
Alibabas Tongyi DeepResearch definiert autonome KI-Agenten mit seinem 30B-Parameter Mixture of Experts (MoE)-Modell neu, das nur 3B Parameter pro Token für effiziente, hochpräzise Webrecherche aktiviert. Dieses Open-Source-Kraftpaket übertrifft Benchmarks wie Humanity's Last Exam (32,9 % vs. OpenAIs o3 mit 24,9 %) und xbench-DeepSearch (75,0 % vs. 67,0 %), wodurch Entwickler komplexe, mehrstufige Anfragen – von der Rechtsanalyse bis zu Reiseplänen – ohne proprietäre Abhängigkeit bearbeiten können.
Ingenieure des Tongyi Lab entwickelten diesen Agenten, um langfristiges Denken und dynamische Tool-Nutzung direkt zu bewältigen. Folglich übertrifft er geschlossene Modelle in der realen Synthese, während er gleichzeitig lokal über Hugging Face läuft. In dieser technischen Analyse sezieren wir seine spärliche Architektur, die automatisierte Datenpipeline, das RL-optimierte Training, die Benchmark-Dominanz und die Bereitstellungshacks. Am Ende werden Sie sehen, wie Tongyi DeepResearch – und Tools wie Apidog – skalierbare Agenten-KI für Ihre Projekte freischalten.
Tongyi DeepResearch verstehen: Kernkonzepte und Innovationen
Tongyi DeepResearch definiert die Agenten-KI neu, indem es sich auf tiefe Informationsbeschaffung und -synthese konzentriert. Im Gegensatz zu traditionellen großen Sprachmodellen (LLMs), die sich in der Kurzform-Generierung auszeichnen, navigiert dieser Agent in dynamischen Umgebungen wie Webbrowsern, um nuancierte Erkenntnisse zu gewinnen. Insbesondere verwendet es eine Mixture of Experts (MoE)-Architektur, bei der die vollen 30 Milliarden Parameter selektiv auf nur 3 Milliarden pro Token aktiviert werden. Diese Effizienz ermöglicht eine robuste Leistung auf ressourcenbeschränkter Hardware bei gleichzeitig hohem Kontextbewusstsein von bis zu 128.000 Tokens.
Darüber hinaus lässt sich das Modell nahtlos in Inferenzparadigmen integrieren, die menschliches Entscheidungsverhalten nachahmen. Im ReAct-Modus durchläuft es nativ Denk-, Handlungs- und Beobachtungsschritte, wodurch aufwändiges Prompt Engineering umgangen wird. Für anspruchsvollere Aufgaben aktiviert der Heavy-Modus das IterResearch-Framework, das parallele Agenten-Explorationen orchestriert, um eine Kontextüberlastung zu vermeiden. Dadurch erzielen Benutzer in Szenarien, die eine iterative Verfeinerung erfordern, wie z. B. akademische Literaturrecherchen oder Marktanalysen, überlegene Ergebnisse.
Was Tongyi DeepResearch auszeichnet, ist sein Engagement für Offenheit. Der gesamte Stack – von den Modellgewichten bis zum Trainingscode – befindet sich auf Plattformen wie Hugging Face und GitHub. Entwickler greifen direkt auf die Variante Tongyi-DeepResearch-30B-A3B zu, was eine Feinabstimmung für domänenspezifische Anforderungen erleichtert. Darüber hinaus senkt die Kompatibilität mit Standard-Python-Umgebungen die Einstiegshürde. Die Installation erfordert beispielsweise einen einfachen Pip-Befehl nach dem Einrichten einer Conda-Umgebung mit Python 3.10.
Im Hinblick auf den praktischen Nutzen treibt Tongyi DeepResearch Anwendungen an, die überprüfbare Ergebnisse erfordern. In der juristischen Forschung analysiert es Gesetze und Fallrecht und zitiert Quellen präzise. Ähnlich erstellt es bei der Reiseplanung mehrtägige Reiserouten, indem es Echtzeitdaten abgleicht. Diese Fähigkeiten resultieren aus einer bewussten Designphilosophie: Agenten-basiertes Denken hat Vorrang vor bloßer Vorhersage.
Die Architektur von Tongyi DeepResearch: Effizienz trifft Leistung
Im Kern nutzt Tongyi DeepResearch ein spärliches MoE-Design, um Rechenanforderungen mit Ausdruckskraft in Einklang zu bringen. Das Modell aktiviert nur eine Untergruppe von Experten pro Token und leitet Eingaben dynamisch basierend auf der Komplexität der Abfrage weiter. Dieser Ansatz reduziert die Latenz um bis zu 90 % im Vergleich zu dichten Gegenstücken, wodurch er für Echtzeit-Agenten-Bereitstellungen praktikabel ist. Darüber hinaus unterstützt das 128K-Kontextfenster erweiterte Interaktionen, die für Aufgaben mit langen Dokumentketten oder Thread-Websuchen entscheidend sind.
Zu den wichtigsten Architekturkomponenten gehören ein benutzerdefinierter Tokenizer, der für Agenten-Tokens – wie Aktionspräfixe und Beobachtungsbegrenzer – optimiert ist, sowie eine eingebettete Tool-Suite für Browser-Navigation, Abruf und Berechnung. Das Framework unterstützt die Integration von On-Policy Reinforcement Learning (RL), bei der Agenten aus simulierten Rollouts in einer stabilen Umgebung lernen. Folglich weist das Modell weniger Halluzinationen bei Tool-Aufrufen auf, wie seine hohen Bewertungen bei Tool-Nutzungs-Benchmarks belegen.
