
ElevenLabs transforme le texte en un discours naturel et prend en charge un large éventail de voix, de langues et de styles. L'API facilite l'intégration de la voix dans les applications, l'automatisation des pipelines de narration ou la création d'expériences en temps réel comme les agents vocaux. Si vous pouvez envoyer une requête HTTP, vous pouvez générer de l'audio en quelques secondes.
Qu'est-ce que l'API ElevenLabs ?
L'API ElevenLabs fournit un accès programmatique aux modèles d'IA qui génèrent, transforment et analysent l'audio. La plateforme a débuté en tant que service de synthèse vocale, mais s'est étendue pour devenir une suite complète d'IA audio.
Capacités principales :
- Synthèse vocale (TTS) : Convertir du texte écrit en audio parlé avec un contrôle sur les caractéristiques vocales, l'émotion et le rythme
- Speech-to-Speech (STS) : Transformer une voix en une autre tout en préservant l'intonation et le timing d'origine
- Clonage de voix : Créer une réplique numérique de n'importe quelle voix à partir d'aussi peu que 60 secondes d'audio clair
- Doublage IA : Traduire et doubler du contenu audio/vidéo dans différentes langues tout en conservant les caractéristiques vocales de l'orateur
- Effets sonores : Générer des effets sonores à partir de descriptions textuelles
- Speech-to-Text : Transcrire l'audio en texte avec une grande précision
L'API fonctionne via les protocoles HTTP et WebSocket standards. Vous pouvez l'appeler depuis n'importe quel langage, mais des SDK officiels existent pour Python et JavaScript/TypeScript avec une sécurité de type et un support de streaming intégrés.
Obtenir la clé API ElevenLabs
Avant d'effectuer tout appel API, vous avez besoin d'une clé API. Voici comment en obtenir une :
Étape 1 : Créez un compte gratuit. Même le plan gratuit inclut l'accès à l'API avec 10 000 caractères par mois.
Étape 2 : Connectez-vous et naviguez vers la section Profil + Clé API. Vous pouvez la trouver en cliquant sur votre icône de profil dans le coin inférieur gauche, ou en allant directement aux paramètres de développement.
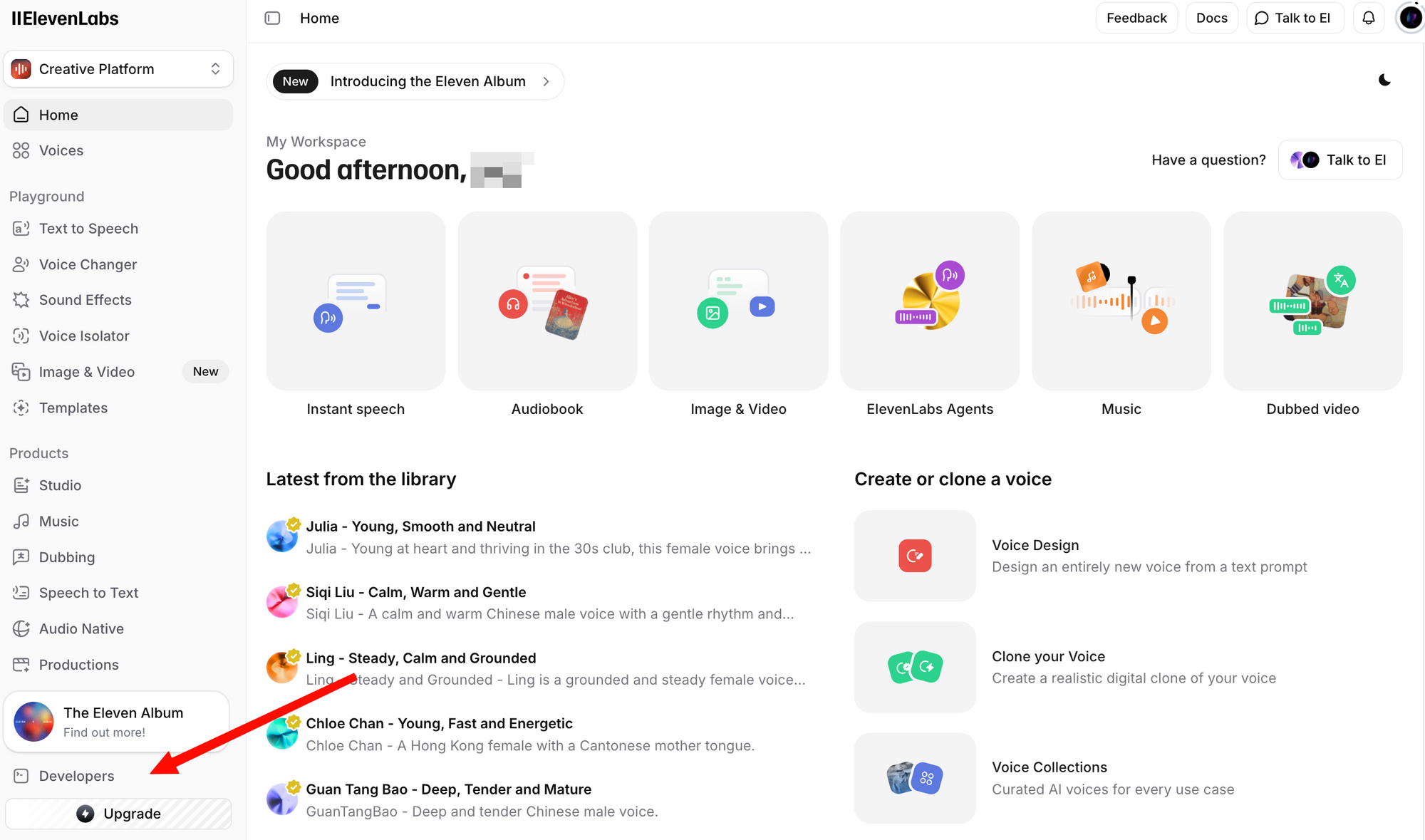
Étape 3 : Cliquez sur Créer une clé API. Copiez la clé et stockez-la en toute sécurité – vous ne pourrez plus revoir la clé complète.
