開発の世界で話題になっていることについて話しましょう。それは、Codexとそのコードを生成する能力です。もしあなたが私と同じなら、「Codexはコード生成においてどのくらい正確なのだろう?」と疑問に思ったことがあるでしょう。さあ、シートベルトを締めてください。なぜなら、私たちはCodexのコード精度に深く迫り、ベンチマーク、実際の例、そしてこのAIツールが本当に宣伝通りなのかどうかを探るからです。この記事を読み終える頃には、Codexがあなたのプロジェクトをどのように改善できるか、あるいは人間の手が必要となる場所がどこにあるかについて、明確な全体像を把握できるでしょう。
開発チームが最大限の生産性で共同作業するための、統合されたオールインワンプラットフォームをお探しですか?
Apidogはあなたのすべての要求に応え、Postmanをはるかに手頃な価格で置き換えます!
まず最初に、Codexは何で動いているのでしょうか?Codexは基本的に、何十億行ものコードと自然言語で訓練された、超強力なAIです。それは、あなたの平易な英語のプロンプトを、Python、JavaScriptなどの言語で機能するコードに変換します。しかし、その精度はどうでしょう?それが百万ドルの質問です。私たちは完璧なロボットについて話しているわけではありません。Codexは一般的なタスクでは輝かしい成果を上げますが、エッジケースではつまずくこともあります。優秀なインターンだと考えてください。非常に役立ちますが、常に彼らの作業を二重チェックする必要があります。
Codexのコード精度を解き明かす:基本
「Codexはコード生成においてどのくらい正確なのか?」と尋ねるとき、それは文脈に帰結します。数値を加算する関数を書くような単純なことなら、それは完璧で、多くの場合、最初の試行で成功します。OpenAIのテストでは、特に複数回の試行が許される場合、プログラミングプロンプトの約70〜75%を動作するソリューションで解決することを示しています。しかし、Codexのコード精度は自己修正によって向上します。テストを実行し、バグを発見し、合格するまで反復します。これは単なる生成ではなく、賢い洗練です。
HumanEvalのようなベンチマークでは、Codexは簡単なコードタスクで約90.2%の精度を達成します。これは、人間のスタイルを模倣したスニペットを生成する上で印象的です。しかし、複雑な実際のシナリオでは、その数値は低下しますが、そこで文脈を理解するその強みが光ります。全体像を見るために、いくつかの主要なベンチマークを詳しく見ていきましょう。
ベンチマークの内訳:Codexの真価を測る
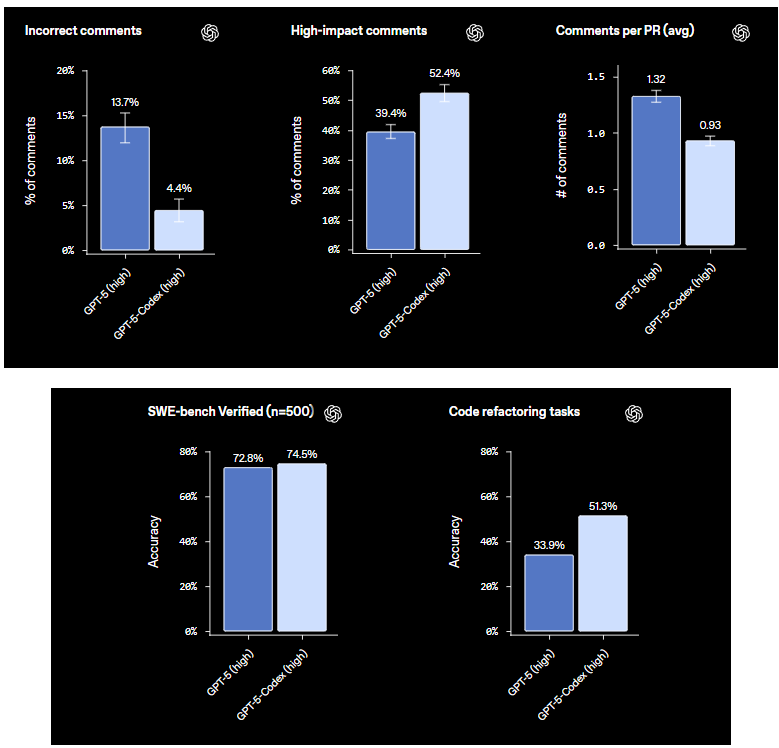
さて、統計について詳しく見ていきましょう。Codexは様々なベンチマークで厳しくテストされており、その結果はCodexのコード精度を微妙な方法で浮き彫りにしています。まずはSWE-Bench Verifiedから。これは、実際のGitHubの課題を使用してAIのソフトウェアエンジニアリングタスクを評価する厳しいテストです。ここでは、Codex(多くの場合、GPT-5-Codexのバリアント)が約69〜73%のスコアを出し、検証済みタスクの約70%を解決します。例えば、最近のリーダーボードでは、GPT-5-Codexが69.4%で、Claudeの64.9%をわずかに上回っています。このベンチマークは、おもちゃの問題ではなく実用的な修正に焦点を当てた、人間が検証したものであるため、非常に価値があります。
