
ElevenLabs mengubah teks menjadi ucapan alami dan mendukung berbagai jenis suara, bahasa, dan gaya. API ini memudahkan untuk menyematkan suara ke dalam aplikasi, mengotomatiskan alur narasi, atau membangun pengalaman real-time seperti agen suara. Jika Anda dapat mengirim permintaan HTTP, Anda dapat menghasilkan audio dalam hitungan detik.
button
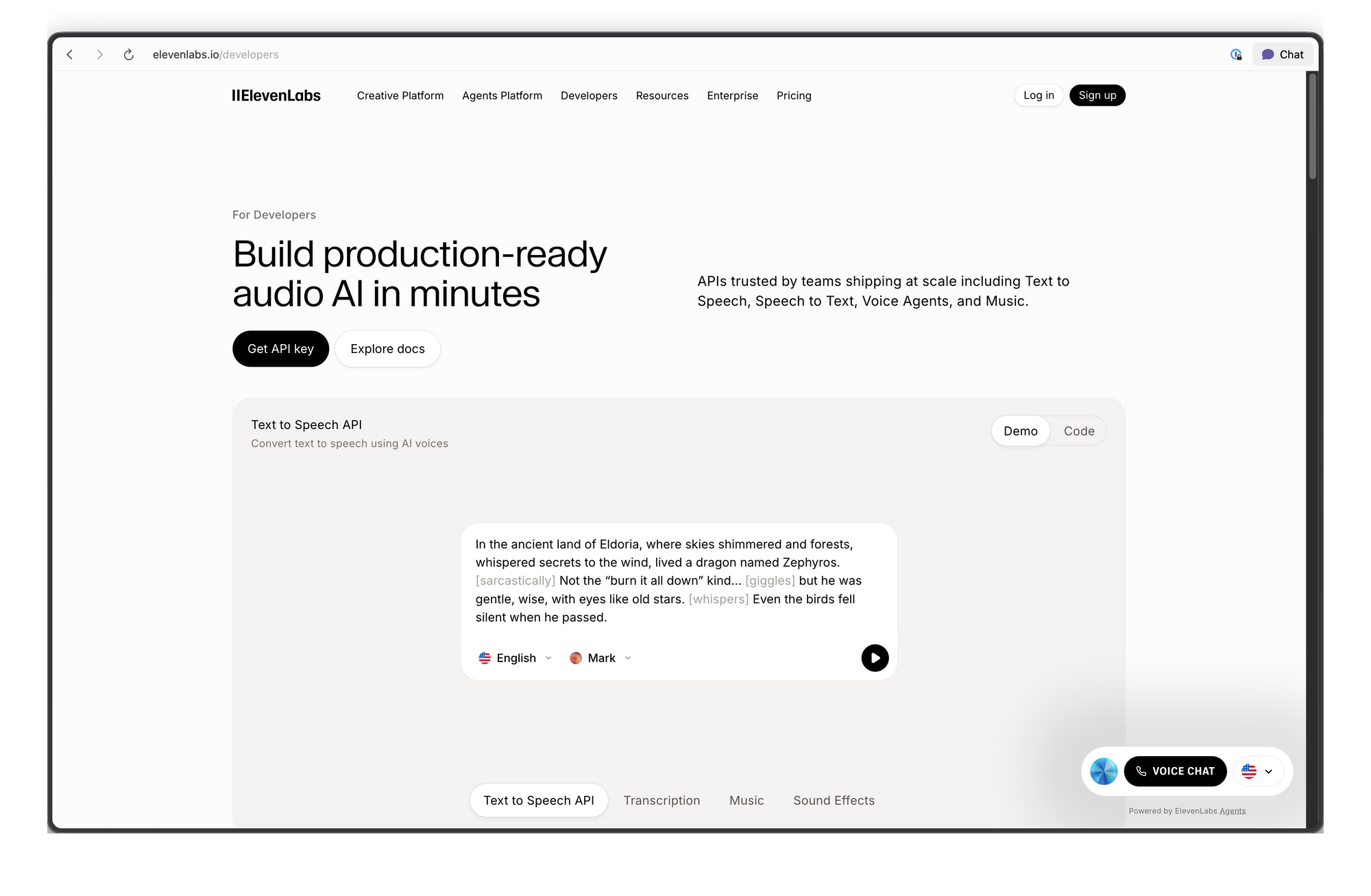
Apa Itu API ElevenLabs?
