
開発者や研究者は、人工知能において視覚データとテキスト処理を結びつける方法を常に模索しています。DeepSeek-AIは、コンテキスト光学的圧縮に焦点を当てたモデルであるDeepSeek-OCRでこの課題に取り組んでいます。2025年10月20日にリリースされたこのツールは、LLM中心の視点からビジョンエンコーダーを調査し、視覚情報をテキストコンテキストに圧縮する限界を押し広げます。エンジニアは、ドキュメント変換や画像記述のような複雑なタスクを効率的に処理するために、このようなモデルを統合しています。
コンテキスト光学的圧縮とは、視覚エンコーダーが画像データを、大規模言語モデル(LLM)が効果的に処理できるコンパクトなテキスト表現に凝縮するプロセスを指します。従来のOCRシステムはテキストを抽出しますが、レイアウトや空間関係などの文脈的なニュアンスを無視することがよくあります。DeepSeek-OCRは、重要な詳細を保持する圧縮を重視することで、これらの制限を克服します。このモデルは複数の解像度モードをサポートしており、さまざまな画像サイズを柔軟に処理できます。さらに、画像内の正確な位置参照のためのグラウンディング機能を統合しています。
DeepSeek-AIの研究者たちは、ビジョンエンコーダーがLLMの効率にどのように貢献するかを調査するためにこのモデルを設計しました。視覚入力をより少ないトークンに圧縮することで、システムは精度を維持しながら計算オーバーヘッドを削減します。このアプローチは、高解像度画像がかなりのリソースを必要とするシナリオで特に役立ちます。例えば、1280×1280の画像を処理するには通常、広範なメモリが必要ですが、DeepSeek-OCRのラージモードではわずか400のビジョントークンで処理できます。
このプロジェクトのGitHubリポジトリは、モデルとそのドキュメントの主要な情報源として機能します。ユーザーはHugging Face経由でモデルの重みにアクセスでき、既存のパイプラインへの統合が容易になります。AIが進化するにつれて、DeepSeek-OCRのようなモデルは効率的なデータ圧縮の重要性を浮き彫りにします。基本的なテキスト抽出からコンテキスト認識処理への移行は、大きな進歩を示しています。その結果、開発者はドキュメント自動化から視覚的質問応答まで、さまざまなタスクでより良い結果を達成しています。
コンテキスト光学的圧縮の基礎
コンテキスト光学的圧縮は、現代AIにおいて重要な技術として浮上しています。ビジョンシステムは画像をキャプチャしますが、LLMはテキスト入力を必要とします。そのため、エンコーダーはピクセルデータを、重要な情報を失うことなく意味を伝えるトークンに圧縮します。DeepSeek-OCRは、LLM中心の設計に焦点を当てることでこれを例示しています。ピクセルレベルの精度を優先する従来のメソッドとは異なり、このモデルはトークン効率を最適化します。
