
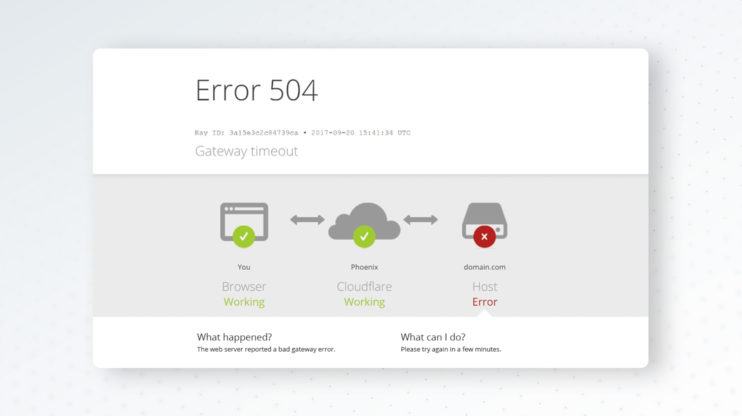
Sie surfen auf einer Website, und anstatt dass die Seite geladen wird, starren Sie auf eine Meldung mit der Aufschrift "504 Gateway Timeout". Der Ladekreis dreht sich gefühlt ewig. Sie aktualisieren die Seite, aber derselbe Fehler erscheint. Die Website ist technisch gesehen nicht "down", aber etwas in ihrer Infrastruktur hat aufgegeben, auf eine Antwort zu warten.
Dieses frustrierende Erlebnis wird durch einen der häufigsten serverseitigen Fehler im modernen Web verursacht: den Statuscode 504 Gateway Timeout.
Im Gegensatz zu Client-Fehlern wie 404 Not Found, die meistens die "Schuld" des Benutzers sind, oder Server-Fehlern wie 500 Internal Server Error, die innerhalb der Anwendung auftreten, ist der 504 ein Kommunikationsausfall zwischen Servern. Es ist das digitale Äquivalent eines Vermittlers, der die Hände über dem Kopf zusammenschlägt und sagt: "Ich habe zu lange auf die Person gewartet, mit der Sie wirklich sprechen möchten, und ich gebe auf."
Aber was genau ist der HTTP-Statuscode 504: Gateway Timeout, und warum tritt er auf? Noch wichtiger ist, wie Sie ihn beheben oder verhindern können, dass er in Ihrer App, API oder Website angezeigt wird?
Wenn Sie Entwickler, Systemadministrator oder einfach nur ein neugieriger Webnutzer sind, ist es unglaublich wertvoll zu verstehen, was einen 504-Fehler verursacht und wie man ihn behebt.
Wir werden all das im Detail behandeln, von der Bedeutung dieses Codes über häufige Ursachen bis hin zu praktischen Lösungen.
Lassen Sie uns nun untersuchen, was hinter den Kulissen passiert, wenn Sie einen 504 Gateway Timeout erhalten.
Die moderne Web-Architektur: Es ist nie nur ein Server
Um 504 zu verstehen, müssen wir verstehen, wie moderne Websites und Anwendungen aufgebaut sind. Nur noch sehr wenige Anwendungen laufen auf einem einzigen Server. Die meisten verwenden eine mehrschichtige Architektur, die etwa so aussieht:
- Browser des Benutzers: Stellt die ursprüngliche Anfrage.
- Load Balancer / Reverse Proxy: Verteilt den Datenverkehr auf mehrere Backend-Server (z.B. NGINX, HAProxy, AWS ALB).
- Web-/Anwendungsserver: Führen den eigentlichen Anwendungscode aus (z.B. Node.js, Python/Django, PHP).
- Backend-Dienste / APIs: Bearbeiten spezifische Aufgaben wie Authentifizierung, Zahlungen oder Datenverarbeitung (oft Microservices).
- Datenbank / Cache: Speichern und Abrufen von Daten.
Der 504-Fehler tritt typischerweise zwischen Schritt 2 und 3 oder zwischen Schritt 3 und 4 auf. Das "Gateway" in "Gateway Timeout" bezieht sich auf den Server, der als Vermittler fungiert – den Load Balancer oder Reverse Proxy.
Was bedeutet HTTP 504 Gateway Timeout wirklich?
