
Pythonを使用してWeb APIとやり取りする際、特に複数のリクエストを処理する場合、遅延に直面することがよくあります。ファイルのダウンロード、データのスクレイピング、APIへのリクエストなど、各タスクが完了するのを待つことで、全体の進行が大幅に遅くなることがあります。ここで非同期プログラミングが役立ちます。Pythonエコシステムにおいて、これに最適なツールの一つがaiohttpライブラリです。
非同期プログラミングに不慣れな方もご安心ください!簡単な言葉で説明し、aiohttpがどのようにウェブリクエストを合理化し、より迅速かつ効率的にするかを解説します。
さらに深く掘り下げる前に、すべての開発者が直面する問題に触れましょう:APIテストです。大多数のチームと同様に、あなたもおそらくPostmanを使用していることでしょう。
その気持ち、分かります—Postmanは信頼できるツールです。しかし、正直に言うと、毎年その魅力が減ってきているのを私たちは皆感じているのではないでしょうか?にもかかわらず、あなたはチームとして働いており、開発プロセスをスムーズに進めるためのコラボレーションツールが必要です。そこで、どうしますか?月額49ドルという大金を投資してPostman Enterpriseを購入します。
しかし、ここで重要なポイントがあります:そんな必要はありません。
はい、その通りです。APIテストやチームコラボレーションを管理するために、過去の価値をもはや提供しないツールに多くのお金をかけることなく、より良く、効率的な方法が存在します。より良い代替案を探ってみましょう!

Apidog:Postmanの有料版からすべての機能を手に入れるが、より安価
その通り、ApidogはPostmanの有料版に含まれるすべての機能を、わずかなコストで提供します。移行は非常に簡単で、ボタンを数回クリックするだけでApidogがすべてを自動で行います。
Apidogは一度試してみる価値があります。しかし、もしあなたが開発チームのテックリードで、Postmanをより良い、そして安価なものに置き換えたいと考えているなら、Apidogをチェックしてみてください!
aiohttpとは何ですか?
aiohttpは、非同期HTTPクライアントおよびサーバーを記述できる人気のPythonライブラリです。これは、Pythonのrequestsライブラリのようなものでありながら、非同期プログラミングの力で強化されています。
Pythonのasyncioフレームワークの上に構築されているため、各リクエストの完了を待たずに多数のリクエストを同時に処理できます。
コーヒーショップにいると想像してみてください。各注文が一回ずつ完了するのを待つのではなく、複数のバリスタが同時にあなたの注文に取り掛かります。
aiohttpを使用すると、まるでチームのバリスタと一緒にコーヒーを淹れているかのようです(この場合、データを取得しているわけですが)。結果は?待たずに高速な結果が得られます。
なぜaiohttpが重要なのか
aiohttpがあなたにとって重要な理由について話しましょう。あなたがPythonの初心者であろうと、データサイエンティストであろうと、ウェブスクレイパーであろうと、経験豊富な開発者であろうと関係ありません。
- パフォーマンス: aiohttpを使用する主な理由はパフォーマンスです。複数のAPIコールやウェブサイトへのリクエストを行う必要がある場合、aiohttpはそれらを同時に処理できます。
順番に処理するのではなく、同時に数十件または数百件のリクエストを実行できます。 - スケーラビリティ:ウェブスクレイピングや複数のAPI呼び出しは、同期プログラミングを使用すると遅く、ブロッキング的なプロセスになる可能性があります。しかし、aiohttpを使用すれば、より少ない時間で多くのタスクを管理できるため、アプリケーションは需要の増大や大規模データセットに対応できるようになります。
- 待機時間の短縮:従来の同期プログラムは、次のタスクを開始する前に1つのタスクが完了するのを待たなければなりません。
非同期コードを使用すると、タスクが待機する必要はありません。複数のURLからデータを一度にダウンロードできるため、全体の実行時間を大幅に短縮できます。 - 効率的なリソース使用:非同期プログラミング、特にaiohttpは、システムリソースのより効率的な使用を可能にします。
応答を待つ間、全体のスレッドやプロセスをブロックする代わりに、aiohttpはI/O操作が完了するのを待ちながら他のタスクを実行できるようにします。
aiohttpはどのように機能するのか?
