Künstliche Intelligenz entwickelt sich weiterhin rasant weiter, und Entwickler fordern nun Tools, die fortschrittliche Denkfähigkeiten bieten. NVIDIA erfüllt diesen Bedarf mit der NVIDIA Llama Nemotron-Modellfamilie. Diese Modelle zeichnen sich bei Aufgaben aus, die komplexes Denken erfordern, bieten Recheneffizienz und verfügen über eine offene Lizenz für den Unternehmenseinsatz. Entwickler können über die NVIDIA Llama Nemotron API auf diese Modelle zugreifen, die über die NIM-Microservices von NVIDIA bereitgestellt wird, wodurch die Integration in Anwendungen nahtlos erfolgt.
Die NVIDIA Llama Nemotron-Modelle verstehen
Bevor wir uns mit der API befassen, wollen wir uns die NVIDIA Llama Nemotron-Modelle ansehen. Diese Familie umfasst drei Varianten: Nano, Super und Ultra. Jede zielt auf spezifische Bereitstellungsanforderungen ab und gleicht Leistung und Ressourcenanforderungen aus.
- Nano (8B parameters): Ingenieure optimieren dieses Modell für Edge-Geräte und PCs. Es liefert hohe Genauigkeit bei minimaler Rechenleistung und ist damit ideal für leichte Anwendungen.
- Super (49B parameters): Entwickler entwerfen dieses Modell für Single-GPU-Setups. Es bietet ein Gleichgewicht zwischen Durchsatz und Genauigkeit und eignet sich für mäßig komplexe Aufgaben.
- Ultra (253B parameters): Experten erstellen dieses Modell für Multi-GPU-Rechenzentrumsserver. Es bietet höchste Genauigkeit für die anspruchsvollsten KI-Agenten-Anwendungen.
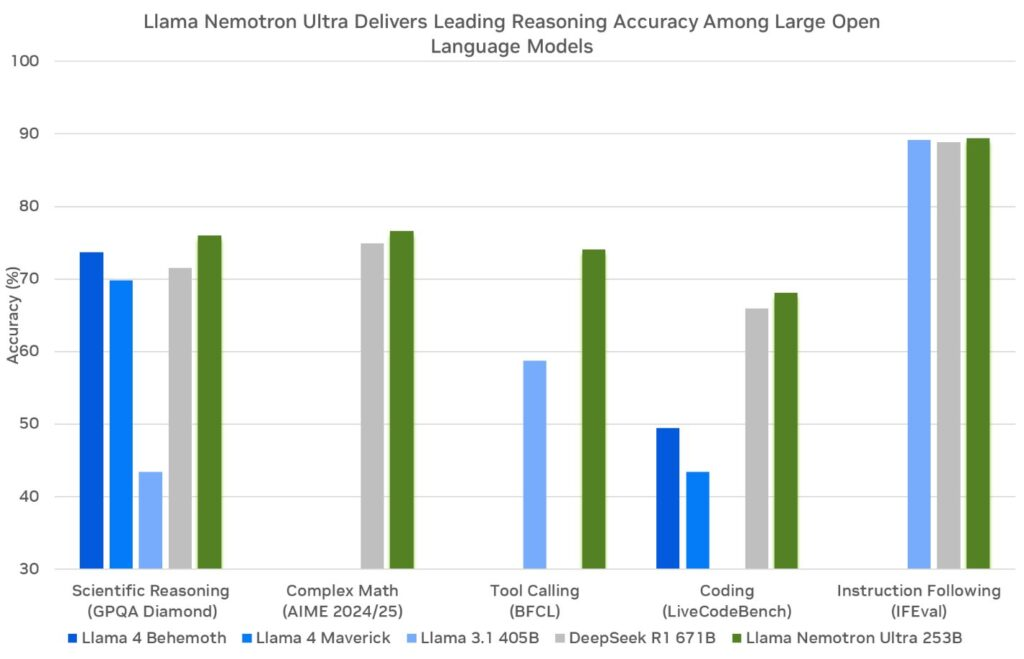
NVIDIA baut diese Modelle auf dem Llama-Framework von Meta auf und verbessert sie mit Techniken nach dem Training wie Distillation und Reinforcement Learning. Folglich zeichnen sie sich bei Denkaufgaben wie wissenschaftlicher Analyse, fortgeschrittener Mathematik, Programmierung und Befolgen von Anweisungen aus. Jedes Modell unterstützt eine Kontextlänge von 128.000 Tokens, sodass sie lange Dokumente verarbeiten oder den Kontext in erweiterten Interaktionen beibehalten können.