API ElevenLabs menyediakan akses terprogram ke model AI yang menghasilkan, mengubah, dan menganalisis audio. Platform ini dimulai sebagai layanan text-to-speech tetapi telah berkembang menjadi suite AI audio lengkap.
Kemampuan inti:
- Text-to-Speech (TTS): Mengubah teks tertulis menjadi audio ucapan dengan kontrol atas karakteristik suara, emosi, dan kecepatan
- Speech-to-Speech (STS): Mengubah satu suara menjadi suara lain sambil mempertahankan intonasi dan waktu asli
- Voice Cloning: Membuat replika digital dari suara apa pun hanya dengan audio bersih minimal 60 detik
- AI Dubbing: Menerjemahkan dan mengisi suara konten audio/video ke berbagai bahasa sambil mempertahankan karakteristik suara pembicara
- Sound Effects: Menghasilkan efek suara dari deskripsi teks
- Speech-to-Text: Mentranskripsi audio menjadi teks dengan akurasi tinggi
API ini bekerja melalui protokol HTTP dan WebSocket standar. Anda dapat memanggilnya dari bahasa apa pun, tetapi SDK resmi tersedia untuk Python dan JavaScript/TypeScript dengan keamanan tipe dan dukungan streaming yang terintegrasi.
Mendapatkan Kunci API ElevenLabs
Sebelum melakukan panggilan API apa pun, Anda memerlukan kunci API. Berikut cara mendapatkannya:
Langkah 1: Buat akun gratis. Bahkan paket gratis sudah termasuk akses API dengan 10.000 karakter per bulan.
Langkah 2: Masuk dan navigasi ke bagian **Profil + Kunci API**. Anda dapat menemukannya dengan mengklik ikon profil Anda di sudut kiri bawah, atau langsung menuju ke pengaturan pengembang.
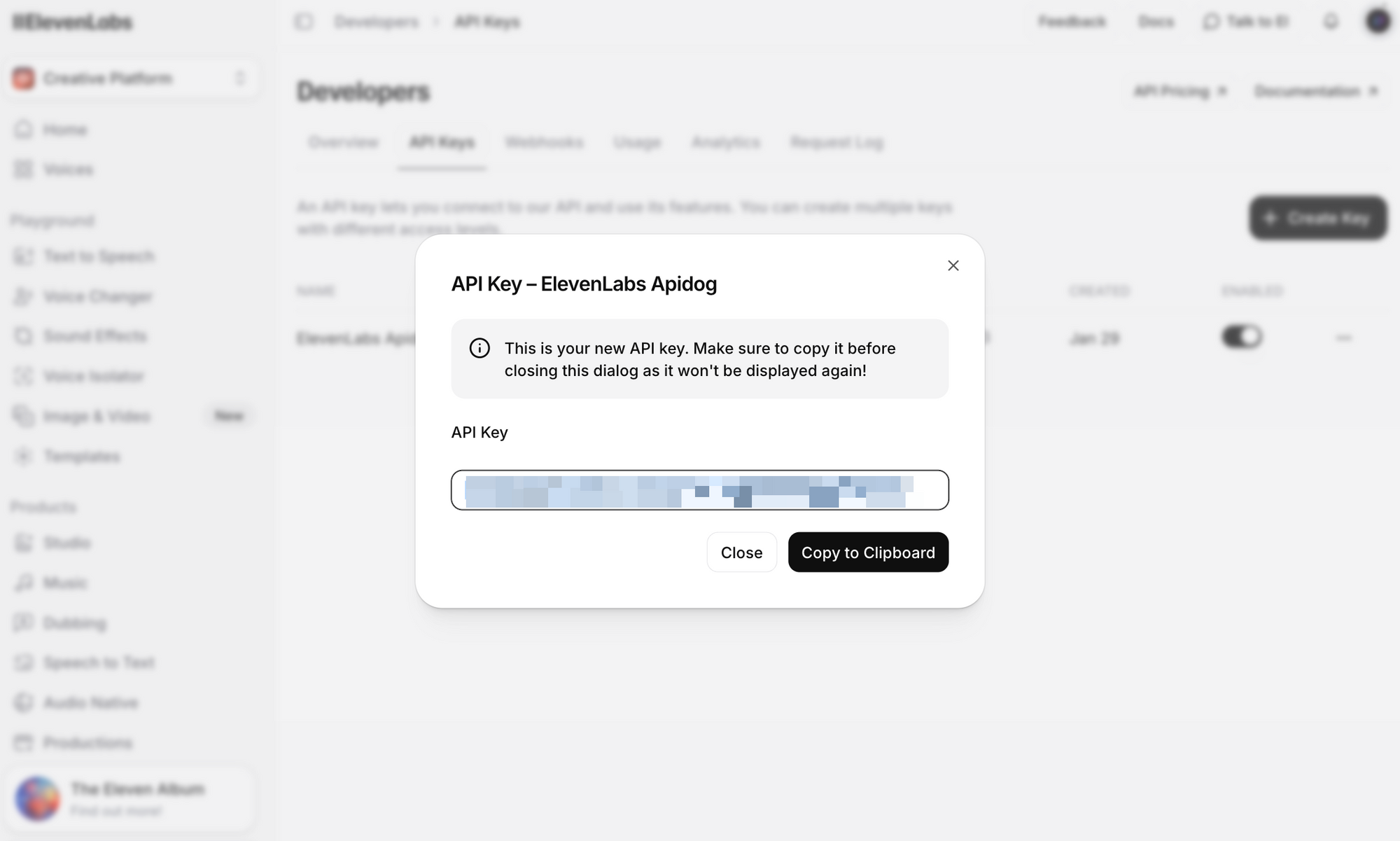
Langkah 3: Klik **Buat Kunci API**. Salin kunci tersebut dan simpan dengan aman—Anda tidak akan dapat melihat kunci lengkapnya lagi.
Catatan keamanan penting:
- Jangan pernah menyimpan kunci API Anda di kontrol versi
- Gunakan variabel lingkungan atau pengelola rahasia dalam produksi
- Kunci API dapat dicakup ke ruang kerja tertentu untuk lingkungan tim
- Rotasi kunci secara teratur dan cabut kunci yang disusupi segera
Atur sebagai variabel lingkungan untuk contoh dalam panduan ini:
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
Gambaran Umum Endpoint API ElevenLabs
