
DeepSeekのエンジニアは、V3.1モデルの反復的な機能強化としてDeepSeek-V3.1-Terminusをリリースしました。これは、ユーザーから報告された問題に対処しつつ、中核となる強みを増幅させています。このバージョンは、一貫した言語出力や堅牢なエージェント機能など、開発者が実際のアプリケーションで重視する実用的な改善に焦点を当てています。AIモデルが進化するにつれて、DeepSeekのようなチームは、基盤を大幅に変更することなく信頼性を向上させる改良を優先しています。その結果、DeepSeek-V3.1-Terminusは、コード生成から複雑な推論まで幅広いタスクに対応する洗練されたツールとして登場しました。
このリリースは、オープンソースイノベーションに対するDeepSeekのコミットメントを強調しています。このモデルは現在Hugging Faceに公開されており、すぐに実験にアクセスできます。エンジニアはV3.1の基盤を基に、ベンチマーク全体でパフォーマンスを向上させる微調整を導入しました。その結果、ユーザーは、以前はスムーズなインタラクションを妨げていた中国語と英語の混在した応答や不規則な文字などの不満を経験することが少なくなりました。
DeepSeek-V3.1-Terminusのアーキテクチャを理解する
DeepSeekのアーキテクトは、DeepSeek-V3.1-Terminusを、その前身であるDeepSeek-V3の構造を反映したハイブリッドなMixture of Experts (MoE) フレームワークで設計しました。このアプローチは、密なコンポーネントと疎なコンポーネントを組み合わせることで、モデルが特定のタスクに対して関連するエキスパートのみを活性化できるようにします。その結果、完全に密なモデルと比較して計算オーバーヘッドを削減し、高い効率でクエリを処理します。

その核となるモデルは、エキスパートモジュール全体に分散された6,850億のパラメータを誇ります。エンジニアは、これらのパラメータにBF16、F8_E4M3、F32のテンソルタイプを採用し、精度と速度の両方を最適化しています。しかし、注目すべき問題として、自己注意出力射影がUE8M0 FP8スケールフォーマットに完全に準拠していない点があり、DeepSeekは今後のイテレーションでこれを解決する予定です。この軽微な欠陥は全体的な機能に大きく影響するものではありませんが、モデル開発の反復的な性質を浮き彫りにしています。
さらに、DeepSeek-V3.1-Terminusは思考モードと非思考モードの両方をサポートしています。思考モードでは、モデルは内部ロジックに基づいて多段階の推論を行い、複雑な問題を処理します。対照的に、非思考モードは、簡単なクエリに対して迅速な応答を優先します。この二重性は、2段階の長文コンテキスト拡張メソッドを組み込んだ、拡張されたV3.1-Baseチェックポイントでの後処理トレーニングに由来します。開発者は、データセットを強化するために追加の長文ドキュメントを収集し、より良いコンテキスト処理のためにトレーニングフェーズを延長します。
以前のバージョンと比較したDeepSeek-V3.1-Terminusの主な改善点
DeepSeekのエンジニアは、V3.1リリースからのフィードバックに取り組むことでDeepSeek-V3.1-Terminusを改良し、具体的な機能強化を実現しました。主に、以前の出力で問題となっていた頻繁な中国語と英語の混在やランダムな文字を排除し、言語の不整合を低減しました。この変更により、特に多言語環境において、よりクリーンでプロフェッショナルな応答が保証されます。
