Was wäre, wenn Sie den KI-Anbieter wechseln könnten, ohne eine einzige Codezeile neu schreiben zu müssen? Die Venice API bietet genau das: OpenAI-kompatible Endpunkte ohne Datenspeicherung, unzensierte Modelloptionen und eine datenschutzorientierte Architektur, die Sie kontrollieren.
Die meisten KI-APIs zwingen Sie zur Verwendung anbieterspezifischer SDKs, speichern Ihre Daten für das Modelltraining und verlangen Premiumpreise für Basisfunktionen. Sie müssen Ihre Anwendung beim Anbieterwechsel neu schreiben. Ihre Prompts trainieren Konkurrenzmodelle. Ihre Kosten steigen unvorhersehbar.
Die Venice API eliminiert diese Reibungspunkte. Sie spiegelt die API-Struktur von OpenAI exakt wider; ändern Sie die Basis-URL, und Ihr bestehender Code funktioniert sofort. Ihre Daten bleiben privat. Sie wählen aus mehreren Zahlungsmodellen, darunter Krypto-Staking und Pay-as-you-go-USD-Guthaben.
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem wesentlich günstigeren Preis!
Generieren Ihres Venice API-Schlüssels
1. Navigieren Sie zu venice.ai/settings/api.
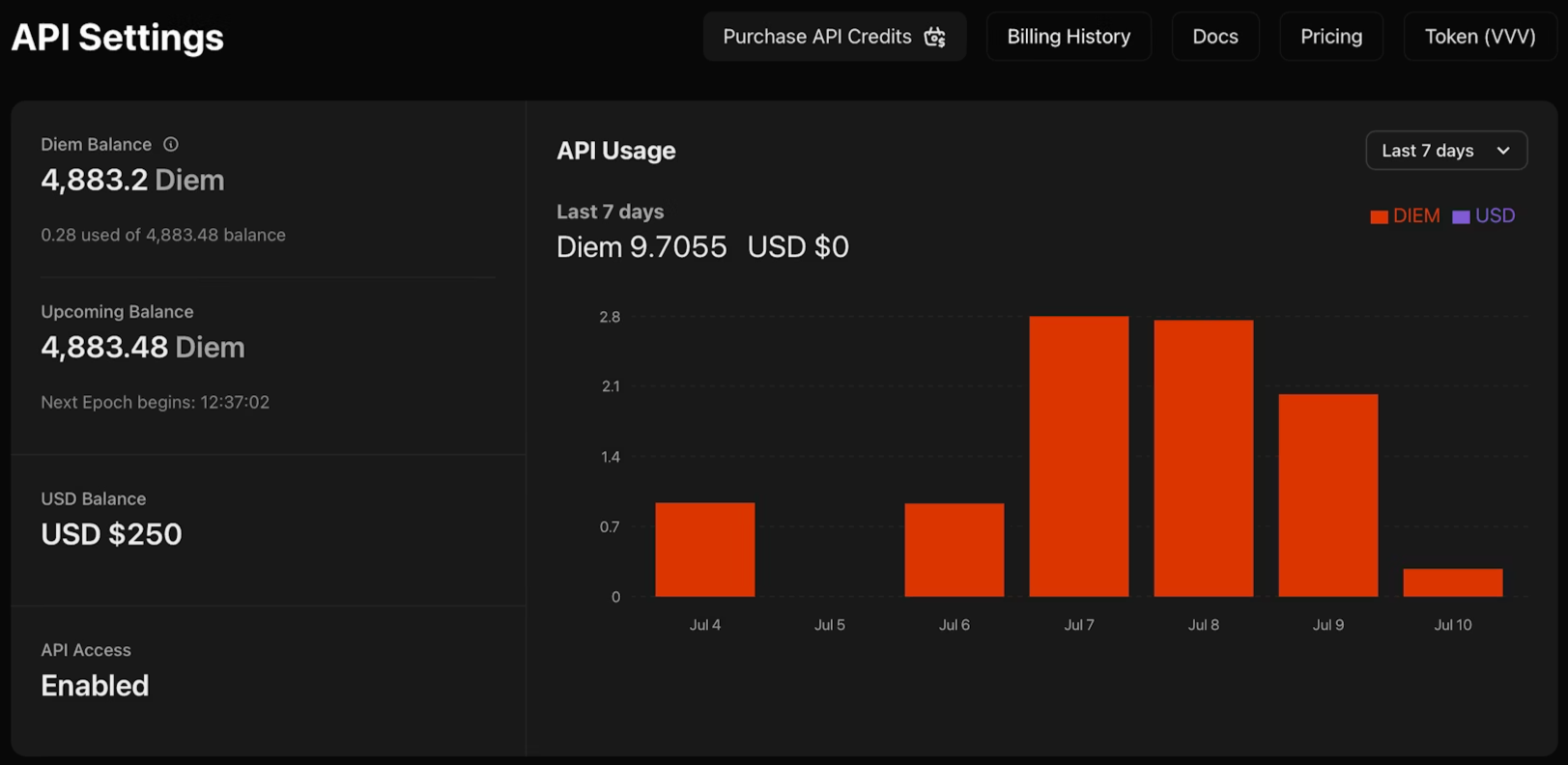
2. Klicken Sie auf „Neuen API-Schlüssel generieren“ und konfigurieren Sie Ihre Anmeldeinformationen:
- Beschreibung: Benennen Sie Ihren Schlüssel zur Organisation
- Typ: Admin-Schlüssel verwalten andere Schlüssel programmatisch; Nur-Inferenz-Schlüssel führen ausschließlich Modelle aus
- Ablaufdatum: Optionales Datum, an dem der Schlüssel automatisch deaktiviert wird
- Verbrauchslimits: Tägliche Diem- oder USD-Obergrenzen zur Kostenkontrolle
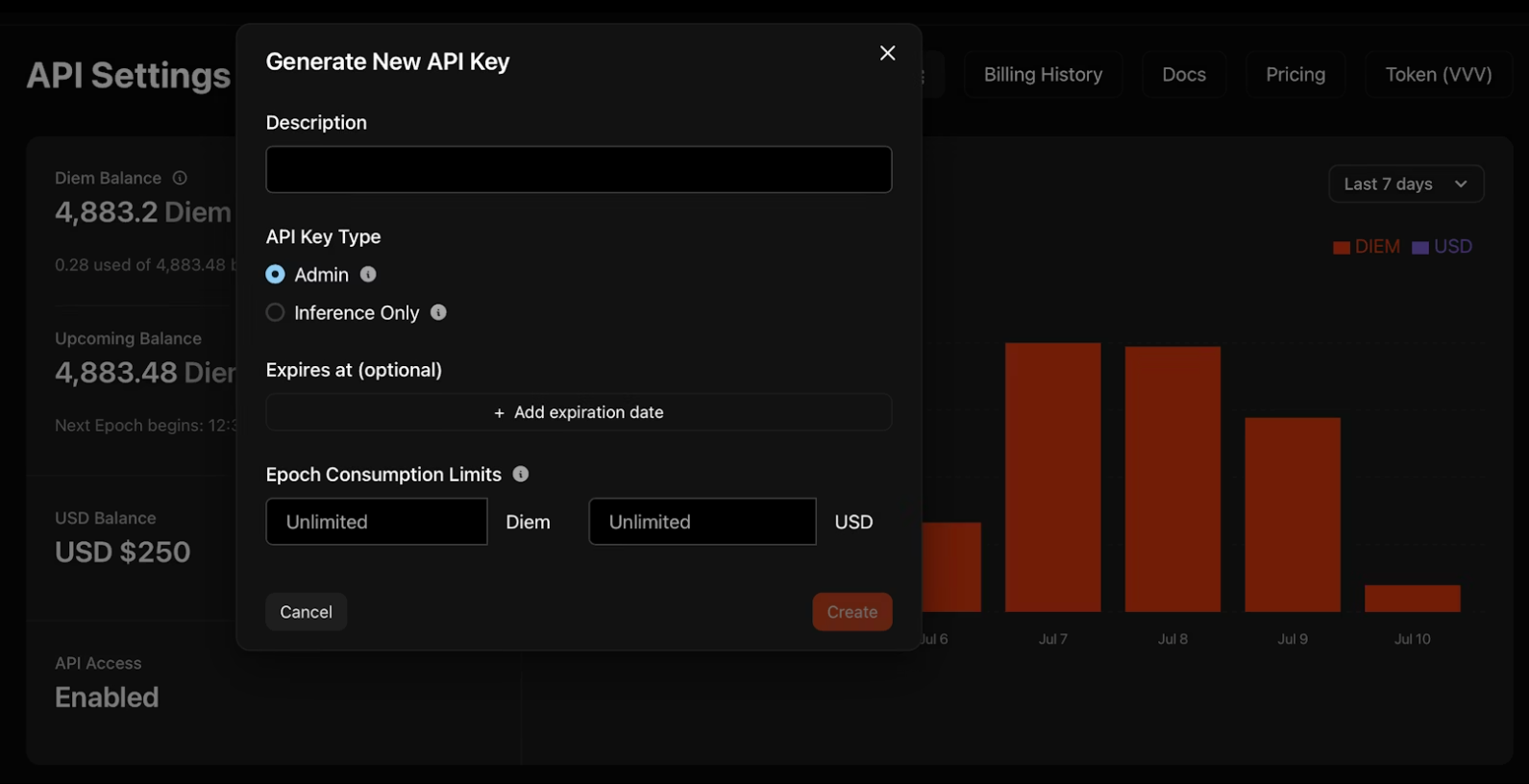
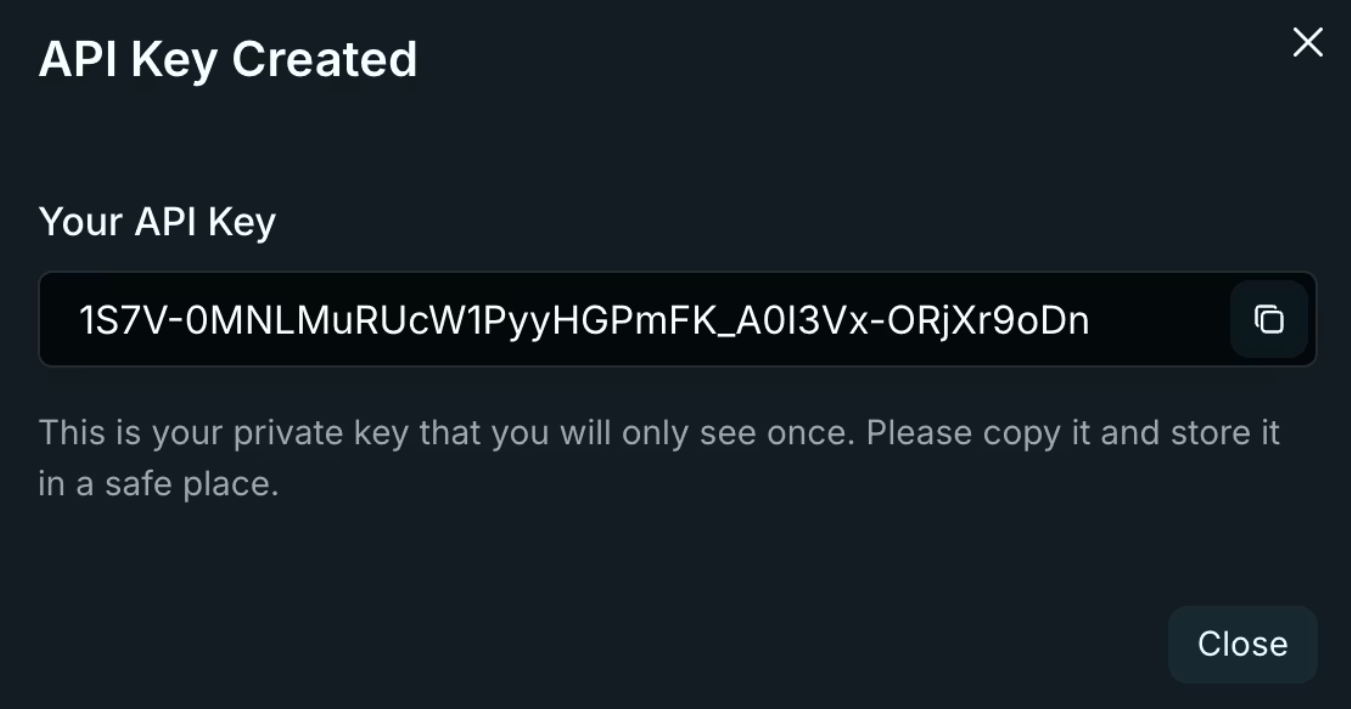
3. Kopieren Sie Ihren Schlüssel sofort. Venice zeigt ihn nur einmal an! Speichern Sie ihn in Umgebungsvariablen, niemals in Code-Repositories.
