
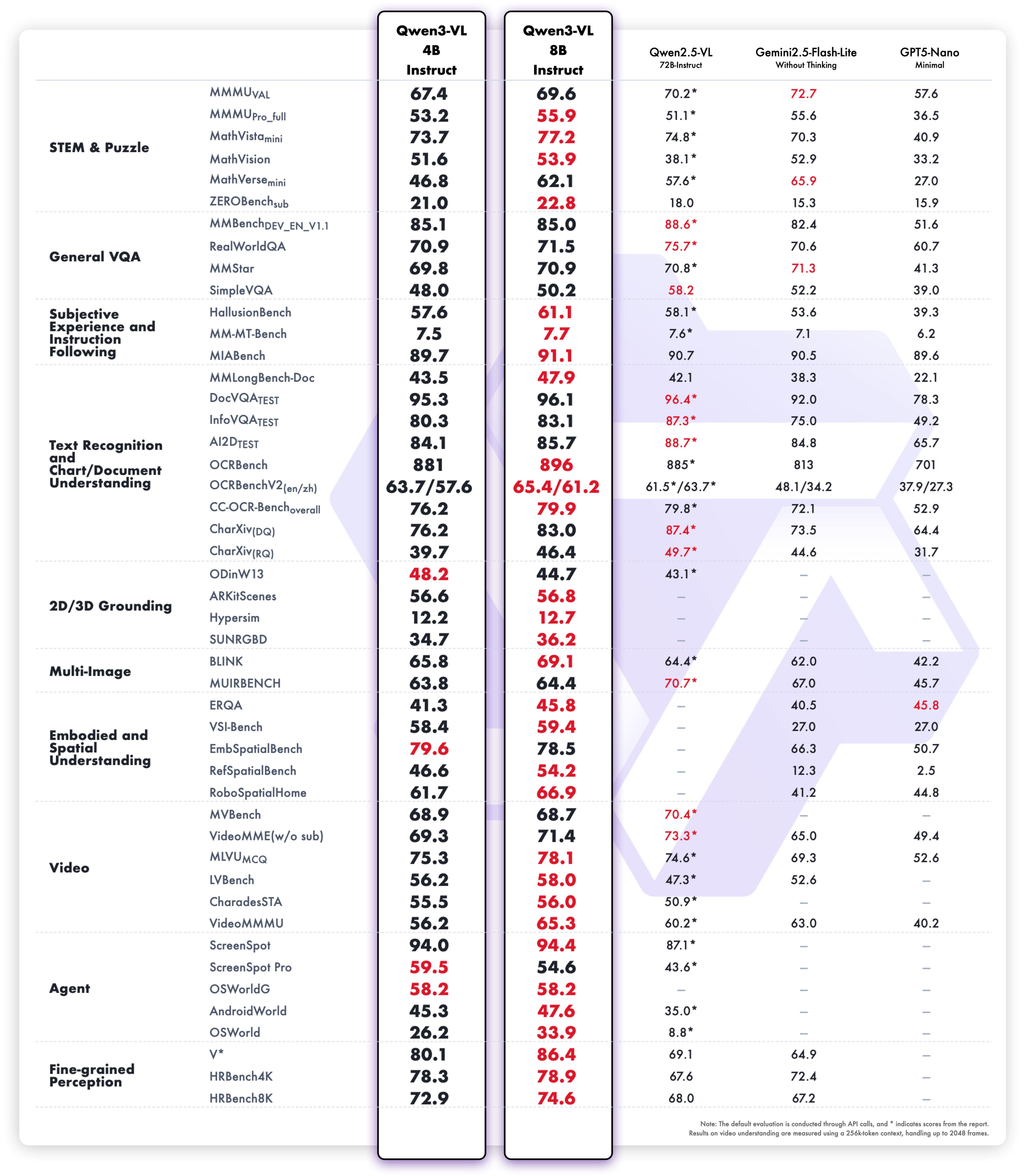
Qwen 3ファミリーは2025年のオープンソースLLM分野を席巻します。エンジニアたちは、ミッションクリティカルな企業エージェントからモバイルアシスタントまで、あらゆる場所でこれらのモデルを展開しています。Alibaba Cloudへのリクエスト送信や自己ホスティングを開始する前に、Apidogでワークフローを効率化しましょう。
Qwen 3の概要:2025年のパフォーマンスを牽引するアーキテクチャ革新
AlibabaのQwenチームは、2025年4月29日にQwen 3シリーズをリリースし、オープンソース大規模言語モデル(LLM)における画期的な進歩を示しました。開発者たちは、無制限のファインチューニングと商用展開を可能にするApache 2.0ライセンスを高く評価しています。Qwen 3は、Transformerベースのアーキテクチャを中核とし、位置埋め込みとアテンションメカニズムの強化により、ネイティブで最大128Kトークンのコンテキスト長をサポートし、YaRNを介して131Kまで拡張可能です。

さらに、このシリーズは特定のバリアントでMixture-of-Experts(MoE)設計を採用しており、推論時にごく一部のパラメーターのみをアクティブにします。このアプローチにより、出力の忠実度を維持しつつ計算オーバーヘッドを削減します。例えば、エンジニアはQwen2.5-72Bのような高密度な先行モデルと比較して、長コンテキストタスクで最大10倍高速なスループットを報告しています。その結果、Qwen 3バリアントはエッジデバイスからクラウドクラスターまで、あらゆるハードウェアで効率的にスケーリングします。
Qwen 3は多言語サポートにも優れており、119以上の言語を微妙な指示に従って処理します。ベンチマークでは、36兆トークンから精製された合成数学およびコードデータを処理するSTEM分野での優位性が確認されています。したがって、グローバル企業でのアプリケーションは、翻訳エラーの削減と多言語推論の改善から恩恵を受けます。具体的に言えば、トークナイザーフラグを介して切り替えられるハイブリッド推論モードは、モデルが数学やコーディングに対してステップバイステップの論理を使用するか、対話には非思考モードをデフォルトとすることを可能にします。この二面性により、開発者はユースケースごとに最適化できます。
Qwen 3バリアントを統一する主要機能
