
クラウドプラットフォーム上で最も強力な大規模言語モデルの1つであるDeepseek R1をデプロイしようとしていますか?AWS、Azure、またはDigital Oceanで作業している場合でも、このガイドはあなたを網羅しています。この記事の終わりまでには、Deepseek R1モデルを簡単に起動するための明確なロードマップが手に入ります。さらに、デプロイ中にAPIテストを効率化するためのツールとしてApidogの活用方法も紹介します。
なぜクラウドにDeepseek R1をデプロイするのか?
Deepseek R1をクラウドにデプロイすることは、単にスケーラビリティに関するものではありません。大量の負荷を効率的に処理するためにGPUとサーバーレスインフラの力を活用することが重要です。671Bのパラメータを持つDeepseek R1は、堅牢なハードウェアと最適化された構成を要求します。クラウドは、柔軟性、コスト効率、高性能リソースを提供し、小規模なチームでもこのようなモデルをデプロイ可能にします。
このガイドでは、Deepseek R1を3つの人気プラットフォーム、AWS、Azure、およびDigital Oceanにデプロイする方法を紹介します。また、パフォーマンスを最適化し、API管理のためにApidogなどのツールを統合するためのヒントも共有します。
環境の準備
デプロイに進む前に、環境を準備しましょう。これには、認証トークンの設定、GPUの可用性の確認、ファイルの整理が含まれます。
認証トークン
すべてのクラウドプロバイダーは、何らかの形の認証を必要とします。例えば:
- AWSでは、S3バケットとEC2インスタンスにアクセスするための許可を持つIAMロールが必要です。
- Azureでは、Azure Machine Learning SDKsが提供する簡略化された認証体験を使用できます。
- Digital Oceanでは、アカウントダッシュボードからAPIトークンを生成します。
これらのトークンは、ローカルマシンとクラウドプラットフォーム間の安全な通信を可能にするため、重要です。
ファイルの整理
ファイルを体系的に整理しましょう。Dockerを使用する場合(強く推奨されます)、すべての依存関係を含むDockerfileを作成します。Tensorfuseのようなツールが、Deepseek R1のデプロイ用の事前構築されたテンプレートを提供します。同様に、IBM Cloudのユーザーは、進む前にモデルファイルをObject Storageにアップロードする必要があります。

オプション1: Tensorfuseを使用したAWS上でのDeepseek R1のデプロイ
まず、本日最も広く使用されているクラウドプラットフォームの一つであるAmazon Web Services (AWS)から始めましょう。AWSはスイスアーミーナイフのようなもので、ストレージからコンピュートパワーまで、すべてのタスクに対するツールが揃っています。このセクションでは、Deepseek R1を、プロセスを大幅に簡略化するTensorfuseを用いてデプロイすることに集中します。
なぜDeepseek R1で構築するのか?