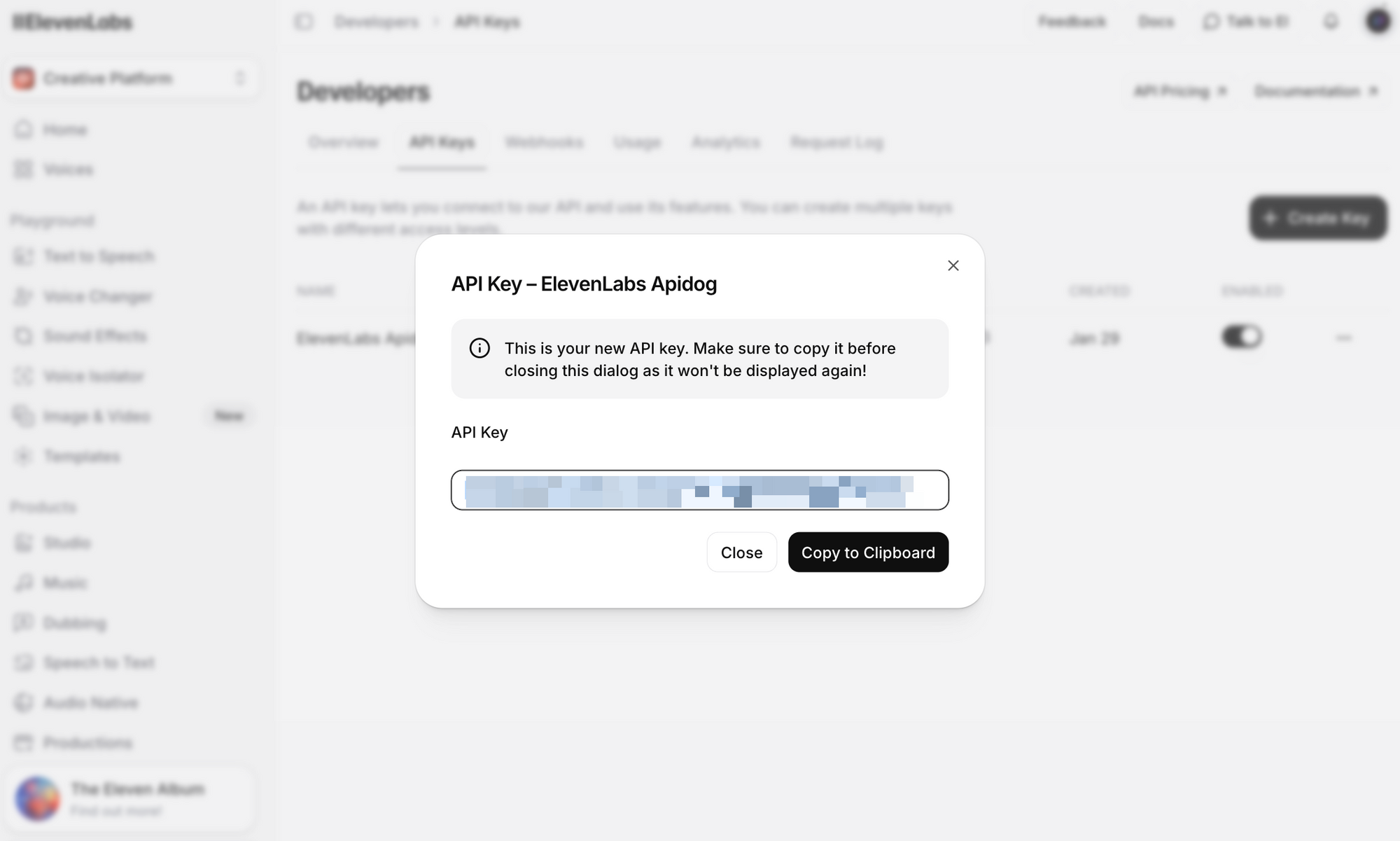
Notes de sécurité importantes :
- Ne jamais commettre votre clé API dans le contrôle de version
- Utilisez des variables d'environnement ou un gestionnaire de secrets en production
- Les clés API peuvent être limitées à des espaces de travail spécifiques pour les environnements d'équipe
- Faites pivoter les clés régulièrement et révoquez immédiatement les clés compromises
Définissez-la comme variable d'environnement pour les exemples de ce guide :
# Linux/macOS
export ELEVENLABS_API_KEY="your_api_key_here"
# Windows (PowerShell)
$env:ELEVENLABS_API_KEY="your_api_key_here"
Présentation des points d'extrémité de l'API ElevenLabs
L'API est organisée autour de plusieurs groupes de ressources. Voici les points d'extrémité les plus couramment utilisés :
| Point d'extrémité | Méthode | Description |
|---|---|---|
/v1/text-to-speech/{voice_id} | POST | Convertir du texte en audio |
/v1/text-to-speech/{voice_id}/stream | POST | Diffuser l'audio au fur et à mesure de sa génération |
/v1/speech-to-speech/{voice_id} | POST | Convertir la parole d'une voix à une autre |
/v1/voices | GET | Lister toutes les voix disponibles |
/v1/voices/{voice_id} | GET | Obtenir les détails d'une voix spécifique |
/v1/models | GET | Lister tous les modèles disponibles |
/v1/user | GET | Obtenir les informations du compte utilisateur et l'utilisation |
/v1/voice-generation/generate-voice | POST | Générer une nouvelle voix aléatoire |
URL de base : https://api.elevenlabs.io
Authentification : Toutes les requêtes nécessitent l'en-tête xi-api-key :
xi-api-key: your_api_key_here
Synthèse vocale avec cURL
Le moyen le plus rapide de tester l'API est d'utiliser une commande cURL. Cet exemple utilise la voix de Rachel (ID : 21m00Tcm4TlvDq8ikWAM), l'une des voix par défaut disponibles sur tous les plans :
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"text": "Bienvenue dans notre application. Cet audio a été généré en utilisant l'API ElevenLabs.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75,
"style": 0.0,
"use_speaker_boost": true
}
}' \
--output speech.mp3
En cas de succès, vous obtiendrez un fichier speech.mp3 avec l'audio généré. Lisez-le avec n'importe quel lecteur multimédia.
Détail de la requête :
- voice_id (dans l'URL) : L'ID de la voix à utiliser. Chaque voix dans ElevenLabs a un ID unique.