export VENICE_API_KEY="your-key-here"
Wichtige Sicherheitsaspekte für Schlüssel
Admin-Schlüssel gewähren umfassenden Zugriff auf Ihr Venice-Konto. Behandeln Sie sie wie Root-Anmeldeinformationen – verwenden Sie sie für Schlüsselrotationsskripte und die Teamverwaltung, niemals im Anwendungscode. Nur-Inferenz-Schlüssel beschränken Operationen auf die Modellausführung und begrenzen das Risiko, falls sie offengelegt werden. Rotieren Sie Schlüssel vierteljährlich mithilfe der Aktivitätsprotokolle des Dashboards, um veraltete Anmeldeinformationen zu identifizieren.
Authentifizierung und Basiskonfiguration der Venice API
Venice verwendet die Standard-Bearer-Token-Authentifizierung. Jede Anfrage erfordert zwei Header:
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
Die Basis-URL folgt exakt dem Muster von OpenAI:
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
Diese einzige Konfigurationsänderung leitet alle Ihre bestehenden OpenAI SDK-Aufrufe durch die Infrastruktur von Venice. Keine Methodenänderungen. Keine Parameter-Neuschreibungen. Ihr Code funktioniert sofort.
SDK-Kompatibilität
Venice pflegt die Kompatibilität mit den offiziellen OpenAI-SDKs für Python, TypeScript, Go, PHP, C#, Java und Swift. Auch Drittanbieter-Bibliotheken, die auf der OpenAI-Spezifikation basieren, funktionieren ohne Änderungen. Testen Sie Ihre bestehende Codebasis gegen Venice, indem Sie nur die Basis-URL und den API-Schlüssel ändern – wenn Sie Standard-Chat-Completions, Streaming oder Funktionsaufrufe verwenden, dauert die Migration nur wenige Minuten.
Migration von OpenAI
Die Migration erfordert drei Änderungen: Basis-URL, API-Schlüssel und Modellname. Ersetzen Sie https://api.openai.com/v1 durch https://api.venice.ai/api/v1. Tauschen Sie Ihren OpenAI API-Schlüssel gegen Ihren Venice-Schlüssel aus. Ändern Sie Modellbezeichnungen von gpt-4 oder gpt-3.5-turbo zu Venice-Äquivalenten wie qwen3-4b. Testen Sie gründlich vor dem Produktiv-Deployment. Verifizieren Sie, dass Streaming-Antworten korrekt verarbeitet werden. Bestätigen Sie, dass Funktionsaufruf-Schemas validieren. Überprüfen Sie, ob die Parameter zur Bildgenerierung Ihren Anforderungen entsprechen. Die Kompatibilitätsschicht von Venice handhabt die meisten Randfälle, aber es gibt subtile Unterschiede in der Formatierung von Fehlermeldungen und Rate-Limit-Headern.
Profi-Tipp: Testen Sie alle Ihre API-Endpunkte gründlich mit Apidog.