さらに、エージェントのアップグレードが大きな進歩として際立っています。コードエージェントはプログラミングタスクをより高い精度で処理できるようになり、検索エージェントは検索効率を向上させました。これらの改善は、洗練されたトレーニングデータと更新されたテンプレートに由来しており、モデルがツールをよりシームレスに統合できるようにします。
ベンチマークの比較は、これらの定量的向上を明らかにしています。例えば、ツールを使用しない推論モードでは、MMLU-Proのスコアは84.8から85.0に上昇し、GPQA-Diamondは80.1から80.7に改善しました。Humanity's Last Examでは15.9から21.7へと大幅な飛躍が見られ、困難な評価での強力なパフォーマンスを示しています。LiveCodeBenchは74.9でほぼ安定しており、CodeforcesとAider-Polyglotではわずかな変動がありました。
エージェントによるツール使用に移行すると、モデルはさらに優れています。BrowseCompは30.0から38.5に増加し、SimpleQAは93.4から96.8に上昇しました。SWE Verifiedは66.0から68.4に、SWE-bench Multilingualは54.5から57.8に、Terminal-benchは31.3から36.7に進歩しました。BrowseComp-zhはわずかに低下しましたが、全体的な傾向は優れた信頼性を示しています。
さらに、DeepSeek-V3.1-Terminusは速度を犠牲にすることなくこれらを達成しています。一部の競合他社よりも速く応答し、困難なベンチマークではDeepSeek-R1に匹敵する品質を維持しています。このバランスは、より良い汎化のために長文コンテキストデータを組み込んだ、最適化された後処理トレーニングから生まれています。
DeepSeek-V3.1-Terminusのパフォーマンスベンチマークと評価
評価者はDeepSeek-V3.1-Terminusを多様なベンチマークで評価し、推論とツール統合におけるその強みを明らかにしています。ツールを使用しない推論では、モデルはMMLU-Proで85.0点を獲得し、広範な知識保持能力を示しています。GPQA-Diamondでは80.7点に達し、大学院レベルの質問に対する熟練度を示しています。
さらに、Humanity's Last Examでの21.7点は、難解なトピックの処理能力が向上したことを強調しています。LiveCodeBench (74.9) やAider-Polyglot (76.1) のようなコーディングベンチマークは実用性を示していますが、Codeforcesは2046に低下しており、さらなるチューニングの余地があることを示唆しています。
エージェントシナリオに移行すると、BrowseCompの38.5点はウェブナビゲーション機能の強化を反映しています。SimpleQAのほぼ完璧な96.8点は、クエリ解決の精度を強調しています。Verified (68.4) とMultilingual (57.8) を含むSWE-benchスイートは、そのソフトウェアエンジニアリング能力を裏付けています。Terminal-benchの36.7点は、コマンドライン操作における能力を示しています。
比較すると、DeepSeek-V3.1-Terminusはほとんどの指標でV3.1を上回り、最小限のパフォーマンストレードオフで68倍のコスト優位性を達成しています。効率性においてはクローズドソースモデルに匹敵し、ビジネスアプリケーションに理想的です。
DeepSeek-V3.1-TerminusとAPI、およびApidogのようなツールの統合