API diorganisasikan berdasarkan beberapa grup sumber daya. Berikut adalah endpoint yang paling umum digunakan:
| Endpoint | Metode | Deskripsi |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Mengubah teks menjadi audio ucapan |
/v1/text-to-speech/{voice_id}/stream | POST | Mengalirkan audio saat dibuat |
/v1/speech-to-speech/{voice_id} | POST | Mengubah ucapan dari satu suara ke suara lain |
/v1/voices | GET | Mencantumkan semua suara yang tersedia |
/v1/voices/{voice_id} | GET | Mendapatkan detail untuk suara tertentu |
/v1/models | GET | Mencantumkan semua model yang tersedia |
/v1/user | GET | Mendapatkan info dan penggunaan akun pengguna |
/v1/voice-generation/generate-voice | POST | Menghasilkan suara acak baru |
URL Dasar: https://api.elevenlabs.io
Otentikasi: Semua permintaan memerlukan header xi-api-key:
xi-api-key: your_api_key_here
Text-to-Speech dengan cURL
Cara tercepat untuk menguji API adalah dengan perintah cURL. Contoh ini menggunakan suara `Rachel` (ID: `21m00Tcm4TlvDq8ikWAM`), salah satu suara default yang tersedia di semua paket:
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Welcome to our application. This audio was generated using the ElevenLabs API.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
Jika berhasil, Anda akan mendapatkan file speech.mp3 dengan audio yang dihasilkan. Putar dengan pemutar media apa pun.
Membedah permintaan:
- voice_id (dalam URL): ID suara yang akan digunakan. Setiap suara di ElevenLabs memiliki ID unik.
- text: Konten yang akan diubah menjadi ucapan. Model Flash v2.5 mendukung hingga 40.000 karakter per permintaan.
- model_id: Model AI yang akan digunakan.
eleven_flash_v2_5menawarkan keseimbangan terbaik antara kecepatan dan kualitas. - voice_settings: Parameter penyetelan halus opsional (akan dibahas secara rinci di bawah).
Respons mengembalikan data audio mentah. Format default adalah MP3, tetapi Anda dapat meminta format lain dengan menambahkan parameter kueri output_format:
# Dapatkan audio PCM daripada MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Menggunakan Python SDK
SDK Python resmi menyederhanakan integrasi dengan petunjuk tipe, pemutaran audio bawaan, dan dukungan streaming.