Darüber hinaus integriert Tongyi DeepResearch einen Entitäten-verankerten Wissensspeicher, der aus der graphenbasierten Datensynthese abgeleitet wird. Dieser Mechanismus verankert Antworten an faktische Entitäten und verbessert so die Nachvollziehbarkeit. Bei einer Abfrage zu Fortschritten in der Quantencomputerforschung ruft der Agent beispielsweise Papiere über WebSailor-ähnliche Tools ab und synthetisiert sie, wobei die Ausgaben auf überprüfbaren Quellen basieren. So verarbeitet die Architektur Informationen nicht nur, sondern kuratiert sie aktiv.
Zur Veranschaulichung betrachten Sie die Handhabung multimodaler Eingaben durch das Modell. Obwohl primär textbasiert, ermöglichen Erweiterungen über das GitHub-Repository die Integration mit Bildparsern oder Code-Executoren. Entwickler konfigurieren diese im Inferenzskript und geben Pfade für Datensätze im JSONL-Format an. Somit fördert die Architektur die Erweiterbarkeit und lädt Beiträge aus der Open-Source-Community ein.
Automatisierte Datensynthese: Die Fähigkeiten von Tongyi DeepResearch fördern
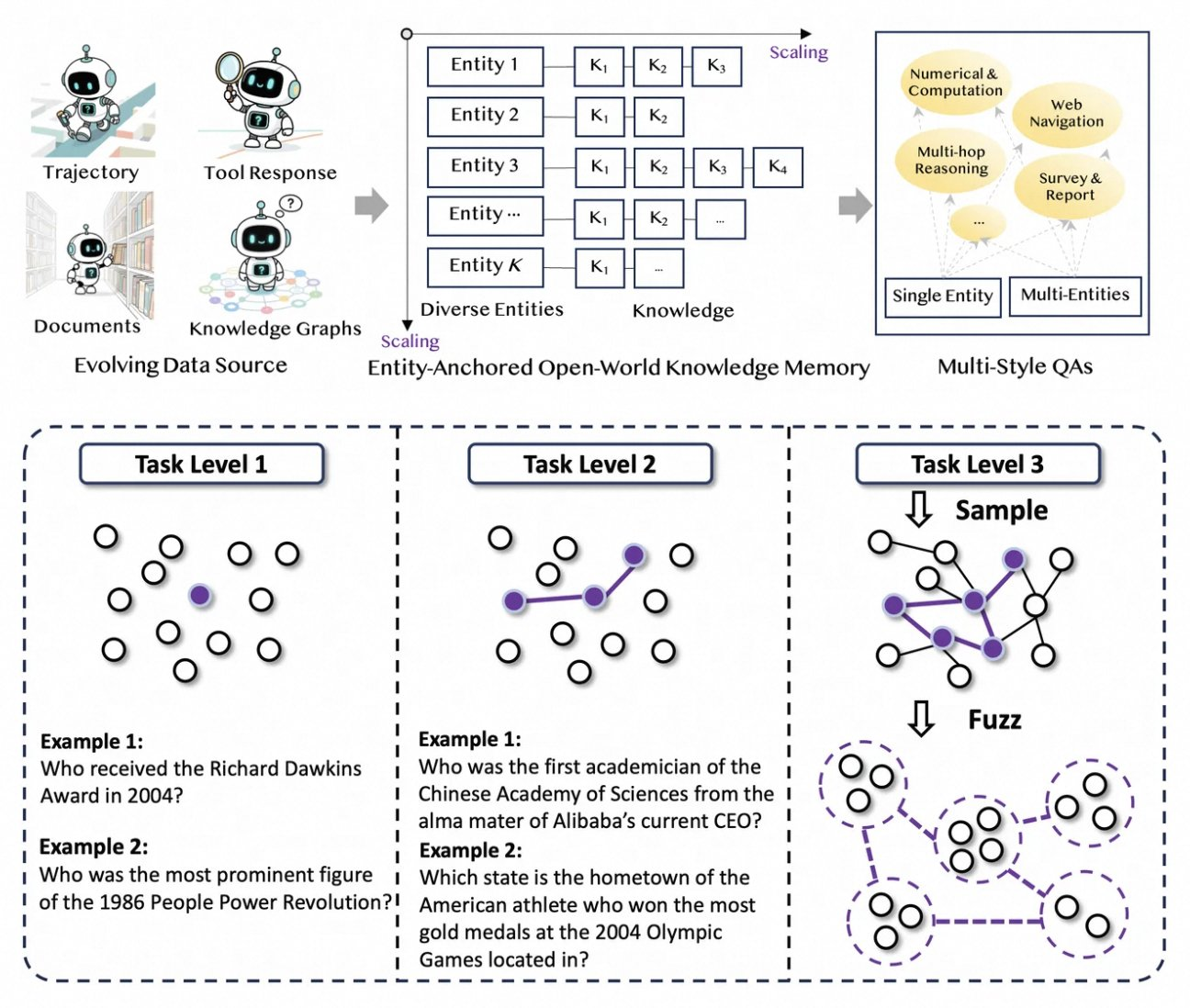
Tongyi DeepResearch lebt von einer neuartigen, vollständig automatisierten Datenpipeline, die Engpässe bei der menschlichen Annotation eliminiert. Der Prozess beginnt mit AgentFounder, einer Synthese-Engine, die Rohkorpora – Dokumente, Web-Crawls und Wissensgraphen – in entitätsverankerte QA-Paare umorganisiert. Dieser Schritt generiert vielfältige Trajektorien für das kontinuierliche Vortraining (CPT), die Schlussfolgerungsketten, Tool-Aufrufe und Entscheidungsbäume abdecken.
