
Die Landschaft der großen Sprachmodelle (Large Language Models, LLMs) entwickelt sich rasant. Modelle werden leistungsfähiger, fähiger und, was wichtig ist, zugänglicher. Das Qwen-Team hat kürzlich Qwen3 vorgestellt, ihre neueste Generation von LLMs, die mit beeindruckender Leistung in verschiedenen Benchmarks aufwartet, darunter Programmierung, Mathematik und allgemeines Denken. Mit Flaggschiffmodellen wie dem Mixture-of-Experts (MoE) Qwen3-235B-A22B, das mit etablierten Giganten konkurriert, und sogar kleineren dichten Modellen wie Qwen3-4B, die mit Modellen der vorherigen Generation mit 72B Parametern konkurrieren, stellt Qwen3 einen bedeutenden Fortschritt dar.
Ein wichtiger Aspekt dieser Veröffentlichung ist die Open-Weighting mehrerer Modelle, darunter zwei MoE-Varianten (Qwen3-235B-A22B und Qwen3-30B-A3B) und sechs dichte Modelle mit einer Bandbreite von 0,6B bis 32B Parametern. Diese Offenheit lädt Entwickler, Forscher und Enthusiasten ein, diese leistungsstarken Werkzeuge zu erkunden, zu nutzen und darauf aufzubauen. Während Cloud-basierte APIs Komfort bieten, wächst der Wunsch, diese hochentwickelten Modelle lokal auszuführen, angetrieben von den Bedürfnissen nach Datenschutz, Kostenkontrolle, Anpassung und Offline-Zugänglichkeit.
Glücklicherweise hat sich das Tooling-Ökosystem für die lokale LLM-Ausführung erheblich weiterentwickelt. Zwei herausragende Plattformen, die diesen Prozess vereinfachen, sind Ollama und vLLM. Ollama bietet eine unglaublich benutzerfreundliche Möglichkeit, mit verschiedenen Modellen zu beginnen, während vLLM eine Hochleistungs-Serving-Lösung bietet, die für Durchsatz und Effizienz optimiert ist, insbesondere für größere Modelle. Dieser Artikel führt Sie durch das Verständnis von Qwen3 und die Einrichtung dieser leistungsstarken Modelle auf Ihrem lokalen Rechner mit Ollama und vLLM.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demans, and replaces Postman at a much more affordable price!
Was ist Qwen 3 und Benchmarks
Qwen3 repräsentiert die dritte Generation der großen Sprachmodelle (LLMs), die vom Qwen-Team entwickelt und im April 2025 veröffentlicht wurden. Diese Iteration steht für einen erheblichen Fortschritt gegenüber früheren Versionen und konzentriert sich auf verbesserte Denkfähigkeiten, Effizienz durch architektonische Innovationen wie Mixture-of-Experts (MoE), breitere mehrsprachige Unterstützung und verbesserte Leistung in einer Vielzahl von Benchmarks. Die Veröffentlichung umfasste die Open-Weighting mehrerer Modelle unter der Apache 2.0-Lizenz, wodurch die Zugänglichkeit für Forschung und Entwicklung gefördert wurde.
