
Die Ausführung eines LLM auf Ihrem lokalen Rechner bietet mehrere Vorteile. Erstens haben Sie die vollständige Kontrolle über Ihre Daten, wodurch die Wahrung der Privatsphäre gewährleistet wird. Zweitens können Sie experimentieren, ohne sich Gedanken über teure API-Aufrufe oder monatliche Abonnements machen zu müssen. Außerdem bieten lokale Bereitstellungen eine praktische Möglichkeit, mehr darüber zu erfahren, wie diese Modelle unter der Haube funktionieren.
Darüber hinaus vermeiden Sie bei der lokalen Ausführung von LLMs potenzielle Netzwerk-Latenzprobleme und die Abhängigkeit von Cloud-Diensten. Dies bedeutet, dass Sie schneller bauen, testen und iterieren können, insbesondere wenn Sie an Projekten arbeiten, die eine enge Integration mit Ihrer Codebasis erfordern.
LLMs verstehen: Ein kurzer Überblick
Bevor wir uns mit unseren Top-Empfehlungen befassen, wollen wir kurz darauf eingehen, was ein LLM ist. Vereinfacht ausgedrückt ist ein Large Language Model (LLM) ein KI-Modell, das auf riesigen Mengen an Textdaten trainiert wurde. Diese Modelle lernen die statistischen Muster in der Sprache, wodurch sie menschenähnlichen Text auf der Grundlage der von Ihnen bereitgestellten Prompts generieren können.
LLMs sind das Herzstück vieler moderner KI-Anwendungen. Sie treiben Chatbots, Schreibassistenten, Code-Generatoren und sogar hochentwickelte Konversationsagenten an. Die Ausführung dieser Modelle – insbesondere der größeren – kann jedoch ressourcenintensiv sein. Deshalb ist es so wichtig, ein zuverlässiges Tool zu haben, um sie lokal auszuführen.
Mit lokalen LLM-Tools können Sie mit diesen Modellen experimentieren, ohne Ihre Daten an Remote-Server zu senden. Dies kann sowohl die Sicherheit als auch die Leistung verbessern. Während dieses Tutorials werden Sie feststellen, dass das Schlüsselwort „LLM“ hervorgehoben wird, während wir untersuchen, wie jedes Tool Ihnen hilft, diese leistungsstarken Modelle auf Ihrer eigenen Hardware zu nutzen.
Tool #1: Llama.cpp
Llama.cpp ist wohl eines der beliebtesten Tools, wenn es darum geht, LLMs lokal auszuführen. Diese von Georgi Gerganov erstellte und von einer lebendigen Community gepflegte C/C++-Bibliothek wurde entwickelt, um Inferenz auf Modellen wie LLaMA und anderen mit minimalen Abhängigkeiten durchzuführen.

Warum Sie Llama.cpp lieben werden
- Leicht und schnell: Llama.cpp ist auf Geschwindigkeit und Effizienz ausgelegt. Mit minimalem Setup können Sie komplexe Modelle auch auf bescheidener Hardware ausführen. Es nutzt fortschrittliche CPU-Anweisungen wie AVX und Neon, was bedeutet, dass Sie das Beste aus der Leistung Ihres Systems herausholen.
- Vielseitige Hardware-Unterstützung: Egal, ob Sie eine x86-Maschine, ein ARM-basiertes Gerät oder sogar einen Apple Silicon Mac verwenden, Llama.cpp hat alles, was Sie brauchen.
- Befehlszeilenflexibilität: Wenn Sie das Terminal grafischen Oberflächen vorziehen, erleichtern Ihnen die Befehlszeilentools von Llama.cpp das Laden von Modellen und das Generieren von Antworten direkt aus Ihrer Shell.
- Community und Open Source: Als Open-Source-Projekt profitiert es von kontinuierlichen Beiträgen und Verbesserungen von Entwicklern auf der ganzen Welt.
Erste Schritte
- Installation: Klonen Sie das Repository von GitHub und kompilieren Sie den Code auf Ihrem Rechner.
- Modell-Setup: Laden Sie Ihr bevorzugtes Modell (z. B. eine quantisierte LLaMA-Variante) herunter und verwenden Sie die bereitgestellten Befehlszeilen-Dienstprogramme, um die Inferenz zu starten.
- Anpassung: Optimieren Sie Parameter wie Kontextlänge, Temperatur und Strahlgröße, um zu sehen, wie sich die Ausgabe des Modells ändert.
Ein einfacher Befehl könnte beispielsweise so aussehen:
./main -m ./models/llama-7b.gguf -p "Tell me a joke about programming" --temp 0.7 --top_k 100
Dieser Befehl lädt das Modell und generiert Text basierend auf Ihrem Prompt. Die Einfachheit dieses Setups ist ein großes Plus für alle, die mit lokaler LLM-Inferenz beginnen.
Lassen Sie uns nahtlos von Llama.cpp übergehen und ein weiteres fantastisches Tool erkunden, das einen etwas anderen Ansatz verfolgt.
Tool #2: GPT4All
GPT4All ist ein Open-Source-Ökosystem, das von Nomic AI entwickelt wurde und den Zugang zu LLMs demokratisiert. Einer der aufregendsten Aspekte von GPT4All ist, dass es so konzipiert ist, dass es auf Hardware für Endverbraucher läuft, egal ob Sie eine CPU oder eine GPU verwenden. Dies macht es perfekt für Entwickler, die experimentieren möchten, ohne teure Maschinen zu benötigen.
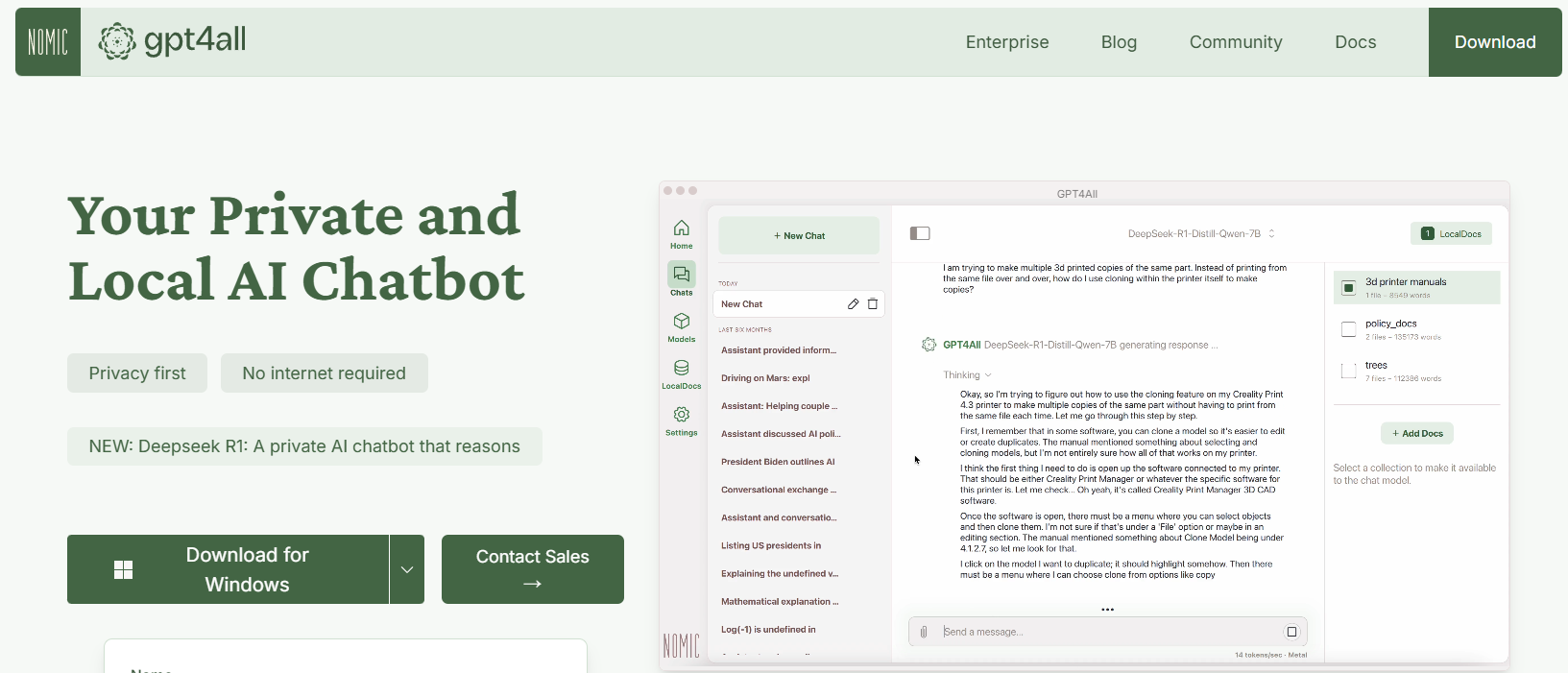
Hauptmerkmale von GPT4All
- Local-First-Ansatz: GPT4All ist so konzipiert, dass es vollständig auf Ihrem lokalen Gerät ausgeführt wird. Dies bedeutet, dass keine Daten jemals Ihr Gerät verlassen, wodurch die Privatsphäre und schnelle Reaktionszeiten gewährleistet werden.