Als Nächstes steigert die Pipeline die Schwierigkeit durch iterative Upgrades. Für das Post-Training werden graphenbasierte Methoden wie WebSailor-V2 eingesetzt, um „übermenschliche“ Herausforderungen zu simulieren, wie z. B. Fragen auf PhD-Niveau, die über die Mengenlehre modelliert werden. Dadurch umfasst der Datensatz Millionen von hochpräzisen Interaktionen, die sicherstellen, dass das Modell über Domänen hinweg generalisiert. Bemerkenswert ist, dass diese Automatisierung linear mit der Rechenleistung skaliert, was kontinuierliche Updates ohne manuelle Kuration ermöglicht.
Darüber hinaus integriert Tongyi DeepResearch Multistyle-Daten für Robustheit. Aktionssynthese-Aufzeichnungen erfassen Tool-Nutzungsmuster, während mehrstufige QA-Paare die Planungsfähigkeiten verfeinern. In der Praxis führt dies zu Agenten, die sich an rauschende Web-Umgebungen anpassen und irrelevante Schnipsel effektiv filtern. Für Entwickler bietet das Repository Skripte zur Replikation dieser Pipeline, was die Erstellung benutzerdefinierter Datensätze ermöglicht.
Durch die Priorisierung von Qualität vor Quantität begegnet die Synthesestrategie häufigen Fallstricken im Agententraining, wie etwa Verteilungsverschiebungen. Folglich zeigen so trainierte Modelle eine überlegene Übereinstimmung mit realen Aufgaben, wie ihre Benchmark-Dominanz zeigt.
End-to-End Trainingspipeline: Von CPT zur RL-Optimierung
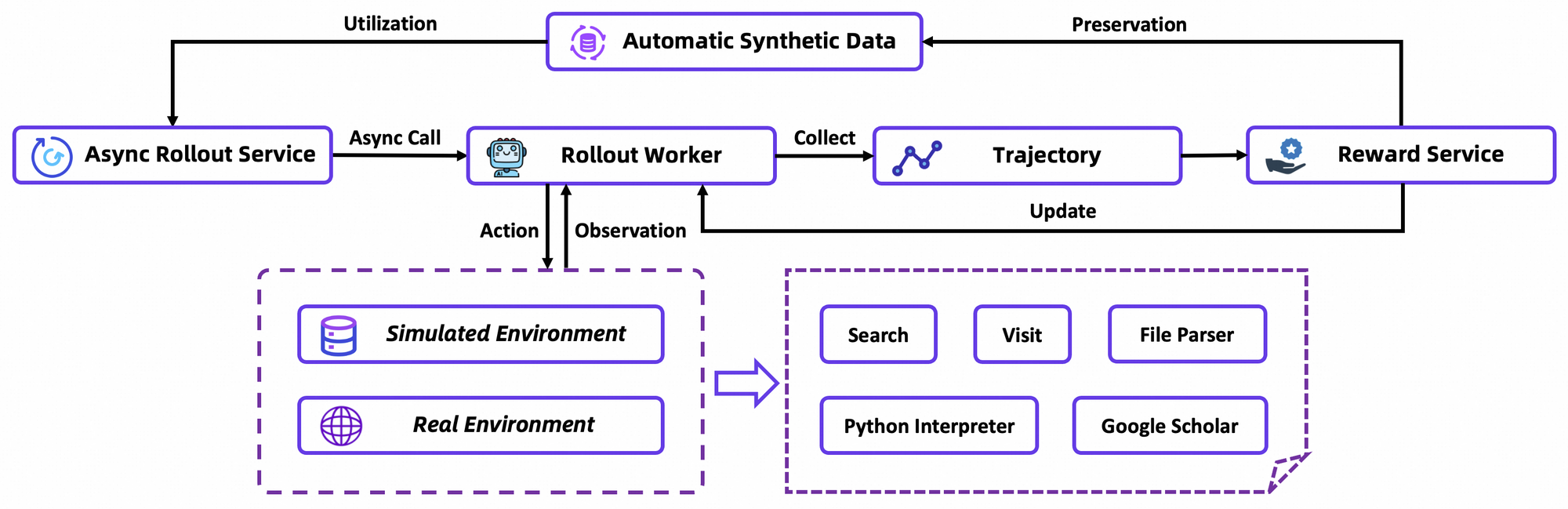
Das Training von Tongyi DeepResearch entfaltet sich in einer nahtlosen Pipeline: Agentic CPT, Supervised Fine-Tuning (SFT) und Reinforcement Learning (RL). Zuerst setzt CPT das Basismodell umfangreichen Agenten-Daten aus und versorgt es mit Web-Navigations-Priorisierungen und Aktualitätssignalen. Diese Phase aktiviert latente Fähigkeiten, wie implizite Planung, durch Masked Language Modeling auf Trajektorien.