Qwen 3 Modellarchitektur und Varianten, erklärt
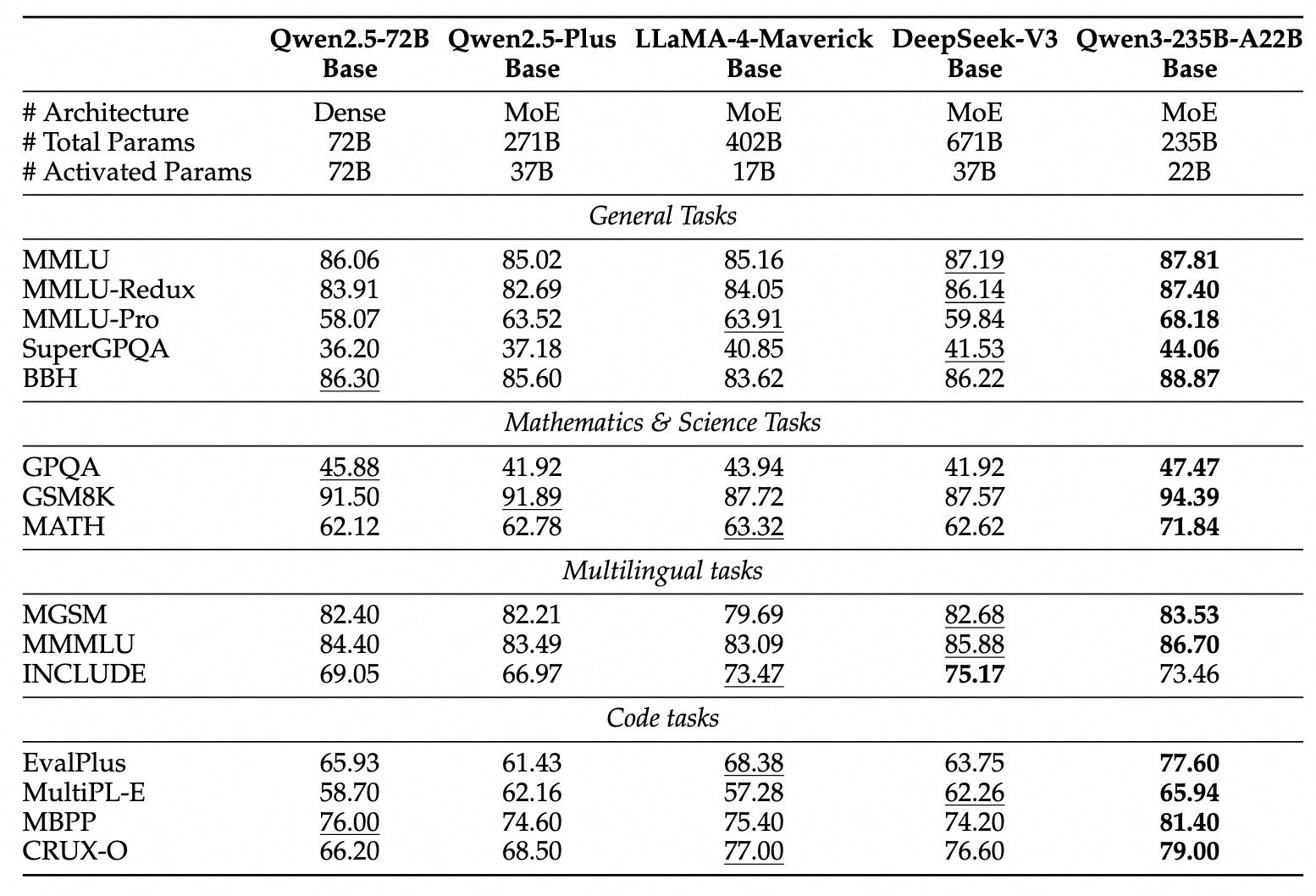
Die Qwen3-Familie umfasst sowohl traditionelle dichte Modelle als auch spärliche MoE-Architekturen, die auf unterschiedliche Rechenbudgets und Leistungsanforderungen zugeschnitten sind.
Dichte Modelle: Diese Modelle verwenden alle ihre Parameter während der Inferenz. Wichtige architektonische Details umfassen:
| Model | Layers | Attention Heads (Query / Key-Value) | Tie Word Embeddings | Max Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32,768 tokens (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32,768 tokens (32K) |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32,768 tokens (32K) |
| Qwen3-8B | 36 | 32 / 8 | No | 131,072 tokens (128K) |
| Qwen3-14B | 40 | 40 / 8 | No | 131,072 tokens (128K) |
| Qwen3-32B | 64 | 64 / 8 | No | 131,072 tokens (128K) |
Hinweis: Grouped-Query Attention (GQA) wird in allen Modellen verwendet, was durch die unterschiedliche Anzahl von Query- und Key-Value-Köpfen angezeigt wird.
Mixture-of-Experts (MoE) Modelle: Diese Modelle nutzen die Sparsity, indem sie während der Inferenz nur eine Teilmenge von "Expert"-Feed-Forward-Netzwerken (FFNs) für jedes Token aktivieren. Dies ermöglicht eine große Gesamtanzahl an Parametern, während die Rechenkosten näher an kleineren dichten Modellen gehalten werden.
| Model | Layers | Attention Heads (Query / Key-Value) | # Experts (Total / Activated) | Max Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131,072 tokens (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131,072 tokens (128K) |
Hinweis: Beide MoE-Modelle verwenden insgesamt 128 Experten, aktivieren aber nur 8 pro Token, wodurch die Rechenlast im Vergleich zu einem dichten Modell gleicher Größe erheblich reduziert wird.
