AIアプリケーションを強化するために、開発者は堅牢なAPIをしばしば求めます。DeepSeek-V3.1 APIは、多用途な選択肢として際立っています。これは高度な言語モデリング機能を提供します。チャット補完やツール統合といった機能にアクセスできます。この記事では、その使用方法を段階的に説明します。
まず、DeepSeekプラットフォームからAPIキーを取得します。彼らのサイトでサインアップし、キーを生成してください。それがあれば、リクエストを開始できます。
次に、主要なコンポーネントを理解しましょう。DeepSeek-V3.1は大規模モデルを基盤としています。最大128Kトークンのコンテキストをサポートします。これにより、複雑なクエリを効率的に処理できます。さらに、より深い推論のための思考モードも含まれています。進めるにつれて、これらの要素がどのように組み合わさるかに注目してください。
DeepSeek-V3.1とは何か、そしてなぜそれを選ぶのか?
DeepSeek-V3.1は、AIモデルの進化を象徴しています。DeepSeek-aiのエンジニアは、これをハイブリッドアーキテクチャとして開発しました。このモデルは合計6710億のパラメータを持ちますが、推論時にはわずか370億のみが活性化されます。この設計により、高いパフォーマンスを維持しつつ計算要件が削減されます。

2つの主要なバリアントがあります:DeepSeek-V3.1-Baseと完全なDeepSeek-V3.1です。ベースバージョンは、さらなるトレーニングの基盤として機能します。これは2段階の長文コンテキスト拡張を受けました。最初の段階では、32Kコンテキストのために6300億トークンにトレーニングが拡張されました。次に、第2段階では、128Kコンテキストのために2090億トークンが追加されました。追加の長文ドキュメントがデータセットを豊かにしました。
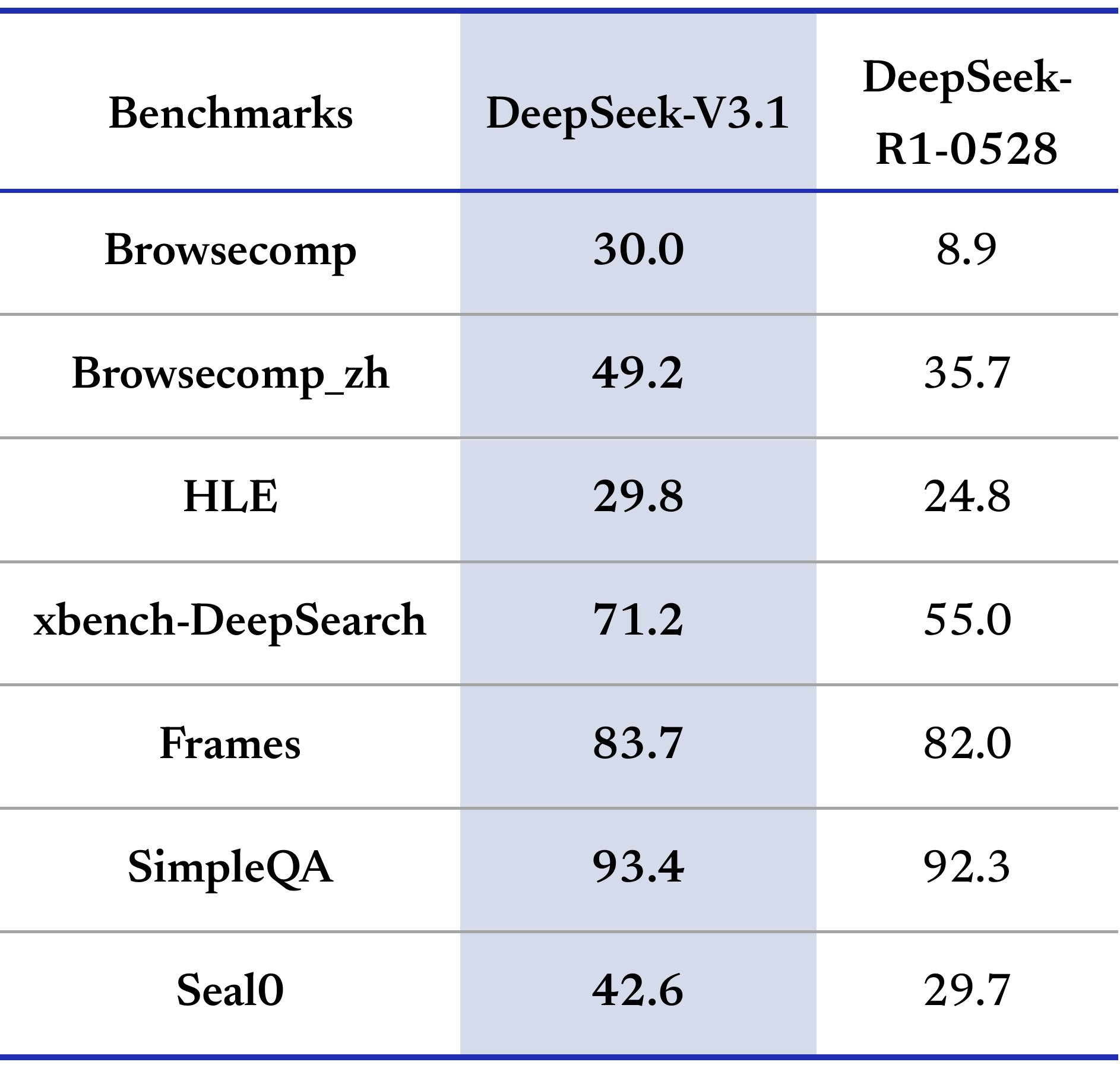
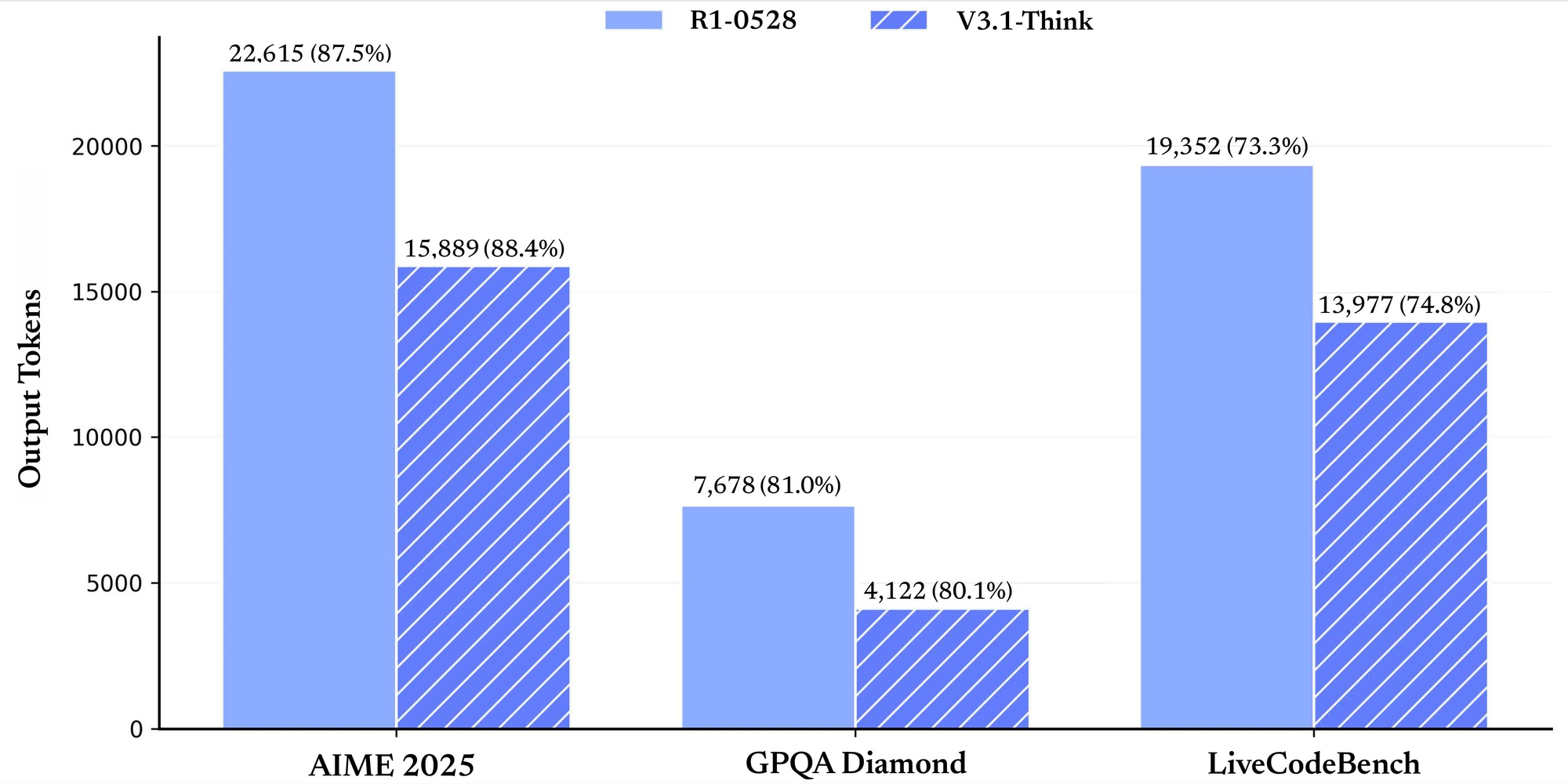
パフォーマンスベンチマークはその強みを浮き彫りにしています。一般的なタスクでは、非思考モードでMMLU-Reduxで91.8点、思考モードで93.7点を記録しました。GPQA-Diamondでは、それぞれ74.9点と80.1点に達します。コード関連の評価では、LiveCodeBenchで非思考モードで56.4点、思考モードで74.8点を示しました。AIME 2024のような数学ベンチマークでは、66.3点と93.1点を示しています。これらの数値は、ドメイン全体での信頼性を示しています。
なぜDeepSeek-V3.1 APIを選ぶのでしょうか?これはエージェントタスクやツール呼び出しに優れています。検索エージェントやコードエージェントのために統合できます。他のAPIと比較して、費用対効果の高い価格設定と互換性機能を提供します。その結果、チームはスケーラブルなAIソリューションのためにこれを採用しています。セットアップに移行する前に、環境を慎重に準備してください。
DeepSeek-V3.1 API統合の開始