すべてのQwen 3モデルは、2025年におけるその有用性を高める基本的な特性を共有しています。まず、デュアルモード操作をサポートしています。思考モードはAIME25のようなベンチマークで連鎖的思考プロセスを活性化し、非思考モードはチャットアプリケーションの速度を優先します。エンジニアはシンプルなパラメータでこれを切り替え、レイテンシーを犠牲にすることなく、複雑な数学で最大92.3%の精度を達成します。
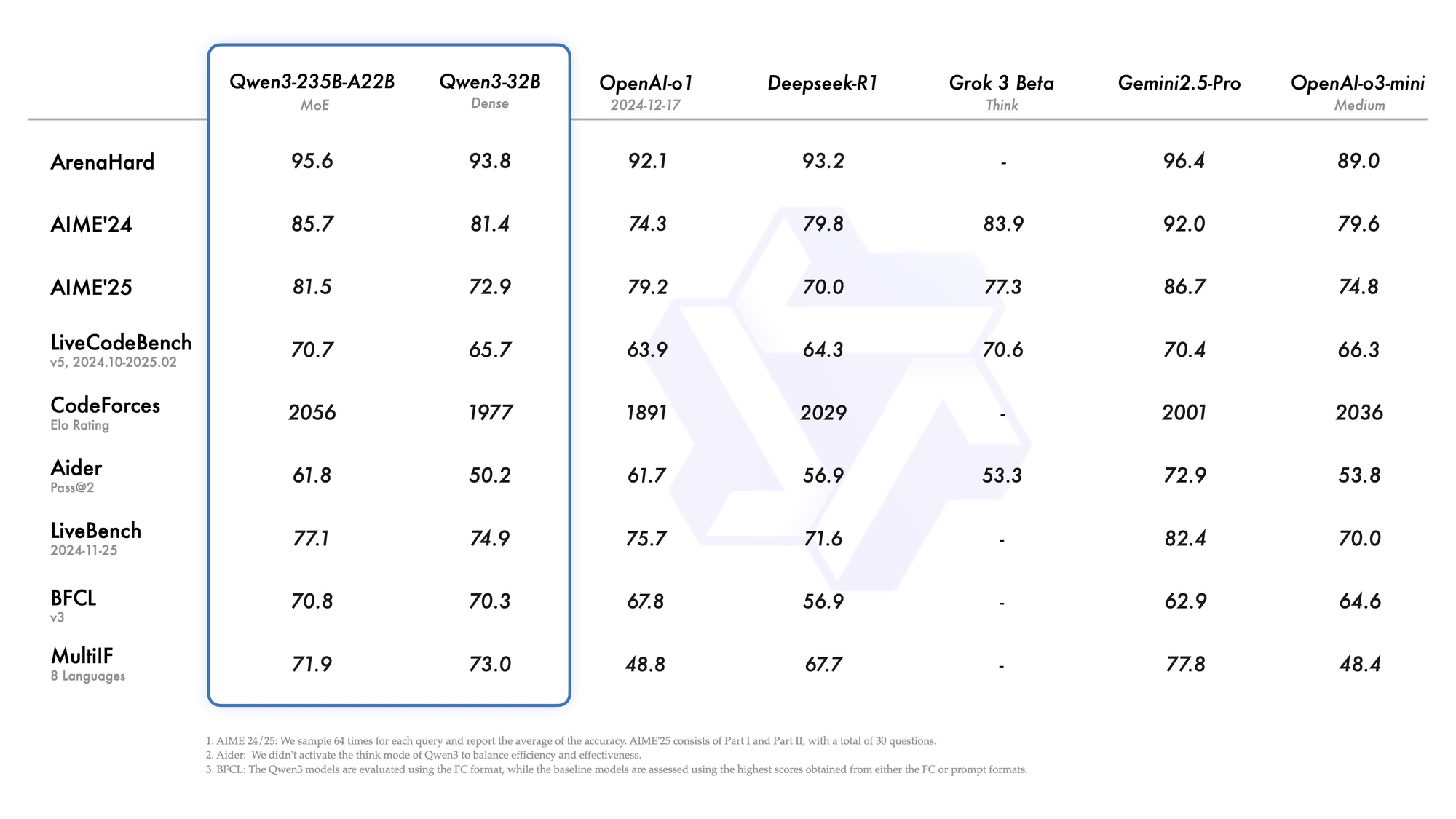
次に、エージェント機能はシームレスなツール呼び出しを可能にし、ブラウザナビゲーションやコード実行などのタスクでオープンソースの競合を凌駕します。例えば、Qwen 3バリアントはTau2-Bench Verifiedで69.6点を獲得し、プロプライエタリモデルに匹敵します。さらに、多言語能力は北京語からスワヒリ語までの方言をカバーし、MultiIFベンチマークで73.0点です。
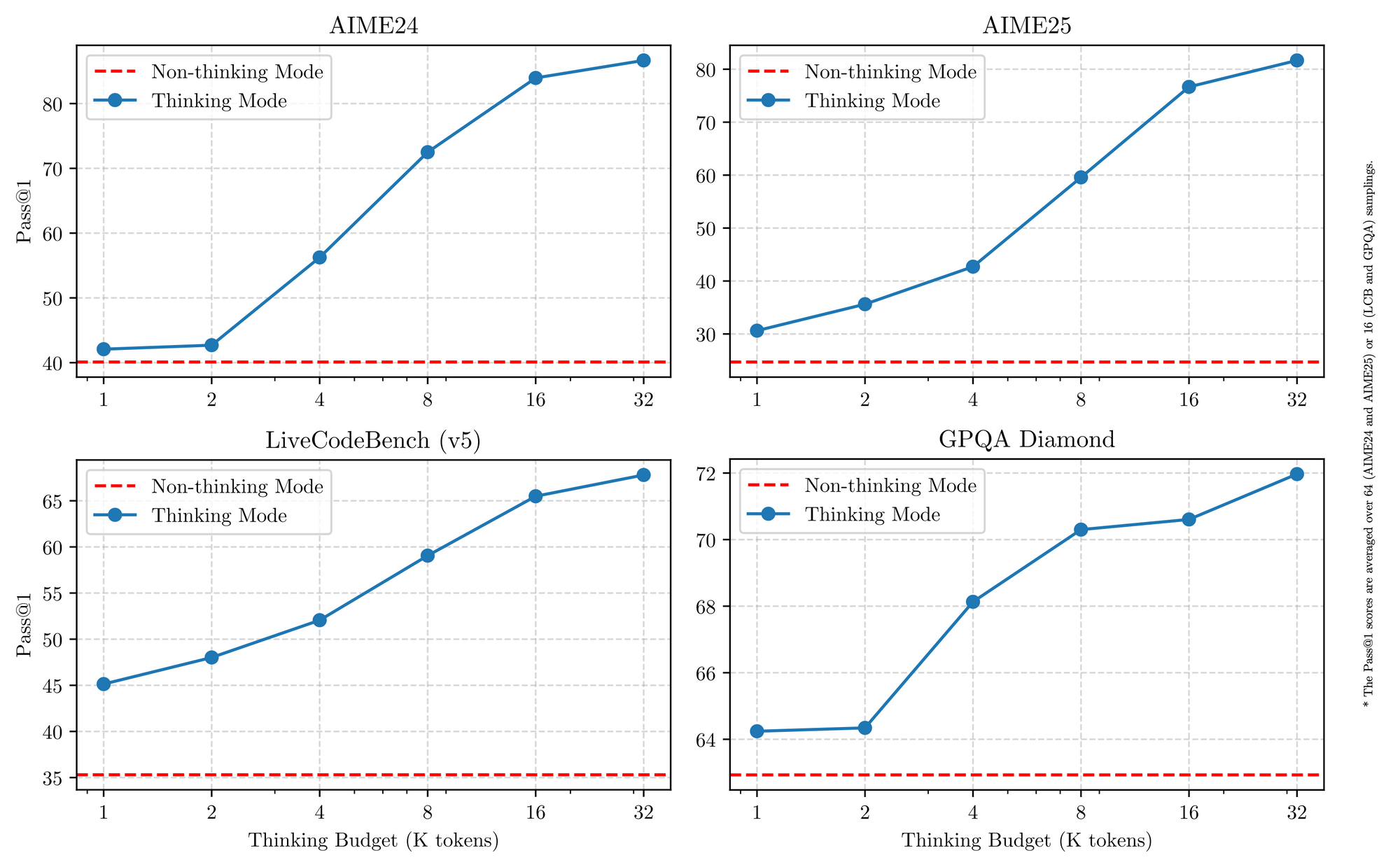
第三に、効率性は、量子化されたバリアント(例:Q4_K_M)や、消費者向けGPUで25トークン/秒を実現するvLLMやSGLangのようなフレームワークから生まれます。しかし、より大規模なモデルは16GB以上のVRAMを必要とし、クラウド展開が求められます。価格設定は競争力があり、Alibaba Cloudを介した入力トークンは100万トークンあたり$0.20〜$1.20です。
さらに、Qwen 3は組み込みのモデレーションによる安全性を重視しており、Qwen2.5に比べてハルシネーションを15%削減しています。開発者はこれを、Eコマースのリコメンダーから法律アナライザーまで、本番環境レベルのアプリに活用しています。個々のバリアントに移行するにつれて、これらの共通の強みが比較のための安定したベースラインを提供します。
2025年におけるQwen 3モデルバリアントのベスト5
LMSYS Arena、LiveCodeBench、SWE-Benchの2025年のベンチマークに基づき、Qwen 3バリアントのトップ5をランク付けします。選択基準には、推論スコア、推論速度、パラメータ効率、APIアクセス性が含まれます。それぞれが異なるシナリオで優れていますが、すべてオープンソースの最前線を推進しています。
1. Qwen3-235B-A22B – 絶対的フラッグシップMoEモンスター