Qwen 3 Wichtige technische Merkmale
Hybride Denkmodi: Ein besonderes Merkmal von Qwen3 ist seine Fähigkeit, in zwei verschiedenen Modi zu arbeiten, die vom Benutzer gesteuert werden können:
- Denkmodus (Standard): Das Modell führt eine interne, schrittweise Argumentation (Chain-of-Thought-Stil) durch, bevor es die endgültige Antwort generiert. Dieser latente Denkprozess wird eingekapselt, oft durch spezielle Token gekennzeichnet (z. B. Ausgabe von
<think>...</think>-Inhalten vor der endgültigen Antwort bei Verwendung bestimmter Framework-Konfigurationen). Dieser Modus verbessert die Leistung bei komplexen Aufgaben, die logische Ableitung, mathematisches Denken oder Planung erfordern. Er ermöglicht skalierbare Leistungsverbesserungen, die direkt mit dem zugewiesenen Rechenbudget für die Argumentation korrelieren. - Nicht-Denkmodus: Das Modell generiert eine direkte Antwort ohne die explizite interne Argumentationsphase und optimiert so die Geschwindigkeit und reduziert die Rechenkosten bei einfacheren Abfragen.
Benutzer können dynamisch zwischen diesen Modi wechseln, möglicherweise auf einer Turn-by-Turn-Basis in Multi-Turn-Konversationen, indem sie Tags wie/thinkund/no_thinkin ihren Prompts verwenden (sofern das Framework dies zulässt), wodurch eine fein abgestimmte Kontrolle über den Kompromiss zwischen Latenz/Kosten und Argumentationstiefe ermöglicht wird.
Umfassende mehrsprachige Unterstützung: Qwen3-Modelle sind auf einem vielfältigen Korpus vortrainiert, der die Unterstützung von 119 Sprachen und Dialekten in den wichtigsten Sprachfamilien (Indo-Europäisch, Sino-Tibetisch, Afro-Asiatisch, Austronesisch, Dravidisch, Turkisch usw.) ermöglicht und sie für eine Vielzahl globaler Anwendungen geeignet macht.
Erweiterte Trainingsmethodik:
- Vortraining: Modelle wurden auf einem groß angelegten Datensatz vortrainiert, der Billionen von Token umfasste. Die letzte Vortrainingsphase umfasste die Verwendung hochwertiger Long-Context-Daten, um das effektive Kontextfenster zunächst auf bis zu 32K Token zu erweitern, mit weiteren Erweiterungen auf 128K für größere Modelle.
