
Los desarrolladores buscan constantemente modelos avanzados de IA para mejorar el razonamiento, la codificación y la resolución de problemas en sus aplicaciones. La API Qwen3-Max-Thinking destaca como una versión preliminar que supera los límites en estas áreas. Esta guía explica cómo los ingenieros acceden e implementan esta API de manera efectiva. Además, destaca herramientas que simplifican el proceso.
Alibaba Cloud impulsa la API Qwen3-Max-Thinking, proporcionando una vista previa temprana de capacidades de pensamiento mejoradas. Lanzado como un punto de control intermedio durante el entrenamiento, este modelo logra un rendimiento notable en puntos de referencia como AIME 2025 y HMMT cuando se combina con el uso de herramientas y computación escalada. Además, los usuarios activan el modo de pensamiento fácilmente a través de parámetros como enable_thinking=True. A medida que avanza el entrenamiento, se esperan características aún más potentes. Este artículo cubre todo, desde el registro hasta el uso avanzado, asegurando que integre la API Qwen3-Max-Thinking sin problemas en sus flujos de trabajo.
Comprendiendo la API Qwen3-Max-Thinking
Los ingenieros reconocen la API Qwen3-Max-Thinking como una evolución de la serie Qwen de Alibaba, diseñada específicamente para tareas de razonamiento superiores. A diferencia de los modelos estándar, esta vista previa incorpora "presupuestos de pensamiento" que permiten a los usuarios controlar la profundidad del razonamiento en áreas como las matemáticas, la codificación y el análisis científico. Alibaba lanzó esta versión para mostrar el progreso, incluso mientras el entrenamiento continúa.