Instalasi
pip install elevenlabs
Untuk memutar audio langsung melalui speaker Anda, Anda mungkin juga memerlukan mpv atau ffmpeg:
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Text-to-Speech Dasar
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="The ElevenLabs API makes it easy to add realistic voice output to any application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # Suara George
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Menyimpan Audio ke File
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio = client.text_to_speech.convert(
text="This audio will be saved to a file.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio disimpan ke output.mp3")
Mencantumkan Suara yang Tersedia
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
response = client.voices.search()
for voice in response.voices:
print(f"Name: {voice.name}, ID: {voice.voice_id}, Category: {voice.category}")
Ini mencetak semua suara yang tersedia di akun Anda, termasuk suara premade, suara kloning, dan suara komunitas yang telah Anda tambahkan.
Dukungan Asinkron
Untuk aplikasi yang menggunakan asyncio, SDK menyediakan AsyncElevenLabs:
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="your_api_key")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="This was generated asynchronously.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Audio asinkron disimpan.")
asyncio.run(generate_speech())
Menggunakan JavaScript SDK
SDK Node.js resmi (@elevenlabs/elevenlabs-js) menyediakan dukungan TypeScript penuh dan berfungsi di lingkungan Node.js.
Instalasi
npm install @elevenlabs/elevenlabs-js
Text-to-Speech Dasar
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // ID suara Rachel
{
text: "Hello from the ElevenLabs JavaScript SDK!",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
Menyimpan ke File (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "This audio will be written to a file using Node.js streams.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio disimpan ke output.mp3");
Penanganan Kesalahan
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Testing error handling.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`Kesalahan API: ${error.message}, Status: ${error.statusCode}`);
} else {
console.error("Kesalahan tak terduga:", error);
}
}
SDK akan mencoba ulang permintaan yang gagal hingga 2 kali secara default, dengan batas waktu 60 detik. Kedua nilai ini dapat dikonfigurasi.
Streaming Audio Secara Real Time
Untuk chatbot, asisten suara, atau aplikasi apa pun di mana latensi menjadi masalah, streaming memungkinkan Anda mulai memutar audio sebelum seluruh respons dihasilkan. Ini sangat penting untuk AI percakapan di mana pengguna mengharapkan respons yang hampir instan.
Streaming Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
audio_stream = client.text_to_speech.stream(
text="Streaming allows you to start hearing audio almost instantly, without waiting for the entire generation to complete.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Putar audio yang di-streaming melalui speaker secara real time
stream(audio_stream)
Streaming JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "This audio streams in real time with minimal latency.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
Streaming WebSocket
Untuk latensi terendah, gunakan koneksi WebSocket. Ini ideal untuk agen suara real-time di mana teks tiba dalam potongan (misalnya, dari LLM):
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Kirim konfigurasi awal
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "your_api_key",
}))
# Kirim potongan teks saat tiba (misalnya, dari LLM)
text_chunks = [
"Hello! ",
"This is streaming ",
"via WebSockets. ",
"Each chunk is sent separately."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Sinyalkan akhir input
await ws.send(json.dumps({"text": ""}))
# Terima potongan audio
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("Audio WebSocket disimpan.")
asyncio.run(stream_tts_websocket())
Pemilihan dan Manajemen Suara
ElevenLabs menawarkan ratusan suara. Memilih suara yang tepat penting untuk pengalaman pengguna aplikasi Anda.
Suara Default
Suara-suara ini tersedia di semua paket, termasuk paket gratis:
| Nama Suara | ID Suara | Deskripsi |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Tenang, perempuan muda |
| Drew | 29vD33N1CtxCmqQRPOHJ | Pria yang lengkap |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Karakter veteran perang |
| Paul | 5Q0t7uMcjvnagumLfvZi | Reporter lapangan |
| Domi | AZnzlk1XvdvUeBnXmlld | Kuat, perempuan tegas |
| Dave | CYw3kZ02Hs0563khs1Fj | Pria Inggris yang komunikatif |
| Fin | D38z5RcWu1voky8WS1ja | Pria Irlandia |
| Sarah | EXAVITQu4vr4xnSDxMaL | Lembut, perempuan muda |
Menemukan ID Suara
Gunakan API untuk mencari semua suara yang tersedia:
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
Atau filter berdasarkan kategori (premade, cloned, generated):
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Hanya daftar suara yang sudah jadi
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
Anda juga dapat menyalin ID suara langsung dari situs web ElevenLabs: pilih suara, klik menu tiga titik, dan pilih **Salin ID Suara**.