Wichtige Venice API-Endpunkte und -Funktionen
Venice bietet neun verschiedene Endpunkte für die Text-, Bild-, Audio- und Videogenerierung:
Textgenerierung
/api/v1/chat/completions– Konversationelle KI mit Streaming-Unterstützung/api/v1/embeddings/generate– Vektor-Embeddings für RAG-Anwendungen
Bildverarbeitung
/api/v1/image/generate– Text-zu-Bild-Generierung/api/v1/image/upscale– Auflösungsverbesserung/api/v1/image/edit– KI-gestütztes Inpainting und Modifikation
Audio
/api/v1/audio/speech– Text-zu-Sprache-Synthese/api/v1/audio/transcriptions– Sprach-zu-Text-Konvertierung
Video und Charaktere
/api/v1/video/queue– Text-/Video-zu-Video-Generierung/api/v1/characters/list– KI-Persona-Verwaltung
Jeder Endpunkt verwendet, wo anwendbar, OpenAI-kompatible Anfrage-/Antwortformate. Sie können bestehende Parsing-Logik wiederverwenden.
Strategie zur Endpunktauswahl
Passen Sie die Endpunkte an die Komplexität Ihres Anwendungsfalls an. Chat-Completions decken die meisten Anforderungen an die Textgenerierung ab. Fügen Sie Embeddings für die semantische Suche oder RAG-Pipelines hinzu. Verwenden Sie Bild-Endpunkte für kreative Workflows oder die Inhaltsmoderation. Audio-Endpunkte ermöglichen Barrierefreiheitsfunktionen oder Sprachschnittstellen. Beginnen Sie mit einem Endpunkt, validieren Sie Ihre Integration und erweitern Sie dann auf multimodale Workflows.
Arbeiten mit Streaming-Antworten
Streaming reduziert die wahrgenommene Latenz bei Chat-Anwendungen. Venice verwendet Server-Sent Events (SSE), die identisch mit der Implementierung von OpenAI sind. Verarbeiten Sie Teilergebnisse, sobald sie eintreffen, anstatt auf vollständige Antworten zu warten. Behandeln Sie die Stream-Beendigung, indem Sie auf [DONE]-Nachrichten prüfen. Implementieren Sie eine Wiederverbindungslogik für unterbrochene Streams – speichern Sie den Konversationsverlauf clientseitig und versuchen Sie fehlgeschlagene Anfragen erneut. Überwachen Sie die Token-Nutzung in Stream-Chunks, um die Kosten in Echtzeit zu verfolgen.
Venice API-spezifische Parameter
Über die Standardparameter von OpenAI hinaus fügt Venice Funktionen zur Steuerung über das Objekt venice_parameters hinzu:
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Latest AI developments?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
Websuche-Integration
Setzen Sie enable_web_search auf auto, on oder off. Bei „auto“ entscheidet das Modell, wann aktuelle Informationen die Antworten verbessern. Erzwingen Sie es für Echtzeitabfragen zu aktuellen Ereignissen oder sich schnell ändernden Technologien. Kombinieren Sie es mit enable_web_citations, um Quell-URLs zurückzugeben – unerlässlich für Recherchetools und Faktenprüfung.
Steuerung der Argumentation
Argumentationsmodelle wie DeepSeek R1 zeigen standardmäßig ein schrittweises Denken. Setzen Sie strip_thinking_response auf true, um nur die endgültigen Antworten zurückzugeben und den Token-Verbrauch zu reduzieren. Verwenden Sie disable_thinking, um die Argumentation für einfache Abfragen vollständig zu umgehen.
Alternative Syntax
Übergeben Sie Parameter über das Modell-Suffix für prägnante Anfragen:
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
Parameterhierarchie
Venice-spezifische Parameter überschreiben Standardwerte, berücksichtigen aber explizite Einstellungen. Wenn Sie temperature: 0.5 im Stammobjekt und enable_web_search: on in venice_parameters angeben, werden beide gleichzeitig angewendet. Testen Sie Parameterkombinationen isoliert, bevor Sie sie in der Produktion einsetzen – einige Parameter interagieren mit bestimmten Modellen unvorhersehbar.
Praktische Implementierungsbeispiele bei der Nutzung der Venice API
Grundlegende Chat-Vervollständigung
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explain zero-knowledge proofs"}],
"stream": true
}'
Streaming funktioniert identisch zu OpenAI – verarbeiten Sie SSE-Chunks, sobald sie eintreffen.