技術的な詳細に飛び込む前に、Deepseek R1が際立っている理由を理解しましょう:
- 評価における高いパフォーマンス:業界標準のベンチマークで強力な結果を達成し、MMLUでは90.8%、AIME 2024では79.8%を記録。
- 高度な推論:最小限のコンテキストで多段階の論理推論タスクを処理し、LiveCodeBench(Pass@1-COT)のようなベンチマークで65.9%のスコアを達成。
- 多言語サポート:多様な言語データで事前トレーニングされているため、多言語理解に優れています。
- スケーラブルな蒸留モデル:より小型の蒸留されたバリアント(2B、7B、および70B)が提供され、コストを損なうことなく安価なオプションを提供。
これらの強みは、チャットボットからエンタープライズレベルのデータ分析まで、生産準備が整ったアプリケーションにおいてDeepseek R1が優れた選択肢となることを意味します。
前提条件
始める前に、AWSアカウントでTensorfuseを設定していることを確認してください。まだ設定していない場合は、はじめにガイドに従ってください。この設定は、プロジェクトを開始する前に作業スペースを準備するようなもので、プロセスがスムーズに進むためにすべてが整っていることを保証します。
ステップ1: API認証トークンを設定する
API認証トークンとして使用されるランダムな文字列を生成します。次のコマンドを使用してTensorfuseに秘密として保存します:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
本番環境では、ランダムに生成されたトークンを使用することを確認してください。openssl rand -base64 32を使用してすぐに生成できるので、安全に保管してください。Tensorfuseの秘密は不透明です。
ステップ2: Dockerfileを準備する
公式のvLLM OpenAIイメージをベースイメージとして使用します。この画像には、vLLMを実行するために必要なすべての依存関係が含まれています。
以下がDockerfileの設定です:
# Deepseek-R1-671BのためのDockerfile
FROM vllm/vllm-openai:latest
# HF Hub Transferを有効化
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# ポート80を公開
EXPOSE 80
# APIキーを持つエントリポイント
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
この設定は、GPUメモリの使用状況やテンソルの並列性など、Deepseek R1の特定の要件に最適化されたvLLMサーバーを保証します。
ステップ3: デプロイメント設定
デプロイメント設定を定義するdeployment.yamlファイルを作成します:
# Deepseek-R1-671Bのためのdeployment.yaml
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
次のコマンドを使用してサービスをデプロイします:
tensorkube deploy --config-file ./deployment.yaml
このコマンドは、認証されたリクエストに応じる準備ができたオートスケーリングの生産LLMサービスをセットアップします。
ステップ4: デプロイされたアプリへのアクセス