- text : Le contenu à convertir en parole. Le modèle Flash v2.5 prend en charge jusqu'à 40 000 caractères par requête.
- model_id : Le modèle d'IA à utiliser.
eleven_flash_v2_5offre le meilleur équilibre entre vitesse et qualité. - voice_settings : Paramètres de réglage facultatifs (détaillés ci-dessous).
La réponse renvoie des données audio brutes. Le format par défaut est MP3, mais vous pouvez demander d'autres formats en ajoutant le paramètre de requête output_format :
# Obtenir l'audio PCM au lieu du MP3
curl -X POST "https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM?output_format=pcm_44100" \
-H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text": "Bonjour le monde", "model_id": "eleven_flash_v2_5"}' \
--output speech.pcm
Utilisation du SDK Python
Le SDK Python officiel simplifie l'intégration avec des indications de type, la lecture audio intégrée et la prise en charge du streaming.
Installation
pip install elevenlabs
Pour lire l'audio directement via vos haut-parleurs, vous pourriez également avoir besoin de mpv ou ffmpeg :
# macOS
brew install mpv
# Ubuntu/Debian
sudo apt install mpv
Synthèse vocale de base
import os
from elevenlabs.client import ElevenLabs
from elevenlabs import play
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY")
)
audio = client.text_to_speech.convert(
text="L'API ElevenLabs facilite l'ajout d'une sortie vocale réaliste à n'importe quelle application.",
voice_id="JBFqnCBsd6RMkjVDRZzb", # voix de George
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
play(audio)
Enregistrer l'audio dans un fichier
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
audio = client.text_to_speech.convert(
text="Cet audio sera enregistré dans un fichier.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("output.mp3", "wb") as f:
for chunk in audio:
f.write(chunk)
print("Audio enregistré dans output.mp3")
Lister les voix disponibles
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
response = client.voices.search()
for voice in response.voices:
print(f"Nom : {voice.name}, ID : {voice.voice_id}, Catégorie : {voice.category}")
Ceci affiche toutes les voix disponibles dans votre compte, y compris les voix pré-enregistrées, les voix clonées et les voix communautaires que vous avez ajoutées.