aiohttpが実際にどのように機能するのかを見ていきましょう。
まず、非同期プログラミングが実際に何を意味するのかを明確にしましょう。同期プログラムでは、各タスクは次のタスクを開始する前に完了しなければなりません。
ウェブサーバーの応答を待っている場合、プログラム全体はその応答が到着するまで停止します。非同期プログラミングでは、応答を待ちながら他のタスクを実行し続けることができます。
aiohttpはこの非同期モデルを活用し、一度に複数のHTTPリクエストを実行し、それに応じて応答を処理できるようにします。以下はこの概念をシンプルに説明する例です:
aiohttpを使用したウェブリクエストの方法:基本
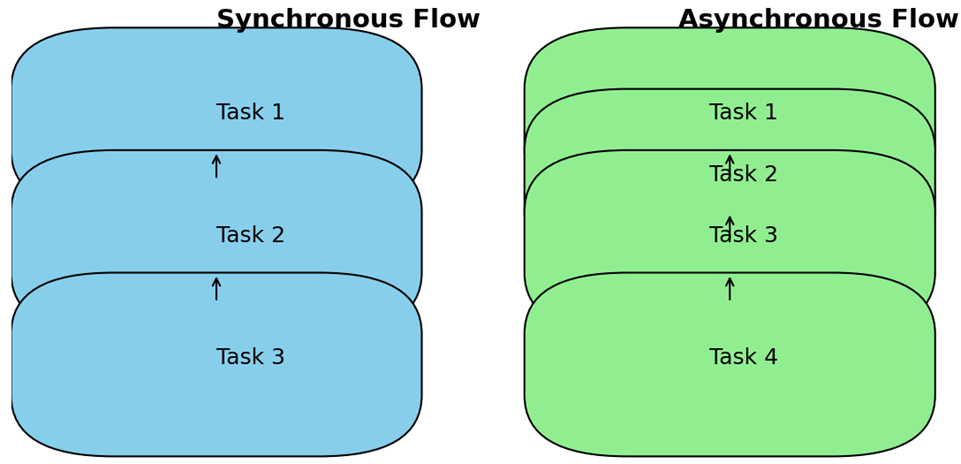
この図(図2)は、同期フロー(次のタスクが開始される前に1つのタスクが完了する)と非同期フロー(複数のタスクが同時に実行される)の違いを比較しています。
青いボックスは同期タスクを表し、緑のボックスは非同期タスクを表しています。
矢印は、同期および非同期プロセスの実行フローを示します。
イベントループの可視化(Pythonの非同期モデル内のループメカニズム)
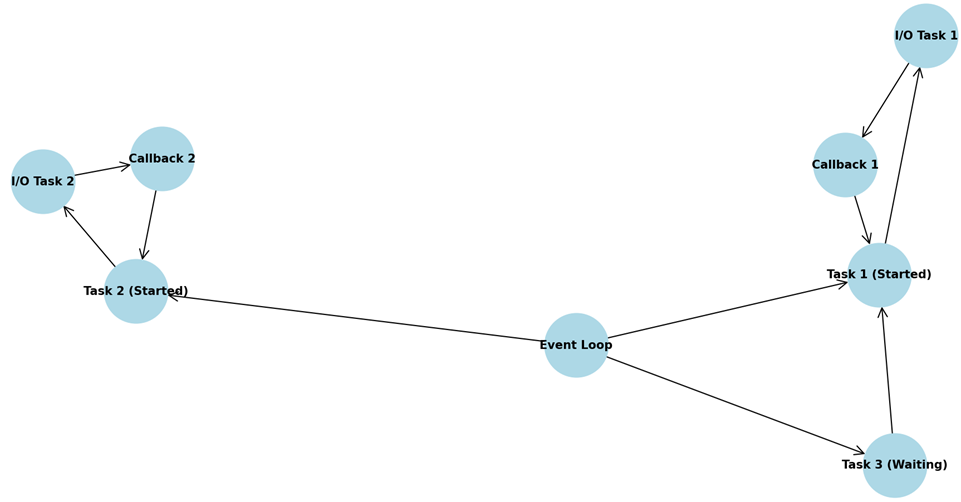
この図(図3)は、Pythonの非同期プログラミングモデルにおけるイベントループメカニズムを示しています。
ノードは、タスクの開始、I/O操作の待機、コールバックの実行など、さまざまなステップを表します。
矢印は、タスクがどのように開始され、I/O操作を待ち、イベントループがコールバックを処理し、タスクを再起動するかを示しています。
aiohttpにおける同時URL取得
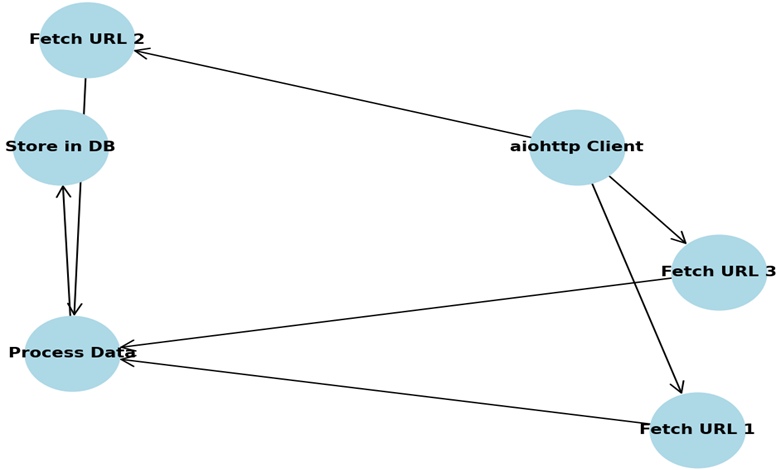
ユースケース図(図4)は、aiohttpが複数のURLリクエストを同時に処理できる様子を視覚化しています。「Fetch URL」プロセスはすべて同時に処理され、中央処理ノードに渡されます。
この図は、aiohttpがウェブスクレイピングやAPIリクエストシナリオで、複数のURLを同時に取得できることを示しています。
ワークフローダイアグラム
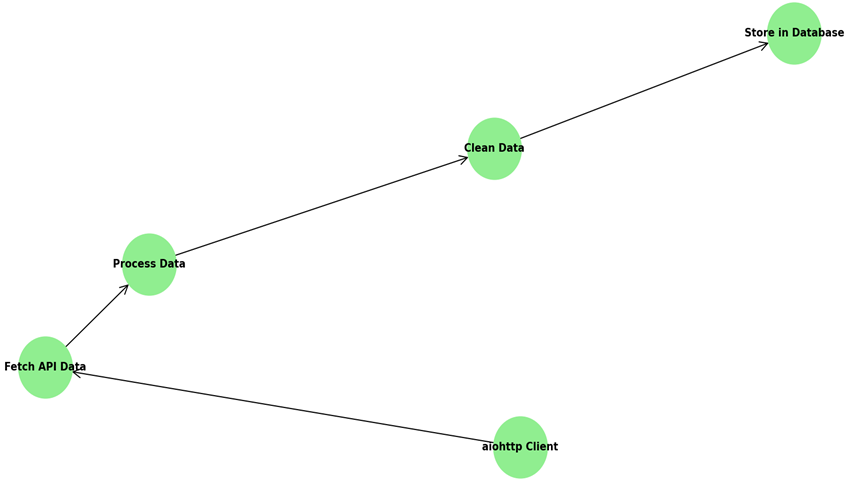
ワークフローダイアグラムは、データを取得、処理、クリーンアップ、保存するステップを示す基本的なデータパイプラインを視覚化しています。
例:aiohttpを使用した非同期リクエスト作成
import aiohttp
import asyncio
async def fetch_url(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = [
"https://jsonplaceholder.typicode.com/posts/1",
"https://jsonplaceholder.typicode.com/posts/2",
"https://jsonplaceholder.typicode.com/posts/3",
]
async with aiohttp.ClientSession() as session:
tasks = [fetch_url(session, url) for url in urls]
responses = await asyncio.gather(*tasks)
for i, response in enumerate(responses):
print(f"レスポンス {i+1}: {response[:60]}...") # 各レスポンスの最初の60文字を出力
イベントループを実行する
asyncio.run(main())
同期的にコンテンツをダウンロードする
まず、requestsライブラリを使用してこれを同期的に試してみましょう。次のコマンドでインストールできます:
