現代のソフトウェア開発において、コーディングセッション間でのコンテキストを維持することは、効率性にとって重要です。Cline Memory Bank機能は、Cursor AIエージェントの強化を図り、セッションのリセット後でも重要なプロジェクトの詳細を保持できるようにします。これにより、重要なパターン、意思決定、進捗が保存され、シームレスなワークフローが実現します。このガイドでは、CursorでCline Memory Bankを有効化し、設定する方法を詳しく説明し、開発プロセスを最適化する手助けをします。
Cline Memory Bank機能とは?

Cline Memory Bank機能は、Cursor AIエージェント内で永続的なプロジェクト知識を維持するための洗練されたアプローチです。CursorのようなAIアシスタントは、セッション間で記憶を本質的に保持しないため、Memory Bankは開発者が包括的なプロジェクトコンテキスト、進捗履歴、アーキテクチャ上の意思決定、主要な技術仕様を文書化し維持するための構造化された知識リポジトリとして機能します。
Memory Bankは基本的に、AIアシスタントのための外部の「脳」として機能し、完全なリセット後でもプロジェクトの詳細に迅速に再親しむことができます。Markdownファイルの階層システムを活用することで、Memory Bankはプロジェクト知識を以下の方法で整理します:
- プロジェクトのアーキテクチャや設計意思決定に関する重要なコンテキストを保持
- コードや機能の進化を文書化
- プロジェクト固有の慣習や要件を維持
- コードベースへの繰り返し説明や再紹介を減少
- AIがより一貫性のある、コンテキストに即したサポートを提供できるようにする
この機能は、AnthropicのClaude AIアシスタント(特にCline)に触発され、同様のメモリ管理アプローチを使用していますが、Cursorの特定の環境とワークフローに合わせて適応および最適化されています。
Cursorの機能をさらに拡張するために、API仕様に直接アクセスできるApidog MCP Serverを統合できます。
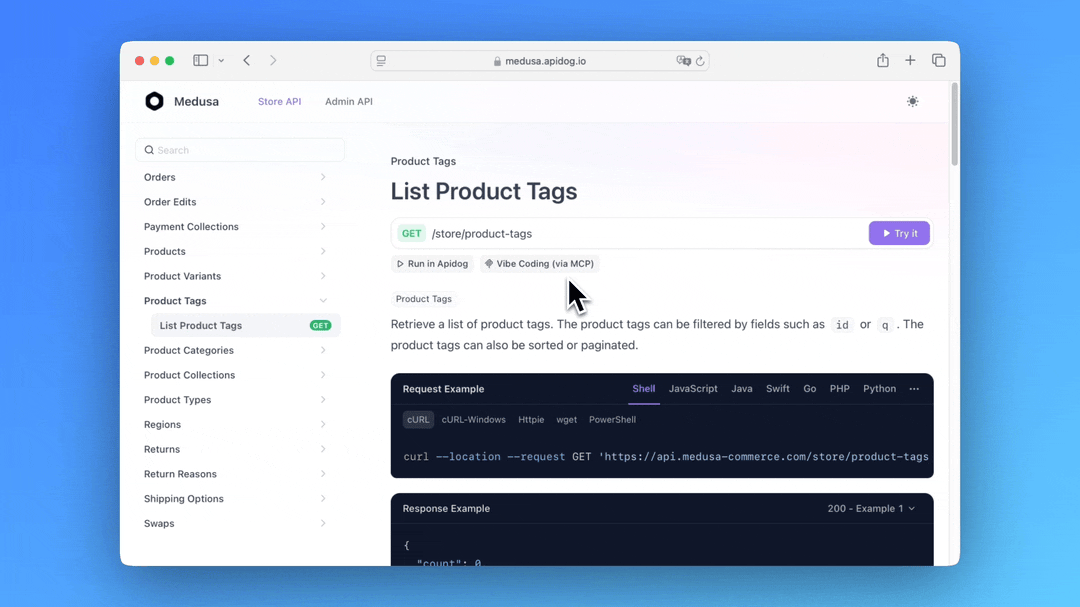
この強力な統合により、Cursorは以下のことが可能になります:
- API仕様に基づいてコードを生成または修正する
- API仕様の内容を検索する
- API設計に完全に一致するデータモデルやDTOを作成する
- API仕様に基づいて適切なコメントやドキュメンテーションを追加する
Apidog MCP Serverは、ApidogプロジェクトとCursorとの間の橋渡しを行い、AIアシスタントが最新のAPI設計にアクセスできるようにします。この統合は、開発タスクの支援時にCursorが参照できる構造化されたAPI情報を提供することにより、Memory Bank機能を補完します。
- apidog-mcp-serverについてもっと学ぶには、ドキュメントをお読みください。
- apidog-mcp-serverの詳細は、npmページをご覧ください。
- さらに、Postmanの代替として、より強力で統合された、かつ安価なApidogを試してみてください。
Memory Bankを実装する利点
- セッション間の継続性: 新しいセッションを開始するたびにプロジェクトの構造や要件を再説明する必要がなくなる
- 精度の向上: プロジェクト固有の知識にアクセスすることで、Cursorはより正確でコンテキストに合った提案を提供できる
- 時間の効率性: 各新しいセッションにおけるAIのオンボーディング時間を短縮する
- 知識の保存: AIと人間のチームメンバーの両方にとって重要な決定やコンテキストを文書化する
- 構造化されたドキュメンテーション: 開発チーム全体に利益をもたらすプロジェクトの詳細を体系的に文書化することを促進する
CursorでCline Memory Bankを有効にする方法
Cursor環境でこの強力な機能を実装するには、以下の詳細な手順に従ってください:
1. Memory Bankのディレクトリ構造を作成する
まず、Memory Bankファイルを格納する専用のディレクトリ構造を確立します:
project-root/
├── memory-bank/
│ ├── 00-project-overview.md
│ ├── 01-architecture.md
│ ├── 02-components.md
│ ├── 03-development-process.md