Support asynchrone
Pour les applications utilisant asyncio, le SDK fournit AsyncElevenLabs :
import asyncio
from elevenlabs.client import AsyncElevenLabs
client = AsyncElevenLabs(api_key="votre_clé_api")
async def generate_speech():
audio = await client.text_to_speech.convert(
text="Ceci a été généré de manière asynchrone.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_flash_v2_5",
)
with open("async_output.mp3", "wb") as f:
async for chunk in audio:
f.write(chunk)
print("Audio asynchrone enregistré.")
asyncio.run(generate_speech())
Utilisation du SDK JavaScript
Le SDK Node.js officiel (@elevenlabs/elevenlabs-js) offre un support TypeScript complet et fonctionne dans les environnements Node.js.
Installation
npm install @elevenlabs/elevenlabs-js
Synthèse vocale de base
import { ElevenLabsClient, play } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM", // ID de la voix de Rachel
{
text: "Bonjour depuis le SDK JavaScript d'ElevenLabs !",
modelId: "eleven_multilingual_v2",
}
);
await play(audio);
Enregistrer dans un fichier (Node.js)
import { ElevenLabsClient } from "@elevenlabs/elevenlabs-js";
import { createWriteStream } from "fs";
import { Readable } from "stream";
import { pipeline } from "stream/promises";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Cet audio sera écrit dans un fichier en utilisant les flux Node.js.",
modelId: "eleven_flash_v2_5",
}
);
const readable = Readable.from(audio);
const writeStream = createWriteStream("output.mp3");
await pipeline(readable, writeStream);
console.log("Audio enregistré dans output.mp3");
Gestion des erreurs
import { ElevenLabsClient, ElevenLabsError } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient({
apiKey: process.env.ELEVENLABS_API_KEY,
});
try {
const audio = await elevenlabs.textToSpeech.convert(
"21m00Tcm4TlvDq8ikWAM",
{
text: "Test de la gestion des erreurs.",
modelId: "eleven_flash_v2_5",
}
);
await play(audio);
} catch (error) {
if (error instanceof ElevenLabsError) {
console.error(`Erreur API : ${error.message}, Statut : ${error.statusCode}`);
} else {
console.error("Erreur inattendue :", error);
}
}
Le SDK réessaie les requêtes échouées jusqu'à 2 fois par défaut, avec un délai d'attente de 60 secondes. Ces deux valeurs sont configurables.
Diffusion audio en temps réel
Pour les chatbots, les assistants vocaux ou toute application où la latence est importante, le streaming vous permet de commencer à lire l'audio avant que la réponse complète ne soit générée. C'est essentiel pour l'IA conversationnelle où les utilisateurs attendent des réponses quasi instantanées.
Streaming Python
from elevenlabs import stream
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
audio_stream = client.text_to_speech.stream(
text="Le streaming vous permet de commencer à entendre l'audio presque instantanément, sans attendre que la génération complète soit terminée.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_flash_v2_5",
)
# Lire l'audio diffusé via les haut-parleurs en temps réel
stream(audio_stream)
Streaming JavaScript
import { ElevenLabsClient, stream } from "@elevenlabs/elevenlabs-js";
const elevenlabs = new ElevenLabsClient();
const audioStream = await elevenlabs.textToSpeech.stream(
"JBFqnCBsd6RMkjVDRZzb",
{
text: "Cet audio est diffusé en temps réel avec une latence minimale.",
modelId: "eleven_flash_v2_5",
}
);
stream(audioStream);
Streaming WebSocket
Pour la latence la plus faible, utilisez les connexions WebSocket. C'est idéal pour les agents vocaux en temps réel où le texte arrive par blocs (par exemple, d'un LLM) :
import asyncio
import websockets
import json
import base64
async def stream_tts_websocket():
voice_id = "21m00Tcm4TlvDq8ikWAM"
model_id = "eleven_flash_v2_5"
uri = f"wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-input?model_id={model_id}"
async with websockets.connect(uri) as ws:
# Envoyer la configuration initiale
await ws.send(json.dumps({
"text": " ",
"voice_settings": {"stability": 0.5, "similarity_boost": 0.75},
"xi_api_key": "votre_clé_api",
}))
# Envoyer des blocs de texte au fur et à mesure qu'ils arrivent (par exemple, d'un LLM)
text_chunks = [
"Bonjour ! ",
"Ceci est du streaming ",
"via WebSockets. ",
"Chaque bloc est envoyé séparément."
]
for chunk in text_chunks:
await ws.send(json.dumps({"text": chunk}))
# Signaler la fin de l'entrée
await ws.send(json.dumps({"text": ""}))
# Recevoir des blocs audio
audio_data = b""
async for message in ws:
data = json.loads(message)
if data.get("audio"):
audio_data += base64.b64decode(data["audio"])
if data.get("isFinal"):
break
with open("websocket_output.mp3", "wb") as f:
f.write(audio_data)
print("Audio WebSocket enregistré.")
asyncio.run(stream_tts_websocket())
Sélection et gestion des voix
ElevenLabs propose des centaines de voix. Choisir la bonne voix est important pour l'expérience utilisateur de votre application.