- Nachtraining: Eine hochentwickelte vierstufige Pipeline wurde eingesetzt, um die Modelle mit Anweisungsbefolgung, Denkfähigkeiten und dem hybriden Denkmechanismus auszustatten:
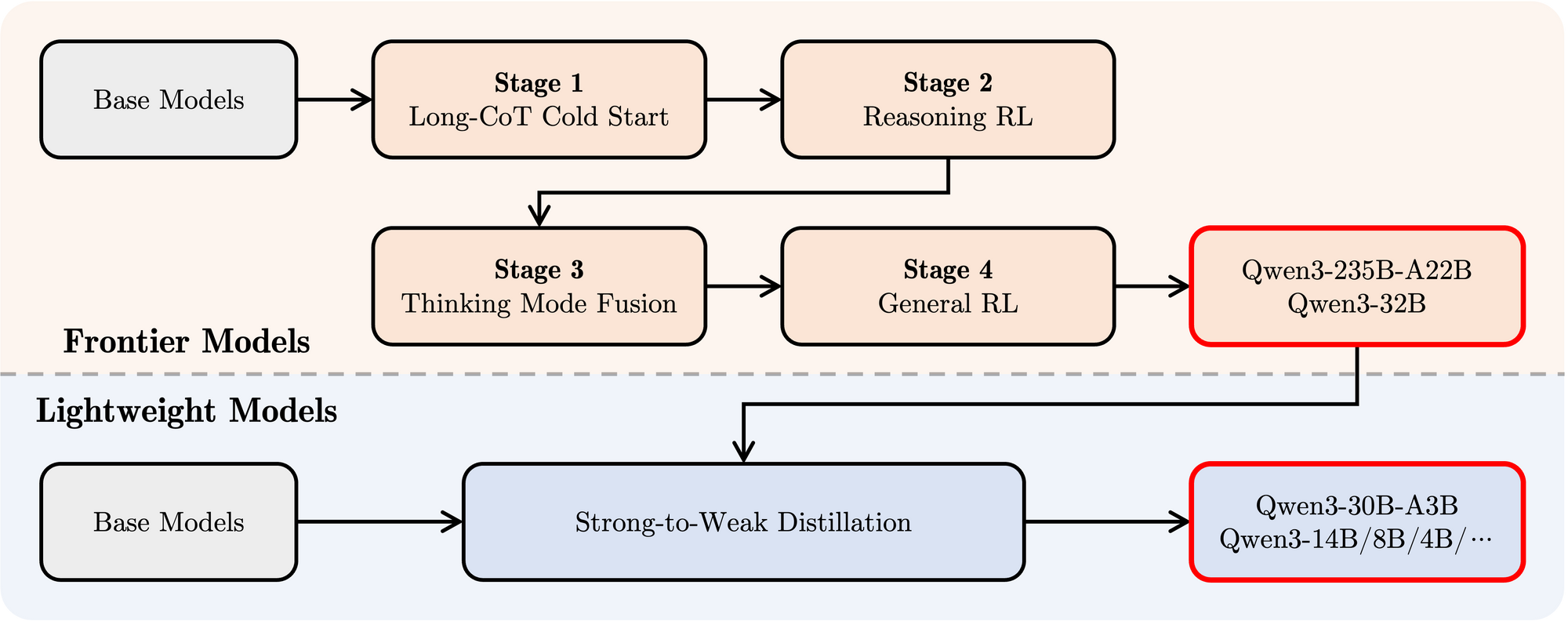
- Long CoT Cold Start: Überwachtes Fine-Tuning (SFT) auf vielfältigen Long-Chain-of-Thought (CoT)-Daten, die Mathematik, Programmierung, logisches Denken und MINT umfassen, um grundlegende Denkfähigkeiten aufzubauen.
- Reasoning-basiertes Reinforcement Learning (RL): Hochskalierung der Rechenressourcen für RL unter Verwendung regelbasierter Belohnungen, um die Exploration und Exploitation speziell für Denkaufgaben zu verbessern.
- Thinking Mode Fusion: Integration von Nicht-Denkfähigkeiten durch Fine-Tuning des denkfähigkeitsverbesserten Modells auf einer Mischung aus Long-CoT-Daten und Standard-Instruction-Tuning-Daten, die vom Modell der Stufe 2 generiert wurden. Dies verbindet tiefes Denken mit schneller Antwortgenerierung.
- General RL: Anwendung von RL über zahlreiche allgemeine Aufgaben (Anweisungsbefolgung, Format-Einhaltung, Agenten-Fähigkeiten), um das Gesamtverhalten zu verfeinern und unerwünschte Ausgaben zu mindern.
Qwen 3 Benchmark-Leistung
Qwen3 zeigt eine sehr wettbewerbsfähige Leistung gegenüber anderen führenden zeitgenössischen Modellen:
Flaggschiff MoE: Das Modell Qwen3-235B-A22B erzielt Ergebnisse, die mit Top-Tier-Modellen wie DeepSeek-R1, Googles o1 und o3-mini, Grok-3 und Gemini-2.5-Pro in verschiedenen Benchmarks zur Bewertung von Programmierung, Mathematik und allgemeinen Fähigkeiten vergleichbar sind.
Kleineres MoE: Das Modell Qwen3-30B-A3B übertrifft Modelle wie QwQ-32B deutlich, obwohl während der Inferenz nur ein Bruchteil (3B vs. 32B) der Parameter aktiviert wird, was die Effizienz der MoE-Architektur hervorhebt.