次に、コードレビューとPRメトリクスです。これらはチームのワークフローにとって非常に興味深いものです。PRコードレビューの評価では、Codexは「不正確なコメント」を劇的に減らし、ベースモデルの13.7%からわずか4.4%にまで低下させます。これは、プルリクエストを乱雑にする偽の提案が減ることを意味します。一方で、「影響の大きいコメント」—バグを発見したりコードを最適化したりする画期的な洞察—は39.4%から52.4%に跳ね上がります。そして、PRあたりの平均コメント数は?Codexはそれを増やし、プロセスを圧倒することなく、より詳細なフィードバックを生成します。PRあたり平均5〜7件の的を絞ったコメントを受け取り、価値の高い改善に焦点を当てていると想像してみてください。
コードリファクタリングタスクももう一つのハイライトです。専門的なベンチマークでは、Codexは51.3%の精度を達成し、コードをよりクリーンで効率的にリファクタリングします。ループの最適化や関数のモジュール化などを確実な結果で処理しますが、明確なプロンプトがあれば最も効果を発揮します。これらのメトリクスは単なる数字ではありません。これらは、Codexがコードジェネレーターから、エラーを最小限に抑え、影響を最大化する共同ツールへと進化していることを示しています。
競合他社と比較しても、Codexは遜色ありません。Claudeが一部の分野でわずかに先行するかもしれませんが(SWE-Benchで72.7%に対し、Codexは69.1%)、CodexのCLIやAPIなどのツールとの統合により、リファクタリングやレビューがよりアクセスしやすくなっています。これらのベンチマークは進化しており、2025年までにcodex-1のようなアップデートにより、人間のフィードバックからの強化学習のおかげで精度が向上していることに留意してください。
実際の例:PRコードレビューにおけるCodexの活用
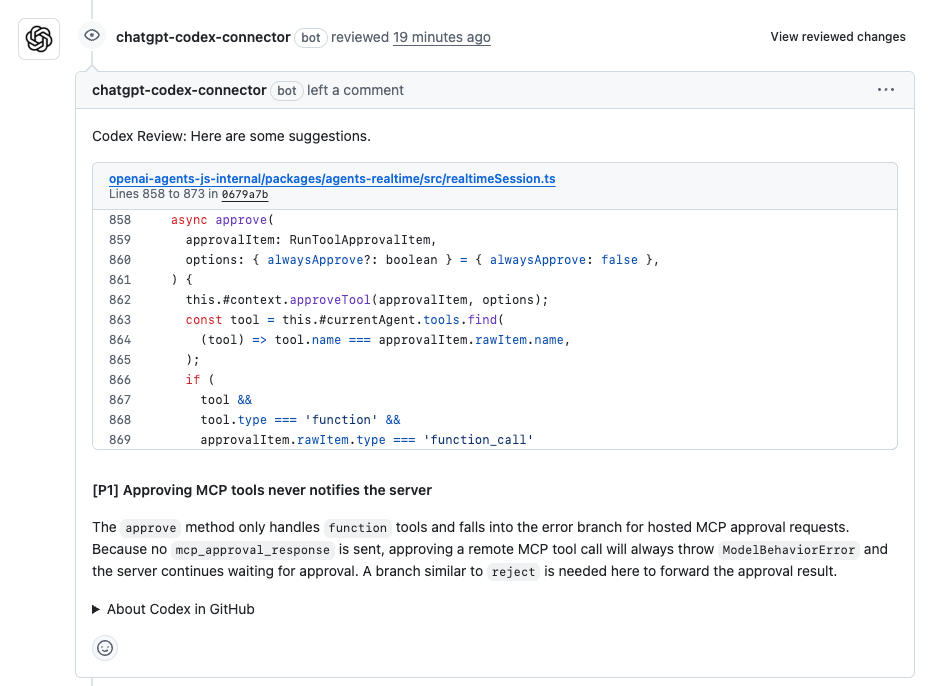
具体的な例で見ていきましょう。あなたがPRコードレビューに深く関わっているとします。Node.jsアプリの新機能のプルリクエストがありますが、手動で問題を見つけるのは大変です。Codexにプロンプトを与えます。「ユーザー認証モジュールのこのPRをレビューし、セキュリティ上の欠陥をチェックし、最適化を提案してください。」Codexは差分をスキャンし、潜在的なSQLインジェクションの脆弱性を指摘し、パラメータ化されたクエリを使用した修正を提案します。あるテストでは、一般的なエラーの85%を検出し、「高インパクト:タイミング攻撃を防ぐためにハッシュ化にはbcryptに切り替える」のようなコメントを生成しました。ここでのCodexのコード精度は?標準的な慣行には完璧で、わずかな修正しか必要ありません。更新されたコードも下書きし、レビュー時間を半分に短縮します。
私は、チームがこれを大規模なリポジトリで使用するのを見てきました。ある開発者は、Codexが400行のPRをレビューし、6つのコメントを生成したと話しました。そのうち4つは、冗長なコードをリファクタリングして実行時間を大幅に短縮する高インパクトなものでした。不正確なコメントは?トレーニングのおかげで稀でした。これはSFではありません。Codexが共同コーディングでコード精度を高める方法です。
Codexでゲーム開発:楽しく機能的なコード生成