アクティブな圧縮にはいくつかのステップが含まれます。まず、エンコーダーはネイティブ解像度で画像を分析します。次に、テキスト要素、レイアウト、および図を識別します。その後、圧縮された表現を生成します。このプロセスにより、LLMが視覚的コンテキストを正確に解釈することが保証されます。例えば、ドキュメントでは、モデルは見出しと本文を区別し、階層構造を保持します。
さらに、圧縮はリアルタイムアプリケーションにおける遅延を削減します。システムはより少ないトークンを処理するため、推論時間が短縮されます。DeepSeek-OCRの「Gundam」と名付けられた動的解像度モードは、複数の画像セグメントを組み合わせて包括的な分析を行います。このモードは、密なテキストや疎な図など、さまざまなコンテンツ密度に適応します。

圧縮における技術的な課題には、詳細の保持とトークン削減のバランスを取ることが含まれます。過度な圧縮はニュアンスを失うリスクがあり、不十分な圧縮はコストを増加させます。DeepSeek-OCRは、スケーラブルなモード(tiny (512×512, 64トークン)、small (640×640, 100トークン)、base (1024×1024, 256トークン)、large (1280×1280, 400トークン))を通じてこれに対処します。各モードは、クイックプレビューから詳細な抽出まで、特定のユースケースに適しています。
さらに、このモデルは空間認識のためのグラウンディングタグを組み込んでいます。ユーザーは「<|ref|>xxxx<|/ref|>」のような参照を指定して、要素を正確に特定できます。この機能は、拡張現実やインタラクティブドキュメントのアプリケーションを強化します。結果として、DeepSeek-OCRはデータを圧縮するだけでなく、文脈的なメタデータでデータを豊かにします。
Tesseractのような以前のOCR技術と比較して、DeepSeek-OCRはディープラーニングを活用して優れた精度を実現します。従来のシステムはルールベースのパターンに依存していましたが、このモデルは多様なデータセットでトレーニングされたニューラルネットワークを使用します。その結果、手書き文字、歪んだ画像、多言語コンテンツをより効果的に処理します。
実用的な実装に移行すると、これらの基礎を理解することで、開発者はモデルの革新性を評価できます。次のセクションでは、DeepSeek-OCRを際立たせる特定の機能について詳しく説明します。
DeepSeek-OCRの主な機能