Funktionsaufruf
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Venice-Modelle unterstützen parallele Funktionsaufrufe und Schema-Erzwingung wie die Implementierung von OpenAI.
Bildgenerierung
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Cyberpunk cityscape at night, neon reflections",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
Verfügbare Seitenverhältnisse sind 1:1, 4:3, 16:9 und 21:9. Auflösungsoptionen sind 1K und 2K.
Bild-Upscaling
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
Bildanalyse
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What architecture style is this?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
Bilder können als Base64-Daten-URIs oder HTTPS-URLs übergeben werden. Visionsmodelle akzeptieren mehrere Bilder pro Nachricht für Vergleichsaufgaben.
Audio-Synthese
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Welcome to Venice API",
"voice": "af_sky",
"response_format": "mp3"
}'
Sprachoptionen verwenden Präfixe: af_ (amerikanische weibliche Stimme), am_ (amerikanischer männliche Stimme) und ähnliche Muster für andere Akzente.
Muster der Fehlerbehandlung
Venice gibt Standard-HTTP-Statuscodes zurück. 401 deutet auf Authentifizierungsfehler hin – überprüfen Sie Ihren API-Schlüssel und Ihre Header. 429 signalisiert Ratenbegrenzung; implementieren Sie einen exponentiellen Backoff, beginnend bei 1 Sekunde. 500er-Fehler deuten auf temporäre Infrastrukturprobleme hin; versuchen Sie es nach 5 Sekunden erneut. Parsen Sie Fehlerantworten auf spezifische Nachrichten – Venice enthält detaillierte Fehlerursachen im Antworttext.
Datenschutz und Datenarchitektur der Venice API
Die Null-Daten-Speicherrichtlinie von Venice basiert auf der technischen Architektur, nicht nur auf rechtlichen Versprechen. Ihr Browser speichert den Konversationsverlauf lokal mithilfe von IndexedDB. Venice-Server verarbeiten Prompts auf GPUs, die nur die aktuelle Anfrage sehen – keinen Konversationsverlauf, keine Metadaten zur Benutzeridentität, keine API-Schlüsselinformationen.
Nachdem eine Antwort generiert wurde, verwerfen die Server den Prompt und die Ausgabe sofort. Nichts wird auf der Festplatte oder in Protokollen gespeichert. Ihre Daten trainieren niemals Modelle. Dies unterscheidet sich grundlegend von zentralisierten Diensten, die Daten zur Missbrauchserkennung und Modellverbesserung speichern.
Für zusätzliche Privatsphäre hostet Venice die meisten Modelle auf privater Infrastruktur, anstatt sich auf Drittanbieter zu verlassen. Unzensierte Optionen laufen auf von Venice kontrollierter Hardware, wodurch keine externe Filterung oder Protokollierung gewährleistet ist.
Verifizierung des Datenflusses
Überprüfen Sie die Datenschutzansprüche von Venice, indem Sie den Netzwerkverkehr überwachen. API-Anfragen gehen direkt an api.venice.ai mit TLS-Verschlüsselung. Es werden keine Analyse-Skripte von Drittanbietern in der Dokumentation geladen. Antwort-Header zeigen keine Caching-Direktiven – was die serverseitige Nichtspeicherung bestätigt. Für sensible Anwendungen implementieren Sie eine clientseitige Verschlüsselung, bevor Sie Prompts senden, obwohl dies das Modell daran hindert, den Inhalt zu verstehen.