Qwen3-235B-A22Bは、総パラメータ数2350億、トークンあたりアクティブパラメータ数220億という、最高のMoEバリアントとして注目を集めています。2025年7月にQwen3-235B-A22B-Instruct-2507としてリリースされ、top-kルーティングを介して8つのエキスパートをアクティブにし、高密度モデルと比較して計算量を90%削減します。ベンチマークでは、Gemini 2.5 Proと互角の性能を発揮しており、ArenaHardで95.6点、LiveBenchで77.1点、CodeForces Eloではトップ(5%リード)を記録しています。
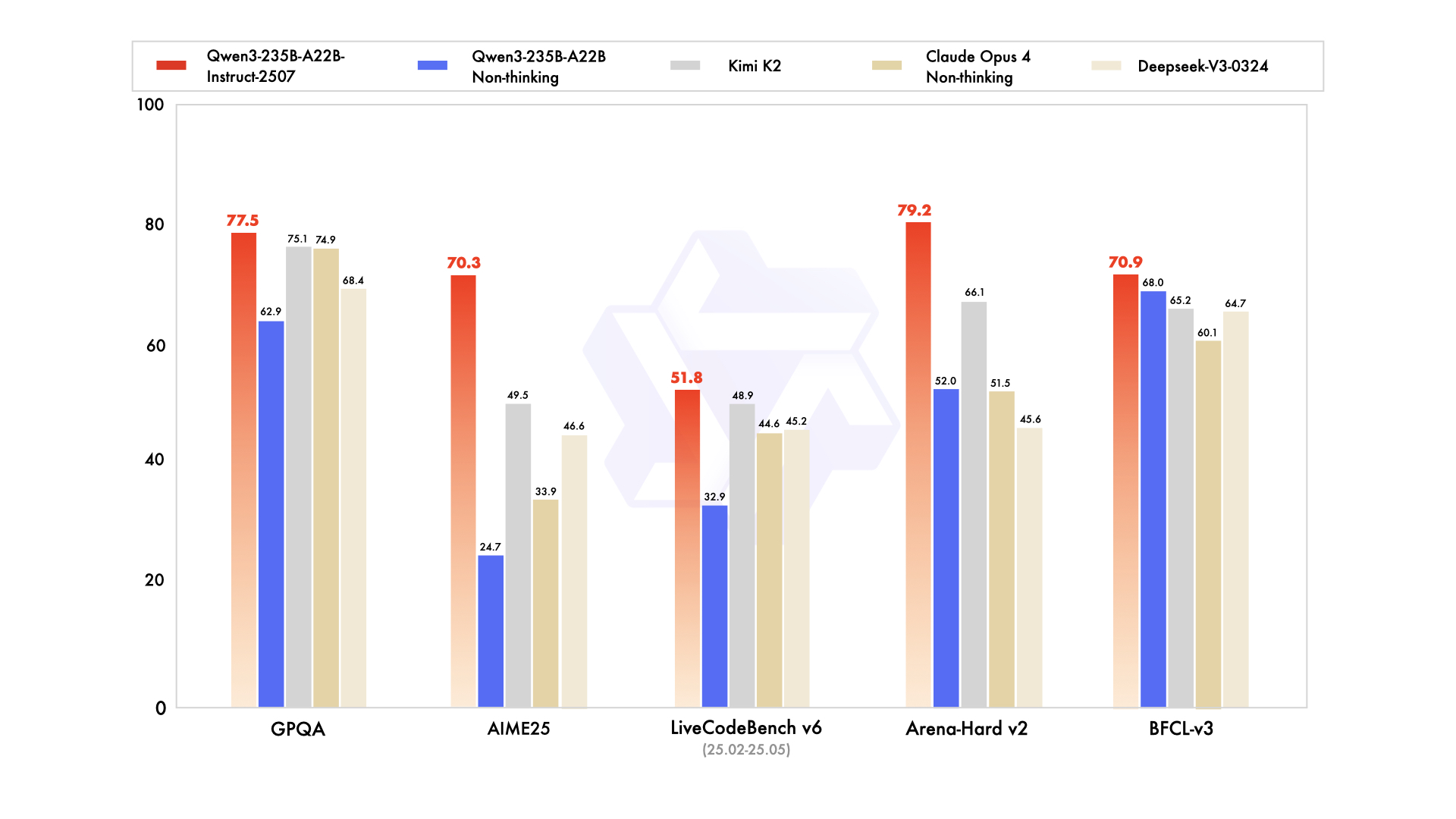
コーディングでは、LiveCodeBench v6で74.8を達成し、最小限の反復で機能的なTypeScriptを生成します。数学では、思考モードがAIME25で92.3を記録し、明確な演繹によって多段階積分を解きます。多言語タスクではMultiIFで73.0を記録し、アラビア語のクエリを完璧に処理します。
デプロイメントはクラウドAPIが有利であり、256Kのコンテキストを処理します。ただし、ローカル実行には8基のH100 GPUが必要です。エンジニアは、リポジトリ規模のデバッグのようなエージェントワークフローにこれを統合しています。全体として、このバリアントは深度において2025年の標準を設定しますが、その規模は高予算チームに適しています。
強み
- 2025年のほぼすべてのリーダーボード(ArenaHardで95.6点、AIME25思考モードで92.3点、LiveCodeBench v6で74.8点)でGemini 2.5 ProおよびClaude 3.7 Sonnetと同等またはそれ以上の性能を発揮します。
- マルチターンエージェントワークフロー、複雑なツール呼び出し、リポジトリレベルのコード理解に優れています。
- YaRNを使用して品質を落とすことなく256K〜1Mのコンテキストを処理します。
- 思考モードは、クローズドソースの最先端モデルに匹敵する、検証可能な連鎖的思考推論を提供します。
弱点
- ローカルでは非常に高価で低速です。適切なレイテンシーを得るには8基のH100または同等のものが必要です。
- API料金はファミリー内で最も高価です(ピークコンテキストで100万出力トークンあたり$1.20~$6.00)。
- 95%の本番ワークロードには過剰であり、ほとんどのチームはその能力を使い切ることはありません。
最適な用途
- 博士号レベルの数学を解き、コードベース全体をデバッグし、またはほぼゼロのハルシネーションで法務契約分析を実行する必要があるエンタープライズグレードの自律エージェント。
- 新しいベンチマークで最先端を推進する高予算の研究室。