Nach dem CPT richtet SFT das Modell an instruktionale Formate an, wobei synthetische Rollouts verwendet werden, um eine präzise Aktionsformulierung zu lehren. Hier lernt das Modell, kohärente ReAct-Zyklen zu generieren und Fehler bei der Beobachtungsanalyse zu minimieren. Nahtlos übergehend, verwendet die RL-Phase Group Relative Policy Optimization (GRPO), einen benutzerdefinierten On-Policy-Algorithmus.

GRPO berechnet token-basierte Policy-Gradienten mit Leave-One-Out-Vorteilsabschätzung, wodurch die Varianz in nicht-stationären Umgebungen reduziert wird. Es filtert auch negative Stichproben konservativ, was Updates im benutzerdefinierten Simulator – einer Offline-Wikipedia-Datenbank gepaart mit einer Tool-Sandbox – stabilisiert. Asynchrone Rollouts über das rLLM-Framework beschleunigen die Konvergenz und erreichen SOTA mit moderatem Rechenaufwand.
Im Detail simuliert die RL-Umgebung Browser-Interaktionen getreu und belohnt mehrstufigen Erfolg gegenüber einzelnen Aktionen. Dies fördert die langfristige Planung, bei der Agenten bei Teilerfolgen iterieren. Als technische Anmerkung enthält die Verlustfunktion eine KL-Divergenz für Konservatismus, um einen Moduskollaps zu verhindern. Entwickler replizieren dies über die Evaluierungsskripte des Repositories und benchmarken benutzerdefinierte Policies.
Insgesamt stellt diese Pipeline einen Durchbruch dar: Sie verbindet das Vortraining mit der Bereitstellung ohne Silos und liefert Agenten, die sich durch Versuch und Irrtum weiterentwickeln.
Benchmark-Leistung: Wie Tongyi DeepResearch überzeugt
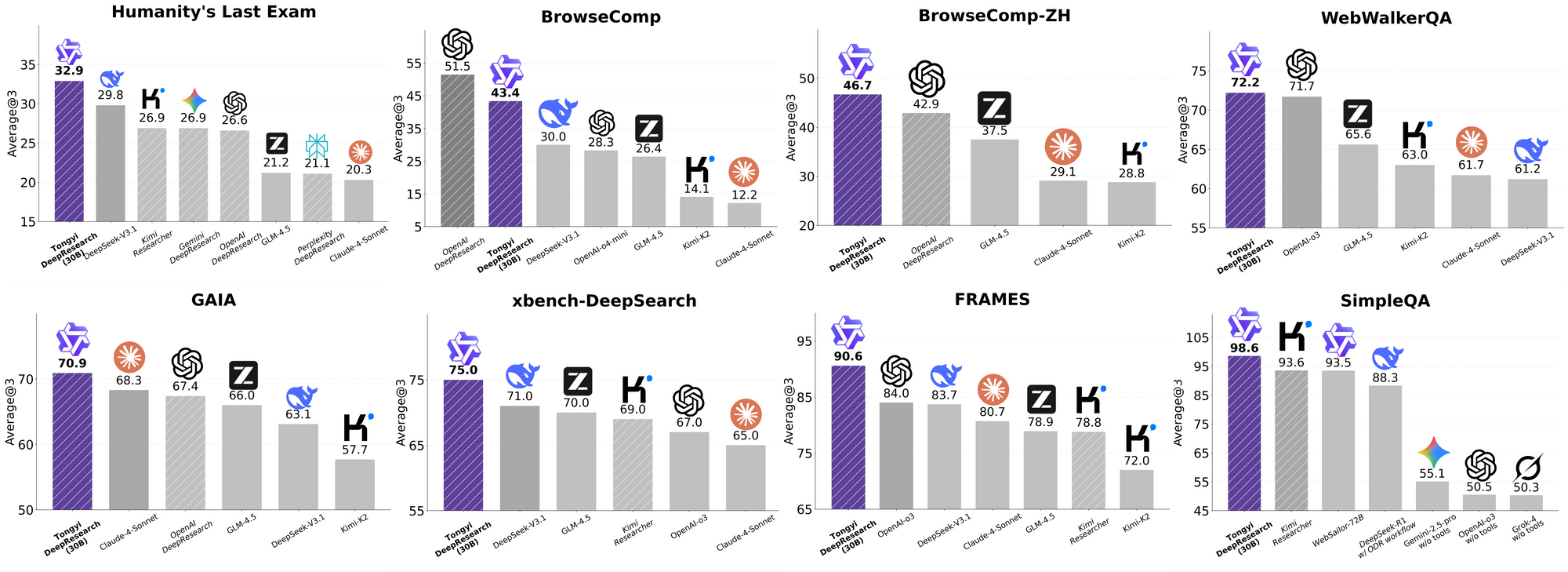
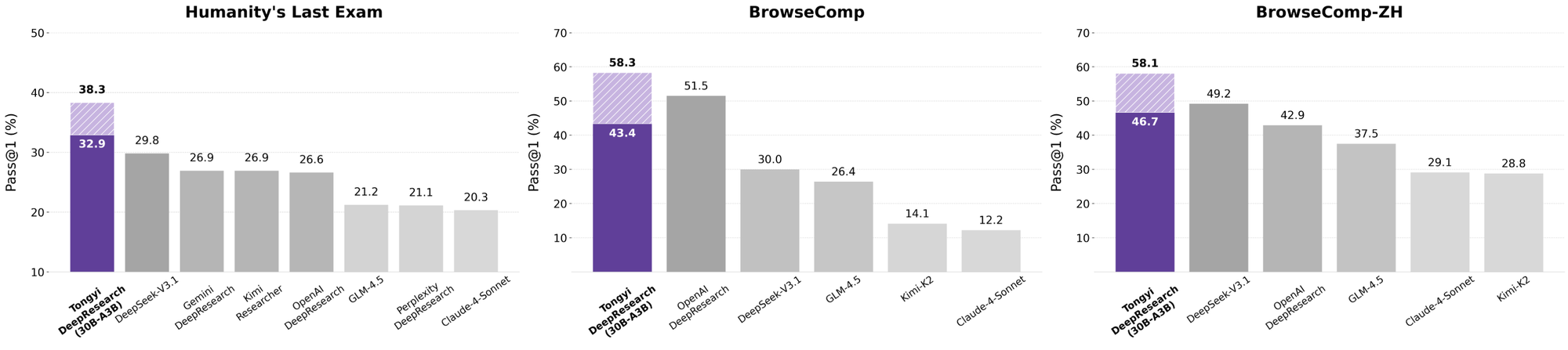
Tongyi DeepResearch glänzt in strengen Agenten-Benchmarks und bestätigt sein Design. Beim Humanity's Last Exam (HLE), einem Test des akademischen Denkens, erreicht es im ReAct-Modus 32,9 – und übertrifft damit OpenAIs o3 mit 24,9. Dieser Abstand vergrößert sich im Heavy-Modus auf 38,3, was die Wirksamkeit von IterResearch unterstreicht.