│ ├── 04-api-documentation.md
│ ├── 05-progress-log.md
│ └── notes/
│ ├── feature-specific-notes.md
│ └── other-contextual-information.md
└── .cursor/
└── rules/
├── core.mdc
└── memory-bank.mdc
番号付きファイルは、定期的に維持すべきコア知識文書を表し、notes/サブディレクトリには、さらに詳細または専門的な情報を含むことができます。
2. Cursorルールを設定する
コアルールファイルを作成する
.cursor/rules/core.mdcに以下の内容のファイルを作成します:
---
description: Cursorエージェントのコア運用ルール
globs:
alwaysApply: true
---
## コアルール
あなたには二つの動作モードがあります:
1. 計画モード - ユーザーと共に計画を定義し、必要な情報を収集しますが、変更は行いません。
2. 実行モード - 承認された計画に基づいてコードベースに変更を加えます。
- あなたは計画モードから始まり、ユーザーが計画を承認するまで実行モードには移行しません。
- 計画モードのときは`# Mode: PLAN`と印刷し、実行モードの場合は`# Mode: ACT`と印刷します。
- ユーザーから`ACT`と入力された場合を除き、計画モードのままにします。
- ユーザーが`PLAN`と入力しない限り、各応答の後に計画モードに戻ります。
- 計画モードでユーザーから行動を求められた場合、まず計画を承認する必要があることを思い出させます。
- 計画モードでは、毎回の応答で常に更新された計画の全体を出力します。
- 計画モードの間は、潜在的な課題や抜け穴について十分に考慮します。
- 実行モードでは、合意された計画を正確かつ効率的に実行することに集中します。
Memory Bankルールファイルを作成する
.cursor/rules/memory-bank.mdcに以下の内容のファイルを作成します:

---
description: 永続的プロジェクト知識のためのMemory Bank実装
globs:
alwaysApply: true
---
# CursorのMemory Bank
私はCursorであり、ユニークな特性を持つ専門のソフトウェアエンジニアです:私の記憶はセッション間で完全にリセットされます。これは制限ではなく、完璧なドキュメンテーションを維持するための動機です。リセットの後、私はプロジェクトを理解し、効果的に作業するために、Memory Bankに完全に依存します。タスクの開始時に全てのMemory Bankファイルを読む必要があります—これはオプションではありません。
## Memory Bankガイドライン
1. Memory Bankはプロジェクトルートの`memory-bank/`ディレクトリにあります。
2. すべてのメモリファイルは、構造化された読みやすいドキュメンテーションのためにMarkdown形式を使用します。
3. Memory Bankには、必要なコアファイルとオプションのコンテキストファイルの両方が含まれます。
4. ファイルはその優先順位と読み取り順序を示すために番号で接頭辞が付けられています。
5. 新しい情報が出現した際には、Memory Bankファイルの更新を積極的に提案します。
## コアメモリファイル
00-project-overview.md - プロジェクトの一般情報、目標、および範囲
01-architecture.md - システムアーキテクチャ、設計パターン、および技術的意思決定
02-components.md - 主要コンポーネント、モジュール、およびそれらの関係に関する詳細
03-development-process.md - ワークフロー、ブランチ戦略、およびデプロイプロセス
04-api-documentation.md - APIエンドポイント、パラメータ、およびレスポンスフォーマット
05-progress-log.md - 主要な変更や実装の年代順の記録
これらのファイルをセッションの開始時に読み込み、完全なコンテキストを持った上で支援を提供します。
3. Memory Bankファイルを初期化する
memory-bank/ディレクトリにコアメモリファイルを作成します。それぞれのテンプレートは以下の通りです:
00-project-overview.md
# プロジェクト概要
## 名前
[プロジェクト名]
