
Die Dokumentenverarbeitung ist seit langem eine der praktischsten Anwendungen der KI – doch die meisten OCR-Lösungen erzwingen einen unangenehmen Kompromiss zwischen Genauigkeit und Effizienz. Traditionelle Systeme wie Tesseract erfordern eine aufwendige Vorverarbeitung. Cloud-APIs berechnen pro Seite und verursachen Latenzzeiten. Selbst moderne Vision-Language-Modelle haben mit der Token-Explosion zu kämpfen, die bei hochauflösenden Dokumentbildern entsteht.
DeepSeek-OCR 2 ändert diese Gleichung grundlegend. Aufbauend auf dem Ansatz der „Contexts Optical Compression“ aus Version 1, führt die neue Version den „Visual Causal Flow“ ein – eine Architektur, die Dokumente so verarbeitet, wie Menschen sie tatsächlich lesen, visuelle Beziehungen und Kontext versteht, anstatt nur Zeichen zu erkennen. Das Ergebnis ist ein Modell, das eine Genauigkeit von 97 % erreicht, während es Bilder auf nur 64 Tokens komprimiert und einen Durchsatz von über 200.000 Seiten pro Tag auf einer einzigen GPU ermöglicht.
Dieser Leitfaden behandelt alles von der grundlegenden Einrichtung bis zur Produktivbereitstellung – mit funktionierendem Code, den Sie sofort kopieren, einfügen und ausführen können.
Was ist DeepSeek-OCR 2?
DeepSeek-OCR 2 ist ein Open-Source-Vision-Language-Modell, das speziell für das Dokumentenverständnis und die Textextraktion entwickelt wurde. DeepSeek AI hat es im Januar 2026 veröffentlicht. Es baut auf dem ursprünglichen DeepSeek-OCR auf und verfügt über eine neue „Visual Causal Flow“-Architektur, die modelliert, wie visuelle Elemente in Dokumenten kausal miteinander in Beziehung stehen – zum Beispiel, dass eine Tabellenüberschrift bestimmt, wie die Zellen darunter interpretiert werden sollen, oder dass eine Bildunterschrift die Grafik darüber erklärt.
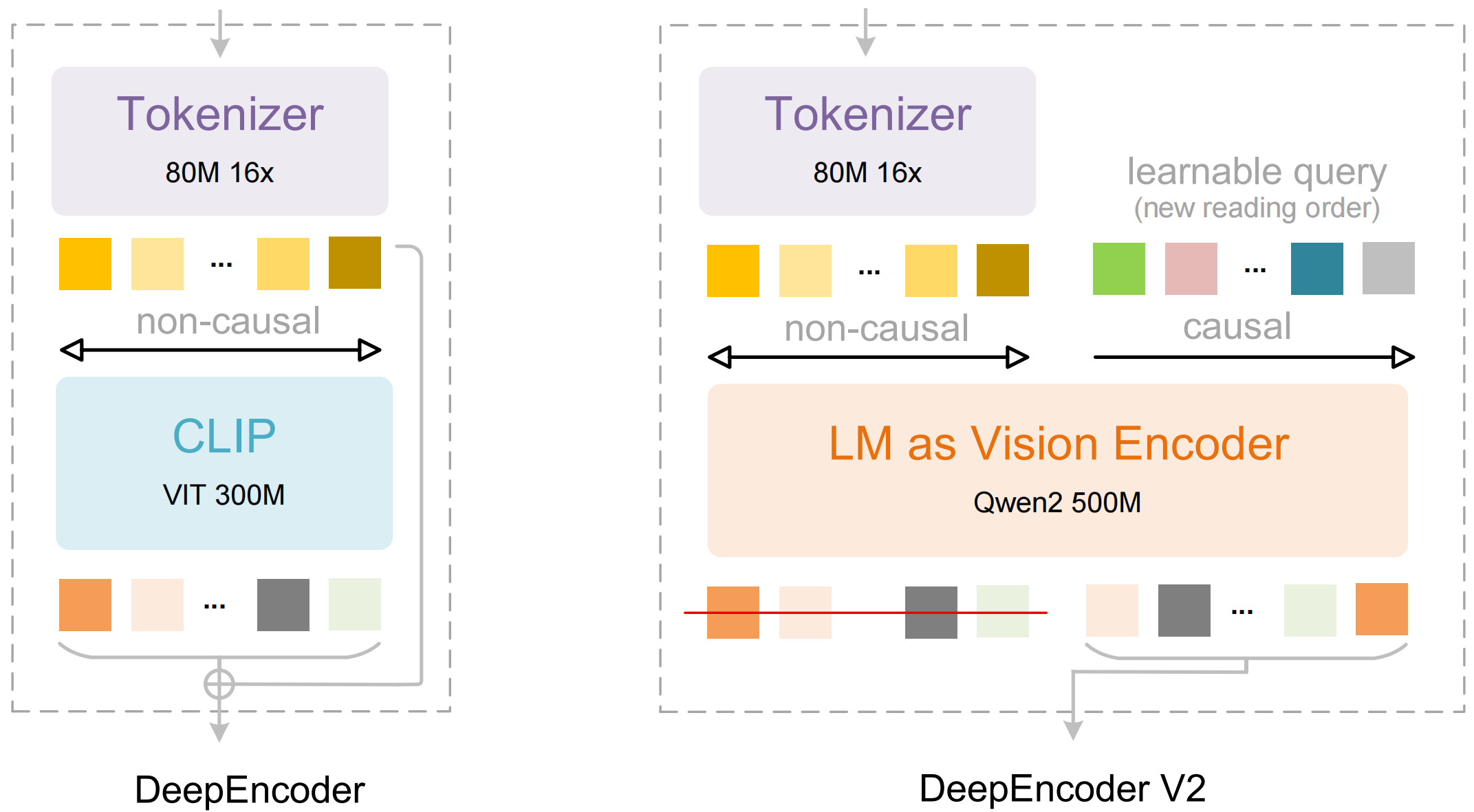
Das Modell besteht aus zwei Hauptkomponenten:
- DeepEncoder: Ein dualer Vision-Transformer, der die lokale Detail extraktion (SAM-basiert, 80 Mio. Parameter) mit dem globalen Layoutverständnis (CLIP-basiert, 300 Mio. Parameter) kombiniert
- DeepSeek3B-MoE Decoder: Ein Mixture-of-Experts-Sprachmodell, das aus der komprimierten visuellen Darstellung strukturierte Ausgaben (Markdown, LaTeX, JSON) generiert