- Benutzerfreundlich: Auch wenn Sie neu bei LLMs sind, verfügt GPT4All über eine einfache, intuitive Benutzeroberfläche, mit der Sie mit dem Modell interagieren können, ohne tiefes technisches Know-how zu haben.
- Leicht und effizient: Die Modelle im GPT4All-Ökosystem sind auf Leistung optimiert. Sie können sie auf Ihrem Laptop ausführen, wodurch sie einem breiteren Publikum zugänglich sind.
- Open Source und Community-gesteuert: Mit seiner Open-Source-Natur lädt GPT4All zu Community-Beiträgen ein und stellt sicher, dass es mit den neuesten Innovationen auf dem Laufenden bleibt.
Erste Schritte mit GPT4All
- Installation: Sie können GPT4All von der Website herunterladen. Der Installationsvorgang ist unkompliziert, und vorkompilierte Binärdateien sind für Windows, macOS und Linux verfügbar.
- Ausführen des Modells: Starten Sie nach der Installation einfach die Anwendung und wählen Sie aus einer Vielzahl von voreingestellten Modellen. Das Tool bietet sogar eine Chat-Oberfläche, die sich perfekt für gelegentliches Experimentieren eignet.
- Anpassung: Passen Sie Parameter wie die Antwortlänge und die Kreativitätseinstellungen des Modells an, um zu sehen, wie sich die Ausgabe ändert. Dies hilft Ihnen zu verstehen, wie LLMs unter verschiedenen Bedingungen funktionieren.
Sie könnten beispielsweise einen Prompt wie diesen eingeben:
What are some fun facts about artificial intelligence?
Und GPT4All generiert eine freundliche, aufschlussreiche Antwort – alles ohne Internetverbindung.
Tool #3: LM Studio
Weiter geht es mit LM Studio , einem weiteren hervorragenden Tool zum lokalen Ausführen von LLMs, insbesondere wenn Sie nach einer grafischen Benutzeroberfläche suchen, die die Modellverwaltung zum Kinderspiel macht.
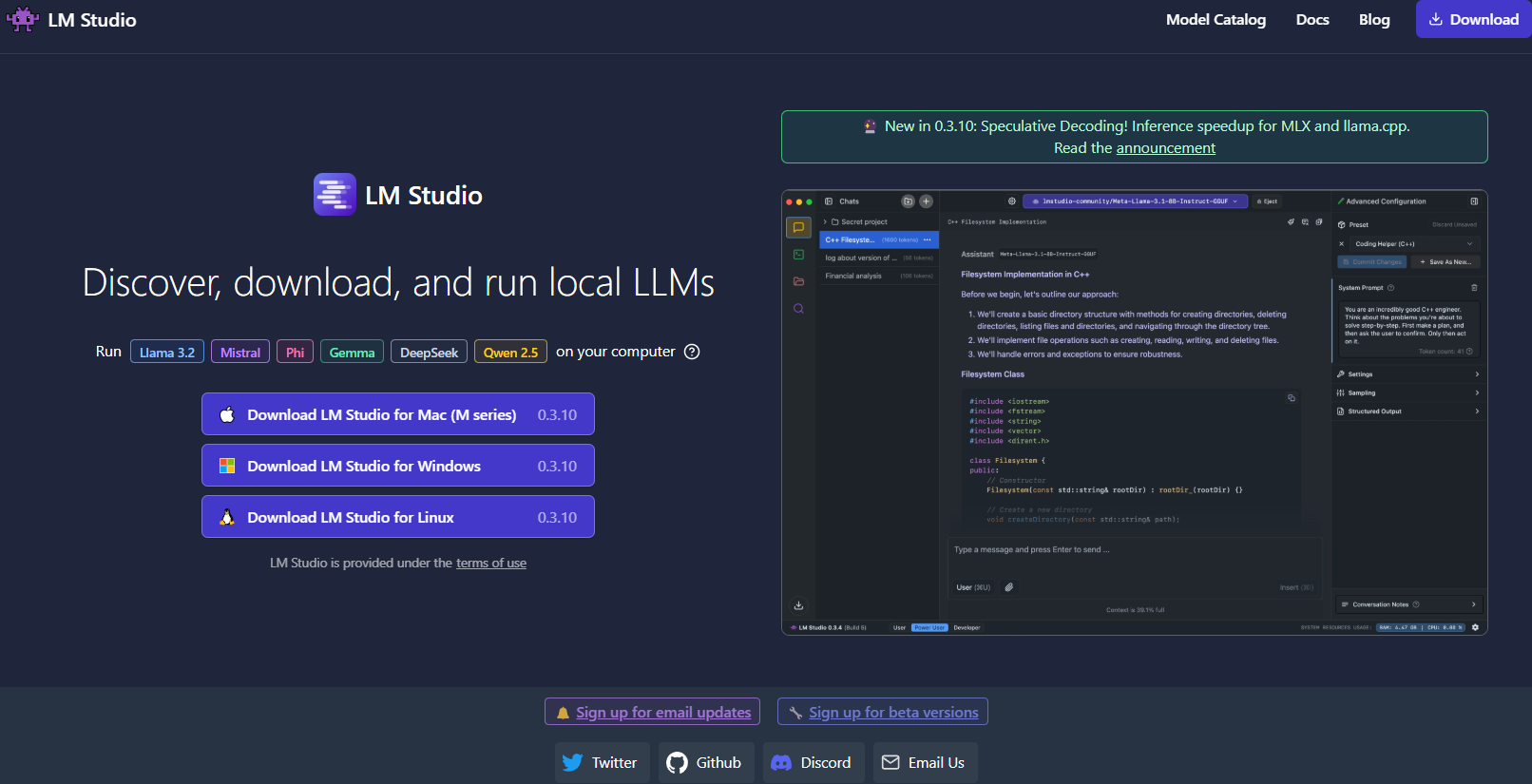
Was LM Studio auszeichnet
- Intuitive Benutzeroberfläche: LM Studio bietet eine elegante, benutzerfreundliche Desktop-Anwendung. Dies ist ideal für diejenigen, die es vorziehen, nicht nur in der Befehlszeile zu arbeiten.
- Modellverwaltung: Mit LM Studio können Sie ganz einfach verschiedene LLMs durchsuchen, herunterladen und zwischen ihnen wechseln. Die App verfügt über integrierte Filter und Suchfunktionen, sodass Sie das perfekte Modell für Ihr Projekt finden können.
- Anpassbare Einstellungen: Passen Sie Parameter wie Temperatur, maximale Token und Kontextfenster direkt über die Benutzeroberfläche an. Diese sofortige Feedbackschleife ist perfekt, um zu lernen, wie sich verschiedene Konfigurationen auf das Modellverhalten auswirken.
- Plattformübergreifende Kompatibilität: LM Studio läuft unter Windows, macOS und Linux und ist somit für eine Vielzahl von Benutzern zugänglich.
- Lokaler Inferenzserver: Entwickler können auch den lokalen HTTP-Server nutzen, der die OpenAI-API nachahmt. Dies vereinfacht die Integration von LLM-Funktionen in Ihre Anwendungen erheblich.
