
Les développeurs se tournent de plus en plus vers les plateformes serverless pour l'inférence d'IA, et l'API Fal.ai se distingue comme une option robuste pour les médias génératifs. Cette API vous permet d'exécuter des modèles pour la génération d'images, de vidéos, de voix et de code sans gérer l'infrastructure. Vous accédez à plus de 600 modèles prêts pour la production via une interface unifiée, qui s'adapte efficacement avec des GPU à la demande.
Ensuite, nous explorons les fondamentaux de l'API Fal.ai et vous guidons à travers son accès et son utilisation.
Qu'est-ce que l'API Fal.ai ?
L'API Fal.ai fournit une plateforme de médias génératifs qui alimente les applications avec une inférence d'IA rapide. Les ingénieurs l'utilisent pour intégrer des modèles de pointe dans les logiciels, en contournant la nécessité de gérer l'infrastructure. La plateforme offre des performances 10 fois plus rapides par rapport aux configurations traditionnelles, grâce à des GPU serverless optimisés qui peuvent évoluer jusqu'à des milliers d'équivalents H100.

À la base, l'API Fal.ai se concentre sur la génération de médias. Par exemple, vous générez des images de haute qualité à partir d'invites textuelles en utilisant des modèles comme FLUX.1. De plus, elle prend en charge l'animation vidéo, la synthèse vocale et les interactions avec les grands modèles linguistiques. Cependant, l'API met l'accent sur la préparation à la production, avec des fonctionnalités telles que l'inférence en streaming et la prise en charge des webhooks pour les tâches asynchrones.
De plus, l'API Fal.ai fonctionne sur un modèle de paiement à l'utilisation, ce qui rend les coûts prévisibles. Vous ne payez que pour la puissance de calcul que vous consommez, ce qui la rend adaptée aussi bien aux prototypes qu'aux applications à grande échelle. Pour passer aux détails, examinons comment vous vous inscrivez.
Comment s'inscrire à l'API Fal.ai ?
Vous commencez par créer un compte sur le site web de Fal.ai. Naviguez vers fal.ai et localisez le bouton d'inscription dans le coin supérieur droit. Fournissez votre adresse e-mail, définissez un mot de passe et vérifiez votre compte via l'e-mail de confirmation. Ce processus prend moins d'une minute.
Une fois inscrit, vous accédez au tableau de bord. Ici, vous gérez les modèles, consultez les statistiques d'utilisation et générez des clés API. Fal.ai ne nécessite pas de carte de crédit pour l'inscription initiale, mais vous pouvez ajouter des détails de paiement plus tard pour les fonctionnalités payantes. De plus, la plateforme offre un niveau gratuit avec des crédits limités, ce qui vous permet de tester les fonctionnalités de base.
Après l'inscription, explorez le catalogue de modèles. Vous pouvez choisir parmi des catégories telles que texte-vers-image ou texte-vers-vidéo. Cette étape vous familiarise avec les points d'extrémité disponibles. Maintenant, avec un compte prêt, vous pouvez obtenir votre clé API.
Comment obtenir votre clé API Fal.ai ?
L'API Fal.ai s'appuie sur les clés API pour l'authentification. Vous en générez une depuis le tableau de bord. Tout d'abord, connectez-vous et cliquez sur la section "Clés" sous votre profil. Ensuite, sélectionnez "Générer une nouvelle clé" et nommez-la pour référence, par exemple "Clé de développement".