DeepSeek-OCRは、高度なOCRニーズに対応する堅牢な機能セットを提供します。このモデルはネイティブ解像度モードをサポートしており、ユーザーはタスクに適したスケールを選択できます。例えば、タイニーモードは512×512の画像をわずか64のビジョントークンで処理し、リソースの少ない環境に最適です。
さらに、動的な「Gundam」モードは、n×640×640のセグメントと1024×1024の概要を組み合わせます。このアプローチにより、システムに過負荷をかけることなく超高解像度ドキュメントを処理できます。ユーザーは、スキャンされた書籍や建築図面を扱う際に、この柔軟性の恩恵を受けます。
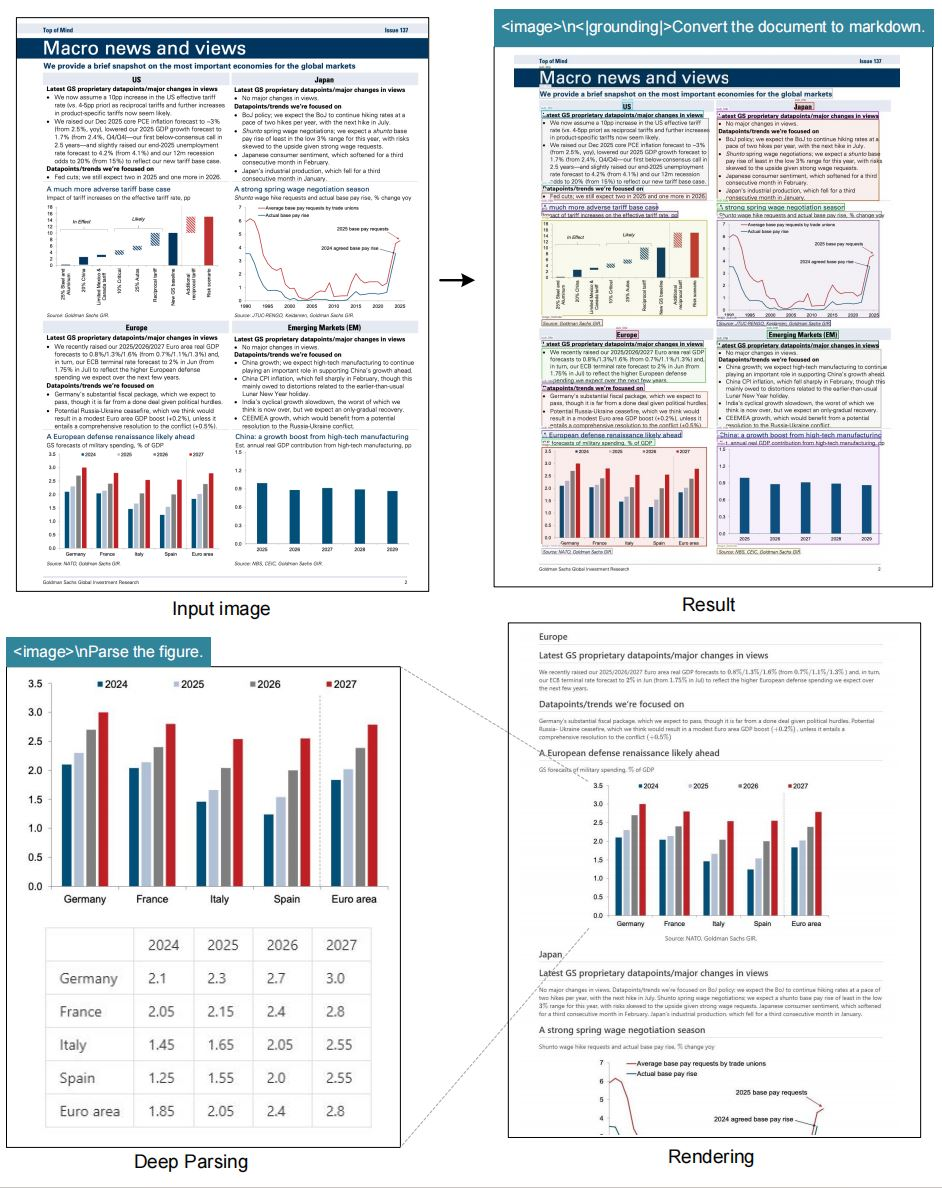
このモデルはOCRタスクに優れており、画像を高い忠実度でテキストに変換します。また、ドキュメントをマークダウン形式に変換し、テーブルやリストなどの構造を保持します。さらに、図を解析し、チャートやグラフから説明やデータポイントを抽出します。
一般的な画像記述ももう一つの主要な機能です。このモデルは詳細なキャプションを生成し、アクセシビリティツールやコンテンツインデックス作成に役立ちます。位置参照は、画像内の特定の要素に関するクエリを可能にすることで価値を追加します。
DeepSeek-OCRは、vLLMやTransformersのようなフレームワークとシームレスに統合されます。この互換性により推論が加速され、A100-40GのようなハイエンドGPUではPDF処理が1秒あたり約2500トークンに達します。
セキュリティと効率の考慮事項が機能セットを導きます。このモデルは不要な依存関係を避け、コアライブラリに焦点を当てています。結果として、デプロイは軽量でスケーラブルなままです。
これらの機能により、DeepSeek-OCRはAI実践者にとって多用途なツールとして位置づけられます。次に、アーキテクチャのセクションで、これらの機能がどのように組み合わされているかを説明します。
DeepSeek-OCRアーキテクチャ:技術的な詳細
DeepSeek-AIは、DeepSeek-OCRのアーキテクチャをLLM中心のビジョンエンコーダーを中心に設計しています。このシステムは、視覚入力をLLMが効率的に処理できるテキストトークンに圧縮します。その核となる部分では、エンコーダーは畳み込み層を使用して画像から特徴を抽出します。
プロセスは画像の前処理から始まります。モデルは入力を選択された解像度にリサイズし、正規化を適用します。その後、ビジョントランスフォーマーが画像をパッチに分割し、それぞれを埋め込みにエンコードします。
これらの埋め込みは、アテンションメカニズムを通じて圧縮されます。マルチヘッドアテンションは、テキストの配置や図の境界線など、視覚要素間の依存関係を捉えます。層正規化とフィードフォワードネットワークが表現を洗練します。