Was DeepSeek-OCR 2 auszeichnet:
- Extreme Kompression: Reduziert ein 1024×1024-Bild von 4.096 Patches auf nur 256 Tokens – eine 16-fache Reduzierung
- Strukturierte Ausgabe: Generiert sauberes Markdown mit korrekten Tabellen, Überschriften und Formatierungen
- Unterstützung mehrerer Formate: Verarbeitet PDFs, gescannte Dokumente, Screenshots, handschriftliche Notizen und mehr
- Über 100 Sprachen: Trainiert auf 30 Millionen Seiten, die etwa 100 Sprachen abdecken
- Offene Gewichte: MIT-lizenziert, verfügbar auf Hugging Face
Hauptmerkmale und Architektur
Visueller Kausalfluss
Das Hauptmerkmal von Version 2 ist der „Visual Causal Flow“ – ein neuer Ansatz zum Verständnis von Dokumenten, der über einfaches OCR hinausgeht. Anstatt eine Seite als flaches Gitter von Zeichen zu behandeln, lernt das Modell kausale Beziehungen zwischen visuellen Elementen:
- Inferenz der Lesereihenfolge: Bestimmt automatisch die korrekte Reihenfolge für mehrspaltige Layouts
- Verständnis der Tabellenstruktur: Erkennt Überschriften, zusammengeführte Zellen und verschachtelte Tabellen
- Verknüpfung von Abbildung und Bildunterschrift: Ordnet Bilder ihren Beschreibungen zu
- Parsing mathematischer Ausdrücke: Verarbeitet Inline- und Block-LaTeX präzise
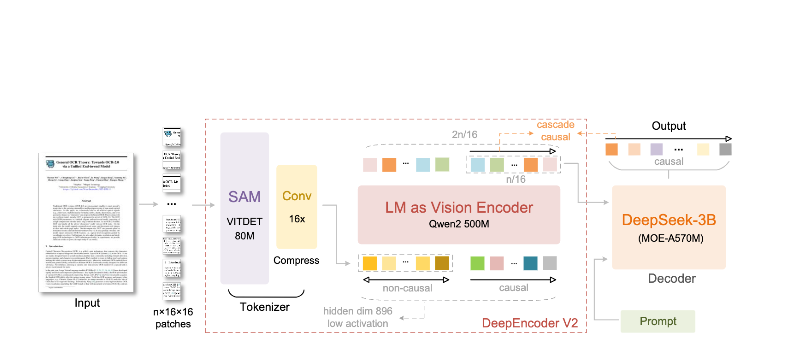
DeepEncoder-Architektur
Der DeepEncoder ist der Ort, an dem die Magie geschieht. Er verarbeitet hochauflösende Bilder, während er eine überschaubare Anzahl von Tokens beibehält:
Eingabebild (1024×1024)
↓
SAM-Basis-Block (80 Mio. Parameter)
- Fensterbasierte Aufmerksamkeit für lokale Details
- Extrahiert feinkörnige Merkmale
↓
CLIP-Large-Block (300 Mio. Parameter)
- Globale Aufmerksamkeit für das Layout
- Versteht die Dokumentstruktur
↓
Faltungsblock
- 16-fache Token-Reduzierung
- 4.096 Patches → 256 Tokens
↓
Ausgabe: Komprimierte Vision Tokens
Kompromiss zwischen Kompression und Genauigkeit
| Kompressionsverhältnis | Vision Tokens | Genauigkeit |
|---|---|---|
| 4× | 1.024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
Der optimale Punkt für die meisten Anwendungen ist das 10-fache Kompressionsverhältnis, das eine Genauigkeit von 97 % beibehält und gleichzeitig den hohen Durchsatz ermöglicht, der den Produktionseinsatz praktikabel macht.