pip.python3.7 -m pip install requests
requestsを使用してオンラインリソースをダウンロードするのは簡単です。
import requestsresponse = requests.get("https://www.python.org/dev/peps/pep-8010/")print(response.content)
PEP 8010のHTMLコンテンツが出力されます。これをファイルにローカル保存するには:
filename = "sync_pep_8010.html"with open(filename, "wb") as pep_file:pep_file.write(content.encode('utf-8'))ファイルsync_pep_8010.htmlが作成されます。
aiohttpの実世界でのユースケース
1. ウェブスクレイピング
複数ページをウェブサイトからスクレイピングしている場合、各ページの読み込みを待つことは非常に遅いプロセスになることがあります。aiohttpを使用すれば、複数のページを同時にスクレイピングでき、プロセスを劇的に加速できます。一度に数百ページを取得することを想像してみてください。
2. APIリクエスト
APIを使用している場合、特にレート制限があるか、遅く応答するAPIに対しては、aiohttpを使用すると同時に複数のリクエストを送信できます。たとえば、複数の都市のデータを取得するために天気APIをクエリしている場合、aiohttpが結果を迅速に集めるのに役立ちます。
3. データ収集
株式市場データ、ソーシャルメディアフィード、ニュースウェブサイトなどを扱う場合、aiohttpは、同時に膨大な量のHTTPリクエストを処理するためのゲームチェンジャーとなります。データをより早く、効率的に収集できるようになります。
ここでは、Pythonのaiohttpライブラリを使用した3つの実用的な例を、手順とサンプルコードと共に示します:
1. 非同期HTTPリクエストの作成
この例では、aiohttpを使用して複数の非同期HTTPリクエストを作成する方法を示します。
手順:
- 必要なモジュールをインポートする
- URLを取得する非同期関数を定義する
- 取得するURLのリストを作成する
- 非同期イベントループを設定する
- 各URLの非同期関数を同時に実行する
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
urls = [
'https://api.github.com',
'https://api.github.com/events',
'https://api.github.com/repos/python/cpython'
]
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
responses = await asyncio.gather(*tasks)
for url, response in zip(urls, responses):
print(f"URL: {url}\nレスポンスの長さ: {len(response)}\n")
asyncio.run(main())
2. シンプルなAPIサーバーの作成
この例では、aiohttpを使用して基本的なAPIサーバーを作成する方法を示します。
手順:
- 必要なモジュールをインポートする
- ルートハンドラーを定義する
- アプリケーションを作成し、ルートを追加する
- アプリケーションを実行する
from aiohttp import web
async def handle_root(request):
return web.json_response({"message": "APIへようこそ"})
async def handle_users(request):