El modelo base Qwen3-Max cuenta con más de un billón de parámetros y un entrenamiento con 36 billones de tokens, duplicando el volumen de datos de su predecesor, Qwen2.5. Admite una ventana de contexto masiva de 262.144 tokens, con una entrada máxima de 258.048 tokens y una salida de 65.536 tokens. Además, maneja más de 100 idiomas, lo que lo hace versátil para aplicaciones globales. Sin embargo, la variante Qwen3-Max-Thinking añade características de agente, reduciendo las alucinaciones y permitiendo procesos de varios pasos a través de la llamada a herramientas de Qwen-Agent.
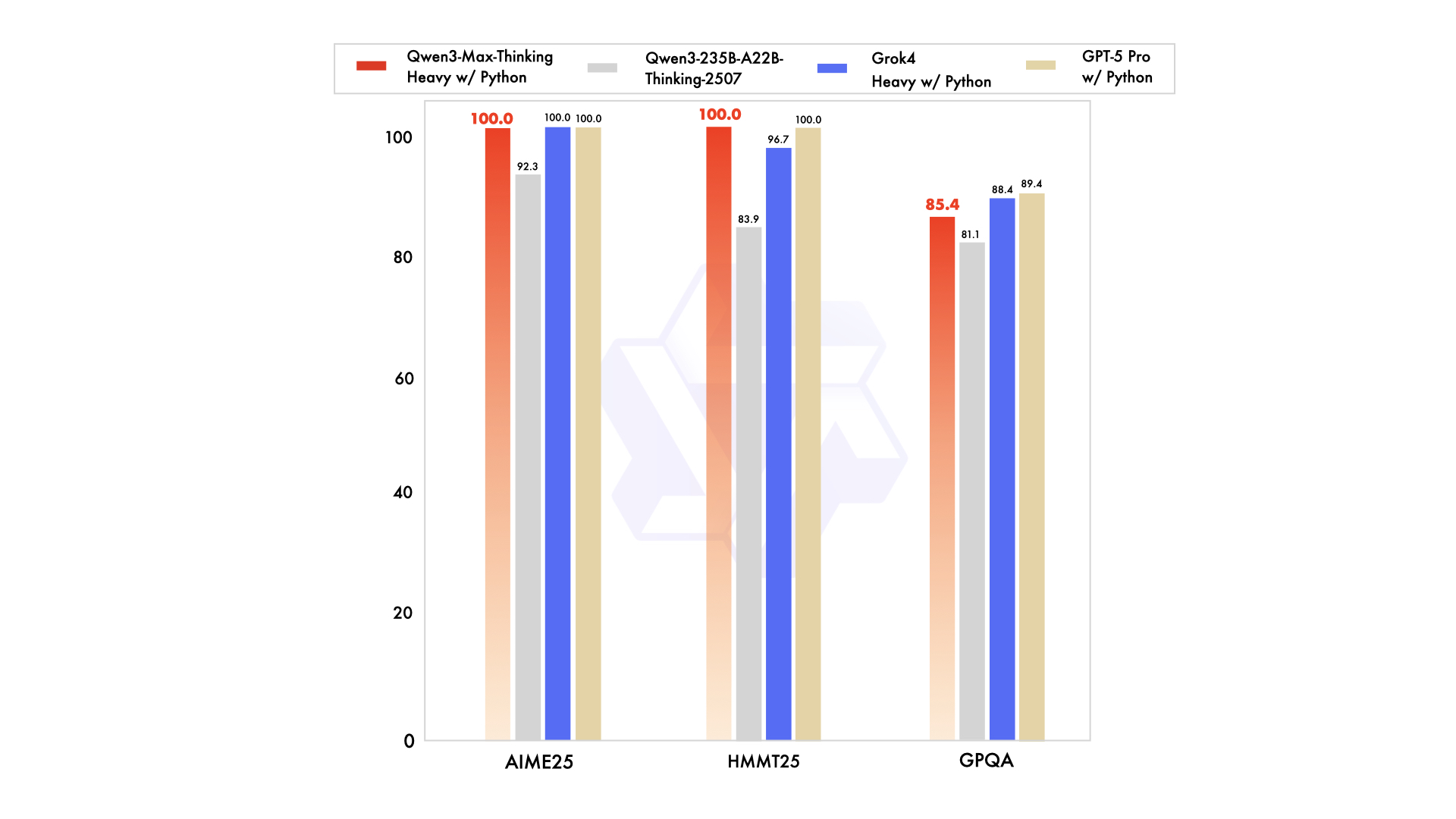
Las métricas de rendimiento subrayan sus puntos fuertes. Por ejemplo, obtiene una puntuación de 74.8 en LiveCodeBench v6 para codificación y 81.6 en AIME25 para matemáticas. Cuando se aumenta, alcanza el 100% en puntos de referencia desafiantes como AIME 2025 y HMMT. Sin embargo, esta vista previa opera inicialmente como un modelo de instrucción sin pensamiento, con mejoras de razonamiento activadas mediante indicadores específicos. Los desarrolladores acceden a ella a través de la API de Alibaba Cloud, que mantiene la compatibilidad con los estándares de OpenAI para una fácil migración.
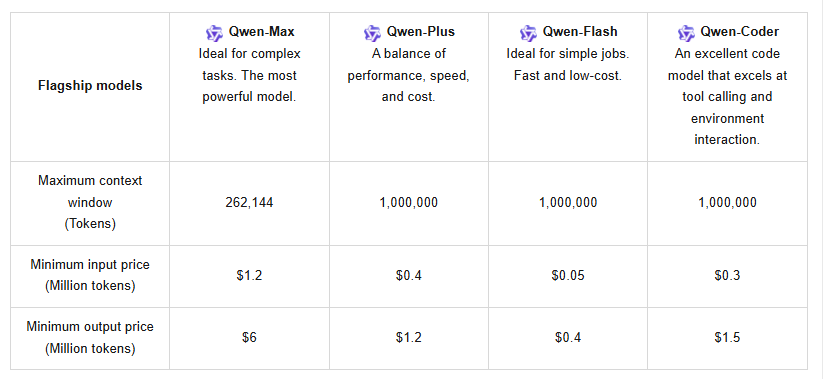
Además, la API admite el almacenamiento en caché de contexto, lo que optimiza las consultas repetidas y reduce los costos. Los precios siguen una estructura escalonada: para 0–32K tokens, la entrada cuesta $1.2 por millón y la salida $6 por millón; para 32K–128K, la entrada sube a $2.4 y la salida a $12; y para 128K–252K, la entrada alcanza $3 con la salida a $15. Los nuevos usuarios se benefician de una cuota gratuita de un millón de tokens, válida por 90 días, lo que fomenta las pruebas iniciales.