- トークンあたりのコストよりも最大の知能が優先される内部推論バックエンド。
2. Qwen3-30B-A3B – スイートスポットMoEチャンピオン
Qwen3-30B-A3Bは、総パラメータ数305億、アクティブパラメータ数33億という、リソースが限られた設定に最適なモデルとして登場しました。そのMoE構造は、48層、128エキスパート(8つのルーティング)で、フラッグシップモデルを反映していますが、フットプリントは10分の1です。2025年7月に更新され、アクティブ効率でQwQ-32Bを10倍上回り、ArenaHardで91.0点、SWE-Bench Verifiedで69.6点を獲得しています。
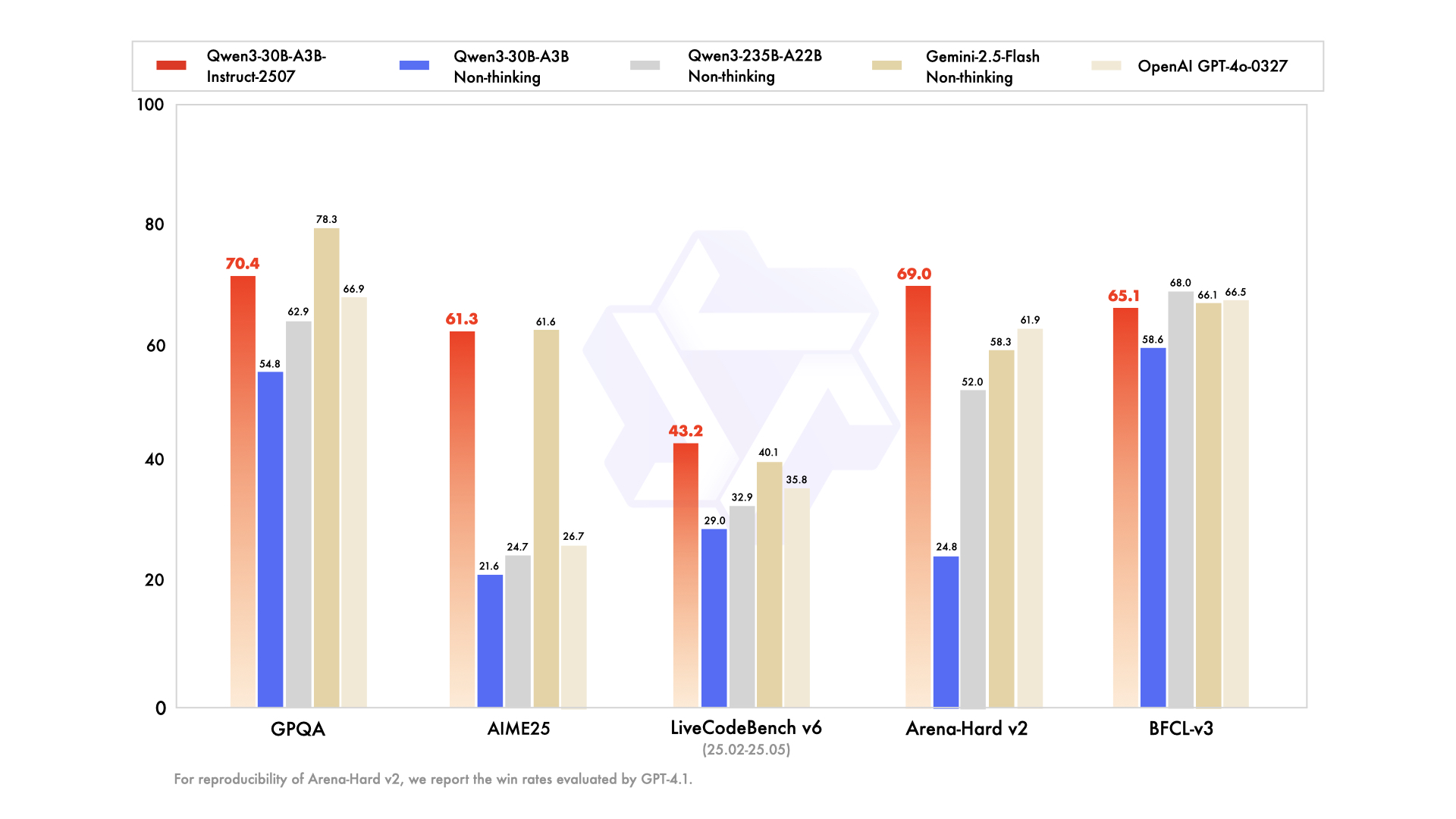
コーディング評価ではその実力が際立っており、新規GitHub PRでpass@5が32.4%と、GPT-5-Highに匹敵します。数学ベンチマークでは、思考モードでAIME25が81.6点と、より大規模な兄弟モデルに迫る成績です。YaRNを介して131Kのコンテキストを持つため、長いドキュメントも切り捨てることなく処理できます。
強み
- 235Bモデルよりもアクティブパラメータが10倍安価でありながら、フラッグシップモデルの推論品質の約90~95%を維持します(ArenaHardで91.0点、AIME25で81.6点)。
- vLLM + FlashAttentionを使用すれば、80GB A100シングルまたは40GBカード2枚で快適に動作します。
- 2025年のすべてのオープンMoEモデルの中で最高の価格性能比を誇ります。
- コーディングと数学において、すべての高密度な72B~110Bモデルを上回ります。
弱点
- FP8/INT4でも約24~30GBのVRAMが必要であり、ラップトップ向けではありません。
- 同規模の純粋な高密度モデルよりも、クリエイティブライティングの流暢さがわずかに劣ります。
- 思考モードのレイテンシーは非思考モードと比較して2~3倍に跳ね上がります。
最適な用途
- 本番環境のコーディングエージェント、自動PRレビュー、または内部DevOpsコパイロット。
- 適度な予算で最先端レベルの数学または科学推論を必要とする高スループットの研究パイプライン。
- 以前Llama-405BまたはMixtral-123Bを使用していたが、より低コストで優れた推論を求めるチーム。
3. Qwen3-32B – 高密度万能の王者