So richten Sie LM Studio ein
- Herunterladen und Installieren: Besuchen Sie die LM Studio-Website, laden Sie das Installationsprogramm für Ihr Betriebssystem herunter und befolgen Sie die Einrichtungsanweisungen.
- Starten und Erkunden: Öffnen Sie die Anwendung, erkunden Sie die Bibliothek der verfügbaren Modelle und wählen Sie eines aus, das Ihren Anforderungen entspricht.
- Experimentieren: Verwenden Sie die integrierte Chat-Oberfläche, um mit dem Modell zu interagieren. Sie können auch mit mehreren Modellen gleichzeitig experimentieren, um Leistung und Qualität zu vergleichen.
Stellen Sie sich vor, Sie arbeiten an einem kreativen Schreibprojekt; Die Benutzeroberfläche von LM Studio erleichtert das Wechseln zwischen Modellen und das Feinabstimmen der Ausgabe in Echtzeit. Das visuelle Feedback und die Benutzerfreundlichkeit machen es zu einer guten Wahl für diejenigen, die gerade erst anfangen, oder für Profis, die eine robuste lokale Lösung benötigen.
Tool #4: Ollama
Als Nächstes kommt Ollama, ein leistungsstarkes, aber unkompliziertes Befehlszeilentool mit Fokus auf Einfachheit und Funktionalität. Ollama wurde entwickelt, um Ihnen zu helfen, LLMs auszuführen, zu erstellen und freizugeben, ohne den Aufwand komplexer Setups.
Warum Ollama wählen?
- Einfache Modellbereitstellung: Ollama verpackt alles, was Sie brauchen – Modellgewichte, Konfiguration und sogar Daten – in einer einzigen, portablen Einheit, die als „Modelfile“ bezeichnet wird. Dies bedeutet, dass Sie ein Modell schnell herunterladen und mit minimaler Konfiguration ausführen können.
- Multimodale Fähigkeiten: Im Gegensatz zu einigen Tools, die sich nur auf Text konzentrieren, unterstützt Ollama multimodale Eingaben. Sie können sowohl Text als auch Bilder als Prompts bereitstellen, und das Tool generiert Antworten, die beides berücksichtigen.
- Plattformübergreifende Verfügbarkeit: Ollama ist unter macOS, Linux und Windows verfügbar. Es ist eine großartige Option für Entwickler, die über verschiedene Systeme hinweg arbeiten.
- Befehlszeilen-Effizienz: Für diejenigen, die es vorziehen, im Terminal zu arbeiten, bietet Ollama eine saubere, effiziente Befehlszeilenschnittstelle, die eine schnelle Bereitstellung und Interaktion ermöglicht.
- Schnelle Updates: Das Tool wird häufig von seiner Community aktualisiert, wodurch sichergestellt wird, dass Sie immer mit den neuesten Verbesserungen und Funktionen arbeiten.
Einrichten von Ollama
1. Installation: Besuchen Sie die Ollama-Website und laden Sie das Installationsprogramm für Ihr Betriebssystem herunter. Die Installation ist so einfach wie das Ausführen einiger Befehle in Ihrem Terminal.
2. Führen Sie ein Modell aus: Verwenden Sie nach der Installation einen Befehl wie:
ollama run llama3
Dieser Befehl lädt automatisch das Llama 3-Modell (oder ein anderes unterstütztes Modell) herunter und startet den Inferenzprozess.
3. Experimentieren Sie mit Multimodalität: Versuchen Sie, ein Modell auszuführen, das Bilder unterstützt. Wenn Sie beispielsweise eine Bilddatei bereit haben, können Sie sie in Ihren Prompt ziehen und ablegen (oder den API-Parameter für Bilder verwenden), um zu sehen, wie das Modell reagiert.
Ollama ist besonders attraktiv, wenn Sie schnell Prototypen erstellen oder LLMs lokal bereitstellen möchten. Seine Einfachheit geht nicht auf Kosten der Leistung, was es sowohl für Anfänger als auch für erfahrene Entwickler ideal macht.
Tool #5: Jan
Zu guter Letzt haben wir Jan. Jan ist eine Open-Source-, Local-First-Plattform, die bei denjenigen, die Wert auf Datenschutz und Offline-Betrieb legen, stetig an Popularität gewinnt. Seine Philosophie ist einfach: Benutzer sollen leistungsstarke LLMs vollständig auf ihrer eigenen Hardware ausführen können, ohne versteckte Datenübertragungen.
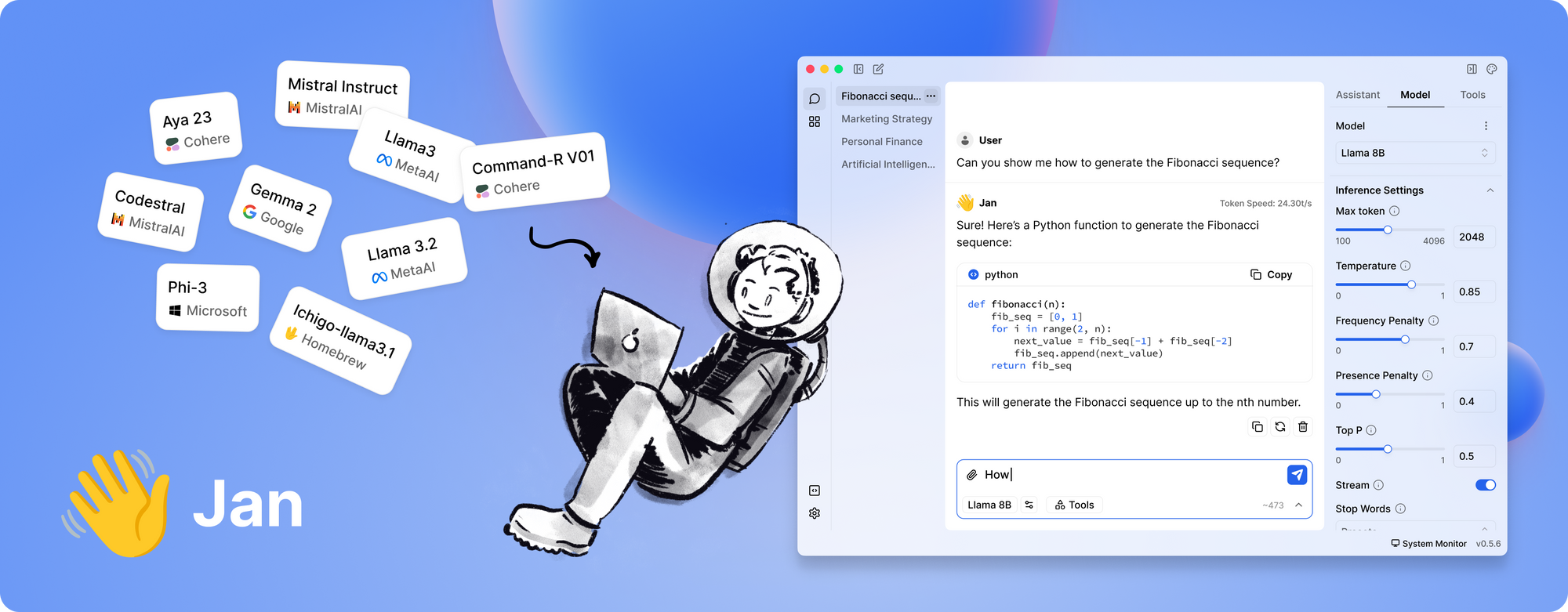
Was Jan auszeichnet
- Völlig offline: Jan ist so konzipiert, dass es ohne Internetverbindung funktioniert. Dies stellt sicher, dass alle Ihre Interaktionen und Daten lokal bleiben, wodurch die Privatsphäre und Sicherheit verbessert werden.
- Benutzerzentriert und erweiterbar: Das Tool bietet eine übersichtliche Benutzeroberfläche und unterstützt ein App-/Plugin-Framework. Dies bedeutet, dass Sie seine Fähigkeiten einfach erweitern oder in Ihre vorhandenen Tools integrieren können.
- Effiziente Modellausführung: Jan ist so konzipiert, dass es eine Vielzahl von Modellen verarbeiten kann, einschließlich solcher, die für bestimmte Aufgaben optimiert wurden. Es ist optimiert, um auch auf bescheidener Hardware zu laufen, ohne die Leistung zu beeinträchtigen.