En comparación con competidores como Claude Opus 4 o DeepSeek-V3.1, Qwen3-Max-Thinking sobresale en tareas de agente, como SWE-Bench Verified con un 72.5. Sin embargo, su estado de vista previa significa que algunas características, como los presupuestos de pensamiento completos, aún están en desarrollo. Los usuarios pueden probarlo a través de Qwen Chat para sesiones interactivas o la API para acceso programático. Esta configuración posiciona la API Qwen3-Max-Thinking como una herramienta clave para el desarrollo de software, la educación y la automatización empresarial.
Requisitos previos para acceder a la API Qwen3-Max-Thinking
Antes de que los desarrolladores procedan, deben reunir los requisitos esenciales. Primero, cree una cuenta de Alibaba Cloud si no tiene una. Visite el sitio web de Alibaba Cloud y regístrese utilizando una dirección de correo electrónico o un número de teléfono. Verifique la cuenta a través del enlace o código proporcionado para habilitar el acceso completo.
A continuación, asegúrese de estar familiarizado con los conceptos de API, incluidos los puntos finales RESTful y las cargas útiles JSON. La API Qwen3-Max-Thinking utiliza protocolos HTTPS, por lo que las conexiones seguras son importantes. Además, prepare las herramientas de desarrollo: Python 3.x o lenguajes similares con bibliotecas como requests para llamadas HTTP. Para integraciones avanzadas, considere marcos como vLLM o SGLang, que admiten un servicio eficiente en múltiples GPU.
La autenticación requiere una clave API de Alibaba Cloud. Navegue a la consola después de iniciar sesión y genere claves en la sección de administración de API. Almacénelas de forma segura, ya que otorgan acceso a los puntos finales del modelo. Además, cumpla con las políticas de uso: evite llamadas excesivas para evitar la limitación de velocidad. El sistema ofrece las versiones más recientes y de instantánea; seleccione las instantáneas para un rendimiento estable bajo cargas altas.
Las consideraciones de hardware se aplican para las pruebas locales, aunque el acceso a la nube lo mitiga. El modelo exige una computación significativa, pero la infraestructura de Alibaba lo maneja. Finalmente, descargue herramientas de apoyo como Apidog para optimizar las pruebas. Apidog gestiona solicitudes, entornos y colaboraciones, lo que lo hace ideal para experimentar con los parámetros de la API Qwen3-Max-Thinking.
Con estos elementos en su lugar, los ingenieros evitan errores comunes como errores de autenticación o agotamiento de cuotas. Esta preparación garantiza una transición fluida a la implementación real.
Guía paso a paso para obtener y configurar la API Qwen3-Max-Thinking
Los desarrolladores comienzan iniciando sesión en la consola de Alibaba Cloud. Localice la sección ModelStudio, donde residen los modelos Qwen. Busque "qwen3-max-preview" o identificadores similares para encontrar la documentación y la página de activación.
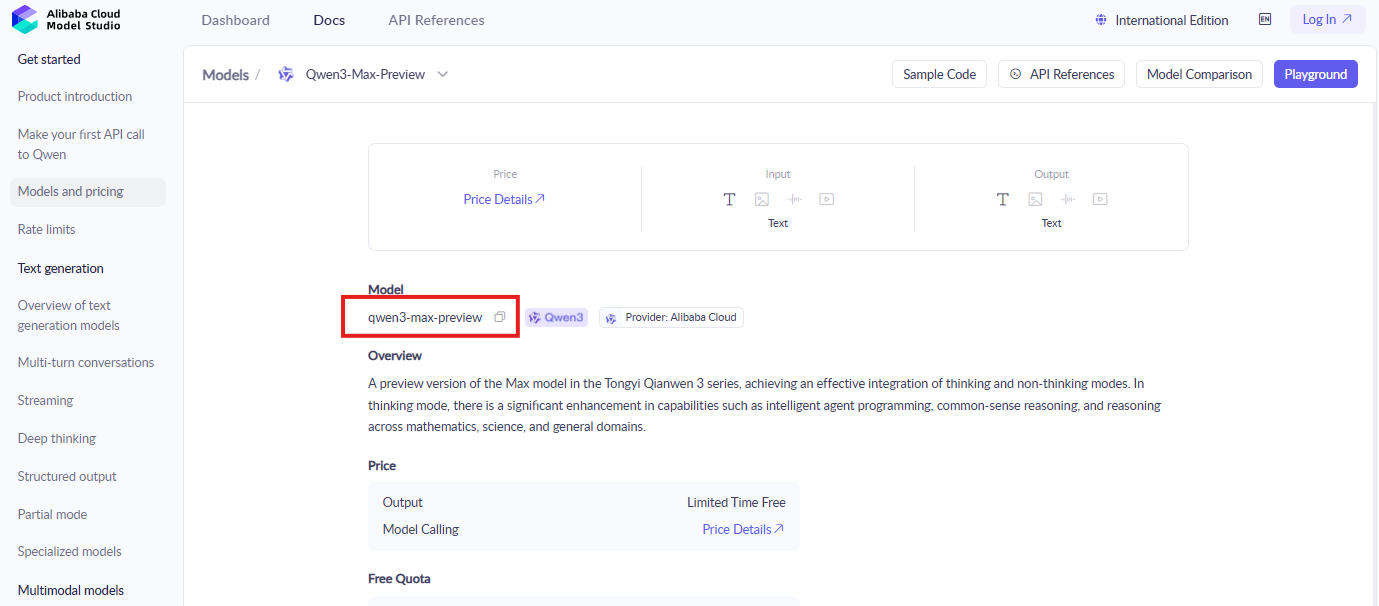
A continuación, active el modelo. Haga clic en el botón de habilitar para Qwen3-Max-Thinking, aceptando los términos si se le solicita. Este paso otorga acceso a las características de vista previa. Además, canjee la cuota de tokens gratuita siguiendo las instrucciones en pantalla; las cuentas nuevas califican automáticamente.