開発環境のセットアップから始めます。必要なライブラリをインストールしてください。Pythonの場合、pipを使用してrequestsまたは互換性のあるSDKを追加します。DeepSeek-V3.1 APIのエンドポイントは標準のHTTPプロトコルに従います。ベースURLはhttps://api.deepseek.comです。
ダッシュボードからAPIキーを生成してください。それを環境変数に安全に保存します。例えば、シェルでDEEPSEEK_API_KEYを設定します。次に、最初のリクエストを行います。チャット補完エンドポイントを使用します。/chat/completionsにPOSTを送信します。
Authorization: Bearer your_keyを含むヘッダーを含めます。ボディには、モデルとして「deepseek-chat」、メッセージ配列、およびmax_tokensのようなパラメータが含まれます。簡単なリクエストは次のようになります。
import requests
url = "https://api.deepseek.com/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "deepseek-chat",
"messages": [{"role": "user", "content": "Hello, DeepSeek-V3.1!"}],
"max_tokens": 100
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
このコードは応答を取得します。出力はcontentフィールドを確認してください。エラーが発生した場合は、キーとペイロードを確認してください。さらに、Apidogでテストしてください。エンドポイントをインポートし、呼び出しをシミュレートします。Apidogは応答を視覚化し、デバッグを支援します。
モデルのオプションを探ります。DeepSeek-chatは一般的なチャットに適しています。DeepSeek-reasonerは推論タスクを処理します。ニーズに基づいて選択してください。進めるにつれて、リアルタイム出力のためにストリーミングを組み込みます。リクエストでstreamをtrueに設定します。チャンクをそれに応じて処理します。
セキュリティも重要です。常にHTTPSを使用してください。キーの露出を制限します。キーを定期的にローテーションします。基本をカバーしたら、関数呼び出しのような高度な機能に進みます。
DeepSeek-V3.1 APIにおける関数呼び出しをマスターする
関数呼び出しはDeepSeek-V3.1 APIを強化します。モデルが呼び出すツールを定義します。これにより、天気データの取得のような動的な対話が可能になります。
リクエスト内でツールを定義します。各ツールには、タイプ「function」、名前、説明、およびパラメータがあります。パラメータはJSONスキーマを使用します。例えば、get_weatherツールは次のようになります。
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"}
},
"required": ["location"]
}
}
}