Memilih Model yang Tepat
ElevenLabs menawarkan beberapa model, masing-masing dioptimalkan untuk kasus penggunaan yang berbeda:

# Cantumkan semua model yang tersedia dengan detailnya
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
models = client.models.list()
for model in models:
print(f"Model: {model.name}")
print(f" ID: {model.model_id}")
print(f" Languages: {len(model.languages)}")
print(f" Max chars: {model.max_characters_request_free_user}")
print()
Menguji API ElevenLabs dengan Apidog
Sebelum menulis kode integrasi, ada baiknya untuk menguji endpoint API secara interaktif. Apidog membuatnya mudah—Anda dapat mengonfigurasi permintaan secara visual, memeriksa respons (termasuk audio), dan menghasilkan kode klien setelah Anda puas.
button
Langkah 1: Siapkan Proyek Baru
Buka Apidog dan buat proyek baru. Beri nama "ElevenLabs API" atau tambahkan endpoint ke proyek yang sudah ada.
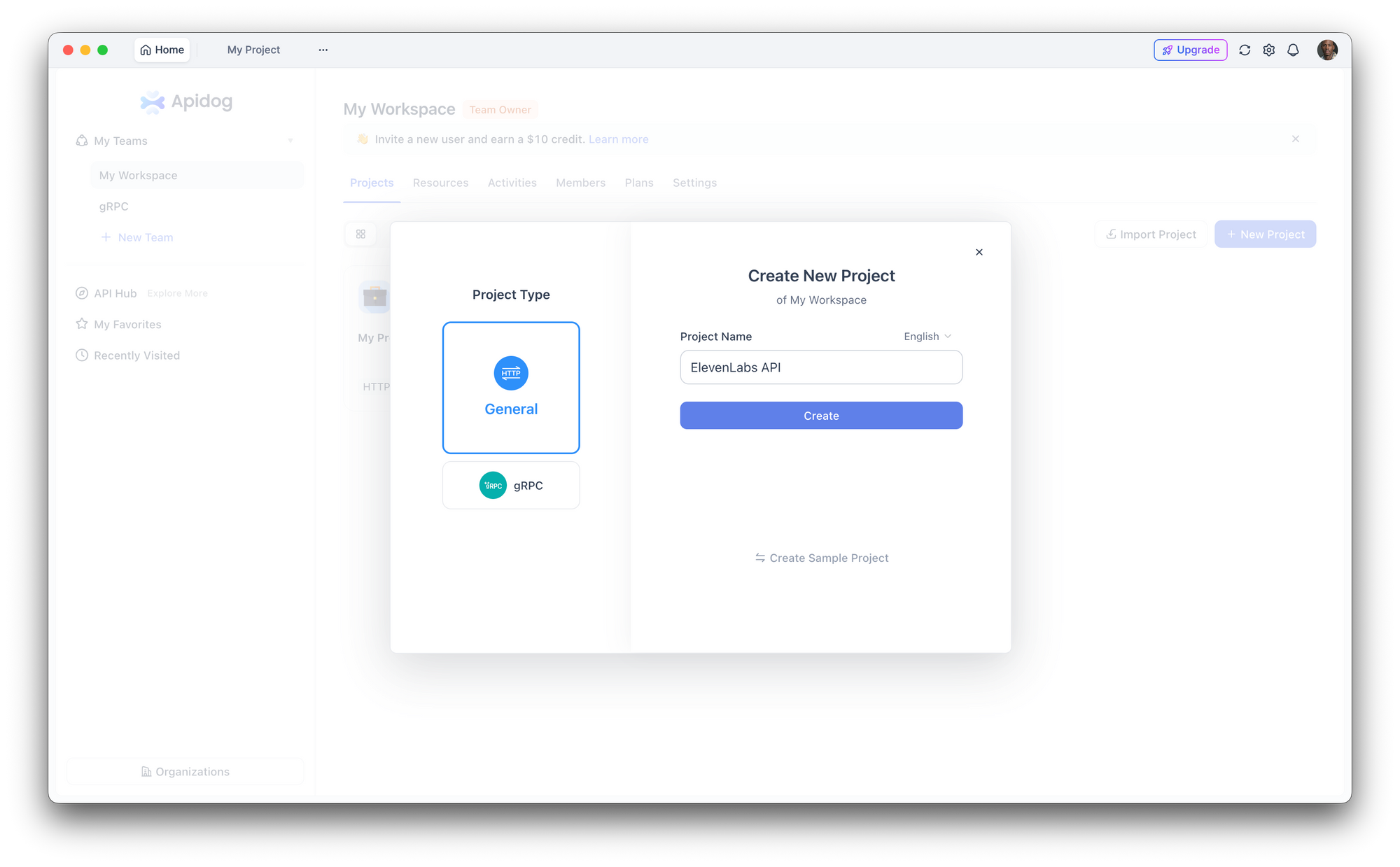
Langkah 2: Konfigurasi Otentikasi
Buka **Pengaturan Proyek > Auth** dan siapkan header global:
- Nama header:
xi-api-key - Nilai header: kunci API ElevenLabs Anda
Ini secara otomatis melampirkan otentikasi ke setiap permintaan dalam proyek.