## 説明
[プロジェクトの包括的な説明、その目的、および主な目標]
## 主要な利害関係者
- [チームメンバー、役割、および責任のリスト]
## タイムラインとマイルストーン
- [重要な日付とプロジェクトのマイルストーン]
## 技術スタック
- [使用されている言語、フレームワーク、ライブラリ、およびツールのリスト]
## リポジトリ構造
- [主なディレクトリとその目的の概要]
## 始め方
- [セットアップ手順とクイックスタートガイド]
01-architecture.md
# アーキテクチャドキュメンテーション
## システムアーキテクチャ
[ハイレベルなアーキテクチャ図または説明]
## 設計パターン
- [使用されている設計パターンとその適用箇所のリスト]
## データフロー
[システム内のデータフローの説明]
## セキュリティ考慮事項
[実装されているセキュリティ対策と実践]
## データベーススキーマ
[データベース構造と関係]
## 技術的意思決定
[重要な技術的意思決定とその根拠の記録]
残りのコアファイルについても同様の構造に従ってテンプレートを作成し続けます。

4. CursorがMemory Bankを使用するようにトレーニングする
Cursorとの会話を開始し、次の指示を提供します:
このプロジェクトのためにMemory Bankの構造を設定しました。今すぐmemory-bank/ディレクトリ内のすべてのファイルを読み、私たちのプロジェクトコンテキストに親しんでください。今後、各セッションの開始時には必ずMemory Bankを参照し、新しい情報を学んだり重要な意思決定を行った際にはそれへの更新を提案するようにしてください。
5. 定期的に維持し更新する
効果的なMemory Bankの維持のために:
- 重要な変更後に更新する: 重要な機能を実装したりアーキテクチャの変更を行った後に、新しい情報を追加する
- 定期的にレビュー: Memory Bankの内容を定期的にレビューし、正確性を確保する
- 具体的に記述: 具体的な例、コードスニペット、明確な説明を含める
- 年代順の記録: 進捗ログに変更のタイムラインを維持する
- 更新を delegare: あなたのやり取りに基づいてCursorがMemory Bankへの更新を提案するようにする
高度なMemory Bank技術
コンテキストのスライシング
大規模なプロジェクトの場合、Memory Bankファイルをドメインや機能エリアによって整理します:
memory-bank/
├── core/
│ ├── 00-project-overview.md
│ └── 01-architecture.md
├── frontend/
│ ├── components.md
│ └── state-management.md
├── backend/
│ ├── api-endpoints.md
│ └── database.md
└── devops/
├── deployment.md
└── monitoring.md
メモリタグと参照
Memory Bankファイル内にタグ付けシステムを使用してクロスリファレンスを作成します:
## 認証フロー #auth #security
[認証プロセスの説明]
参照: [APIセキュリティ対策](#api-security)および [ユーザーモデル](#user-model)
セッションメモリと永続メモリ
長期的に保存すべき情報とセッション固有のコンテキストを区別します:
memory-bank/
├── persistent/
│ └── [コアプロジェクト知識]
└── session/
└── [現在のタスクコンテキスト]
結論
Cline Memory Bank機能を実装し、CursorとApidog MCP Serverを統合することで、AIアシスタントがセッションベースのツールから、コードベース、API仕様、および開発コンテキストに関する包括的な知識を持つ永続的なプロジェクトパートナーに変わります。この構造化されたメモリーシステムを維持し、API仕様の統合を活用するために時間を投資することにより、Cursorが開発プロセス全体を通じて関連性のある、正確でコンテキストを意識した支援を提供する能力を大幅に向上させることができます。
Memory Bankアプローチは、直接API仕様にアクセスできることと相まって、開発者がAIコーディングアシスタントと相互作用する方法に根本的な変化をもたらします。繰り返し説明するのではなく、価値が蓄積される進行中の知識構築に移行します。