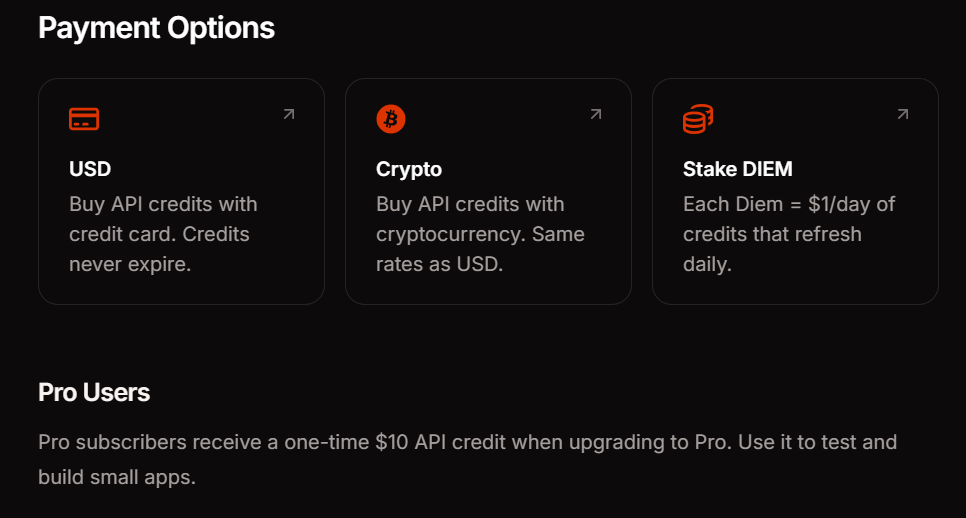
Preise und Zahlungsoptionen der Venice API
Venice bietet drei Zahlungsmethoden, die Ihren Nutzungsmustern entsprechen. Das Pro-Abonnement kostet 18 US-Dollar monatlich und beinhaltet 10 US-Dollar API-Guthaben sowie unbegrenzte Prompts für Consumer-Funktionen. DIEM-Staking erfordert den Kauf von VVV-Token, die dauerhafte tägliche Rechenleistung zuweisen – ideal für Anwendungen mit hohem Volumen und vorhersehbarem Traffic. USD Pay-as-you-go ermöglicht es Ihnen, Ihr Konto mit US-Dollar aufzuladen und Credits nach Bedarf zu verbrauchen, perfekt für Experimente und variable Arbeitslasten.
Der API-Zugriff bleibt während der Beta-Phase derzeit kostenlos. Dies ermöglicht Ihnen, Integrationsmuster zu validieren und Kosten abzuschätzen, bevor Sie sich für eine Zahlungsmethode entscheiden. Überwachen Sie Ihr Nutzungs-Dashboard, um den Token-Verbrauch über Endpunkte und Modelle hinweg zu verfolgen.
Richtlinien zur Modellauswahl
Wählen Sie Modelle basierend auf den Leistungsanforderungen und Latenzbeschränkungen aus. Beginnen Sie mit qwen3-4b für Prototyping und einfache Abfragen – es reagiert schnell und bewältigt die meisten Textgenerierungsaufgaben adäquat. Wechseln Sie zu größeren Modellen wie llama-3.3-70b oder deepseek-ai-DeepSeek-R1, wenn Sie fortgeschrittene Argumentation, Codegenerierung oder komplexe Anweisungsbefolgung benötigen. Bildverarbeitungsaufgaben erfordern multimodale Modelle wie qwen3-vl-235b-a22b. Audio-Generierung verwendet spezialisierte Sprachmodelle. Fragen Sie den Endpunkt /api/v1/models programmatisch ab, um die Echtzeitverfügbarkeit zu prüfen – Venice rotiert Modelle basierend auf Nachfrage und Infrastrukturkapazität.
Fazit
Die Venice API beseitigt Reibungspunkte bei der KI-Integration. Sie erhalten OpenAI-Kompatibilität ohne Anbieterbindung, Datenschutz ohne Konfigurationskomplexität und flexible Preise ohne unerwartete Rechnungen. Der Drop-in-Ersatzansatz bedeutet, dass Sie Venice neben Ihrem aktuellen Anbieter evaluieren können, ohne Anwendungscode neu schreiben zu müssen.
Beim Erstellen von API-Integrationen – sei es beim Testen von Venice-Endpunkten, beim Debuggen von Authentifizierungsabläufen oder beim Verwalten mehrerer Anbieterkonfigurationen – verwenden Sie Apidog, um Ihren Workflow zu optimieren. Es übernimmt visuelles API-Testing, Dokumentationsgenerierung und Teamzusammenarbeit, sodass Sie sich auf die Bereitstellung von Funktionen konzentrieren können.