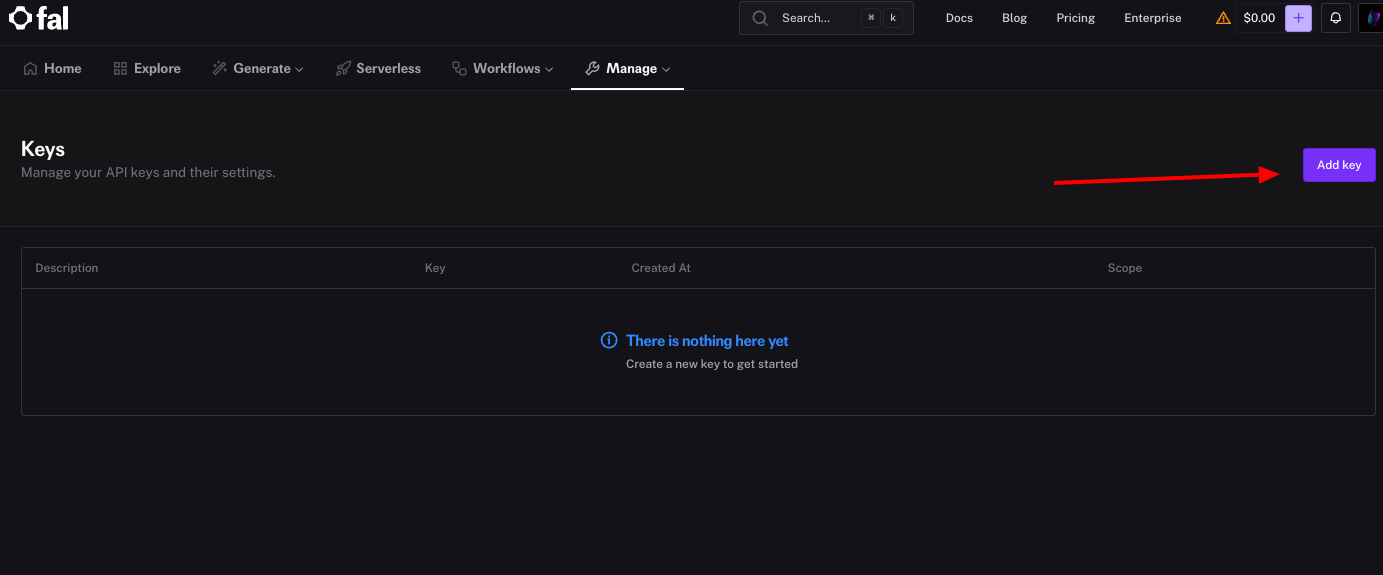
Le système affiche la clé immédiatement – copiez-la et stockez-la en toute sécurité, car Fal.ai ne la montrera plus. Vous définissez cette clé comme variable d'environnement, par exemple export FAL_KEY="votre_clé_ici", pour éviter de la coder en dur dans les scripts.
Si vous travaillez avec plusieurs projets, générez des clés distinctes pour chacun. Cette pratique améliore la sécurité en permettant la révocation sans affecter les autres intégrations. De plus, surveillez l'utilisation des clés dans le tableau de bord pour détecter les anomalies. Avec la clé en main, vous installerez la bibliothèque cliente ensuite.
Comment installer le client Fal.ai ?
Fal.ai fournit des bibliothèques clientes officielles pour une intégration plus facile. Pour les environnements JavaScript ou Node.js, vous installez le client via npm. Exécutez la commande npm install --save @fal-ai/client dans le répertoire de votre projet.
Cette bibliothèque gère l'authentification, la soumission des requêtes et l'analyse des réponses. Elle remplace @fal-ai/serverless-client qui est déprécié, assurez-vous donc d'utiliser la dernière version. Pour les utilisateurs de Python, installez fal-client avec pip install fal-client.
Une fois installée, importez la bibliothèque dans votre code. Par exemple, en JavaScript : import { fal } from "@fal-ai/client";. Vous la configurez avec vos identifiants si vous n'utilisez pas de variables d'environnement. Cette configuration simplifie les appels aux points d'extrémité de l'API Fal.ai. Pour la suite, l'authentification devient la prochaine étape critique.
Comment authentifier les requêtes avec l'API Fal.ai ?
L'authentification sécurise vos interactions avec l'API Fal.ai. Vous utilisez principalement la clé API dans les en-têtes ou les variables d'environnement. Pour les requêtes HTTP directes, incluez Authorization: Key votre_clé_fal dans l'en-tête.
Cependant, la bibliothèque cliente automatise cela. Configurez-la une fois : fal.config({ credentials: "votre_clé_fal" });. Cette approche évite l'exposition dans le code côté client — proxyisez toujours les requêtes si vous créez des applications web.
L'API Fal.ai ne prend actuellement pas en charge d'autres méthodes d'authentification comme OAuth. Testez l'authentification en effectuant une simple requête ; une erreur 401 indique des problèmes. De plus, faites pivoter les clés périodiquement pour les meilleures pratiques de sécurité. Authentifié maintenant, vous explorez les modèles disponibles.