高密度なQwen3-32Bは、320億の完全にアクティブなパラメータを提供し、スパース性よりも純粋なスループットを重視します。36兆トークンでトレーニングされ、基本的な性能ではQwen2.5-72Bに匹敵しますが、後トレーニングでのアラインメントに優れています。ベンチマークではArenaHardで89.5点、MultiIFで73.0点を示し、強力なクリエイティブライティング(例:ロールプレイング物語で85%の人間の好感度を獲得)を備えています。
コーディングでは、BFCLで68.2を記録し、プロンプトからドラッグ&ドロップUIを生成します。数学ではAIME25で70.3を記録しますが、連鎖的思考ではMoEモデルに劣ります。128Kのコンテキストは知識ベースに適しており、非思考モードでは対話速度を20トークン/秒に向上させます。
強み
- 卓越した指示追従とクリエイティブな出力で、ライティングやロールプレイに関するブラインド人間評価では、より大規模なMoEモデルよりも好まれることがよくあります。
- 消費者向けハードウェア(16~24GB VRAM)でLoRA/QLoRAを使用して簡単にファインチューニングできます。
- 多くのタスクで依然としてGPT-4oを上回るモデルの中で最速の推論速度(ArenaHardで89.5点)。
- 119以上の言語で非常に強力な多言語性能。
弱点
- 思考モードが有効な場合、最も難しい数学およびコーディングベンチマークでMoE兄弟モデルに約8~12ポイント差をつけられます。
- パラメータ効率化の工夫がなく、すべてのトークンが320億の完全な計算コストを必要とします。
最適な用途
- コンテンツ生成プラットフォーム、小説執筆アシスタント、マーケティングコピー作成ツール。
- 大規模なファインチューニングを必要とするプロジェクト(ドメイン固有のチャットボット、スタイル転送)。
- フラッグシップに近い品質を求めるが、24GB VRAM以下に抑える必要があるチーム。
4. Qwen3-14B – エッジ&モバイルの主力モデル
Qwen3-14Bは、148億のパラメータでポータビリティを優先し、ミッドレンジハードウェアで128Kのコンテキストをサポートします。効率性ではQwen2.5-32Bに匹敵し、ArenaHardで85.5点を獲得し、数学/コーディングではQwen3-30B-A3Bと互角の性能(5%以内の差)を発揮します。Q4_0に量子化すると、RedMagic 8S Proのようなモバイルデバイスで24.5トークン/秒で動作します。