Ein herausragendes Merkmal ist die Möglichkeit, das Denken über den System-Prompt ein- oder auszuschalten. Entwickler aktivieren das Denken für komplexe Abfragen, wie z. B. die Fehlerbehebung, und deaktivieren es für einfache Aufgaben, wie z. B. das Abrufen statischer Informationen. Diese Flexibilität optimiert die Ressourcenauslastung, ein entscheidender Vorteil in realen Anwendungen.
Einrichten der NVIDIA Llama Nemotron API
Um die NVIDIA Llama Nemotron API zu nutzen, müssen Sie sie zuerst einrichten. NVIDIA liefert diese API über seine NIM-Microservices, die die Bereitstellung in Cloud-, On-Premises- oder Edge-Umgebungen unterstützen. Führen Sie die folgenden Schritte aus, um zu beginnen:
Dem NVIDIA Developer Program beitreten: Registrieren Sie sich, um auf Ressourcen, Dokumentation und Tools zuzugreifen. Dieser Schritt schaltet das Ökosystem frei, das Sie benötigen.
API-Anmeldeinformationen abrufen: NVIDIA stellt API-Schlüssel bereit. Verwenden Sie diese, um Ihre Anfragen sicher zu authentifizieren.
Erforderliche Bibliotheken installieren: Installieren Sie für Python-Entwickler die requests-Bibliothek, um HTTP-Aufrufe zu verarbeiten. Führen Sie diesen Befehl in Ihrem Terminal aus:
pip install requests
Nachdem Sie diese Schritte ausgeführt haben, bereiten Sie Ihre Umgebung vor, um mit der NVIDIA Llama Nemotron API zu interagieren. Als Nächstes werden wir untersuchen, wie man Anfragen stellt.
API-Anfragen stellen
Die NVIDIA Llama Nemotron API hält sich an RESTful-Standards und vereinfacht so die Integration in Ihre Projekte. Sie senden POST-Anfragen an den API-Endpunkt und betten Parameter in den Anfragetext ein. Lassen Sie uns dies anhand eines praktischen Beispiels aufschlüsseln.
So fragen Sie die API mit Python ab:
import requests
import json
# Definieren Sie den API-Endpunkt und die Authentifizierung
endpoint = "https://your-nim-endpoint.com/api/v1/generate"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Erstellen Sie die Anforderungsnutzlast
payload = {
"model": "llama-nemotron-super",
"prompt": "How many R's are in the word 'strawberry'?",
"max_tokens": 100,
"temperature": 0.7,
"reasoning": "on"
}
# Senden Sie die Anfrage
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Verarbeiten Sie die Antwort
if response.status_code == 200:
result = response.json()
print(result["text"])
else:
print(f"Error: {response.status_code} - {response.text}")
Wichtige Parameter erklärt
model: Gibt die Modellvariante an – Nano, Super oder Ultra. Wählen Sie basierend auf Ihrer Bereitstellung aus.prompt: Stellt den Eingabetext für das zu verarbeitende Modell bereit.max_tokens: Begrenzt die Antwortlänge in Tokens. Passen Sie dies an, um die Ausgabegröße zu steuern.temperature: Reicht von 0 bis 1. Niedrigere Werte (z. B. 0,5) liefern vorhersagbare Ausgaben, während höhere Werte (z. B. 0,9) die Kreativität erhöhen.reasoning: Schaltet Denkfähigkeiten ein und aus. Stellen Sie es auf "on" für komplexe Aufgaben und auf "off" für einfache Aufgaben.
Beispielsweise eignet sich die Aktivierung des Denkens für Aufgaben wie das Lösen von mathematischen Problemen, während die Deaktivierung für einfache Nachschlagevorgänge funktioniert. Sie können auch Parameter wie top_p zur Diversitätskontrolle oder stop_sequences hinzufügen, um die Generierung bei bestimmten Tokens anzuhalten, z. B. "\n\n".
Hier ist ein erweitertes Beispiel:
payload = {
"model": "llama-nemotron-super",
"prompt": "Explain recursion in programming.",
"max_tokens": 200,
"temperature": 0.6,
"top_p": 0.9,
"reasoning": "on",
"stop_sequences": ["\n\n"]
}
Diese Anfrage generiert eine detaillierte Erklärung der Rekursion und stoppt bei einem doppelten Zeilenumbruch. Tools wie Apidog helfen Ihnen, diese Anfragen effizient zu testen und zu verfeinern.