これをチャット補完リクエストのtools配列に含めます。モデルはユーザーメッセージを分析します。関連性がある場合、応答でtool_callsを返します。各呼び出しには、id、name、およびargumentsがあります。
呼び出しを処理します。関数をローカルで実行します。get_weatherの場合、外部APIをクエリするか、データをモックします。結果をツールメッセージとして追加します。
{
"role": "tool",
"tool_call_id": "call_id_here",
"content": "Temperature: 24°C"
}
更新されたメッセージを返送します。モデルは最終的な応答を生成します。
より良い検証のために厳格モードを使用します。strictをtrueに設定し、ベータ版のベースURLを使用します。これによりスキーマの準拠が強制されます。サポートされる型には、string、number、arrayが含まれます。minLengthのようなサポートされていないフィールドは避けてください。
ベストプラクティスには、明確な説明が含まれます。Apidogでツールをテストして応答をモックします。引数内のエラーを監視します。その結果、アプリケーションはよりインタラクティブになります。次に、他のエコシステムとの互換性を調べます。
DeepSeek-V3.1におけるAnthropic API互換性の活用
DeepSeek-V3.1 APIはAnthropic形式をサポートしています。これにより、Anthropic SDKをシームレスに使用できます。ベースURLをhttps://api.deepseek.com/anthropicに設定してください。
Anthropic SDKをインストールします: pip install anthropic。環境を設定します:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEY
メッセージを作成します:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are helpful.",
messages=[{"role": "user", "content": [{"type": "text", "text": "Hi"}]}]
)
print(message.content)
これはAnthropicのように動作しますが、DeepSeekモデルを使用します。サポートされるフィールド: max_tokens、temperature (0-2.0)、tools。無視されるフィールド: top_k、cache_control。
違いは存在します。画像やドキュメントのサポートはありません。ツール選択のオプションは限られています。Anthropicからの移行にこれを使用してください。Apidogでテストして応答を比較してください。結果として、コードを書き直すことなくツールキットを拡張できます。
DeepSeek-V3.1モデルアーキテクチャとトークナイザーの理解
DeepSeek-V3.1-Baseが核を成します。効率のためにハイブリッド設計を使用しています。コンテキスト長は128Kに達し、長文ドキュメントに理想的です。
トレーニングは拡張されたフェーズを含みました。まず、32Kで6300億トークン。次に、128Kで2090億トークン。FP8形式が互換性を保証します。