Der Statuscode 504 Gateway Timeout zeigt an, dass ein Server, der als Gateway oder Proxy fungiert, keine rechtzeitige Antwort von einem Upstream-Server erhalten hat, auf den er zugreifen musste, um die Anfrage abzuschließen.
Einfacher ausgedrückt: "Ich (das Gateway) habe einen anderen Server um Hilfe gebeten, aber dieser Server hat zu lange gebraucht, um mir zu antworten, also gebe ich auf und sage Ihnen, dass es ein Problem gibt."
Eine typische 504-Antwort ist ziemlich minimalistisch:
HTTP/1.1 504 Gateway TimeoutContent-Type: text/htmlContent-Length: 125
<html><head><title>504 Gateway Timeout</title></head><body><center><h1>504 Gateway Timeout</h1></center></body></html>
Im Gegensatz zu einigen anderen Fehlern gibt es normalerweise keinen benutzerdefinierten Body, da das Gateway selbst oft ein einfaches Stück Infrastruktur ist, das keine ausgefallenen Fehlerseiten generieren kann.
Stellen Sie es sich so vor:
Sie bitten Ihren Freund zu prüfen, ob ein Restaurant geöffnet ist. Ihr Freund ruft das Restaurant an, aber niemand nimmt ab. Nach einer Weile sagt Ihr Freund Ihnen:
„Entschuldigung, sie haben nicht geantwortet – ich habe einen Timeout bekommen.“
Genau das passiert bei einem 504 Gateway Timeout.
Das Gateway (normalerweise ein Reverse Proxy wie NGINX oder ein Load Balancer) versucht, sich mit einem Upstream-Server (wie Ihrer Web-App oder Datenbank) zu verbinden. Wenn dieser Upstream-Server zu lange braucht, um zu antworten, wirft das Gateway einen 504 und bricht die Anfrage ab.
Die Verantwortungskette: Wie ein 504 entsteht
Gehen wir ein konkretes Beispiel anhand einer gängigen E-Commerce-Architektur durch.
1. Die Anfrage: Ein Benutzer sucht nach einem Produkt. Sein Browser sendet eine Anfrage an https://shop.example.com/search?q=laptop.
2. Die Rolle des Load Balancers: Die Anfrage trifft zuerst auf einen Load Balancer (das Gateway). Die Aufgabe des Load Balancers ist es, diese Anfrage an einen von mehreren verfügbaren Anwendungsservern weiterzuleiten. Der Load Balancer hat eine Timeout-Einstellung von, sagen wir, 30 Sekunden.
3. Die Aufgabe des Anwendungsservers: Der Anwendungsserver empfängt die Anfrage. Um sie zu erfüllen, muss er zwei weitere Dienste aufrufen:
- Er ruft den Suchdienst auf, um Produktergebnisse zu erhalten.
- Er ruft den Benutzerprofildienst auf, um personalisierte Empfehlungen zu erhalten.
4. Das Problem: Der Benutzerprofildienst hat eine hohe Auslastung oder einen Datenbank-Deadlock. Er bleibt hängen und antwortet nicht.
5. Der Timeout: Der Anwendungsserver wartet... 25 Sekunden... 28 Sekunden... 29 Sekunden... Der Load Balancer, der immer noch auf eine Antwort vom Anwendungsserver wartet, erreicht seine 30-Sekunden-Timeout-Grenze.
6. Die 504-Antwort: Der Load Balancer gibt auf. Er kann die Suchergebnisse nicht zurückgeben, da er sie nie vom Anwendungsserver erhalten hat. Daher gibt er einen 504 Gateway Timeout an den Browser des Benutzers zurück.
Die entscheidende Erkenntnis hier ist, dass der Anwendungsserver möglicherweise noch arbeitet und versucht, eine Antwort vom Benutzerprofildienst zu erhalten. Aber der Load Balancer hat die Anfrage aus seiner Sicht bereits abgebrochen.
Wann ein 504 zu erwarten ist
504er sind am häufigsten in Szenarien, in denen:
- Ihre Anwendung auf mehrere nachgelagerte Dienste oder Microservices angewiesen ist.
- Der Upstream-Dienst aufgrund von Wartungsarbeiten oder hoher Last vorübergehend nicht verfügbar ist.