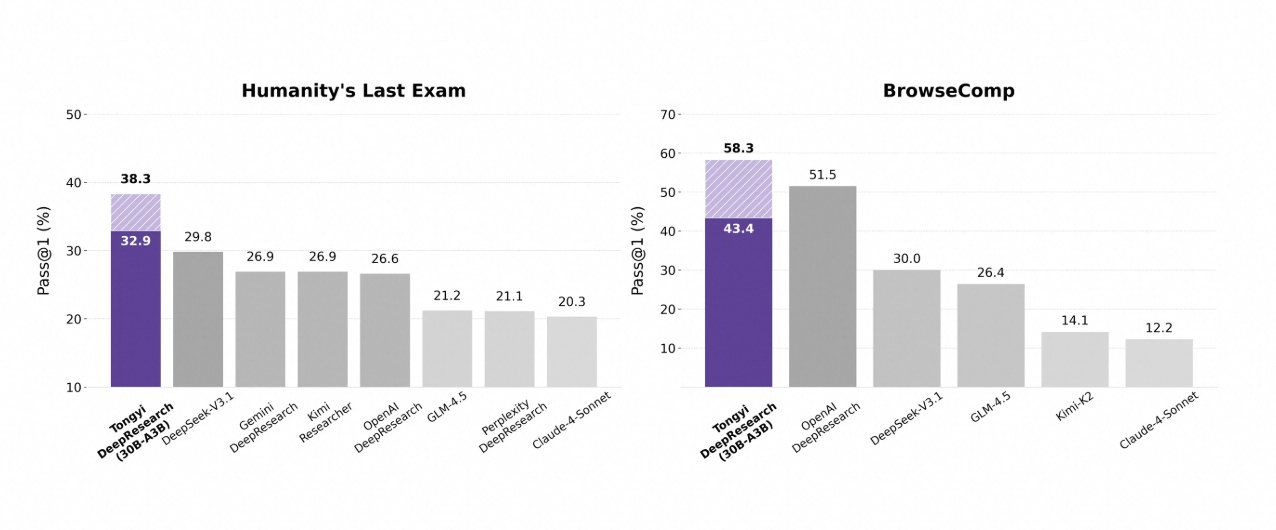
Ähnlich bewertet BrowseComp komplexe Informationssuche; Tongyi erreicht 43,4 (EN) und 46,7 (ZH), übertrifft o3s 49,7 bzw. 58,1 in der Effizienz. Der xbench-DeepSearch-Benchmark, benutzerzentriert für tiefe Abfragen, sieht Tongyi bei 75,0 gegenüber o3s 67,0, was die überlegene Abrufsynthese unterstreicht.
Weitere Metriken bestätigen dies: FRAMES bei 90,6 (vs. o3s 84,0), GAIA bei 70,9 und SimpleQA bei 95,0. Eine Vergleichstabelle visualisiert diese, wobei die Balken für Tongyi DeepResearch über Gemini, Claude und andere bei HLE, BrowseComp, xbench, FRAMES und mehr ragen. Blaue Balken zeigen Tongyis Führung, graue Basislinien zeigen die Defizite der Konkurrenten.
Diese Ergebnisse resultieren aus gezielten Optimierungen, wie der selektiven Expertenweiterleitung für Suchaufgaben. Somit konkurriert Tongyi DeepResearch nicht nur, sondern führt im Bereich der Open-Source-Agenten.
Tongyi DeepResearch im Vergleich zu Branchenführern
Wenn Entwickler KI-Agenten bewerten, zeigen Vergleiche den wahren Wert. Tongyi DeepResearch, mit 30B-A3B, übertrifft OpenAIs o3 in HLE (32,9 vs. 24,9) und xbench (75,0 vs. 67,0), trotz o3s größerem Umfang. Gegen Googles Gemini beansprucht es 35,2 bei BrowseComp-ZH, einen Vorsprung von 10 Punkten.