Voix par défaut
Ces voix sont disponibles sur tous les plans, y compris le niveau gratuit :
| Nom de la voix | ID de la voix | Description |
|---|---|---|
| Rachel | 21m00Tcm4TlvDq8ikWAM | Femme calme et jeune |
| Drew | 29vD33N1CtxCmqQRPOHJ | Homme équilibré |
| Clyde | 2EiwWnXFnvU5JabPnv8n | Personnage vétéran de guerre |
| Paul | 5Q0t7uMcjvnagumLfvZi | Reporter de terrain |
| Domi | AZnzlk1XvdvUeBnXmlld | Femme forte et affirmée |
| Dave | CYw3kZ02Hs0563khs1Fj | Homme britannique conversationnel |
| Fin | D38z5RcWu1voky8WS1ja | Homme irlandais |
| Sarah | EXAVITQu4vr4xnSDxMaL | Femme douce et jeune |
Trouver les ID de voix
Utilisez l'API pour rechercher toutes les voix disponibles :
curl -X GET "https://api.elevenlabs.io/v1/voices" \
-H "xi-api-key: $ELEVENLABS_API_KEY" | python3 -m json.tool
Ou filtrez par catégorie (pré-enregistrée, clonée, générée) :
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
# Lister uniquement les voix pré-enregistrées
response = client.voices.search(category="premade")
for voice in response.voices:
print(f"{voice.name}: {voice.voice_id}")
Vous pouvez également copier un ID de voix directement depuis le site Web d'ElevenLabs : sélectionnez une voix, cliquez sur le menu à trois points et choisissez Copier l'ID de voix.
Choisir le bon modèle
ElevenLabs propose plusieurs modèles, chacun optimisé pour différents cas d'utilisation :

# Lister tous les modèles disponibles avec leurs détails
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
models = client.models.list()
for model in models:
print(f"Modèle : {model.name}")
print(f" ID : {model.model_id}")
print(f" Langues : {len(model.languages)}")
print(f" Max caractères : {model.max_characters_request_free_user}")
print()
Tester l'API ElevenLabs avec Apidog