- Eine Drittanbieter-API oder -Datenbank langsam oder nicht reagiert.
- Netzwerkpfade vorübergehende Latenz oder Paketverluste aufweisen.
Da 504 normalerweise vorübergehend ist, kommen oft Wiederholungsstrategien und Circuit Breaker als Teil eines robusten Resilienzplans zum Einsatz.
Wann ein 504 akzeptabel sein könnte
Es gibt legitime Fälle, in denen ein Gateway-Timeout erwartet oder akzeptabel ist:
- Wartungsfenster, in denen Upstream-Dienste absichtlich verlangsamt oder offline sind.
- Temporäre Verkehrsspitzen, die Upstream-Dienste nicht sofort absorbieren können.
- Sporadische Abhängigkeitsprobleme, die zurückgerollt oder gemildert werden.
In diesen Fällen tragen transparente Kommunikation und gut durchdachte Wiederholungsrichtlinien dazu bei, die Auswirkungen auf die Benutzer zu minimieren.
Praxisbeispiel eines 504 Gateway Timeout
Stellen Sie sich vor, Sie bauen eine E-Commerce-Website. Ihr Checkout-Prozess ruft mehrere APIs auf: Zahlung, Inventar, Versand und Benutzerauthentifizierung.
Wenn nun die Zahlungs-API plötzlich langsamer wird oder nicht verfügbar ist, wartet Ihr Server (der als Gateway fungiert) auf eine Antwort. Wenn er innerhalb des Timeout-Limits (sagen wir, 30 Sekunden) keine erhält, wirft er:
504 Gateway Timeout
Für Benutzer sieht es so aus, als wäre Ihre Website kaputt. Technisch gesehen liegt das Problem jedoch in der Kommunikationskette zwischen den Diensten.
504 vs. andere 5xx-Fehler: Den Unterschied kennen
Es ist leicht, Serverfehler zu verwechseln, aber jeder erzählt eine andere Geschichte darüber, was schiefgelaufen ist.
504 Gateway Timeout vs. 502 Bad Gateway:
504bedeutet: "Der Upstream-Server hat zu lange gebraucht, um zu antworten." (Timeout-Problem)502bedeutet: "Der Upstream-Server hat mir etwas Ungültiges oder Müll zurückgeschickt." (Die Antwort war fehlerhaft, oder die Verbindung wurde vollständig verweigert).
504 Gateway Timeout vs. 500 Internal Server Error:
504tritt auf der Infrastrukturebene zwischen Servern auf.500tritt auf der Anwendungsebene innerhalb Ihres Codes auf (z.B. eine unbehandelte Ausnahme in Ihrem Python- oder JavaScript-Code).
504 Gateway Timeout vs. 408 Request Timeout:
504ist ein serverseitiger Timeout: ein Gateway hat zu lange gewartet, bis ein anderer Server antwortet.408ist ein clientseitiger Timeout: ein Server hat zu lange gewartet, bis der Client die vollständige Anfrage sendet.
Häufige Ursachen für 504 Gateway Timeout
Das Verständnis der Ursachen ist der erste Schritt zur Vorbeugung und Behebung.
1. Überlastete Backend-Server
Dies ist die häufigste Ursache. Ihre Anwendungsserver könnten unter starker Last stehen, was dazu führt, dass sie langsam oder gar nicht reagieren. Dies könnte folgende Ursachen haben:
- Ein Verkehrsspitzenwert
- Ineffiziente Datenbankabfragen
- Unzureichende Serverressourcen (CPU, RAM)
2. Netzwerkprobleme
Konnektivitätsprobleme zwischen Ihrem Gateway und Ihren Backend-Servern können Timeouts verursachen.
- Netzwerküberlastung
- Firewall-Regeln, die den Datenverkehr blockieren
- DNS-Auflösungsprobleme
3. Ressourcenintensive Operationen
Einige Operationen dauern naturgemäß lange:
- Erstellen komplexer Berichte
- Verarbeiten großer Dateiuploads
- Ausführen von Machine-Learning-Inferenz
Wenn diese Operationen den Timeout-Schwellenwert Ihres Gateways überschreiten, verursachen sie 504-Fehler.