開発者は、OpenAI互換APIを介してDeepSeek-V3.1-Terminusを統合し、導入を簡素化します。非思考モードには「deepseek-chat」を、思考モードには「deepseek-reasoner」を指定します。
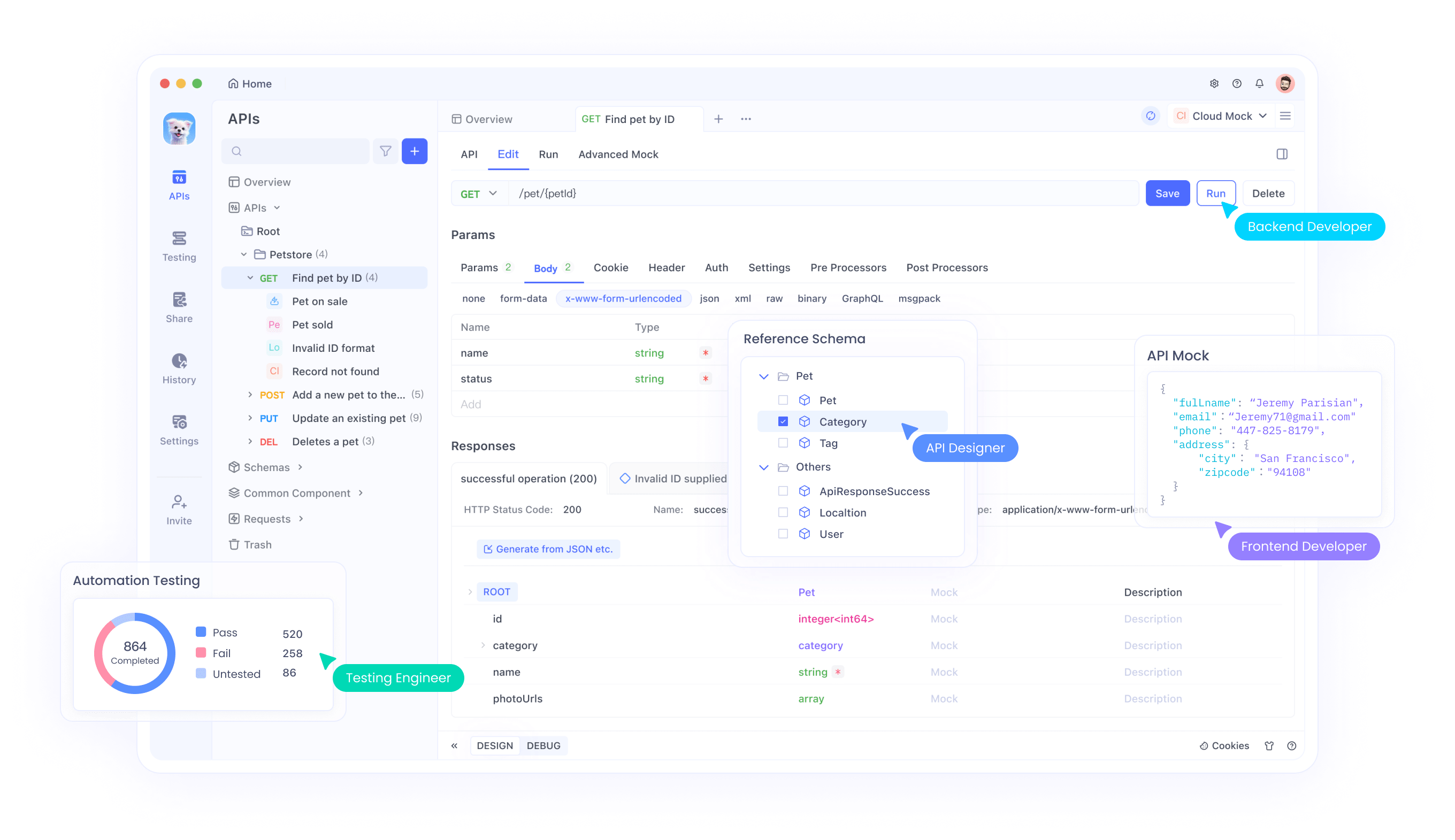
まず、ユーザーはDeepSeekプラットフォームでAPIキーを生成します。Apidogを使用すると、ベースURL (https://api.deepseek.com) を入力し、キーを変数として保存することで環境をセットアップできます。この設定により、チャット補完と関数呼び出しのテストが容易になります。
さらに、Apidogはデバッグをサポートしており、開発者が応答を効率的に検証できます。関数呼び出しの場合、リクエスト内でツールを定義することで、モデルが外部関数を動的に呼び出すことを可能にします。
価格は100万出力トークンあたり1.68ドルと競争力があり、幅広い利用を促進します。統合はGeneplore AIやAI/ML APIのようなフレームワークにも及び、マルチエージェントシステムをサポートします。
競合するAIモデルとの比較
DeepSeek-V3.1-Terminusは、DeepSeek-R1のようなモデルと効果的に競合し、推論の品質を維持しつつ、より速く応答します。ツール使用においてはV3.1を上回り、BrowseCompで8.5ポイントの向上を達成しています。
プロプライエタリなオプションと比較して、オープンソースのアクセシビリティとコスト効率を提供します。例えば、ベンチマークではSonnetレベルのパフォーマンスに近づいています。
さらに、そのハイブリッドモードは、一部の競合他社にはない汎用性を提供します。したがって、堅牢な機能を求める予算重視の開発者にアピールします。
DeepSeek-V3.1-Terminusのデプロイ戦略
エンジニアは、DeepSeek-V3リポジトリを使用してモデルをローカルにデプロイします。クラウドの場合、AWS Bedrockのようなプラットフォームがホストします。
リポジトリ内の最適化された推論コードはセットアップを支援します。したがって、スケーラビリティは様々な環境に適しています。
高度な機能:関数呼び出しとツール統合
開発者は、APIリクエストでスキーマを定義することにより、関数呼び出しを実装します。これにより、データベースへのクエリのような動的なインタラクションが可能になります。
Apidogはこれらの機能のテストを支援し、堅牢な統合を保証します。
コスト分析と最適化のヒント
低いトークンあたりのコストで、DeepSeek-V3.1-Terminusは価値を提供します。簡単なタスクには非思考モードを選択するなど、モードを賢く選択することで最適化できます。
Apidogを介して使用状況を監視し、費用を効果的に管理します。
ユーザーフィードバックとコミュニティの反応
ユーザーはこのリリースを歓迎し、安定性の向上を指摘しています。V4を期待する声もあり、高い期待が寄せられています。
Redditのようなフォーラムでは、そのエージェント機能の強みに関する議論が活発に行われています。
結論:AI開発におけるDeepSeek-V3.1-Terminusの活用
DeepSeek-V3.1-TerminusはAI機能を洗練させ、開発者に強力で効率的なツールを提供します。エージェントと言語におけるその改善は、革新的なアプリケーションへの道を開きます。チームがこれを採用するにつれて、モデルはコミュニティの意見によって進化し続けます。