Installation und Einrichtung
Voraussetzungen
- Python 3.10+ (3.12.9 empfohlen)
- CUDA 11.8+ mit kompatibler NVIDIA-GPU
- Mindestens 16 GB GPU-Speicher (A100-40G für die Produktion empfohlen)
Methode 1: vLLM-Installation (Empfohlen)
vLLM bietet die beste Leistung für Produktionsbereitstellungen:
# Virtuelle Umgebung erstellen
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# vLLM mit CUDA-Unterstützung installieren
pip install vllm>=0.8.5
# Flash-Attention für optimale Leistung installieren
pip install flash-attn==2.7.3 --no-build-isolation
Methode 2: Transformers-Installation
Für Entwicklung und Experimente:
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Methode 3: Docker (Produktion)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Modell vorab herunterladen
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Installation überprüfen
import torch
print(f"PyTorch version: {torch.__version__}")
print(f"CUDA available: {torch.cuda.is_available()}")
print(f"GPU: {torch.cuda.get_device_name(0)}")
import vllm
print(f"vLLM version: {vllm.__version__}")
Python-Codebeispiele
Grundlegendes OCR mit vLLM
Hier ist der einfachste Weg, Text aus einem Dokumentbild zu extrahieren:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Modell initialisieren
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Ihr Dokumentbild laden
image = Image.open("document.png").convert("RGB")
# Den Prompt vorbereiten - "Free OCR." löst die Standardextraktion aus
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Sampling-Parameter konfigurieren
sampling_params = SamplingParams(
temperature=0.0, # Deterministisch für OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> für Tabellen
},
skip_special_tokens=False,
)
# Ausgabe generieren
outputs = llm.generate(model_input, sampling_params)
# Den Markdown-Text extrahieren
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Stapelverarbeitung mehrerer Dokumente
Verarbeiten Sie mehrere Dokumente effizient in einem einzigen Stapel:
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Mehrere Bilder in einem einzigen Stapel verarbeiten."""