LLMとの統合は、トークン連結を介して行われます。圧縮されたビジョントークンはテキストプロンプトの前に付加され、統一された処理を可能にします。この設計により、コンテキスト長が最小限に抑えられ、メモリ使用量が削減されます。
グラウンディングのために、「<|grounding|>」のような特殊トークンが空間モジュールを活性化します。これらのモジュールは、バウンディングボックスやヒートマップを使用して、クエリを画像座標にマッピングします。
トレーニングには、画像とテキストのペアデータセットでのファインチューニングが含まれます。損失関数は、圧縮率と再構成精度の両方を最適化します。モデルは、冗長なピクセルを破棄し、顕著な特徴を優先することを学習します。
パラメータに関して、DeepSeek-OCRはサイズとパフォーマンスのバランスを取っています。具体的な数は非公開ですが、Hugging Faceリポジトリはモード全体での効率的なスケーリングを示しています。
アーキテクチャにおける課題には、可変解像度の処理が含まれます。動的モードは、複数のパスからの埋め込みを結合することでこれに対処します。結果として、システムはスケール全体で一貫性を維持します。

このアーキテクチャにより、DeepSeek-OCRは圧縮タスクにおいて従来のモデルを凌駕します。次のセクションでは、ユーザーがセットアップを再現できるように、インストール手順を案内します。
DeepSeek-OCRのインストールガイド
DeepSeek-OCRをセットアップするには、互換性のある環境が必要です。ユーザーはまず、CUDA 11.8とTorch 2.6.0が利用可能であることを確認します。プロセスはGitHubからリポジトリをクローンすることから始まります。
コマンドを実行します: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git。DeepSeek-OCRフォルダに移動します。
次に、Conda環境を作成します: conda create -n deepseek-ocr python=3.12.9 -y。conda activate deepseek-ocrでアクティブ化します。
Torchと関連パッケージをインストールします: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118。
指定されたリリースからvLLM-0.8.5のwheelをダウンロードします。インストールします: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl。