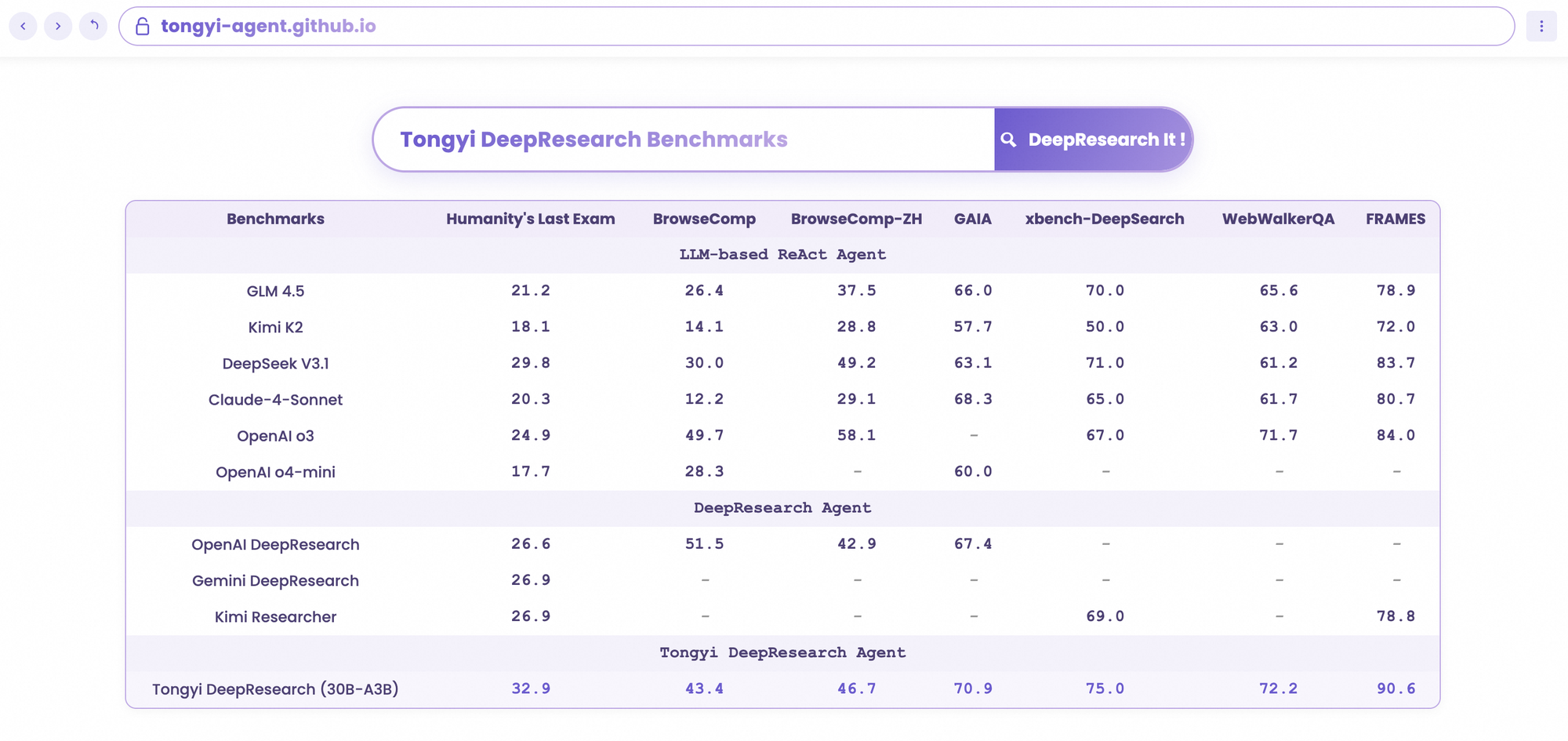
Proprietäre Modelle wie Claude 3.5 Sonnet hinken bei der Tool-Nutzung hinterher; Tongyis 90,6 bei FRAMES übertrifft Sonnets 84,3 deutlich. Open-Source-Konkurrenten, wie Llama-Varianten, liegen noch weiter zurück – z.B. 21,1 bei HLE. Tongyis MoE-Sparsität ermöglicht diese Gleichheit, da es weniger Inferenzrechenleistung verbraucht.
Darüber hinaus kippt die Zugänglichkeit die Waage: Während o3 API-Credits erfordert, läuft Tongyi lokal über Hugging Face. Für API-intensive Workflows koppeln Sie es mit Apidog, um Endpunkte zu simulieren und Tool-Aufrufe effizient zu testen.
Im Wesentlichen demokratisiert Tongyi DeepResearch Spitzenleistung und fordert geschlossene Ökosysteme heraus.