4. Dienstabhängigkeiten
Wenn Ihre Anwendung von externen APIs oder Microservices abhängt, die langsam oder ausgefallen sind, wartet Ihr Anwendungsserver auf diese, was möglicherweise den Gateway-Timeout auslöst.
5. Falsch konfigurierte Timeouts
Manchmal sind die Timeouts einfach zu niedrig eingestellt. Ein Gateway könnte einen 10-Sekunden-Timeout haben, aber eine legitime komplexe Operation könnte 15 Sekunden dauern.
APIs testen und debuggen mit Apidog
Die Grundursache für intermittierende 504-Fehler zu identifizieren, kann wie die Suche nach der Nadel im Heuhaufen sein. Beim Debuggen von 504ern haben Entwickler oft Schwierigkeiten mit der Transparenz – herauszufinden, welcher Server, Dienst oder welche Anfrage schuld ist. Apidog bietet mehrere Funktionen, die dies erheblich erleichtern.
Mit Apidog können Sie:
- Leistungstests: Verwenden Sie Apidog, um mehrere gleichzeitige Anfragen an Ihre API zu senden und die Antwortzeiten zu messen. Dies kann Ihnen helfen zu identifizieren, ob bestimmte Endpunkte unter Last langsam sind, was zu 504ern führen könnte.
- Überwachung einrichten: Erstellen Sie automatisierte Monitore in Apidog, die Ihre Endpunkte regelmäßig überprüfen. Wenn eine Anfrage länger dauert als ein von Ihnen festgelegter Schwellenwert (z.B. 25 Sekunden, wenn Ihr Gateway-Timeout 30 beträgt), kann Apidog Sie alarmieren, bevor Benutzer 504er sehen.
- Dienstabhängigkeiten testen: Wenn Ihre API andere Dienste aufruft, verwenden Sie Apidog, um diese Abhängigkeiten unabhängig zu testen. Dies hilft Ihnen zu isolieren, ob das Problem in Ihrer Anwendung oder in einem nachgelagerten Dienst liegt.
- Langsame Antworten simulieren: Verwenden Sie die Mock-Server von Apidog, um langsame Backend-Antworten zu simulieren. So können Sie testen, wie Ihr Gateway und Ihre Anwendung Timeouts handhaben, ohne Ihr Produktionssystem tatsächlich zu überlasten.
- Timeout-Erwartungen dokumentieren: Verwenden Sie die Dokumentationsfunktionen von Apidog, um zu vermerken, welche Endpunkte voraussichtlich langwierig sind, und helfen Sie Ihrem Team so, geeignete Timeout-Werte in der Infrastruktur festzulegen.
Und ja, Sie können Apidog kostenlos herunterladen. Es ist nicht nur eine weitere Postman-Alternative, sondern ein vollständiges Ökosystem für API-Design, -Tests und Leistungsüberwachung.
Fehlerbehebung und Behebung von 504-Fehlern
Sofortmaßnahmen:
- Serverressourcen prüfen: Überprüfen Sie CPU, Speicher und Festplatten-I/O auf Ihren Anwendungsservern.
- Protokolle überprüfen: Überprüfen Sie Ihre Anwendungs- und Gateway-Protokolle auf Fehler zum Zeitpunkt des Auftretens der 504er.
- Externe Abhängigkeiten überprüfen: Stellen Sie sicher, dass alle Drittanbieter-APIs oder -Dienste, die Ihre Anwendung verwendet, fehlerfrei sind.
Langfristige Lösungen:
- Anwendungsleistung optimieren: Langsame Datenbankabfragen identifizieren und beheben, Code optimieren und Caching implementieren.
- Timeout-Einstellungen anpassen: Erhöhen Sie die Timeout-Werte auf Ihrem Gateway, wenn Sie legitime langwierige Operationen haben.
- Circuit Breaker implementieren: Verwenden Sie Muster, die nach mehreren Fehlern das Aufrufen eines fehlerhaften Dienstes einstellen, um kaskadierende Timeouts zu verhindern.
- Infrastruktur skalieren: Fügen Sie weitere Anwendungsserver hinzu oder rüsten Sie auf leistungsfähigere Instanzen auf.