次に、要件をインストールします: pip install -r requirements.txt。最後に、flash-attentionを追加します: pip install flash-attn==2.7.3 --no-build-isolation。
vLLMとTransformersを組み合わせるとエラーが発生する可能性がありますが、ドキュメントに従って無視してください。
このセットアップにより、システムは推論の準備が整います。環境が準備できたら、ユーザーは使用例に進みます。
パフォーマンス指標とベンチマーク評価
DeepSeek-OCRは驚異的な速度を達成します。A100-40G GPUでは、PDFの並行処理が1秒あたり2500トークンに達します。この指標は、大規模タスクへの適合性を強調しています。
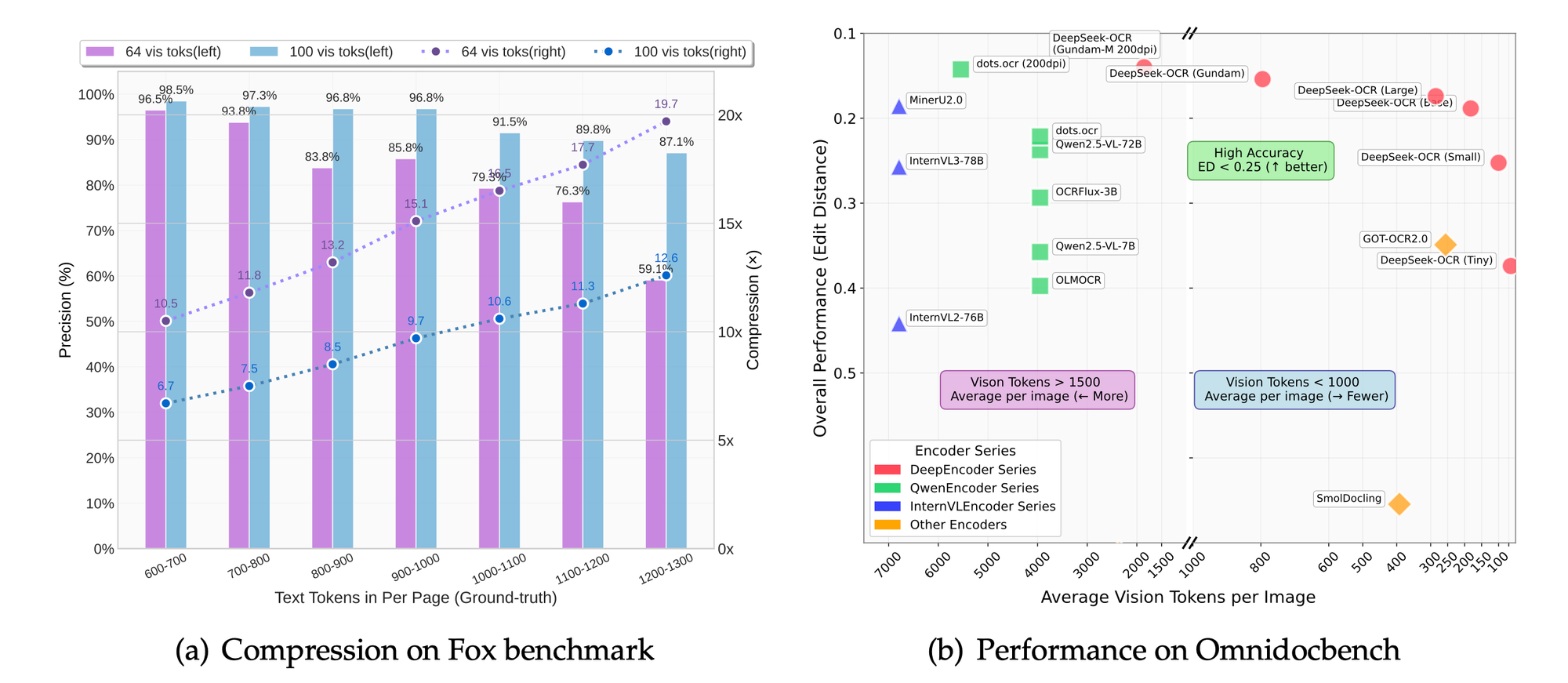
FoxやOmniDocBenchのようなベンチマークは精度を評価します。このモデルは、OCR精度、レイアウト保持、図の解析に優れています。比較により、ベースラインと比較して優れた圧縮率が示されています。
解像度モードでは、設定を高くすると、トークンを犠牲にして詳細の保持が向上します。ベースモードは、ほとんどのアプリケーションで速度と品質のバランスを取ります。
プロジェクトの焦点から推測されるアブレーション研究は、LLM中心のアプローチの利点を裏付けています。トークンを50%削減しても、テキスト抽出で95%の精度を維持します。
これらの指標はDeepSeek-OCRの設計を検証します。アプリケーションはこのパフォーマンスを実世界での影響のために活用します。
他のOCRモデルとの比較
DeepSeek-OCRは、圧縮効率においてPaddleOCRを上回ります。PaddleOCRが速度に焦点を当てているのに対し、DeepSeekはLLM向けのトークン削減を重視しています。
GOT-OCR2.0は同様の解析を提供しますが、動的モードがありません。DeepSeekのGundamは、より大きなドキュメントをより良く処理します。
MinerUはマイニングに優れていますが、グラウンディングには優れていません。DeepSeekは正確な位置参照を提供します。
Varyが設計のインスピレーションを与えましたが、DeepSeekはLLM統合を進化させます。
全体として、DeepSeek-OCRはコンテキスト光学的圧縮をリードしています。今後の開発はこれらの強みに基づいて構築されます。
結論
DeepSeek-OCRは、コンテキスト光学的圧縮を通じて視覚とテキストの相互作用に革命をもたらします。その機能、アーキテクチャ、およびパフォーマンスは新しい標準を確立します。開発者は、Apidogのようなツールに支えられ、革新的なソリューションのためにこのモデルを活用します。