- Community-gesteuerte Entwicklung: Wie viele der Tools auf unserer Liste ist Jan Open Source und profitiert von Beiträgen einer engagierten Community von Entwicklern.
- Keine Abonnementgebühren: Im Gegensatz zu vielen Cloud-basierten Lösungen ist Jan kostenlos. Dies macht es zu einer ausgezeichneten Wahl für Startups, Hobbyisten und alle, die mit LLMs ohne finanzielle Hürden experimentieren möchten.
Erste Schritte mit Jan
- Herunterladen und Installieren: Besuchen Sie die offizielle Website von Jan oder das GitHub-Repository. Befolgen Sie die Installationsanweisungen, die unkompliziert sind und darauf ausgelegt sind, Sie schnell zum Laufen zu bringen.
- Starten und Anpassen: Öffnen Sie Jan und wählen Sie aus einer Vielzahl von vorinstallierten Modellen. Bei Bedarf können Sie Modelle aus externen Quellen wie Hugging Face importieren.
- Experimentieren und Erweitern: Verwenden Sie die Chat-Oberfläche, um mit Ihrem LLM zu interagieren. Passen Sie Parameter an, installieren Sie Plugins und sehen Sie, wie sich Jan an Ihren Workflow anpasst. Seine Flexibilität ermöglicht es Ihnen, Ihr lokales LLM-Erlebnis auf Ihre genauen Bedürfnisse zuzuschneiden.
Jan verkörpert wirklich den Geist der lokalen, datenschutzorientierten LLM-Ausführung. Es ist perfekt für alle, die ein unkompliziertes, anpassbares Tool suchen, das alle Daten auf ihrem eigenen Rechner speichert.
Profi-Tipp: Streaming von LLM-Antworten mit SSE-Debugging
Wenn Sie mit LLMs (Large Language Models) arbeiten, kann die Interaktion in Echtzeit die Benutzererfahrung erheblich verbessern. Ob es sich um einen Chatbot handelt, der Live-Antworten liefert, oder um ein Content-Tool, das sich dynamisch aktualisiert, während Daten generiert werden, Streaming ist der Schlüssel. Server-Sent Events (SSE) bieten hierfür eine effiziente Lösung, die es Servern ermöglicht, Updates über eine einzige HTTP-Verbindung an Clients zu pushen. Im Gegensatz zu bidirektionalen Protokollen wie WebSockets ist SSE einfacher und unkomplizierter, was es zu einer guten Wahl für Echtzeitfunktionen macht.
Das Debuggen von SSE kann eine Herausforderung sein. Hier kommt Apidog ins Spiel. Mit der SSE-Debugging-Funktion von Apidog können Sie SSE-Streams einfach testen, überwachen und Fehler beheben. In diesem Abschnitt werden wir untersuchen, warum SSE für das Debuggen von LLM-APIs wichtig ist, und Sie durch ein Schritt-für-Schritt-Tutorial zur Verwendung von Apidog zum Einrichten und Testen von SSE-Verbindungen führen.
Warum SSE für das Debuggen von LLM-APIs wichtig ist
Bevor wir uns mit dem Tutorial befassen, hier ist der Grund, warum SSE eine gute Lösung für das Debuggen von LLM-APIs ist:
- Echtzeit-Feedback: SSE streamt Daten, während sie generiert werden, sodass Benutzer die Antworten auf natürliche Weise entfalten sehen können.
- Geringer Overhead: Im Gegensatz zum Polling verwendet SSE eine einzige persistente Verbindung, wodurch die Ressourcennutzung minimiert wird.
- Benutzerfreundlichkeit: SSE lässt sich nahtlos in Webanwendungen integrieren und erfordert nur minimale Einrichtung auf der Clientseite.
Bereit, es zu testen? Lassen Sie uns das SSE-Debugging in Apidog einrichten.
Schritt-für-Schritt-Tutorial: Verwenden von SSE-Debugging in Apidog
Befolgen Sie diese Schritte, um eine SSE-Verbindung mit Apidog zu konfigurieren und zu testen.
Schritt 1: Erstellen Sie einen neuen Endpunkt in Apidog
Erstellen Sie ein neues HTTP-Projekt in Apidog, um API-Anfragen zu testen und zu debuggen. Fügen Sie einen Endpunkt mit der URL des KI-Modells für den SSE-Stream hinzu – in diesem Beispiel wird DeepSeek verwendet. (PRO TIP: Klonen Sie das vorgefertigte DeepSeek-API-Projekt aus dem API Hub von Apidog).
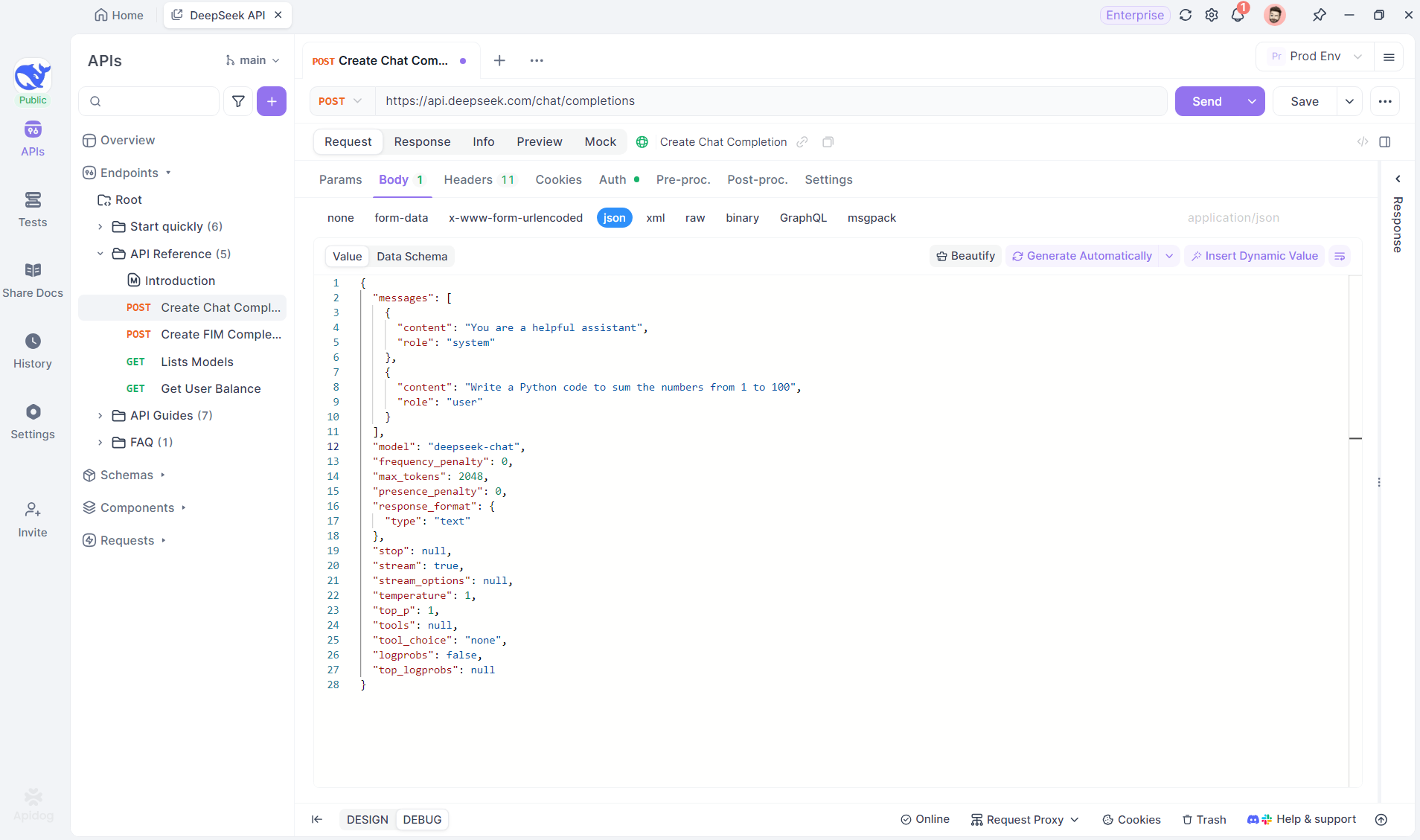
Schritt 2: Senden Sie die Anfrage
Klicken Sie nach dem Hinzufügen des Endpunkts auf Senden, um die Anfrage zu senden. Wenn der Antwortheader Content-Type: text/event-stream enthält, erkennt Apidog den SSE-Stream, analysiert die Daten und zeigt sie in Echtzeit an.