Avant d'écrire du code d'intégration, il est utile de tester les points d'extrémité de l'API de manière interactive. Apidog rend cela simple : vous pouvez configurer les requêtes visuellement, inspecter les réponses (y compris l'audio) et générer du code client une fois que vous êtes satisfait.
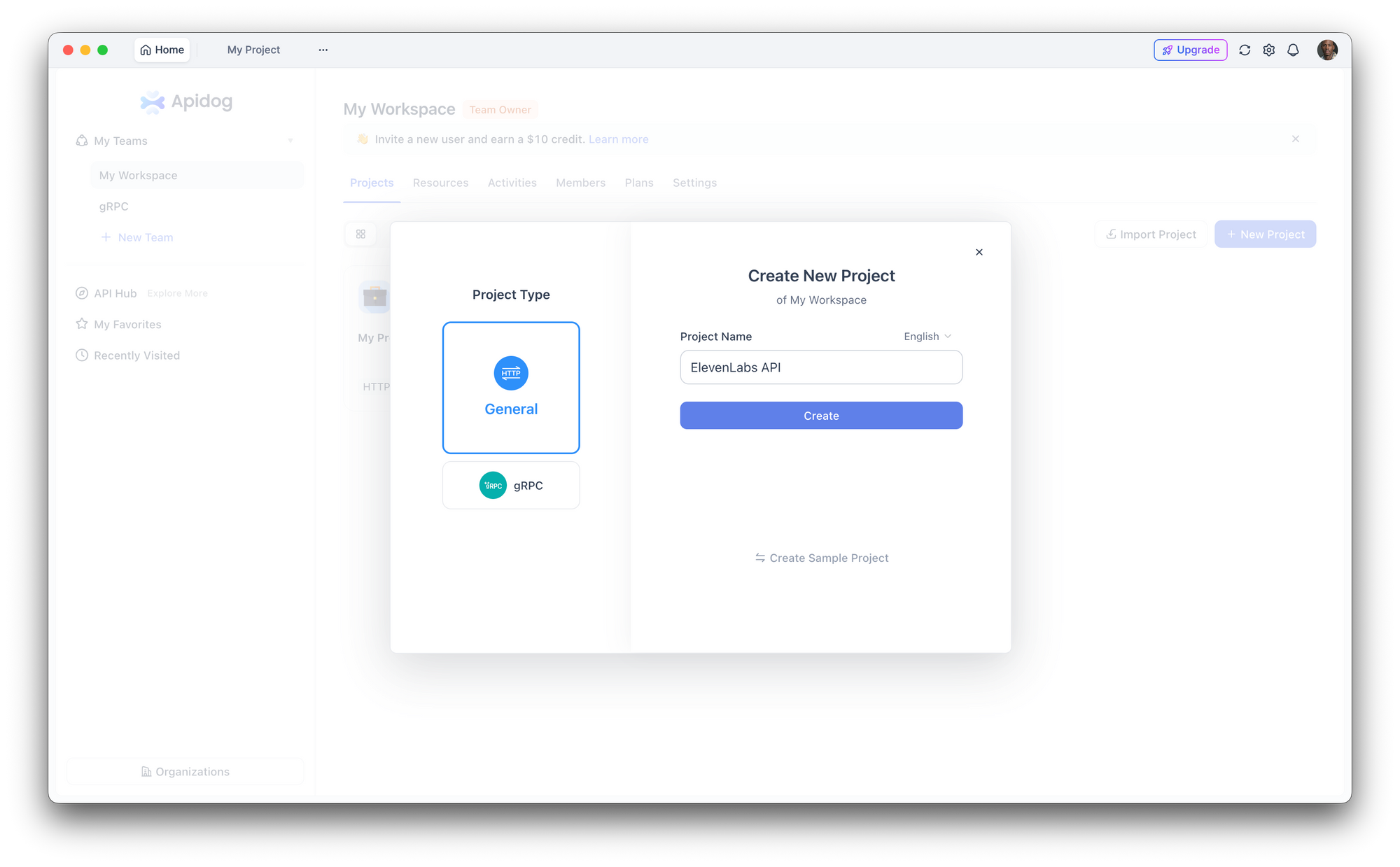
Étape 1 : Créer un nouveau projet
Ouvrez Apidog et créez un nouveau projet. Nommez-le "ElevenLabs API" ou ajoutez les points d'extrémité à un projet existant.
Étape 2 : Configurer l'authentification
Allez dans Paramètres du projet > Auth et configurez un en-tête global :
- Nom de l'en-tête :
xi-api-key - Valeur de l'en-tête : votre clé API ElevenLabs
Ceci attache automatiquement l'authentification à chaque requête du projet.
Étape 3 : Créer une requête de synthèse vocale
Créez une nouvelle requête POST :
- URL :
https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM - Corps (JSON) :
{
"text": "Tester l'API ElevenLabs via Apidog. Cela facilite l'expérimentation avec différentes voix et paramètres.",
"model_id": "eleven_flash_v2_5",
"voice_settings": {
"stability": 0.5,
"similarity_boost": 0.75
}
}
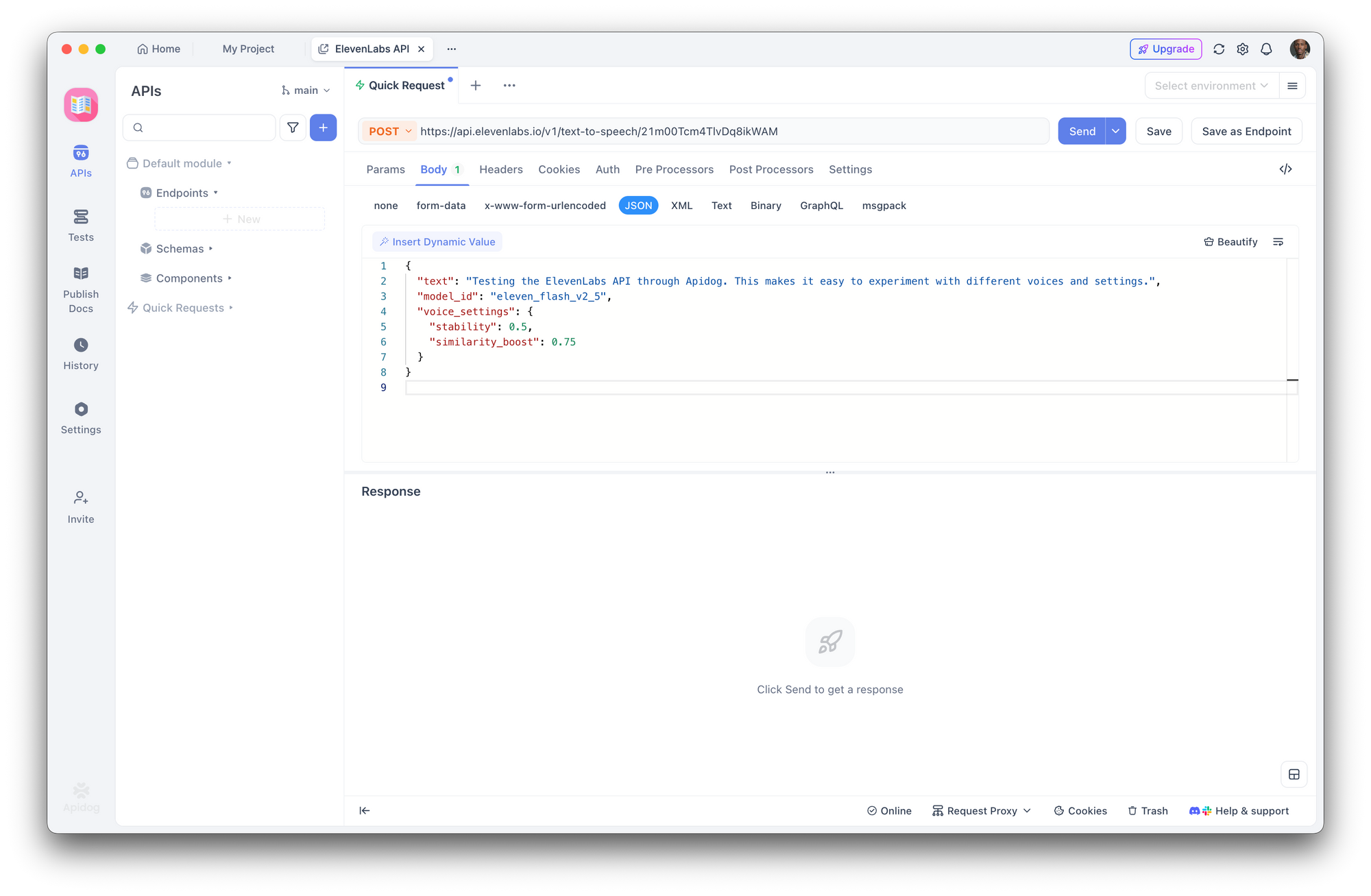
Cliquez sur Envoyer. Apidog affiche les en-têtes de réponse et vous permet de télécharger ou de lire l'audio directement.
Étape 4 : Expérimenter avec les paramètres
Utilisez l'interface d'Apidog pour échanger rapidement les ID de voix, changer de modèle ou ajuster les paramètres vocaux sans modifier le JSON brut. Enregistrez différentes configurations en tant que points d'extrémité distincts dans votre collection pour une comparaison facile.
Étape 5 : Générer du code client