Quels sont les modèles disponibles dans l'API Fal.ai ?
L'API Fal.ai héberge une bibliothèque de modèles diversifiée. Les catégories clés incluent texte-vers-image, texte-vers-vidéo, synthèse vocale et grands modèles linguistiques. Par exemple, FLUX.1 [dev] génère des images à partir d'invites avec son transformateur de 12 milliards de paramètres.
Autres modèles notables : FLUX.1 [schnell] pour une génération rapide en 1 à 4 étapes, Stable Diffusion 3.5 pour des images riches en typographie, et Whisper pour la transcription audio. Vous y accédez via des identifiants uniques comme "fal-ai/flux/dev".
Parcourez l'aire de jeu des modèles sur fal.ai/models pour les tester de manière interactive. Chaque page de modèle détaille les paramètres, les exemples et les prix. Cette variété permet des sélections sur mesure. Par exemple, choisissez Recraft V3 pour l'art vectoriel. Une fois les modèles identifiés, vous apprenez à générer des images.
Comment générer des images en utilisant l'API Fal.ai ?
Vous générez des images en vous abonnant à un point d'extrémité de modèle. Utilisez le client pour envoyer une requête POST avec des paramètres d'entrée. Pour FLUX.1 [dev], le code ressemble à ceci :
import { fal } from "@fal-ai/client";
const result = await fal.subscribe("fal-ai/flux/dev", {
input: {
prompt: "A futuristic cityscape at dusk, with neon lights and flying cars",
image_size: "landscape_16_9",
num_inference_steps: 28,
guidance_scale: 3.5
}
});
console.log(result.images[0].url);
Cette requête produit une URL d'image. L'API traite l'invite et renvoie des métadonnées telles que les timings et la graine. De plus, activez les contrôles de sécurité pour filtrer le contenu NSFW : enable_safety_checker: true.
Testez des variations en ajustant les invites. Pour la génération par lot, définissez num_images: 4. Les sorties incluent des URL, des dimensions et des types de contenu. Cette méthode constitue la base des tâches multimédias. Ensuite, personnalisez avec des paramètres avancés.
Utilisation avancée : paramètres et personnalisation dans l'API Fal.ai
L'API Fal.ai offre des paramètres étendus pour un réglage précis. Pour la génération d'images, prompt contrôle le contenu, tandis que guidance_scale contrôle l'adhérence — des valeurs plus élevées donnent des résultats plus stricts, généralement entre 1.0 et 20.0.
Définissez image_size comme des énumérations comme "square_hd" ou des objets personnalisés : { width: 1024, height: 768 }. Les étapes d'inférence (num_inference_steps) équilibrent vitesse et qualité ; 20-50 fonctionne bien. Seed assure la reproductibilité : fournissez un entier pour des sorties cohérentes.
Les modes d'accélération ("none", "regular", "high") optimisent le temps d'exécution. Pour la sortie, choisissez "jpeg" ou "png" via output_format. Gérez les fichiers en téléchargeant via fal.storage.upload(file) ou en utilisant des URL/base64.
Personnalisez davantage avec des webhooks pour les notifications. Ces options améliorent le contrôle. Cependant, surveillez les coûts, car plus d'étapes augmentent la facturation. En passant à l'efficacité, la gestion asynchrone suit.
Comment gérer les requêtes asynchrones et les files d'attente dans l'API Fal.ai ?
L'API Fal.ai prend en charge les files d'attente pour les tâches longues. Soumettez via fal.queue.submit(model_id, { input: {...} }), en recevant un request_id. Sondez l'état : fal.queue.status(model_id, { requestId: "id" }).
Récupérez les résultats : fal.queue.result(model_id, { requestId: "id" }). Incluez webhookUrl pour les rappels. Cela découple la soumission de l'attente, idéal pour le traitement par lots.
Le streaming fournit des mises à jour en temps réel :
const stream = await fal.stream("fal-ai/flux/dev", { input: {...} });
for await (const event of stream) {
console.log(event);
}
const result = await stream.done();
Les files d'attente évitent les expirations de délai. De plus, les journaux (logs: true) facilitent le débogage. Une fois l'asynchrone maîtrisé, intégrez des outils de test comme Apidog.