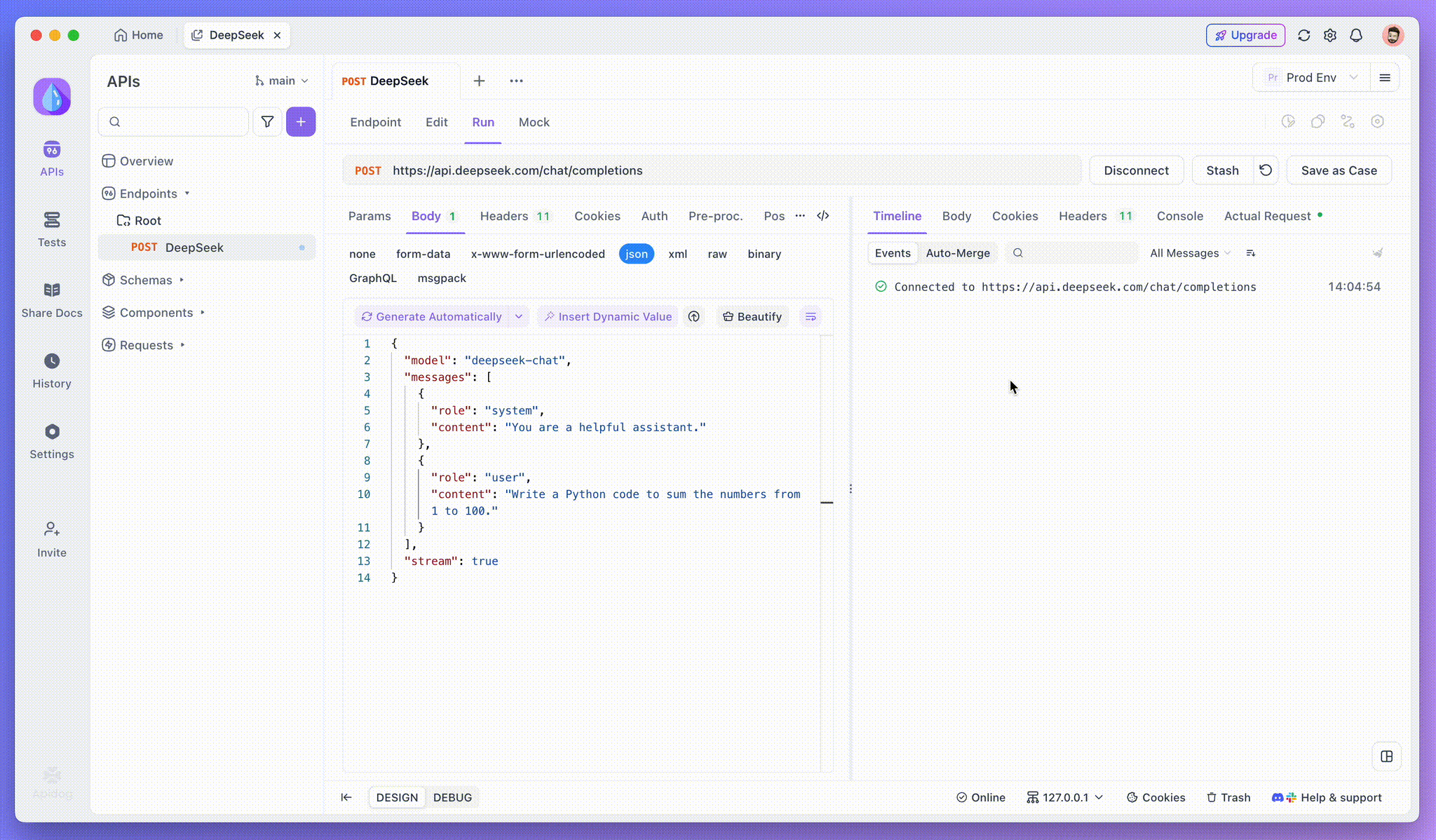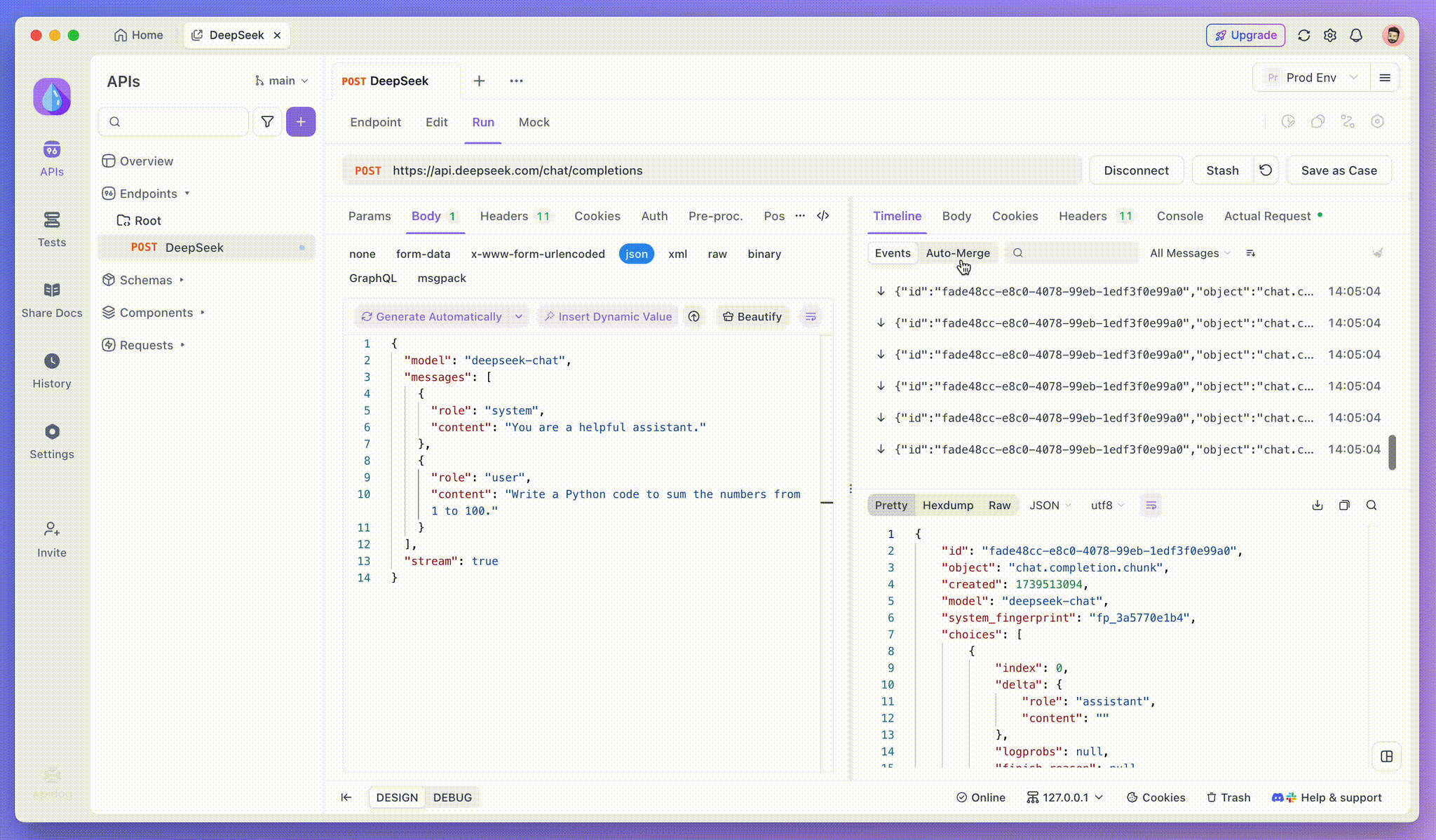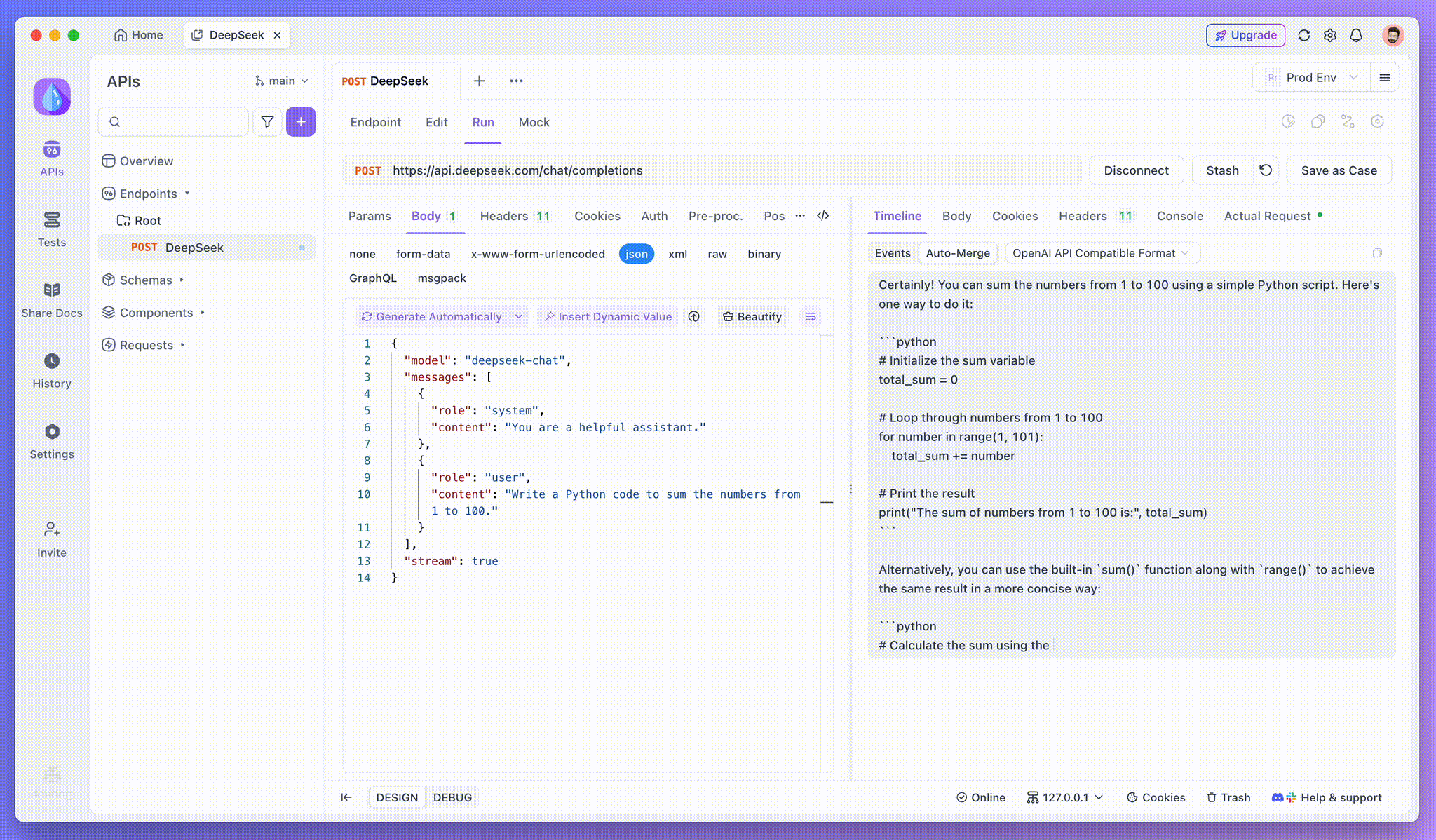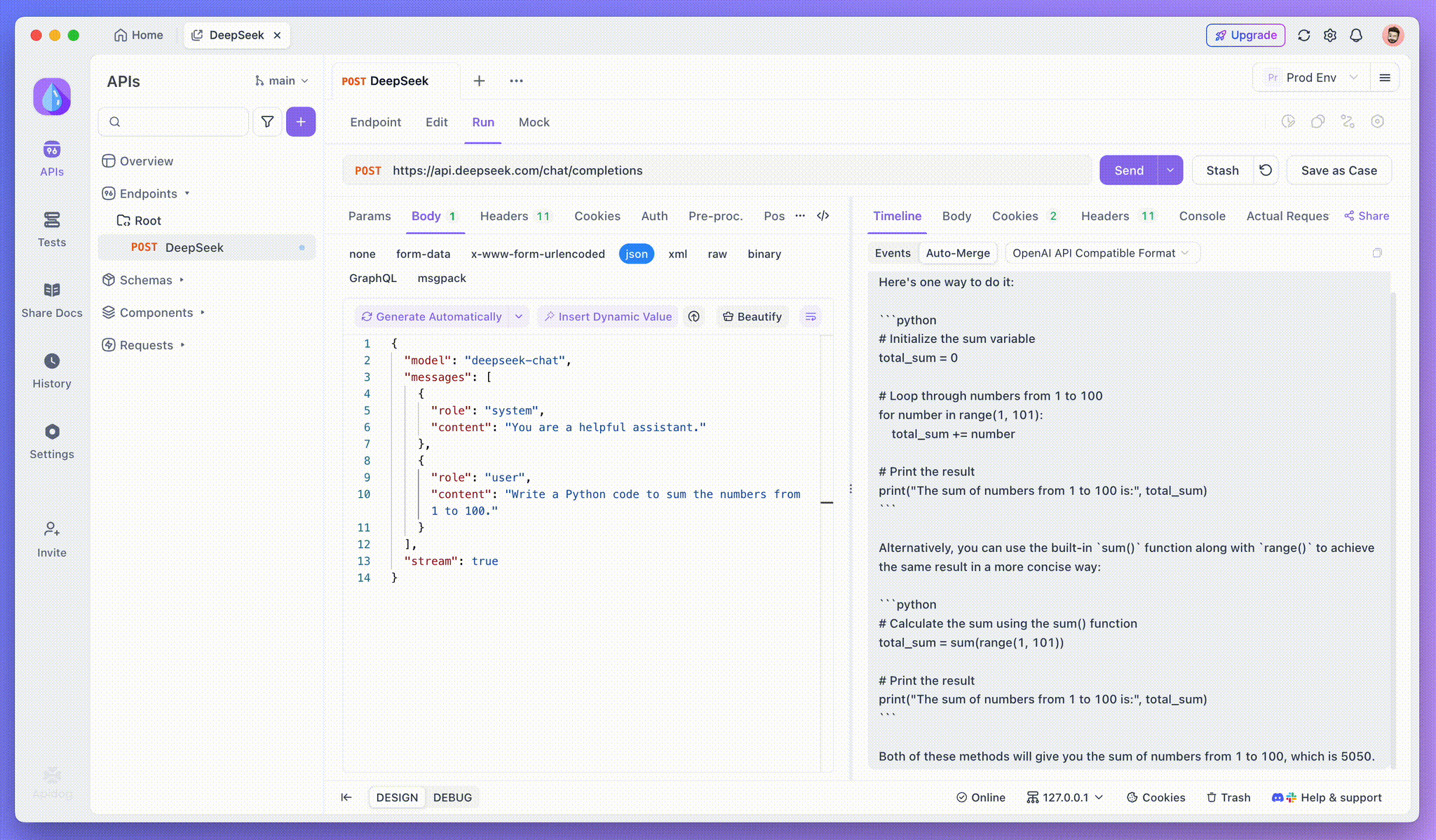
Schritt 3: Echtzeitantworten anzeigen
Die Timeline View von Apidog aktualisiert sich in Echtzeit, während das KI-Modell Antworten streamt, und zeigt jedes Fragment dynamisch an. Auf diese Weise können Sie den Denkprozess der KI verfolgen und Einblicke in die Generierung ihrer Ausgabe erhalten.