API-Antworten verarbeiten
Nach dem Senden einer Anfrage gibt die NVIDIA Llama Nemotron API eine JSON-Antwort zurück. Diese enthält den generierten Text und Metadaten. Hier ist eine Beispielantwort:
{
"text": "There are three R's in the word 'strawberry'.",
"tokens_generated": 10,
"time_taken": 0.5
}
text: Enthält die Ausgabe des Modells.tokens_generated: Gibt die Anzahl der erzeugten Tokens an.time_taken: Misst die Generierungszeit in Sekunden.
Überprüfen Sie immer den Statuscode. Ein Code von 200 signalisiert Erfolg, sodass Sie das JSON parsen können. Fehler geben Codes wie 400 oder 500 zurück, mit Details im Antworttext zur Fehlerbehebung. Implementieren Sie Fehlerbehandlung, z. B. Wiederholungen oder Fallbacks, um die Robustheit in der Produktion sicherzustellen.
Erweitern Sie beispielsweise den vorherigen Code:
if response.status_code == 200:
result = response.json()
print(f"Response: {result['text']}")
print(f"Tokens used: {result['tokens_generated']}")
else:
print(f"Failed: {response.text}")
# Fügen Sie hier bei Bedarf eine Wiederholungslogik hinzu
Dieser Ansatz hält Ihre Anwendung unter unterschiedlichen Bedingungen zuverlässig.
Best Practices und Anwendungsfälle
Um das Potenzial der NVIDIA Llama Nemotron API zu maximieren, sollten Sie diese Best Practices anwenden:
- Ressourcenauslastung optimieren: Aktivieren Sie das Denken nur für komplexe Aufgaben. Dies reduziert die Rechenkosten erheblich.
- Leistung überwachen: Verfolgen Sie
time_taken, um zeitnahe Antworten sicherzustellen, insbesondere für Echtzeitanwendungen. - Parameter optimieren: Experimentieren Sie mit
temperatureundmax_tokens, um Kreativität und Präzision in Einklang zu bringen. - Anmeldeinformationen sichern: Speichern Sie API-Schlüssel in Umgebungsvariablen oder sicheren Tresoren, niemals im Code.
- Batch-Anfragen: Verarbeiten Sie mehrere Prompts in einem Aufruf, um die Effizienz zu steigern.
Praktische Anwendungsfälle
Die Vielseitigkeit der API unterstützt verschiedene Anwendungen:
- Kundensupport: Entwickeln Sie Chatbots, die komplizierte Anfragen mit Denken lösen, z. B. die Fehlerbehebung bei Hardwareproblemen.
- Bildung: Erstellen Sie Tutoren, die Konzepte wie Analysis mit Schritt-für-Schritt-Logik erklären.
- Forschung: Unterstützen Sie Wissenschaftler bei der Analyse von Daten oder der Erstellung von Hypothesen.
- Softwareentwicklung: Generieren Sie Code oder debuggen Sie Skripte basierend auf Eingaben in natürlicher Sprache.
Für ein Programmierbeispiel:
payload = {
"model": "llama-nemotron-super",
"prompt": "Write a Python function to calculate a factorial.",
"max_tokens": 200,
"temperature": 0.5,
"reasoning": "on"
}
Das Modell könnte Folgendes zurückgeben:
def factorial(n):
if n == 0 or n == 1:
return 1
return n * factorial(n - 1)
Dies zeigt seine Fähigkeit, durch rekursive Logik zu denken. Apidog kann bei der Prüfung solcher API-Aufrufe helfen und die Genauigkeit sicherstellen.
Fazit
Die NVIDIA Llama Nemotron API ermöglicht es Entwicklern, fortschrittliche KI-Agenten mit robusten Denkfähigkeiten zu erstellen. Seine umschaltbare Denkfunktion optimiert die Leistung, während seine Skalierbarkeit über die Modelle Nano, Super und Ultra für unterschiedliche Anforderungen geeignet ist. Egal, ob Sie Chatbots, Bildungstools oder Coding-Assistenten erstellen, diese API bietet Flexibilität und Leistung.
Darüber hinaus verbessert die Integration mit Tools wie Apidog Ihren Workflow. Testen Sie Endpunkte, validieren Sie Antworten und iterieren Sie schnell, um sich auf Innovation zu konzentrieren. Wenn die KI Fortschritte macht, positioniert Sie die Beherrschung der NVIDIA Llama Nemotron API an der Spitze dieses transformativen Bereichs.