Luego, genere las credenciales de la API. En el área de administración de claves de API, cree un nuevo par de claves. Anote el ID y el secreto de la clave de acceso; estos autentican las solicitudes. Evite compartirlos públicamente para mantener la seguridad.
Configure su entorno de desarrollo después. Instale las bibliotecas necesarias a través de pip, como pip install requests openai. Aunque es compatible con OpenAI, ajuste los puntos finales a la URL base de Alibaba, típicamente algo como "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation".
Pruebe una llamada básica para verificar la configuración. Construya una carga útil JSON con el nombre del modelo "qwen3-max-preview", la instrucción de entrada y el parámetro crucial "enable_thinking": true. Envíe una solicitud POST al punto final. Por ejemplo:
import requests
url = "https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen3-max-preview",
"input": {
"messages": [{"role": "user", "content": "Solve this math problem: What is 2+2?"}]
},
"parameters": {
"enable_thinking": True
}
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
Monitoree la respuesta para ver los pasos de pensamiento en la salida. Si tiene éxito, demuestra un razonamiento activo. Sin embargo, maneje errores como el 401 para claves no válidas verificando las credenciales.
Amplíe a configuraciones avanzadas. Incorpore la llamada a herramientas añadiendo funciones en la carga útil. La API es compatible con Qwen-Agent para flujos de trabajo de agente, lo que permite ejecuciones de varios pasos. Además, utilice el almacenamiento en caché de contexto incluyendo IDs de caché en las solicitudes para reutilizar contextos anteriores de manera eficiente.
Resuelva los problemas rápidamente. Los límites de velocidad activan errores 429; cambie a versiones de instantánea u optimice las consultas. Los problemas de red requieren conexiones estables. Siguiendo estos pasos, los desarrolladores aseguran un acceso fiable a la API Qwen3-Max-Thinking.
Integrando la API Qwen3-Max-Thinking con Apidog
Apidog simplifica las interacciones con la API, y los desarrolladores lo aprovechan para la API Qwen3-Max-Thinking. Comience descargando Apidog desde su sitio oficial; es gratuito y se instala rápidamente en las principales plataformas.
A continuación, importe la especificación de la API. Apidog es compatible con los formatos OpenAPI; descargue la especificación de Alibaba para los modelos Qwen y súbala. Esta acción rellena automáticamente los puntos finales, incluidos los de generación de texto.
Configure los entornos entonces. Cree un nuevo entorno en Apidog, añadiendo variables para las claves API y las URL base. Esta configuración permite cambiar fácilmente entre pruebas y producción.
Pruebe las solicitudes después. Utilice la interfaz de Apidog para construir llamadas POST. Introduzca el modelo, el prompt y el parámetro enable_thinking. Envíe la solicitud e inspeccione las respuestas en tiempo real, con funciones como el resaltado de sintaxis y el registro de errores.