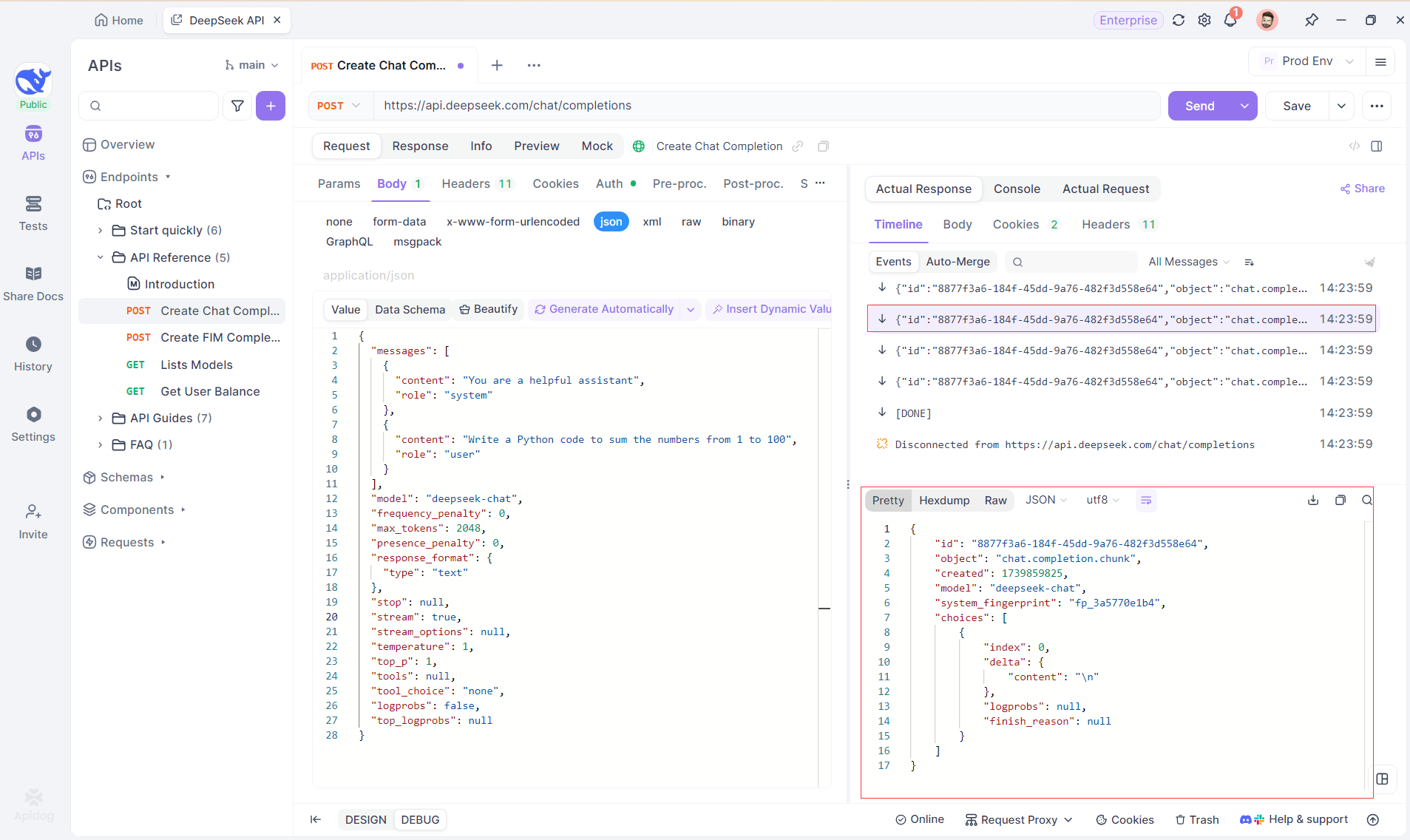
Schritt 4: SSE-Antwort in einer vollständigen Antwort anzeigen
SSE streamt Daten in Fragmenten, was eine zusätzliche Verarbeitung erfordert. Die Auto-Merge-Funktion von Apidog löst dies, indem sie fragmentierte KI-Antworten von Modellen wie OpenAI, Gemini oder Claude automatisch zu einer vollständigen Ausgabe kombiniert.
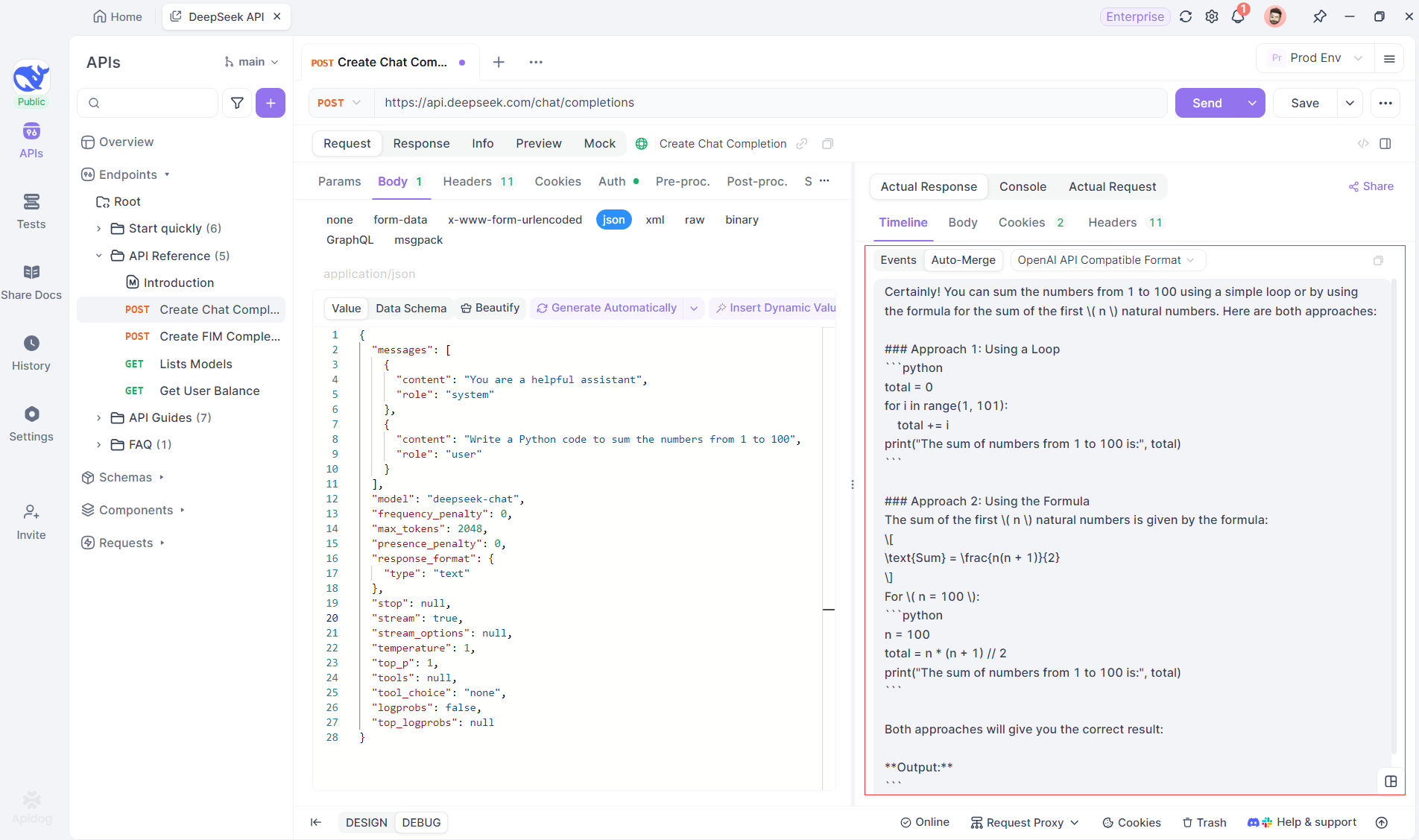
Die Auto-Merge-Funktion von Apidog eliminiert die manuelle Datenverarbeitung, indem sie fragmentierte KI-Antworten von Modellen wie OpenAI, Gemini oder Claude automatisch kombiniert.