エージェントタスクではTau2-Benchで65.1を記録し、低遅延アプリでのツール使用を可能にします。多言語サポートも際立ち、方言推論で70%の精度を誇ります。エッジデバイス向けには、32Kのコンテキストをオフラインで処理でき、IoT分析に最適です。
エンジニアは、プライバシーが規模よりも優先される連合学習において、そのフットプリントを高く評価しています。したがって、モバイルAIアシスタントや組み込みシステムに適しています。
強み
- Q4_K_Mに量子化すると、最新のスマートフォン(Snapdragon 8 Gen 4、Dimensity 9400)で24~30トークン/秒で動作します。
- ほとんどの推論ベンチマークで、依然としてQwen2.5-32BおよびLlama-3.1-70Bを上回ります。
- 32K~128Kのコンテキストを持つオンデバイスRAGに優れています。
- トップティアのパフォーマンス帯で最も低いAPIコスト。
弱点
- 5回以上のツール呼び出しが必要な多段階エージェントタスクでは苦戦し始めます。
- クリエイティブライティングの品質は32B以上のモデルより著しく劣ります。
- ベンチマークが上昇し続けるため、将来性において劣る可能性があります。
最適な用途
- オンデバイスアシスタント(Android/iOSアプリ、ウェアラブル)。
- データがデバイスから離れることができない、プライバシーに配慮したデプロイメント(ヘルスケア、金融)。
- リアルタイム組み込みシステム(ロボット、自動車、IoTゲートウェイ)。
5. Qwen3-8B – 究極のプロトタイピング&軽量主力モデル
トップ5の最後を飾る、Qwen3-8Bは、迅速なイテレーションのために80億のパラメータを提供し、15のベンチマークでQwen2.5-14Bを上回ります。AIME25(非思考モード)で81.5点、LiveCodeBenchで60.2点を達成し、基本的なコードレビューには十分です。32Kのネイティブコンテキストを持ち、Ollamaを介してラップトップにデプロイでき、25トークン/秒を達成します。
このバリアントは、多言語チャットやシンプルなエージェントをテストする初心者向けです。その思考モードは論理パズルを強化し、演繹タスクで75%を記録します。結果として、より大規模な兄弟モデルにスケールアップする前の概念実証を加速します。
強み
- 8~12GB VRAMのラップトップ(MacBook M3 Pro、RTX 4070 mobile)でも25トークン/秒以上で動作します。
- 驚くほど優れた指示追従能力で、2025年のほとんどのリーダーボードでGemma-2-27BおよびPhi-4-14Bを上回ります。