- Asynchrone Verarbeitung implementieren: Verwenden Sie für langwierige Aufgaben eine Job-Warteschlange (wie Redis Queue oder AWS SQS) und kehren Sie sofort mit einem
202 Acceptedzurück, und benachrichtigen Sie den Benutzer dann, wenn die Aufgabe abgeschlossen ist.
Best Practices zur langfristigen Vermeidung von 504-Fehlern
Lassen Sie uns den technischen Teil mit einigen präventiven Strategien abschließen, die Ihnen zukünftige Kopfschmerzen ersparen werden.
1. Caching wo immer möglich einsetzen
Das Caching von Antworten (auf App-, CDN- oder Proxy-Ebene) reduziert die Backend-Last und die Antwortzeit.
2. Datenbankabfragen optimieren
Schlecht optimierte SQL-Abfragen verursachen oft Backend-Engpässe – optimieren Sie Indizes und vermeiden Sie große Joins.
3. API-Zustand überwachen
Verwenden Sie Tools wie Apidog, Datadog oder Pingdom, um die API-Verfügbarkeit und -Leistung kontinuierlich zu überwachen.
4. Circuit Breaker implementieren
Fügen Sie ein Circuit-Breaker-Muster in Ihre API ein, um Anfragen an fehlerhafte Dienste vorübergehend zu stoppen.
5. Automatisch skalieren
Verwenden Sie Auto-Scaling in Cloud-Umgebungen wie AWS oder Azure, um plötzliche Verkehrsspitzen zu bewältigen.
6. Alles protokollieren
Eine zentralisierte Protokollierung hilft Ihnen, langsame Endpunkte zu erkennen, bevor sie zu vollständigen Ausfällen führen.
Die menschliche Seite: Kommunikation bei Ausfällen
Transparente Kommunikation bei Gateway-Timeouts ist wichtig. Informieren Sie Benutzer, wenn ein Dienst Verzögerungen aufweist, bieten Sie nach Möglichkeit eine erwartete Wiederherstellungszeit an und stellen Sie Statusaktualisierungen bereit. Ein gut verwalteter Incident-Response-Plan reduziert die Benutzer frustration und schafft Vertrauen.
Architekturmuster zur Minderung von Gateway-Problemen
- Service Mesh mit Timeout-Richtlinien: Zentralisieren Sie Timeout-Konfigurationen und Fehlerbehandlung.
- Timeouts pro Hop: Konfigurieren Sie geeignete Timeouts an jedem Hop in der Anfragekette, um lange Wartezeiten zu vermeiden.
- Gegendruck und Warteschlangen: Puffern Sie Anfragen bei Überlastung, um Spitzen abzufedern.
- Canary Deployments: Führen Sie Änderungen schrittweise ein, um das Risiko weit verbreiteter Upstream-Verzögerungen zu reduzieren.
- Redundante Upstreams: Stellen Sie alternative Dienste bereit, um Single Points of Failure zu reduzieren.
Diese Muster helfen Ihnen, die Auswirkungen von Upstream-Verzögerungen einzudämmen und die Benutzererfahrung intakt zu halten.
Fazit: Der Preis verteilter Systeme
Der HTTP-Statuscode 504 Gateway Timeout ist eine natürliche Folge der modernen, verteilten Web-Architektur. Obwohl er für Benutzer frustrierend ist, erfüllt er einen wichtigen Zweck: Er verhindert, dass Anfragen unbegrenzt hängen bleiben, und stellt sicher, dass das Gesamtsystem reaktionsfähig bleibt.
Zu verstehen, dass ein 504 im Grunde ein Kommunikationsproblem zwischen Servern ist – und nicht unbedingt ein Anwendungsfehler – ist der Schlüssel zu einer effektiven Fehlerbehebung. Durch die Überwachung der Leistung, die Optimierung langsamer Operationen und die korrekte Konfiguration Ihrer Infrastruktur können Sie diese Fehler minimieren und Ihren Benutzern eine bessere Erfahrung bieten.
Wenn Sie das nächste Mal einen 504-Fehler sehen, wissen Sie, dass es die Geschichte eines geduldigen Gateway-Servers ist, der irgendwann das Warten aufgeben musste. Und wenn Sie Systeme entwickeln, die diese Timeouts vermeiden müssen, kann ein Tool wie Apidog Ihr bester Verbündeter sein, um Leistungsengpässe zu identifizieren und sicherzustellen, dass Ihre APIs rechtzeitig reagieren.