Reale Anwendungen: Tongyi DeepResearch in Aktion
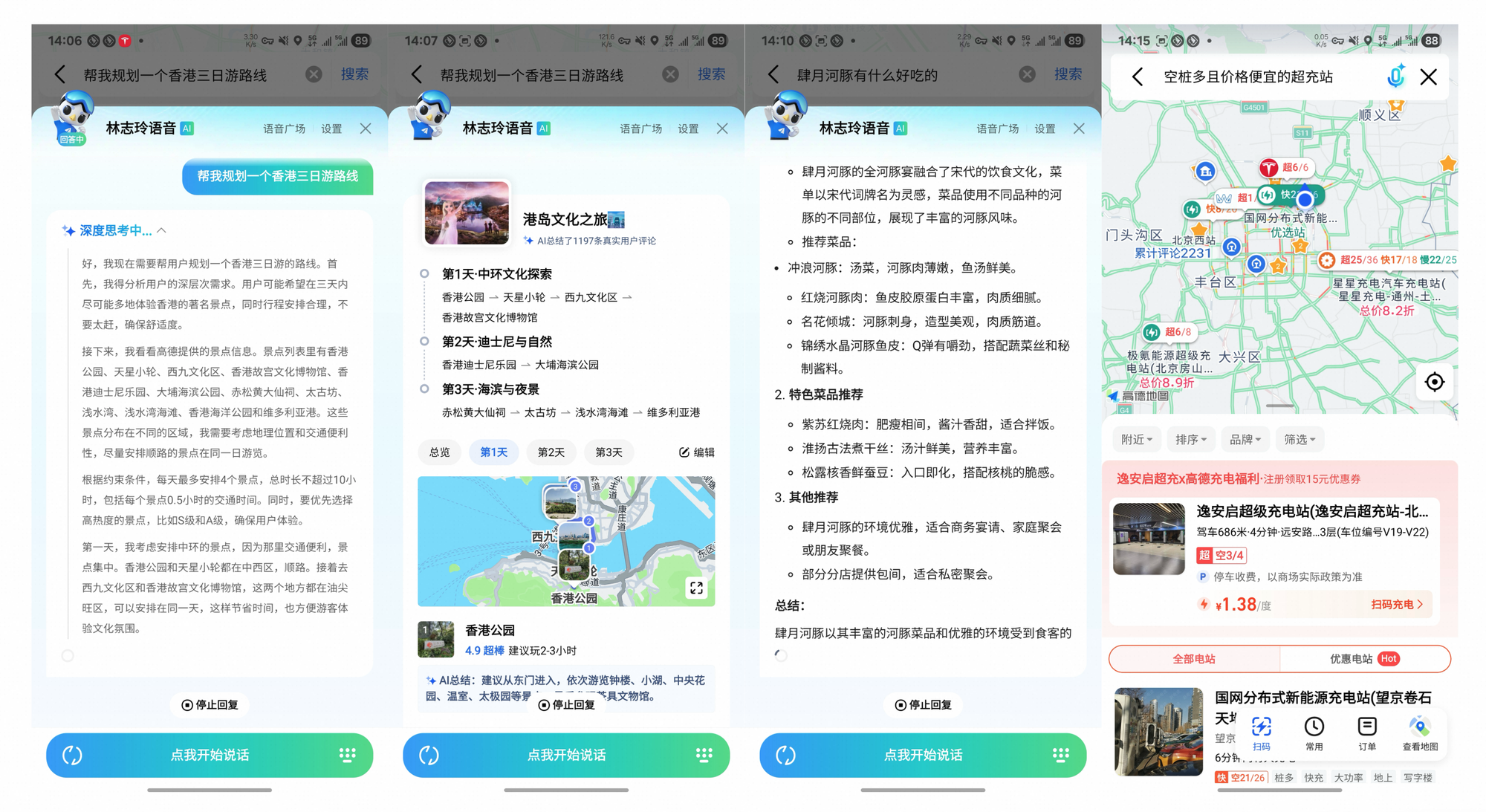
Tongyi DeepResearch geht über Benchmarks hinaus und erzielt greifbare Auswirkungen. In Gaode Mate, Alibabas Navigations-App, plant es komplexe Reisen – Flüge, Hotels und Veranstaltungen werden im Heavy-Modus parallel abgefragt. Benutzer erhalten synthetisierte Reiserouten mit Zitaten, was die Planungszeit um 70 % reduziert.
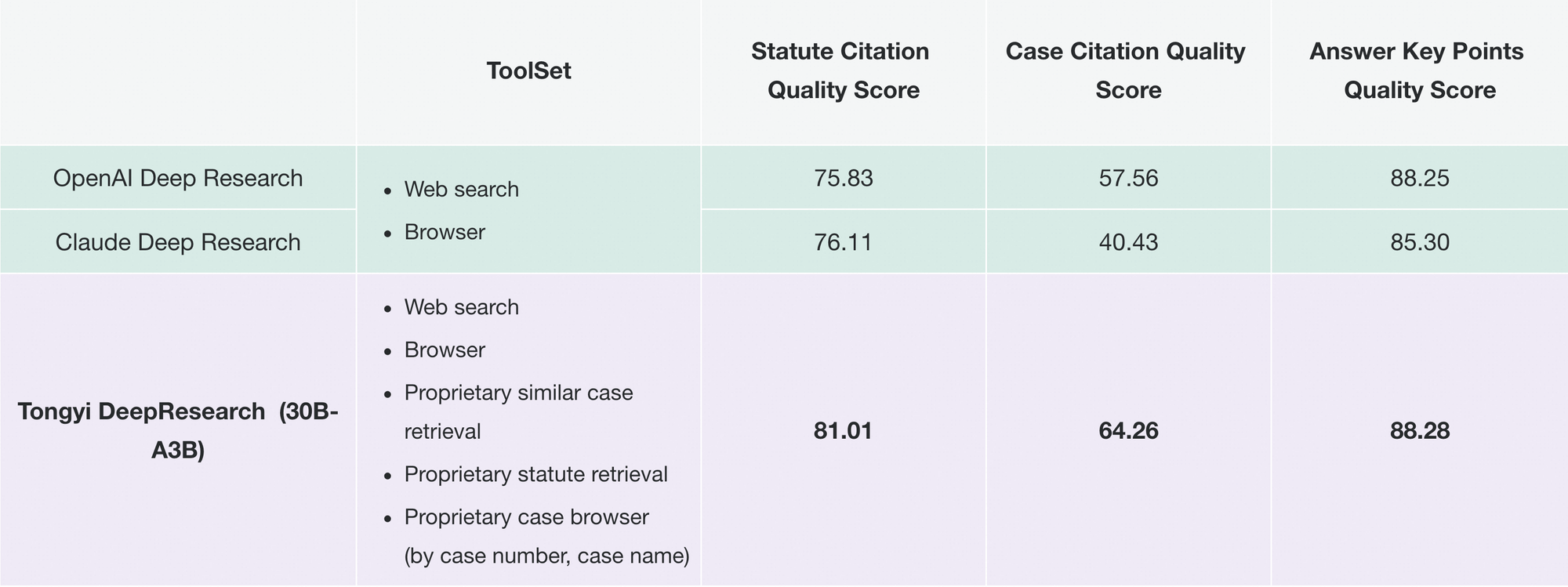
Ebenso revolutioniert Tongyi FaRui die juristische Forschung. Der Agent analysiert Gesetze, gleicht Präzedenzfälle ab und erstellt Schriftsätze mit überprüfbaren Links. Fachleute überprüfen die Ergebnisse schnell und minimieren Fehler in kritischen Bereichen.
