthropic"。claude --versionを実行してセットアップを確認します。エンドポイントが自動的に検出されます。
プロジェクトディレクトリでClaude Codeを起動します。
cd /path/to/your/repo
claude
コマンドで対話します。コード生成の場合:「/generate AVLバランスを持つC++で二分探索木を実装する」。DeepSeek-V3.2はこれを処理し、説明付きのファイルを出力します。その思考モードは、複雑なタスクでは暗黙的にアクティブになり、コードの前にロジックをトレースします。
エージェントワークフローを処理します。「/agent この失敗しているテストスイートをデバッグし、修正案を提案する。」モデルはスタックトレースを分析し、パッチを提案し、git経由でコミットします。これらすべてはDeepSeekの84.8%のSWE-Benchスコアによって強化されています。並列ツール使用はここで輝きを放ちます。インラインでテストを実行するために「/use-tool pytest」を指定します。
プラグインでカスタマイズします。Claude CodeのYAML設定(~/.claude-code/config.yaml)を拡張して、推論が重いプロンプトにDeepSeekを優先させます。
models:
default: deepseek-chat
fallback: deepseek-chat # V3.2-Specialeの場合、セッションごとにオーバーライド
reasoning_enabled: true
max_context: 100000 # 128Kウィンドウを活用
Apidogを使用して統合をテストします。Claude CodeセッションをHARファイルとしてエクスポートし、Apidogにインポートして、DeepSeekエンドポイントに対してリプレイします。これにより、レイテンシ(通常1Kトークンで2秒未満)とエラーレートが検証され、本番環境向けのプロンプトが洗練されます。
一般的な問題をトラブルシューティングします。認証に失敗した場合は、APIキーを再生成します。トークン制限の場合、大きなコードベースを「/summarize repo structure first.」でチャンク化します。これらの調整により、スムーズな操作が保証されます。
高度なテクニック:Claude CodeでDeepSeekを活用して最高のパフォーマンスを実現する
基本的な機能を超えて、上級ユーザーはDeepSeekの強みを活用します。思考の連鎖(CoT)を明示的に有効にします:「/think この動的計画法問題を解決してください:[詳細]」。V3.2-Specialeはメタ認知トレースを生成し、テキストでの準モンテカルロシミュレーションを通じて自己修正を行い、HMMTでの精度を94.6%に向上させます。
複数のファイルの編集には、「/edit --files main.py utils.py ロギングデコレータを追加する。」を使用します。エージェントは依存関係をナビゲートし、変更をアトミックに適用します。ベンチマークではTerminal-Bench 2.0で80.3%の成功率を示し、Gemini-3.0-Proを上回っています。
外部ツールを統合します。生成後の検証のために「/tool npm run build」を設定します。DeepSeekのツール使用ベンチマーク(84.7%)は、信頼性の高いオーケストレーションを保証します。
倫理を監視します。DeepSeekはRLHFを介して安全性に適合していますが、コードの仮定におけるバイアスの出力を監査します。Apidogのスキーマ検証を使用して、入力サニタイズなどの安全なパターンを強制します。
チームへのスケーリング。ドットファイルリポジトリを介して構成を共有します。CI/CDでは、DeepSeekを組み込んだClaude Codeスクリプトを自動PRレビューに埋め込み、レビュー時間を40%短縮します。
実世界への応用:DeepSeek搭載のClaude Codeの活用例
フィンテックプロジェクトを考えてみましょう。「/generate GraphQLを使用したトランザクション処理用のセキュアなAPI。」DeepSeek-V3.2は、OWASP標準に照らして検証されたスキーマ、リゾルバ、レート制限ミドルウェアを出力します。
MLパイプラインでは:「/agent このPyTorchモデルをエッジデプロイメント用に最適化する。」量子化のためにリファクタリングし、シミュレートされたハードウェアでテストし、トレードオフを文書化します。
これらのケースは、GitHubイシューでのユーザー報告によって裏付けられた2~3倍の生産性向上を示しています。
結論
DeepSeek-V3.2とDeepSeek-V3.2-Specialeは、Claude Codeを推論中心の強力なツールに変革します。オープンソースのロードからAPI駆動のスケーラビリティまで、これらのモデルは、わずかなコストでベンチマークをリードするパフォーマンスを提供します。概説された手順(APIプロトタイピングのためのApidogから始める)を実行し、合理化されたワークフローを体験してください。
今すぐ試してみてください:環境をセットアップし、サンプルコマンドを実行し、反復します。この統合は開発を加速させるだけでなく、透明性の高い推論を通じてコードへのより深い理解を育みます。AIが進歩するにつれて、このようなツールは開発者が最前線に立ち続けることを保証します。