# Alle Bilder laden
images = [Image.open(p).convert("RGB") for p in image_paths]
# Batch-Eingabe vorbereiten
prompt = "<image>\nFree OCR."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Alle Ausgaben in einem Aufruf generieren
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Nutzung
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # Erste 500 Zeichen
print()
Transformers direkt verwenden
Für mehr Kontrolle über den Inferenzprozess:
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# GPU setzen
device = "cuda:0"
# Modell und Tokenizer laden
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Bild laden und vorverarbeiten
image = Image.open("document.png").convert("RGB")
# Verschiedene Prompts für verschiedene Aufgaben
prompts = {
"ocr": "<image>\nFree OCR.",
"markdown": "<image>\n<|grounding|>Convert the document to markdown.",
"table": "<image>\nExtract all tables as markdown.",
"math": "<image>\nExtract mathematical expressions as LaTeX.",
}
# Mit dem gewählten Prompt verarbeiten
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Bild zu den Inputs hinzufügen (modellspezifische Vorverarbeitung)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Asynchrone Verarbeitung für hohen Durchsatz
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Ein einzelnes Dokument asynchron verarbeiten."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nFree OCR."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Asynchrone Engine initialisieren
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Mehrere Dokumente gleichzeitig verarbeiten
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} Zeichen extrahiert")
asyncio.run(main())
vLLM für die Produktion verwenden
Starten des OpenAI-kompatiblen Servers
DeepSeek-OCR 2 als API-Server bereitstellen:
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
Aufruf des Servers mit dem OpenAI SDK
from openai import OpenAI
import base64
# Client initialisieren, der auf den lokalen Server zeigt
client = OpenAI(
api_key="EMPTY", # Für lokalen Server nicht erforderlich
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Bild in Base64 kodieren."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Text aus Dokument mit OCR-API extrahieren."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Nutzung
result = ocr_document("invoice.png")
print(result)
Verwendung mit URLs
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Testen mit Apidog
Das effektive Testen von OCR-APIs erfordert die Visualisierung sowohl der Eingabedokumente als auch der extrahierten Ausgabe. Apidog bietet eine intuitive Benutzeroberfläche zum Experimentieren mit DeepSeek-OCR 2.