Darüber hinaus adaptieren Unternehmen es für Marktanalysen: Wettbewerbsdaten werden gescrapt, Trends synthetisiert. Die Modularität des Repositories unterstützt solche Erweiterungen – fügen Sie benutzerdefinierte Tools über JSON-Konfigurationen hinzu.
Mit zunehmender Akzeptanz integriert sich Tongyi DeepResearch in Ökosysteme wie LangChain und verstärkt Agentenschwärme. Für API-Entwickler ergänzt Apidog dies, indem es Integrationen vor der Bereitstellung validiert.
Diese Fälle demonstrieren Skalierbarkeit: Von Consumer-Apps bis zu B2B-Tools liefert das Modell zuverlässige Autonomie.
Erste Schritte mit Tongyi DeepResearch: Ein Entwicklerhandbuch
Implementieren Sie Tongyi DeepResearch mühelos mit seinem GitHub-Repository. Beginnen Sie mit der Erstellung einer Conda-Umgebung: conda create -n deepresearch python=3.10. Aktivieren und installieren Sie: pip install -r requirements.txt.
Bereiten Sie Daten in eval_data/ als JSONL vor, mit den Schlüsseln question und answer. Für Dateien stellen Sie den Namen den Fragen voran und speichern sie in file_corpus/. Bearbeiten Sie run_react_infer.sh für den Modellpfad (z.B. Hugging Face URL) und API-Schlüssel für Tools.
Ausführen: bash run_react_infer.sh. Die Ausgaben landen in den angegebenen Pfaden und sind bereit zur Analyse.
Für den Heavy-Modus konfigurieren Sie IterResearch-Parameter im Code – legen Sie die Agentenanzahl und Runden fest. Benchmarken Sie über die Skripte in evaluation/ und vergleichen Sie mit Baselines.
Beheben Sie Probleme mit Protokollen; häufige Probleme wie Tokenizer-Diskrepanzen werden durch BF16-Tensor-Prüfungen behoben. Um die Leistung zu verbessern, laden Sie Apidog kostenlos herunter, um API-Simulationen durchzuführen und Tool-Endpunkte ohne Live-Aufrufe zu testen.
Diese Einrichtung ermöglicht es Ihnen, Agenten schnell zu prototypisieren.
Zukünftige Richtungen: Tongyi DeepResearch weiter skalieren
Mit Blick auf die Zukunft zielt das Tongyi Lab auf eine Kontextausweitung über 128K hinaus ab, um ultra-lange Horizonte wie buchumfassende Analysen zu ermöglichen. Sie planen die Validierung auf größeren MoE-Basen, um Skalierbarkeitsgrenzen zu untersuchen.
RL-Verbesserungen umfassen partielle Rollouts für Effizienz und Off-Policy-Methoden zur Minderung von Verschiebungen. Community-Beiträge könnten Vision- oder mehrsprachige Tools integrieren und den Umfang erweitern.
Während sich Open-Source weiterentwickelt, wird Tongyi DeepResearch als Anker für kollaborative Fortschritte dienen und die AGI-Bestrebungen fördern.
Fazit: Die Ära von Tongyi DeepResearch begrüßen
Tongyi DeepResearch transformiert die Agenten-KI und vereint Effizienz, Offenheit und Leistungsfähigkeit. Seine Benchmarks, Architektur und Anwendungen positionieren es als führendes Unternehmen, das Konkurrenten wie die Angebote von OpenAI übertrifft. Entwickler, nutzen Sie diese Leistung – laden Sie das Modell herunter, experimentieren Sie und integrieren Sie es mit Apidog für nahtlose APIs.
In einem Bereich, der auf Autonomie zusteuert, beschleunigt Tongyi DeepResearch den Fortschritt. Beginnen Sie noch heute mit dem Aufbau; die Erkenntnisse warten.