Comment intégrer l'API Fal.ai avec Apidog ?
Apidog améliore le développement de l'API Fal.ai en offrant une plateforme unifiée pour les tests. Tout d'abord, créez un projet dans Apidog et importez le schéma OpenAPI depuis fal.ai/docs (par exemple, /api/openapi/queue/openapi.json?endpoint_id=fal-ai/flux/dev).
Configurez l'authentification : Ajoutez Authorization: Key votre_clé_fal dans les en-têtes. Configurez les requêtes pour des points d'extrémité comme POST vers "fal-ai/flux/dev", incluant des charges utiles JSON avec prompt et des paramètres.
Apidog simule les réponses, simulant les délais GPU et les sorties. Téléchargez des fichiers pour les modifications d'image ou testez les cas limites. Exécutez des collections pour couvrir des scénarios, en déboguant les invites de manière itérative.
Les avantages incluent des itérations plus rapides (jusqu'à 40% rapporté), des économies de coûts grâce aux mocks et la détection d'erreurs (par exemple, limites de taux 429). Les fonctionnalités de collaboration d'équipe garantissent la cohérence. Cette intégration optimise les flux de travail. Ensuite, adoptez les meilleures pratiques.
Bonnes pratiques pour l'utilisation de l'API Fal.ai
Optimisez les performances en sélectionnant les modèles appropriés — utilisez des variantes plus rapides pour la vitesse. Limitez les points de données dans les requêtes pour éviter la latence. De plus, implémentez la mise en cache pour les invites répétées.
Sécurisez les clés avec des variables d'environnement et des proxys. Surveillez l'utilisation via le tableau de bord pour contrôler les coûts. Traitez les requêtes par lots lorsque cela est possible, mais respectez les limites de taux.
Pour la production, utilisez des clusters dédiés pour les charges lourdes. Testez minutieusement avec des mocks dans Apidog. De plus, rejoignez le Discord de Fal.ai pour des informations de la communauté. Ces pratiques garantissent des intégrations fiables. Cependant, des erreurs peuvent survenir, il faut donc les gérer correctement.
Comment gérer les erreurs dans l'API Fal.ai ?
L'API Fal.ai renvoie des erreurs structurées. Les problèmes clients (par exemple, validation) donnent des codes 4xx avec des détails comme "Invalid prompt". Les erreurs serveur sont 5xx, souvent transitoires — réessayez avec un délai d'attente exponentiel.
Erreurs courantes : 401 (authentification échouée) — vérifiez la clé ; 429 (limite de taux) — attendez et réduisez la fréquence ; 400 (mauvaise entrée) — validez les paramètres.
Dans le code, interceptez les exceptions :
try {
const result = await fal.subscribe(...);
} catch (error) {
console.error(error.response.data);
}
Les journaux aident au diagnostic. Apidog simule les erreurs pour les tests. Une bonne gestion maintient la robustesse. Enfin, considérez la tarification.
Quelle est la tarification de l'API Fal.ai ?
L'API Fal.ai utilise une tarification à l'utilisation. Les frais serverless sont par sortie, par exemple, 0,0001 $ par mégapixel pour les images. Les modèles vidéo comme Veo 3 coûtent 0,20 $/seconde (audio désactivé).
Le niveau gratuit offre des crédits initiaux. Mettez à niveau pour plus via le tableau de bord. La tarification GPU horaire commence à 1,2 $ pour les H100 en mode Calcul.
Suivez les dépenses dans le tableau de bord. Optimisez en réduisant les étapes ou en utilisant des modèles plus rapides. Ce modèle convient aux charges de travail variables. En résumé, l'API Fal.ai permet un développement IA efficace.
Conclusion
Vous comprenez maintenant comment accéder et utiliser l'API Fal.ai de manière complète. De l'inscription et la génération de clés aux intégrations avancées avec Apidog, ce guide vous équipe pour des applications prêtes pour la production. Expérimentez avec les modèles, gérez les erreurs avec diligence et surveillez les coûts. À mesure que l'IA évolue, l'API Fal.ai reste un outil polyvalent. Commencez à construire dès aujourd'hui.