Encadene solicitudes para flujos de trabajo complejos. Apidog permite secuenciar llamadas, ideal para tareas de agente donde una respuesta alimenta otra. Además, simule cargas altas para probar el rendimiento.
Colabore con equipos utilizando las herramientas de intercambio de Apidog. Exporte colecciones para que los colegas repliquen las configuraciones. Además, monitoree el uso de tokens a través de análisis integrados para mantenerse dentro de las cuotas.
Optimice aún más las integraciones. Apidog maneja cargas útiles grandes de manera eficiente, admitiendo la ventana de contexto de 262K. Depure alucinaciones ajustando los presupuestos de pensamiento una vez que estén completamente disponibles.
Explorando puntos finales y parámetros de la API
La API Qwen3-Max-Thinking expone varios puntos finales, principalmente para la generación de texto. El principal, /api/v1/services/aigc/text-generation/generation, maneja las tareas de completado. Los desarrolladores envían datos JSON aquí.
Los parámetros clave incluyen "model", especificando "qwen3-max-preview". El objeto "input" contiene mensajes en formato de chat. Además, "parameters" dictan el comportamiento: establezca "enable_thinking" en True para el modo de razonamiento.
- Otras opciones mejoran el control. "max_tokens" limita la longitud de salida, hasta 65.536. "temperature" ajusta la creatividad, con un valor predeterminado de 0.7. "top_p" refina el muestreo.
- Para el uso de herramientas, incluya la matriz "tools" con definiciones de funciones. La API responde con llamadas, habilitando flujos de agente.
- El almacenamiento en caché de contexto utiliza "cache_prompt" para almacenar y referenciar entradas anteriores, reduciendo costos. Especifique los ID de caché en solicitudes posteriores.
- Los parámetros de manejo de errores como "retry" gestionan transitorios. Además, el versionado a través de "snapshot" garantiza la coherencia.
Comprender esto permite una sintonización precisa. Para problemas matemáticos, un pensamiento más profundo permite pasos detallados; para la codificación, genera soluciones robustas. Los desarrolladores experimentan para encontrar la configuración óptima.
Ejemplos prácticos de uso de la API Qwen3-Max-Thinking
Los ingenieros aplican la API en diversos escenarios. Considere la codificación: Pregunte "Escribe una función de Python para ordenar una lista." Con el pensamiento habilitado, describe la lógica antes del código.
- En matemáticas, consulte "Resuelve la integral de x^2 dx". La respuesta desglosa los pasos, mostrando las reglas de integración.
- Para tareas de agente, defina herramientas como la búsqueda web. El modelo planifica acciones, las ejecuta a través de devoluciones de llamada y sintetiza los resultados.
- Uso empresarial: Analice documentos largos alimentando contextos. La gran ventana procesa los historiales de los usuarios para obtener recomendaciones.
- Educación: Genere explicaciones para temas complejos, adaptando la profundidad a través de parámetros.
- Atención médica: Apoye decisiones éticas con resultados razonados, aunque siempre verifique.
- Escritura creativa: Produzca historias con tramas lógicas.
Estos ejemplos ilustran la versatilidad. Los desarrolladores los escalan utilizando Apidog para las pruebas.
Mejores prácticas para un uso eficiente
Optimice primero el consumo de tokens. Elabore indicaciones concisas para evitar el desperdicio. Utilice el almacenamiento en caché para elementos repetitivos.
Monitoree las cuotas diligentemente. Rastree el uso en la consola; actualice si es necesario.
Proteja las claves con variables de entorno o bóvedas. Rótelas periódicamente.
Maneje los límites de velocidad implementando una retirada exponencial en el código.
Pruebe a fondo con Apidog antes de la producción. Simule casos extremos.
Actualice a nuevas instantáneas a medida que se lancen, revisando los registros de cambios.
Combine con otras herramientas para sistemas híbridos.
Siga estos consejos para maximizar el potencial de la API Qwen3-Max-Thinking.
Conclusión
La API Qwen3-Max-Thinking transforma las aplicaciones de IA con razonamiento avanzado. Siguiendo esta guía, los desarrolladores acceden e integran la API de manera efectiva, aprovechando Apidog para la eficiencia. A medida que las características evolucionan, sigue siendo una opción principal para proyectos innovadores.