Une fois que vous avez confirmé que la requête fonctionne, cliquez sur Générer du code dans Apidog pour obtenir du code client prêt à l'emploi en Python, JavaScript, cURL, Go, Java et plus encore. Cela élimine la traduction manuelle des documents de l'API en code fonctionnel.
Essayez-le maintenant :Téléchargez Apidog gratuitement
Paramètres vocaux et réglages fins
Les paramètres vocaux vous permettent d'ajuster le son d'une voix. Ces paramètres sont envoyés dans l'objet voice_settings :
| Paramètre | Plage | Défaut | Effet |
|---|---|---|---|
stability | 0.0 - 1.0 | 0.5 | Plus élevé = plus cohérent, moins expressif. Plus bas = plus variable, plus émotionnel. |
similarity_boost | 0.0 - 1.0 | 0.75 | Plus élevé = plus proche de la voix originale. Plus bas = plus de variation. |
style | 0.0 - 1.0 | 0.0 | Plus élevé = style plus exagéré. Augmente la latence. Uniquement pour Multilingual v2. |
use_speaker_boost | booléen | vrai | Augmente la similarité avec l'orateur original. Légère augmentation de la latence. |
Exemples pratiques :
from elevenlabs.client import ElevenLabs
client = ElevenLabs(api_key="votre_clé_api")
# Voix de narration : cohérente, stable
narration = client.text_to_speech.convert(
text="Chapitre Un. C'était un beau jour froid d'avril.",
voice_id="21m00Tcm4TlvDq8ikWAM",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.8,
"similarity_boost": 0.8,
"style": 0.2,
"use_speaker_boost": True,
},
)
# Voix conversationnelle : expressive, naturelle
conversational = client.text_to_speech.convert(
text="Oh wow, c'est en fait une excellente idée ! Laissez-moi réfléchir à la façon dont nous pourrions la concrétiser.",
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
voice_settings={
"stability": 0.3,
"similarity_boost": 0.6,
"style": 0.5,
"use_speaker_boost": True,
},
)
Conseils :
- Pour les livres audio et la narration, utilisez une stabilité plus élevée (0,7-0,9) pour une livraison cohérente