- ローカルのOllamaやLM Studioでの実験に最適です。
- ファミリー内で最も安価なAPI料金。
弱点
- 大学院レベルの数学や高度なコーディング問題では、明らかに推論能力の限界があります。
- 知識集約型タスクではハルシネーションを起こしやすい傾向があります。
- コンテキストが制限されています(ネイティブで32K、YaRNを使用すると128Kですが、速度は低下します)。
最適な用途
- 迅速なプロトタイピングとMVP構築。
- 教育ツール、パーソナルアシスタント、または趣味のプロジェクト。
- ハイブリッドシステムにおけるフロントエンドルーティング層(8Bでトリアージし、必要に応じて30B/235Bにエスカレート)。
Qwen 3モデルのAPI料金とデプロイメントに関する考慮事項
APIを介したQwen 3へのアクセスは高度なAIを民主化し、Alibaba Cloudが競争力のある料金でリードしています。料金はトークンに基づいて階層化されており、Qwen3-235B-A22Bの場合、入力は100万トークンあたり$0.20~$1.20(0~252Kの範囲)、出力は100万トークンあたり$1.00~$6.00です。Qwen3-30B-A3Bはこの80%の料金であり、Qwen3-32Bのような高密度モデルは入力$0.15/出力$0.75に下がります。
Together AIのようなサードパーティプロバイダーは、Qwen3-32Bを総トークン100万あたり$0.80で提供し、ボリュームディスカウントもあります。キャッシュヒットは料金を削減し、暗黙的で20%、明示的で10%です。GPT-5($3~15/100万)と比較して、Qwen 3は70%安価であり、費用対効果の高いスケーリングを可能にします。
デプロイのヒント:バッチ処理にはvLLM、OpenAI互換性にはSGLangを使用します。Apidogは、Qwenエンドポイントのモック、ペイロードのテスト、ドキュメント生成を通じてこれを強化し、CI/CDパイプラインにとって不可欠です。Ollamaを介したローカル実行はプロトタイピングに適していますが、APIは本番環境で優れています。
レート制限やモデレーションなどのセキュリティ機能は、追加料金なしで価値を提供します。したがって、予算を意識するチームは、トークン量に基づいて選択します。開発には小さなバリアントを、推論にはフラッグシップモデルを使用します。
意思決定表 – 2025年に最適なQwen 3モデルを選択する