トークナイザー設定: add_bos_token true, model_max_length 131072。BOSトークン「<|begin of sentence|>」、EOS「<|end of sentence|>」。チャットテンプレートは、User、Assistant、thinkタグのような役割を処理します。
会話にはテンプレートを適用します。思考モードでは、推論をタグで囲みます。これにより、複雑なタスクでのパフォーマンスが向上します。
Hugging Faceを介してモデルをロードします。from_pretrained("deepseek-ai/DeepSeek-V3.1")を使用してください。入力を慎重にトークン化します。制限内に収まるようにトークン数を監視します。これにより、精度を最適化できます。
DeepSeek-V3.1 APIの料金とコスト管理
料金は採用に影響します。DeepSeek-V3.1 APIは100万トークンごとに課金されます。モデル: deepseek-chatとdeepseek-reasoner。

2025年9月5日16:00 UTC以降:両モデルとも、キャッシュヒット入力は$0.07、キャッシュミス入力は$0.56、出力は$1.68です。
それ以前は、標準時間(00:30-16:30 UTC):deepseek-chatはヒット$0.07、ミス$0.27、出力$1.10;reasonerはヒット$0.14、ミス$0.55、出力$2.19。割引時間(16:30-00:30):おおよそ半額です。
無料枠の言及はありません。コスト計算:リクエストごとのトークンを推定します。繰り返しの入力にはキャッシュを使用します。トークンを削減するためにプロンプトを最適化します。
ダッシュボードで使用状況を追跡します。予算を設定します。Apidogを使用して呼び出しをシミュレートし、コストを予測します。したがって、費用を効果的に管理できます。
DeepSeek-V3.1 APIのベストプラクティスとトラブルシューティング
成功のためのガイドラインに従ってください。簡潔なプロンプトを作成します。メッセージにコンテキストを提供します。
レイテンシを監視します。長いコンテキストは応答を遅くします。可能であれば入力をチャンクに分割します。
データのセキュリティ:機密情報を送信しないようにします。
トラブルシューティング:ステータスコードを確認します。401は無効なキーを意味します。429はリクエストが多すぎることを意味します。
SDKを定期的に更新します。変更点についてはドキュメントを読んでください。
スケーリング:サポートされている場合はリクエストをバッチ処理します。並列処理には非同期を使用します。
コミュニティフォーラムが役立ちます。経験を共有しましょう。
これらを適用することで、信頼性の高い統合を実現できます。
結論:DeepSeek-V3.1 APIでAIプロジェクトを向上させる
DeepSeek-V3.1 APIを効果的に使用する方法が理解できたでしょう。セットアップから高度な機能まで、これは開発者を力づけます。よりスムーズなワークフローのためにApidogを組み込みましょう。今日から構築を開始し、その影響を実感してください。