デプロイが成功したら、curlやPythonのOpenAIクライアントライブラリを使用してエンドポイントをテストできます。以下はcurlを使用した例です:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "地球からロボットランドへ。どうしたの?",
"max_tokens": 200
}'
Pythonユーザー向けには、以下のサンプルスニペットがあります:
import openai
# 実際のURLとトークンに置き換えてください
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="こんにちは、Deepseek R1!今日はどうですか?",
max_tokens=200
)
print(response)
オプション2: AzureでのDeepseek R1のデプロイ
Azure Machine Learning(Azure ML)でDeepseek R1をデプロイすることは、プラットフォームの堅牢なインフラとリアルタイムの推論のための高度なツールを活用した効率的なプロセスです。このセクションでは、Azure MLのManaged Online Endpointsを使用してDeepseek R1をデプロイする方法を紹介します。このアプローチは、スケーラビリティ、効率性、および管理の容易さを保証します。
ステップ1: Azure ML上でのvLLMのためのカスタム環境の作成
まず、vLLM専用のカスタム環境を作成する必要があります。これがDeepseek R1をデプロイする基盤となります。vLLMフレームワークは高スループット推論のために最適化されており、Deepseek R1のような大規模言語モデルを扱うのに理想的です。
1.1: Dockerfileを定義する:モデルのための環境を指定するDockerfileを作成します。vLLMのベースコンテナには、すべての必要な依存関係とドライバーが含まれており、スムーズなセットアップを保証します:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
このDockerfileにより、モデル名を環境変数(MODEL_NAME)経由で渡すことができ、デプロイ中に希望のモデルを選択する柔軟性が得られます。たとえば、基盤となるコードを変更することなく、さまざまなバージョンのDeepseek R1に簡単に切り替えることができます。
1.2: Azure MLワークスペースにログインする:次に、Azure CLIを使用してAzure MLワークスペースにログインします。<subscription ID>、<Azure Machine Learning workspace name>、および<resource group>を特定の詳細で置き換えてください:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
このステップは、すべての次のコマンドがあなたのワークスペースのコンテキスト内で実行されることを保証します。
1.3: 環境設定ファイルを作成する:次に、環境設定を定義するenvironment.ymlファイルを作成します。このファイルは、先に作成したDockerfileを参照します:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: 環境を構築する:設定ファイルができたら、次のコマンドで環境を構築します:
az ml environment create -f environment.yml
このステップは、環境をコンパイルし、デプロイメントで使用できるようにします。
ステップ2: Azure MLのManaged Online Endpointをデプロイする