users = [
{"id": 1, "name": "アリス"},
{"id": 2, "name": "ボブ"},
{"id": 3, "name": "チャーリー"}
]
return web.json_response(users)
app = web.Application()
app.add_routes([
web.get('/', handle_root),
web.get('/users', handle_users)
])
if __name__ == '__main__':
web.run_app(app)
3. ウェブソケットチャットサーバー
この例では、aiohttpを使用してシンプルなウェブソケットベースのチャットサーバーを作成する方法を示します。
手順:
- 必要なモジュールをインポートする
- アクティブなウェブソケットを格納するためのセットを作成する
- ウェブソケットハンドラーを定義する
- アプリケーションを作成し、ルートを追加する
- アプリケーションを実行する
import aiohttp
from aiohttp import web
import asyncio
active_websockets = set()
async def websocket_handler(request):
ws = web.WebSocketResponse()
await ws.prepare(request)
active_websockets.add(ws)
try:
async for msg in ws:
if msg.type == aiohttp.WSMsgType.TEXT:
for client in active_websockets:
if client != ws:
await client.send_str(f"ユーザー{id(ws)}: {msg.data}")
elif msg.type == aiohttp.WSMsgType.ERROR:
print(f"ウェブソケット接続が例外{ws.exception()}で閉じられました")
finally:
active_websockets.remove(ws)
return ws
app = web.Application()
app.add_routes([web.get('/ws', websocket_handler)])
if __name__ == '__main__':
web.run_app(app)
このウェブソケットサーバーをテストするには、ウェブソケットクライアントを使用するか、サーバーに接続するためのシンプルなHTMLページをJavaScriptで作成できます。
これらの例は、非同期リクエストの作成からウェブサーバーの立ち上げ、ウェブソケットの処理に至るまで、aiohttpの異なる側面を示しています。これにより、この強力なライブラリを使用してより複雑なアプリケーションを構築するためのしっかりとした基盤が提供されます。
まとめ
データ駆動の世界では、速度が重要であり、同時に多くのタスクを処理できる能力は優位性をもたらすことができます。aiohttpは、ウェブスクレイピング、APIリクエスト、または多くのHTTPリクエストを行う必要がある任意のタスクにおいて、Pythonのツールキットに欠かせないツールです。
非同期にすることで、時間を節約するだけでなく、コードをより効率的でスケーラブルにできます。
したがって、Pythonのウェブリクエストを次のレベルに引き上げたい場合は、aiohttpを試してみてください。
なぜそれがI/O重視のアプリケーションを扱う開発者にとって非常に人気のある選択肢であるかをすぐに実感することでしょう。
このページが役に立ったと思いますか?これが皆さんにとって非常に有益な資料であったことを願っています!
皆さんのご成功を祈っています!この記事を読んで少しでも理解を深めていただければ幸いです!