Langkah 3: Buat Permintaan Text-to-Speech
Buat permintaan POST baru:
- URL:
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Body (JSON):
{
"text": "Menguji API ElevenLabs melalui Apidog. Ini memudahkan untuk bereksperimen dengan berbagai suara dan pengaturan.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
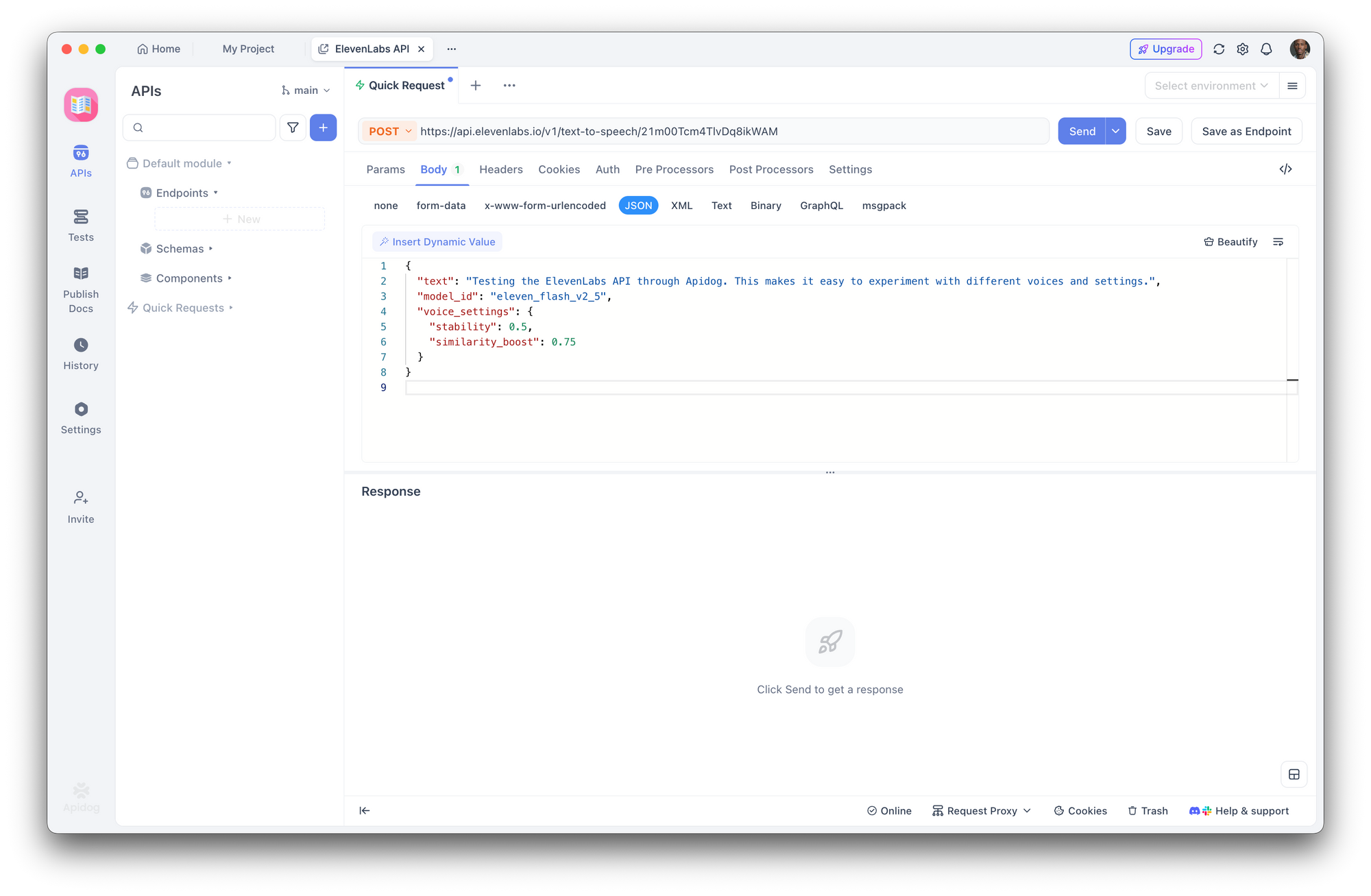
Klik **Kirim**. Apidog menampilkan header respons dan memungkinkan Anda mengunduh atau memutar audio secara langsung.