環境が設定されたら、Deepseek R1モデルをデプロイするためにAzure MLのManaged Online Endpointsを使用します。これらのエンドポイントは、スケラブルでリアルタイムの推論機能を提供し、生産グレードのアプリケーションに最適です。
2.1: エンドポイント設定ファイルを作成する:Managed Online Endpointを定義するendpoint.ymlファイルを作成します:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
この設定は、エンドポイントの名前(r1-prod)と認証モード(key)を指定します。後でテスト目的のために、エンドポイントのスコアリングURIとAPIキーを取得できます。
2.2: エンドポイントを作成する:次のコマンドを使用してエンドポイントを作成します:
az ml online-endpoint create -f endpoint.yml
2.3: Dockerイメージのアドレスを取得する:次に進む前に、ステップ1で作成されたDockerイメージのアドレスを取得します。Azure ML Studio > Environments > r1に移動してイメージアドレスを見つけてください。以下のようになります:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
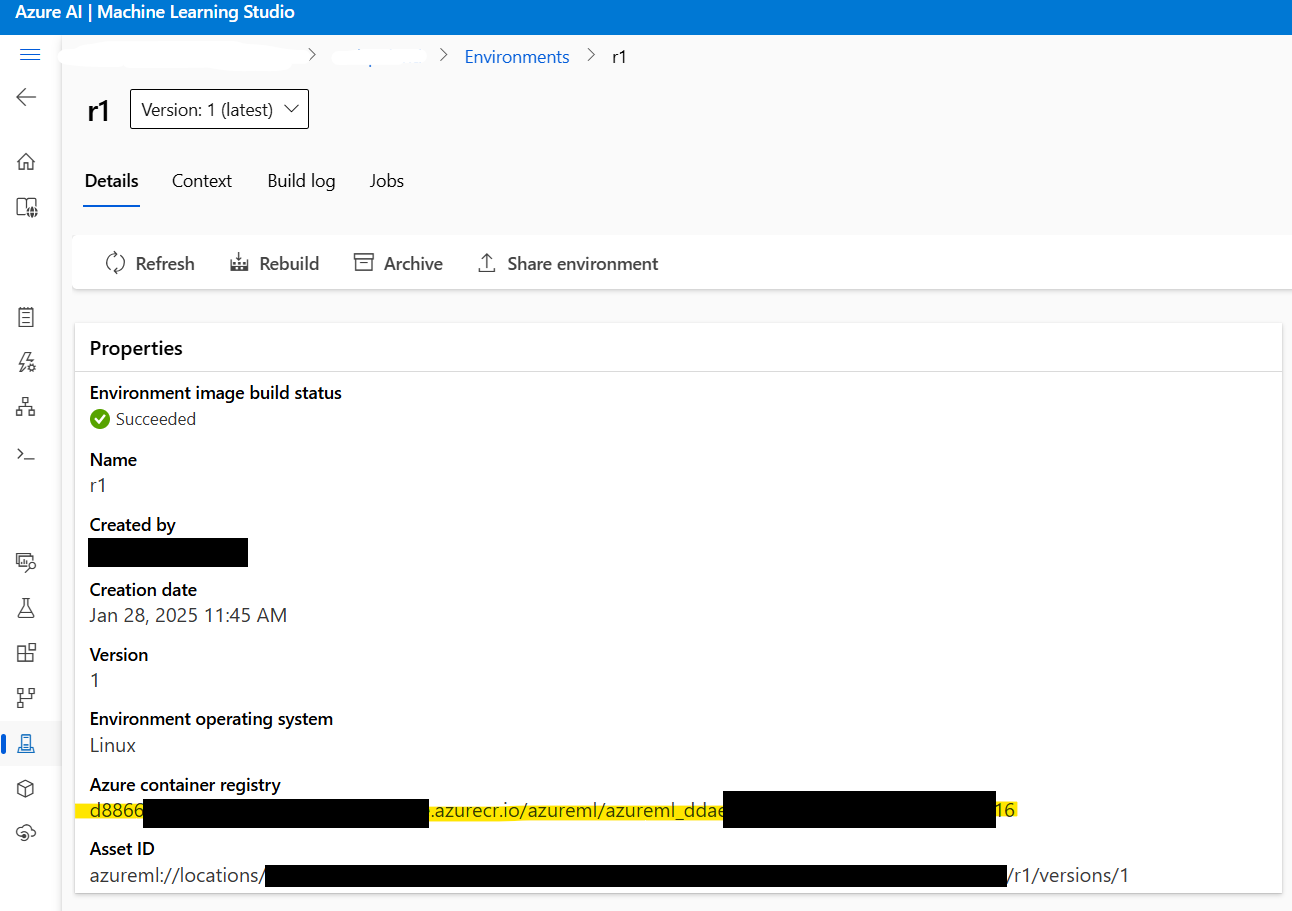
2.4: デプロイメント設定ファイルを作成する:次に、デプロイメント設定を構成するdeployment.ymlファイルを作成します。このファイルは、モデル、インスタンスタイプ、その他のパラメータを指定します:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # vLLMランタイムのオプション引数
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # ここにDockerイメージのアドレスを貼り付けます
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # オプションですがスループットを最適化するために重要です
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # モデルが平和に読み込まれるのを待つために、120秒待ちます
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
考慮すべき重要なパラメータ:
instance_count:Standard_NC24ads_A100_v4のノード数を定義します。この値を増やすことでスループットがリニアに拡大しますが、その分コストも増加します。max_concurrent_requests_per_instance:インスタンスごとに許可される同時リクエスト数を制御します。高い値はスループットを増加させますが、レイテンシを増加させる可能性があります。request_timeout_ms:エンドポイントがタイムアウトする前に待機する最大時間(ミリ秒)を指定します。これはワークロード要件に基づいて調整してください。
2.5: モデルをデプロイする:最後に、次のコマンドでDeepseek R1モデルをデプロイします:
az ml online-deployment create -f deployment.yml --all-traffic
このステップでデプロイメントが完了し、モデルは指定されたエンドポイントを介してアクセス可能になります。
ステップ3: デプロイメントのテスト