Einrichten des OCR-Endpunkts
Schritt 1: Eine neue Anfrage erstellen
- Öffnen Sie Apidog und erstellen Sie ein neues Projekt
- Fügen Sie eine POST-Anfrage an
http://localhost:8000/v1/chat/completionshinzu
Schritt 2: Header konfigurieren
Content-Type: application/json
Schritt 3: Anfragetext konfigurieren
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "Free OCR."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Testen verschiedener Dokumenttypen
Erstellen Sie gespeicherte Anfragen für gängige Dokumenttypen:
- Rechnungsextraktion – Test der Extraktion strukturierter Daten
- Wissenschaftliche Arbeit – Test der LaTeX-Mathematikverarbeitung
- Handschriftliche Notizen – Test der Handschrifterkennung
- Mehrspaltiges Layout – Test der Inferenz der Lesereihenfolge
Auflösungsmodi vergleichen
Richten Sie Umgebungsvariablen ein, um verschiedene Modi schnell zu testen:
| Modus | Auflösung | Tokens | Anwendungsfall |
|---|---|---|---|
tiny | 512×512 | 64 | Schnelle Vorschauen |
small | 640×640 | 100 | Einfache Dokumente |
base | 1024×1024 | 256 | Standarddokumente |
large | 1280×1280 | 400 | Dichter Text |
gundam | Dynamisch | Variabel | Komplexe Layouts |

Auflösungsmodi und Kompression
DeepSeek-OCR 2 unterstützt fünf Auflösungsmodi, die jeweils für unterschiedliche Anwendungsfälle optimiert sind:
Winziger Modus (64 Tokens)
Am besten geeignet für: Schnelle Texterkennung, einfache Formulare, Eingaben mit niedriger Auflösung
# Für den winzigen Modus konfigurieren
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Kleiner Modus (100 Tokens)
Am besten geeignet für: Saubere digitale Dokumente, einspaltigen Text
Basismodus (256 Tokens) - Standard
Am besten geeignet für: Die meisten Standarddokumente, Rechnungen, Briefe
Großer Modus (400 Tokens)
Am besten geeignet für: Dichte wissenschaftliche Arbeiten, juristische Dokumente
Gundam-Modus (Dynamisch)
Am besten geeignet für: Komplexe mehrseitige Dokumente mit variierenden Layouts
# Der Gundam-Modus kombiniert mehrere Ansichten
# - n × 640×640 lokale Kacheln für Details
# - 1 × 1024×1024 globale Ansicht für die Struktur
Den richtigen Modus wählen
def select_mode(document_type: str, page_count: int) -> str:
"""Wählen Sie den optimalen Auflösungsmodus basierend auf den Dokumentmerkmalen."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Standard
PDFs und Dokumente verarbeiten
PDFs in Bilder umwandeln
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""PDF-Seiten in PIL-Bilder umwandeln."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Mit angegebener DPI rendern
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# In PIL-Bild umwandeln
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Nutzung
images = pdf_to_images("report.pdf", dpi=200)
print(f"Extrahierte {len(images)} Seiten")
Vollständige PDF-Verarbeitungspipeline
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Gesamtes PDF verarbeiten und kombiniertes Markdown zurückgeben."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Seite in Bild umwandeln
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# Die Seite OCRn
prompt = "<image>\nFree OCR."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Seite {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Nutzung
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# In Datei speichern
Path("output.md").write_text(markdown)
Benchmark-Leistung
Genauigkeits-Benchmarks
| Benchmark | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| Tokens/Seite | 100-256 | 256 | 6.000+ |
| Fox (10× Kompression) | 97% | – | – |
| Fox (20× Kompression) | 60% | – | – |
Durchsatzleistung
| Hardware | Seiten/Tag | Seiten/Stunde |
|---|---|---|
| A100-40G (einzeln) | 200.000+ | ~8.300 |
| A100-40G × 20 | 33 Mio.+ | ~1,4 Mio. |
| RTX 4090 | ~80.000 | ~3.300 |
| RTX 3090 | ~50.000 | ~2.100 |
Genauigkeit in der Praxis nach Dokumenttyp
| Dokumenttyp | Genauigkeit | Anmerkungen |
|---|---|---|
| Digitale PDFs | 98%+ | Beste Leistung |
| Gescannte Dokumente | 95%+ | Scans guter Qualität |
| Finanzberichte | 92% | Komplexe Tabellen |
| Handschriftliche Notizen | 85% | Hängt von der Lesbarkeit ab |
| Historische Dokumente | 80% | Verschlechterte Qualität |
Best Practices und Optimierung
Bildvorverarbeitung
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""Dokumentbild für optimales OCR vorverarbeiten."""
# Bei Bedarf in RGB umwandeln
if image.mode != "RGB":
image = image.convert("RGB")
# Größe ändern, wenn zu klein (mindestens 512px auf der kürzesten Seite)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# Kontrast für gescannte Dokumente verbessern