Für Reasoning-Modelle wie DeepSeek R1 bildet die Timeline View von Apidog den Denkprozess der KI visuell ab, wodurch es einfacher wird, Fehler zu beheben und zu verstehen, wie Schlussfolgerungen gebildet werden.
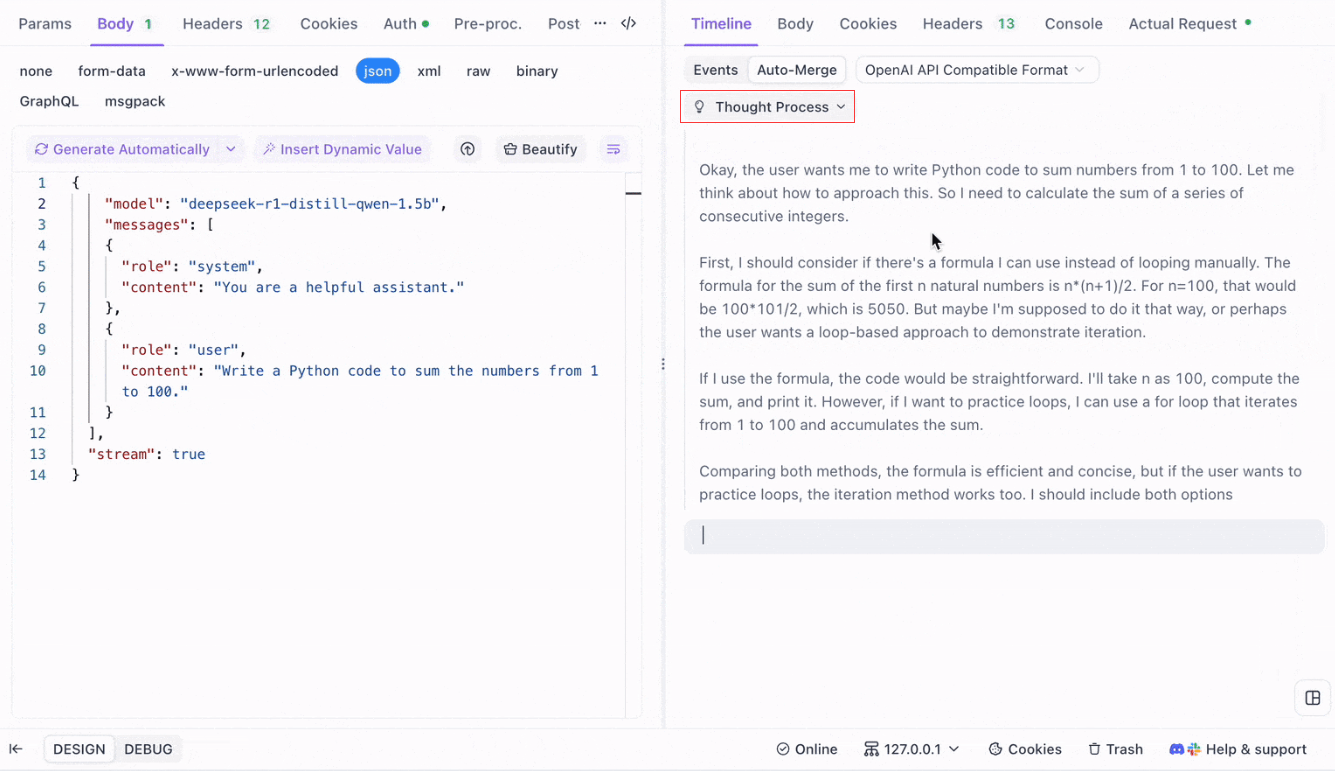
Apidog erkennt und führt KI-Antworten nahtlos zusammen von:
- OpenAI API-Format
- Gemini API-Format
- Claude API-Format
Wenn eine Antwort mit diesen Formaten übereinstimmt, kombiniert Apidog die Fragmente automatisch, wodurch das manuelle Zusammenfügen entfällt und das SSE-Debugging optimiert wird.
Fazit und nächste Schritte
Wir haben heute viel behandelt! Zusammenfassend sind hier die fünf herausragenden Tools für die lokale Ausführung von LLMs:
- Llama.cpp: Ideal für Entwickler, die ein leichtes, schnelles und hocheffizientes Befehlszeilentool mit breiter Hardware-Unterstützung wünschen.
- GPT4All: Ein Local-First-Ökosystem, das auf Hardware für Endverbraucher läuft und eine intuitive Benutzeroberfläche und leistungsstarke Leistung bietet.
- LM Studio: Perfekt für diejenigen, die eine grafische Benutzeroberfläche bevorzugen, mit einfacher Modellverwaltung und umfangreichen Anpassungsoptionen.
- Ollama: Ein robustes Befehlszeilentool mit multimodalen Fähigkeiten und nahtloser Modellverpackung über sein „Modelfile“-System.
- Jan: Eine datenschutzorientierte Open-Source-Plattform, die vollständig offline ausgeführt wird und ein erweiterbares Framework für die Integration verschiedener LLMs bietet.
Jedes dieser Tools bietet einzigartige Vorteile, sei es Leistung, Benutzerfreundlichkeit oder Datenschutz. Je nach den Anforderungen Ihres Projekts ist eine dieser Lösungen möglicherweise die perfekte Lösung für Ihre Anforderungen. Das Schöne an lokalen LLM-Tools ist, dass sie Sie in die Lage versetzen, zu forschen und zu experimentieren, ohne sich Gedanken über Datenverluste, Abonnementkosten oder Netzwerk-Latenz machen zu müssen.
Denken Sie daran, dass das Experimentieren mit lokalen LLMs ein Lernprozess ist. Sie können diese Tools nach Belieben mischen und anpassen, verschiedene Konfigurationen testen und sehen, welche am besten zu Ihrem Workflow passt. Wenn Sie diese Modelle in Ihre eigenen Anwendungen integrieren, können Tools wie Apidog Ihnen helfen, Ihre LLM-API-Endpunkte mithilfe von Server-Sent Events (SSE) nahtlos zu verwalten und zu testen. Vergessen Sie nicht, Apidog kostenlos herunterzuladen und Ihr lokales Entwicklungserlebnis zu verbessern.
Nächste Schritte
- Experimentieren: Wählen Sie ein Tool aus unserer Liste aus und richten Sie es auf Ihrem Rechner ein. Spielen Sie mit verschiedenen Modellen und Einstellungen herum, um zu verstehen, wie sich Änderungen auf die Ausgabe auswirken.
- Integrieren: Wenn Sie eine Anwendung entwickeln, verwenden Sie das lokale LLM-Tool als Teil Ihres Backends. Viele dieser Tools bieten API-Kompatibilität (z. B. der lokale Inferenzserver von LM Studio), was die Integration erleichtern kann.
- Beitragen: Die meisten dieser Projekte sind Open Source. Wenn Sie einen Fehler, eine fehlende Funktion finden oder einfach nur Ideen zur Verbesserung haben, sollten Sie in Erwägung ziehen, einen Beitrag zur Community zu leisten. Ihr Input kann dazu beitragen, diese Tools noch besser zu machen.
- Erfahren Sie mehr: Erkunden Sie die Welt der LLMs weiter, indem Sie sich über Themen wie Modellquantisierung, Optimierungstechniken und Prompt Engineering informieren. Je mehr Sie verstehen, desto mehr können Sie diese Modelle voll ausschöpfen.
Bis jetzt sollten Sie eine solide Grundlage für die Auswahl des richtigen lokalen LLM-Tools für Ihre Projekte haben. Die Landschaft der LLM-Technologie entwickelt sich rasant, und die lokale Ausführung von Modellen ist ein wichtiger Schritt zum Aufbau privater, skalierbarer und leistungsstarker KI-Lösungen.
Wenn Sie mit diesen Tools experimentieren, werden Sie feststellen, dass die Möglichkeiten endlos sind. Egal, ob Sie an einem Chatbot, einem Code-Assistenten oder einem benutzerdefinierten Tool zum kreativen Schreiben arbeiten, lokale LLMs können Ihnen die Flexibilität und Leistung bieten, die Sie benötigen. Viel Spaß auf der Reise und viel Spaß beim Programmieren!