デプロイが完了したら、すべてが期待通りに機能しているかを確認するためにエンドポイントをテストします。
3.1: エンドポイントの詳細を取得する:次のコマンドを使用してエンドポイントのスコアリングURIとAPIキーを取得します:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: OpenAI SDKを使用してストリーミング応答:ストリーミング応答にOpenAI SDKを使用できます:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "夏と冬、どちらが良いですか?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
ステップ4: モニタリングとオートスケーリング
Azure MonitorはGPUメトリクスを含むリソース利用状況に関する包括的な洞察を提供します。常に負荷がかかっている場合、vLLMは約90%のGPUメモリを消費し、GPU使用率は100%近くに達することがわかります。これらのメトリクスは、パフォーマンスを微調整し、コストを最適化するのに役立ちます。
オートスケーリングを有効にするには、トラフィックパターンに基づいてスケーリングポリシーを構成します。例えば、ピーク時間中にinstance_countを増やし、オフピーク時に減らしてパフォーマンスとコストをバランスさせることができます。
オプション3: Digital OceanでのDeepseek R1のデプロイ
最後に、簡素さと手頃な価格で知られるDigital OceanでDeepseek R1をデプロイする方法について話しましょう。
前提条件
デプロイメントプロセスに進む前に、必要なものがすべて揃っていることを確認してください:
- DigitalOceanアカウント:まだ持っていない場合は、DigitalOceanアカウントにサインアップしてください。新規ユーザーには最初の60日間で使用できる100ドルのクレジットが提供され、GPU搭載のドロップレットでの実験にぴったりです。
- Bashシェルに慣れていること:ターミナルを使用してドロップレットと対話し、依存関係をダウンロードし、コマンドを実行します。専門家でなくても心配いりません。各コマンドは手順ごとに提供されます。
- GPUドロップレット:DigitalOceanは現在、AI/MLワークロード専用のGPUドロップレットを提供しています。これらのドロップレットにはNVIDIA H100 GPUが装備されており、Deepseek R1のような大規模なモデルをデプロイするのに理想的です。
これらの前提条件が整ったら、前進する準備が整いました。
GPUドロップレットの設定
最初のステップは、マシンを設定することです。これは、絵を描く前にキャンバスを準備するようなものです。詳細に入る前にすべてを準備したいと思います。
ステップ1: 新しいGPUドロップレットを作成する
- DigitalOceanアカウントにログインし、Dropletsセクションに移動します。
- Create Dropletをクリックし、AI/ML Readyオペレーティングシステムを選択します。このOSはCUDAドライバーやGPU加速に必要な他の依存関係を事前に設定しています。
- Deepseek R1の最大671Bパラメータバージョンをデプロイする予定がない限り、単一のNVIDIA H100 GPUを選択します。
- ドロップレットが作成されるまで待ちます。このプロセスは通常数分で完了します。
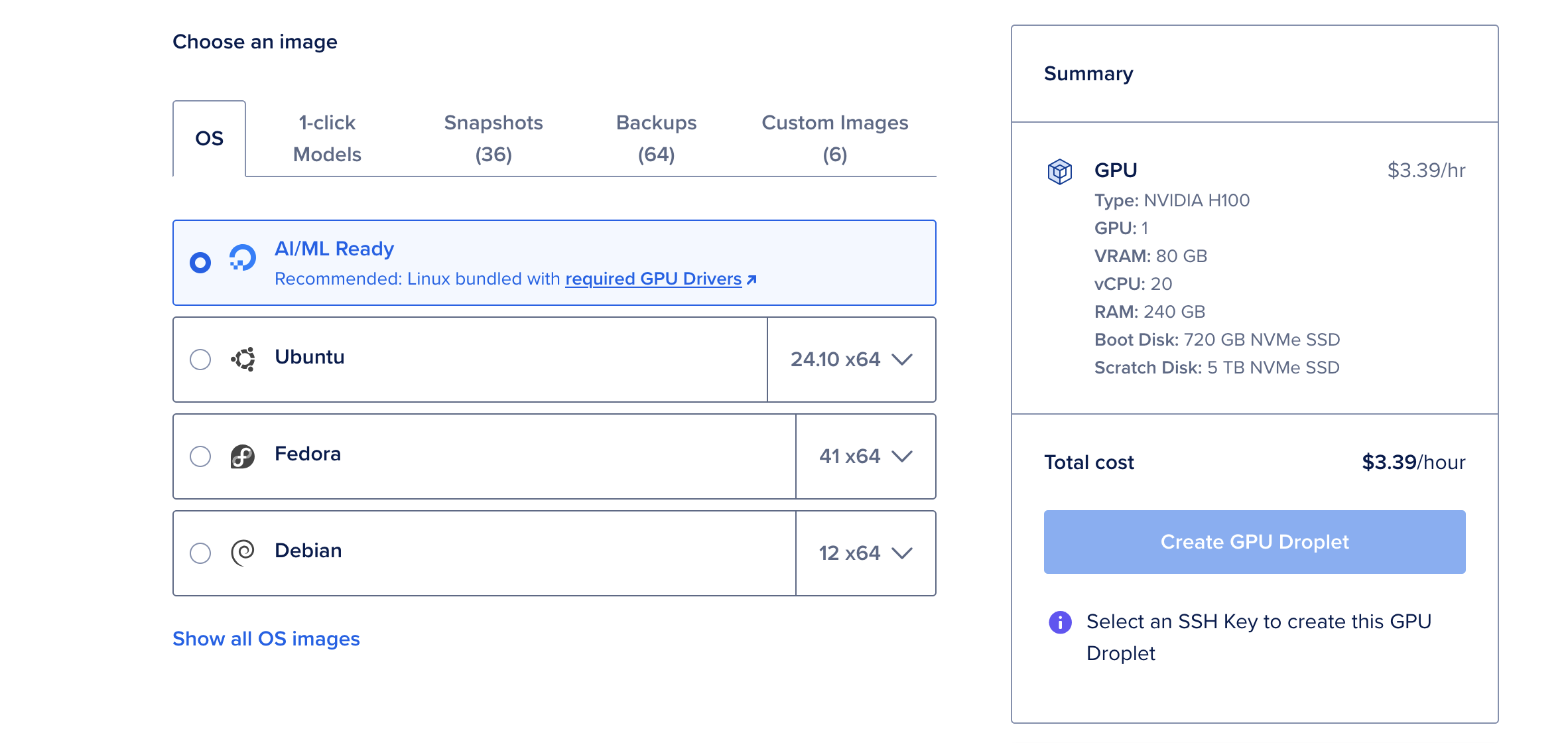
なぜH100 GPUを選ぶのか?