| 順位 | モデル | パラメータ数(合計/アクティブ) | 強み(概要) | 主な弱点 | 最適な用途 | API概算費用(入力/出力 100万トークンあたり) | 最小VRAM(量子化時) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 2350億 / 220億 MoE | 最高の推論、エージェント機能、数学、コード | 非常に高価で重い | 最先端の研究、企業エージェント、ゼロトレランスの精度 | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (クラウド) |
| 2 | Qwen3-30B-A3B | 305億 / 33億 MoE | 最高の価格性能比、強力な推論 | 依然としてサーバーGPUが必要 | 本番環境のコーディングエージェント、数学/科学バックエンド、大量推論 | $0.16–$0.96 / $0.80–$4.80 | 24~30GB |
| 3 | Qwen3-32B | 320億 高密度 | クリエイティブライティング、簡単なファインチューニング、速度 | 最難関タスクでMoEに劣る | コンテンツプラットフォーム、ドメイン特化ファインチューニング、多言語チャットボット | $0.15 / $0.75 | 16~20GB |
| 4 | Qwen3-14B | 148億 高密度 | エッジ/モバイル対応、優れたオンデバイスRAG | 多段階エージェント能力に限界 | オンデバイスAI、プライバシー重視アプリ、組み込みシステム | $0.12 / $0.60 | 8~12GB |
| 5 | Qwen3-8B | 80億 高密度 | ラップトップ/スマートフォン速度、最安価 | 複雑なタスクで明らかに限界あり | プロトタイピング、パーソナルアシスタント、ハイブリッドシステムのルーティング層 | $0.10 / $0.50 | 4~8GB |
2025年の最終推奨
2025年のほとんどのチームは、デフォルトでQwen3-30B-A3Bを使用すべきです。これは、フラッグシップモデルの90%以上の能力を、はるかに低いコストとハードウェア要件で提供します。推論品質の最後の5~10%が本当に必要で、かつ予算がある場合にのみ、235B-A22Bに移行してください。クリエイティブな作業やファインチューニングの負荷が高いワークロードには32Bの高密度モデルに移行し、レイテンシー、プライバシー、またはデバイスの制約が主な場合には14B/8Bを使用してください。
どのバリアントを選択しても、ApidogはAPIデバッグの時間を大幅に節約します。今すぐ無料でダウンロードして、自信を持ってQwen 3での開発を始めましょう。