Langkah 4: Bereksperimen dengan Parameter
Gunakan antarmuka Apidog untuk dengan cepat mengganti ID suara, mengubah model, atau menyesuaikan pengaturan suara tanpa mengedit JSON mentah. Simpan konfigurasi yang berbeda sebagai endpoint terpisah dalam koleksi Anda untuk perbandingan yang mudah.
Langkah 5: Hasilkan Kode Klien
Setelah Anda mengonfirmasi bahwa permintaan berfungsi, klik **Hasilkan Kode** di Apidog untuk mendapatkan kode klien siap pakai dalam Python, JavaScript, cURL, Go, Java, dan lainnya. Ini menghilangkan terjemahan manual dari dokumen API ke kode yang berfungsi.
Coba sekarang:Unduh Apidog gratis
Pengaturan Suara dan Penyetelan Halus
Pengaturan suara memungkinkan Anda menyesuaikan bagaimana suara terdengar. Parameter-parameter ini dikirim dalam objek voice_settings:
| Parameter | Rentang | Default | Efek |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Lebih tinggi = lebih konsisten, kurang ekspresif. Lebih rendah = lebih bervariasi, lebih emosional. |
similarity_boost | 0.0 - 1.0 | 0.75 | Lebih tinggi = lebih dekat ke suara asli. Lebih rendah = lebih banyak variasi. |
style | 0.0 - 1.0 | 0.0 | Lebih tinggi = gaya lebih berlebihan. Meningkatkan latensi. Hanya untuk Multilingual v2. |
use_speaker_boost | boolean | true | Meningkatkan kemiripan dengan pembicara asli. Peningkatan latensi kecil. |
Contoh Praktis:
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="your_api_key")
# Suara narasi: konsisten, stabil
narration = client.text_to_speech.convert(
text="Chapter One. It was a bright cold day in April.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Suara percakapan: ekspresif, alami
conversational = client.text_to_speech.convert(
text="Oh wow, that's actually a great idea! Let me think about how we could make it work.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Pedoman:
- Untuk **buku audio dan narasi**, gunakan stabilitas yang lebih tinggi (0.7-0.9) untuk penyampaian yang konsisten
- Untuk **chatbot dan AI percakapan**, gunakan stabilitas yang lebih rendah (0.3-0.5) untuk variasi alami
- Untuk **suara karakter**, bereksperimenlah dengan `similarity_boost` yang lebih rendah (0.4-0.6) untuk menciptakan kepribadian yang berbeda
- Parameter `style` hanya berfungsi dengan Multilingual v2 dan menambah latensi—hindari untuk aplikasi real-time
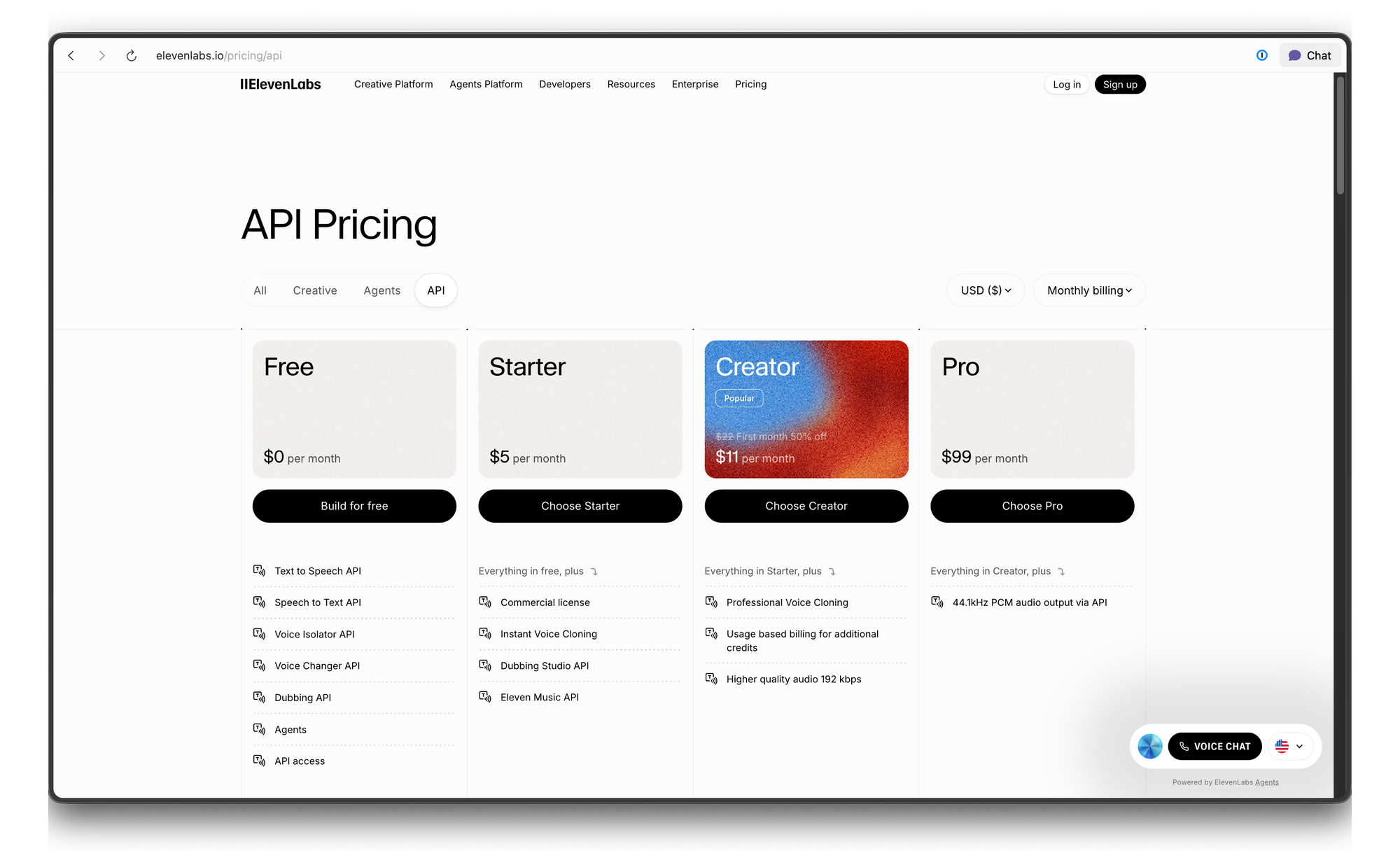
Harga API ElevenLabs dan Batas Tarif
ElevenLabs menggunakan sistem harga berbasis kredit. Berikut adalah rinciannya:
Pemecahan Masalah
| Kesalahan | Penyebab | Solusi |
|---|---|---|
| 401 Unauthorized | Kunci API tidak valid atau hilang | Periksa nilai headerxi-api-keyAnda |
| 422 Unprocessable Entity | Badan permintaan tidak valid | Verifikasi voice_id ada dan teks tidak kosong |
| 429 Too Many Requests | Batas tarif terlampaui | Tambahkan `exponential backoff`, atau tingkatkan paket Anda |
| Audio terdengar robotik | Model atau pengaturan salah | Coba Multilingual v2 dengan stabilitas 0.5 |
| Kesalahan pengucapan | Masalah normalisasi teks | Eja angka/singkatan, atau gunakan pemformatan mirip SSML |
Kesimpulan
API ElevenLabs memberikan akses kepada pengembang ke beberapa sintesis ucapan paling realistis yang tersedia saat ini. Baik Anda memerlukan beberapa baris narasi atau alur suara real-time penuh, API ini dapat diskalakan dari panggilan cURL sederhana hingga aliran WebSocket produksi.
Siap menambahkan suara realistis ke aplikasi Anda? Unduh Apidog untuk menguji endpoint API ElevenLabs, bereksperimen dengan pengaturan suara, dan menghasilkan kode klien—semuanya gratis, tanpa kartu kredit.
button