NVIDIA H100 GPUは、80GBのvRAM、240GBのRAM、720GBのストレージを提供するパワーハウスです。時間あたり6.47ドルというコスト効果の高いオプションで、大規模な言語モデルのデプロイに適しています。70Bパラメータバージョンなどの小型モデルには、単独のH100 GPUで十分です。
OllamaとDeepseek R1のインストール
GPUドロップレットが稼働しているので、Deepseek R1を実行するために必要なツールをインストールする時間です。大規模な言語モデルのデプロイを簡略化するために設計された軽量フレームワークであるOllamaを使用します。
ステップ1: ウェブコンソールを開く
ドロップレットの詳細ページから、右上隅にあるWeb Consoleボタンをクリックします。これにより、SSH設定が必要ないブラウザー内にターミナルウィンドウが開きます。
ステップ2: Ollamaをインストールする
ターミナルに次のコマンドを貼り付けてOllamaをインストールします:
curl -fsSL https://ollama.com/install.sh | sh
このスクリプトは、すべての必要な依存関係をダウンロードおよび構成するインストールプロセスを自動化します。インストールには数分かかることがありますが、完了すればマシンはDeepseek R1を実行する準備が整います。
ステップ3: Deepseek R1を実行する
Ollamaがインストールされたら、Deepseek R1を実行するのは単一のコマンドを実行することと同じくらい簡単です。このデモでは、パフォーマンスとリソース使用のバランスを取る70Bパラメータバージョンを使用します:
ollama run deepseek-r1:70b
このコマンドを初めて実行すると、モデルがダウンロードされ(約40GB)、メモリにロードされます。このプロセスは数分かかることがありますが、その後の実行はモデルがローカルにキャッシュされているため、はるかに高速になります。
モデルがロードされると、Deepseek R1と対話を開始できるインタラクティブなプロンプトが表示されます。まるで高度に知的なアシスタントと会話しているかのようです!
Apidogによるテストとモニタリング
Deepseek R1モデルがデプロイされたら、そのパフォーマンスをテストしてモニタリングする時間です。ここでApidogが輝きます。
Apidogとは何ですか?
Apidogは、デバッグと検証を簡素化するために設計された強力なAPIテストツールです。その直感的なインターフェイスを使用すると、テストケース、モック応答の作成、APIの健康状態のモニタリングが迅速に行えます。

なぜApidogを使用するのか?
- 使いやすさ:コーディング不要!ドラッグアンドドロップ機能を使って視覚的にテストを構築できます。
- 統合能力:CI/CDパイプラインとスムーズに統合され、DevOpsワークフローに最適です。
- リアルタイムの洞察:レイテンシ、エラーレート、スループットをリアルタイムでモニタリングできます。
Apidogをワークフローに統合することで、Deepseek R1のデプロイメントが信頼性を保ち、さまざまな負荷の下で最適なパフォーマンスを発揮することを保証できます。
結論
Deepseek R1をクラウドにデプロイすることは、恐れる必要はありません。上記の手順に従うだけで、AWS、Azure、またはDigital Oceanでこの最先端のモデルを成功裏にセットアップできます。テストとモニタリングプロセスを簡素化するために、Apidogのようなツールを活用することを忘れないでください。