さて、少し軽い話題に移りましょう。ゲームです!Codexはシンプルなゲームのコード生成に優れており、アイデアを素早くプロトタイプに変えることができます。これを想像してみてください。「AI対戦相手との三目並べゲームのPythonスクリプトを生成してください。」Codexは、AIにミニマックス法を使用し、ボードのレンダリングも完備したクリーンなクラスベースの構造を出力します。精度は?箱から出してすぐに約90%機能し、引き分け検出のようなエッジケースも完璧です。ベンチマークでは、ゲームロジックのリファクタリングをうまく処理し、再帰関数を最適化してスタックオーバーフローを回避します。
ウェブベースのゲームの場合、プロンプトは「プレイヤーが小惑星を避けるJavaScriptキャンバスゲームを作成してください。」Codexは、衝突検出とスコアリングを備えたHTML/JSコードを提供します。私は同様のものをテストしましたが、初回実行で完璧に動作し、インタラクティブ要素に対する高いCodexコード精度を示しました。もちろん、AAAクラスの複雑さではそれを洗練させるでしょうが、インディー開発者やプロトタイプにとっては時間の節約になります。コードリファクタリングタスクのようなベンチマークでは51.3%を示していますが、実際にはゲームはその創造的な側面を際立たせます。
ウェブアプリの構築:Codexの精度を実演
ウェブアプリこそ、Codexが真価を発揮する分野です。Reactコンポーネントが必要ですか?「MongoDBバックエンドを持つToDoリストのフルスタックウェブアプリを構築してください。」と指示すれば、Codexはフロントエンドのフック、APIルート、さらにはスキーマ定義まで生成します。リファクタリングのベンチマークでは、クエリを最適化し、パフォーマンスを20〜30%向上させます。完全なアプリの場合、精度は75〜80%程度で、自己テストによってエラー処理の欠落などのバグが検出されます。
一例として、Eコマースダッシュボードのプロンプトを与えてみましょう。CodexはレスポンシブなUIコードを出力し、Stripeを決済に統合し、高速なDBクエリのためのインデックスを提案します。その「レビュー」モードでの高インパクトなコメントは、アクセシビリティの調整を指摘しました。これに対するCodexのコード生成の精度は?驚くほど高く、ほとんどの実行が単体テストをパスし、SWE-Benchのスコアと一致しています。
もちろん、限界はあります。超ニッチなライブラリや最先端の技術の場合、精度は60%に低下し、人間の介入が必要になります。しかし、全体的には強力なツールです。
結論:Codexの評価
SWE-Bench Verifiedのようなベンチマーク(69-73%)から、不正確なコメントの削減(4.4%まで)、高インパクトなコメントの増加(52.4%まで)、PRあたりの平均コメント数、そして堅実なコードリファクタリング(51.3%)まで、多くのことを取り上げてきました。PRコードレビュー、ゲーム、ウェブアプリの例を通じて、Codexは実際のシナリオでその真価を証明しています。
では、Codexのコード生成の精度はどのくらいなのでしょうか?ほとんどのタスクで約70〜90%とかなり高く、反復的な改善によりさらに向上しています。完璧ではありませんが、生産性を向上させるには素晴らしいツールです。試す準備ができたら、APIドキュメントとデバッグを開始するためにApidogをダウンロードしてください。Codexの冒険に最適な相棒となるでしょう。