- Pour les chatbots et l'IA conversationnelle, utilisez une stabilité plus faible (0,3-0,5) pour une variation naturelle
- Pour les voix de personnages, expérimentez avec une
similarity_boostplus faible (0,4-0,6) pour créer des personnalités distinctes - Le paramètre
stylene fonctionne qu'avec Multilingual v2 et ajoute de la latence — évitez-le pour les applications en temps réel
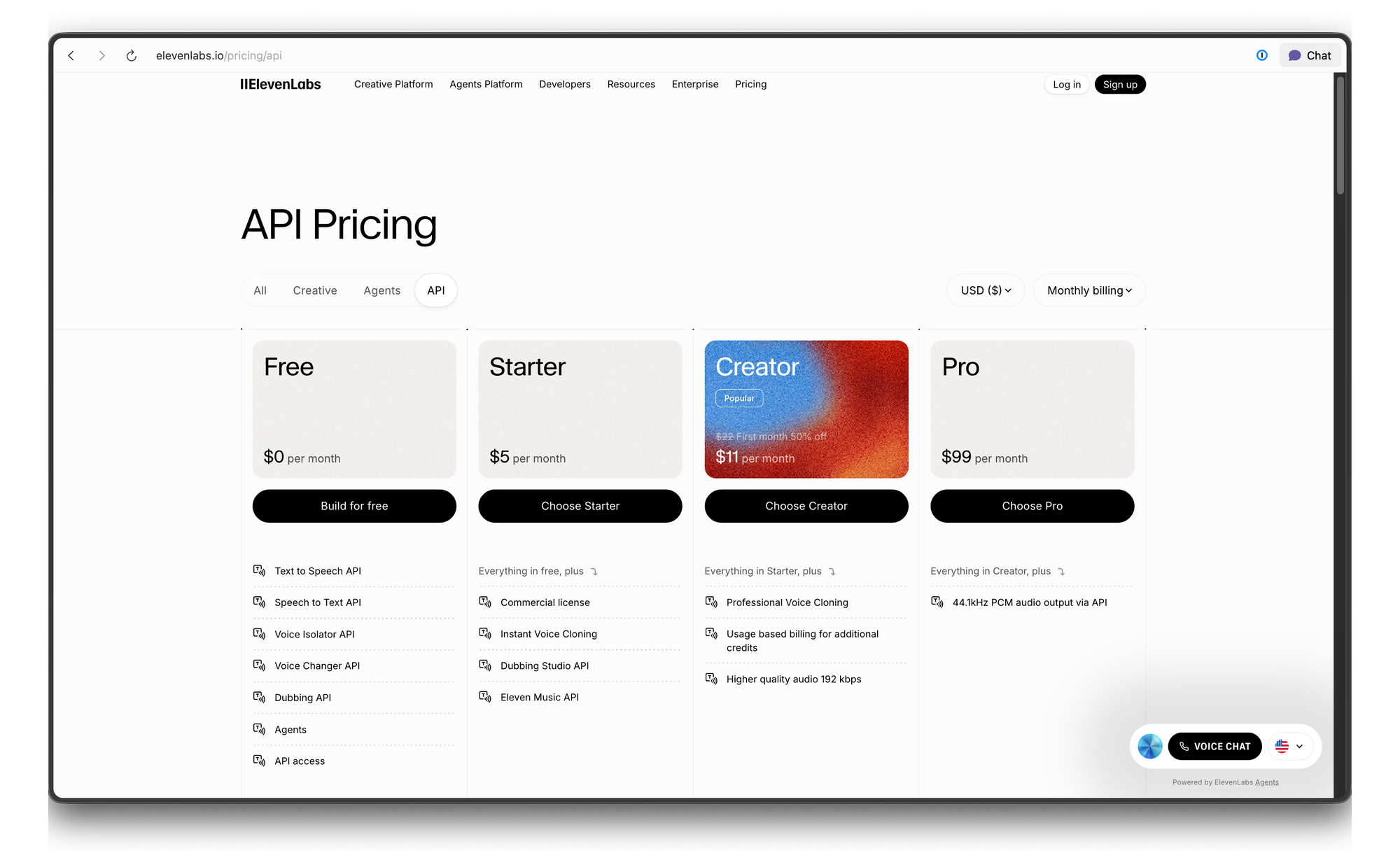
Tarification de l'API ElevenLabs et limites de débit
ElevenLabs utilise un système de tarification basé sur les crédits. Voici la répartition :
Dépannage
| Erreur | Cause | Solution |
|---|---|---|
| 401 Non autorisé | Clé API invalide ou manquante | Vérifiez la valeur de votre en-tête xi-api-key |
| 422 Entité non traitable | Corps de requête invalide | Vérifiez que voice_id existe et que le texte n'est pas vide |
| 429 Trop de requêtes | Limite de débit dépassée | Ajoutez un délai exponentiel ou améliorez votre plan |
| L'audio semble robotique | Mauvais modèle ou paramètres | Essayez Multilingual v2 avec une stabilité de 0,5 |
| Erreurs de prononciation | Problème de normalisation du texte | Épelez les chiffres/abréviations, ou utilisez un formatage similaire à SSML |
Conclusion
L'API ElevenLabs offre aux développeurs l'accès à certaines des synthèses vocales les plus réalistes disponibles aujourd'hui. Que vous ayez besoin de quelques lignes de narration ou d'un pipeline vocal complet en temps réel, l'API s'adapte des simples appels cURL aux flux WebSocket de production.
Prêt à ajouter une voix réaliste à votre application ? Téléchargez Apidog pour tester les points d'extrémité de l'API ElevenLabs, expérimenter les paramètres vocaux et générer du code client — le tout gratuitement, sans carte de crédit requise.