Dichte Modelle: Aufgrund von architektonischen und Trainingsfortschritten erreichen Qwen3-Dichtemodelle im Allgemeinen die Leistung größerer Qwen2.5-Dichtemodelle oder übertreffen diese. Zum Beispiel:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(und konkurriert in einigen Aspekten mitQwen2.5-72B-Instruct)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Bemerkenswert ist, dass Qwen3-Dichtebasismodelle besonders starke Leistungsverbesserungen gegenüber ihren Vorgängern in den Bereichen MINT, Programmierung und Argumentation aufweisen.
MoE-Effizienz: Qwen3-MoE-Basismodelle erzielen eine Leistung, die mit deutlich größeren Qwen2.5-Dichtemodellen vergleichbar ist, während sie nur ~10 % der Parameter aktivieren, was zu erheblichen Einsparungen bei der Berechnung von Training und Inferenz führt.
Diese Benchmark-Ergebnisse unterstreichen die Position von Qwen3 als eine hochmoderne Modellfamilie, die sowohl hohe Leistung als auch, insbesondere mit MoE-Varianten, verbesserte Recheneffizienz bietet. Die Modelle sind über Standardplattformen wie Hugging Face, ModelScope und Kaggle verfügbar und werden von beliebten Bereitstellungs-Frameworks wie Ollama, vLLM, SGLang, LMStudio und llama.cpp unterstützt, was ihre Integration in verschiedene Workflows und Anwendungen, einschließlich der lokalen Ausführung, erleichtert.
So führen Sie Qwen 3 lokal mit Ollama aus
Ollama hat aufgrund seiner Einfachheit beim Herunterladen, Verwalten und Ausführen von LLMs lokal immense Popularität erlangt. Es abstrahiert einen Großteil der Komplexität und bietet eine Befehlszeilenschnittstelle und einen API-Server.
1. Installation:
Die Installation von Ollama ist in der Regel unkompliziert. Besuchen Sie die offizielle Ollama-Website (ollama.com) und befolgen Sie die Download-Anweisungen für Ihr Betriebssystem (macOS, Linux, Windows).
2. Abrufen von Qwen3-Modellen:
Ollama verwaltet eine Bibliothek mit sofort verfügbaren Modellen. Um ein bestimmtes Qwen3-Modell auszuführen, verwenden Sie den Befehl ollama run. Wenn das Modell nicht lokal vorhanden ist, lädt Ollama es automatisch herunter. Das Qwen-Team hat mehrere Qwen3-Varianten direkt in der Ollama-Bibliothek verfügbar gemacht.
Sie können verfügbare Qwen3-Tags auf der Qwen3-Seite der Ollama-Website finden (z. B. ollama.com/library/qwen3). Häufige Tags könnten sein:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(Das kleinere MoE-Modell)
Um beispielsweise das Modell mit 4B Parametern auszuführen, öffnen Sie einfach Ihr Terminal und geben Sie Folgendes ein:
ollama run qwen3:4b
Dieser Befehl lädt das Modell herunter (falls erforderlich) und startet eine interaktive Chat-Sitzung.
3. Interaktion mit dem Modell:
Sobald der Befehl ollama run aktiv ist, können Sie Ihre Prompts direkt in das Terminal eingeben. Ollama startet auch einen lokalen Server (normalerweise unter http://localhost:11434), der eine API bereitstellt, die mit dem OpenAI-Standard kompatibel ist. Sie können programmgesteuert mit diesem interagieren, indem Sie Tools wie curl oder verschiedene Client-Bibliotheken in Python, JavaScript usw. verwenden.
4. Hardware-Überlegungen:
Die lokale Ausführung von LLMs erfordert erhebliche Ressourcen.
- RAM: Selbst kleinere Modelle (0,6B, 1,7B) benötigen mehrere Gigabyte RAM. Größere Modelle (8B, 14B, 32B, 30B-A3B) benötigen deutlich mehr, oft 16 GB, 32 GB oder sogar 64 GB+, abhängig von der vom Ollama verwendeten Quantisierungsstufe.
- VRAM (GPU): Für eine akzeptable Leistung wird eine dedizierte GPU mit ausreichend VRAM dringend empfohlen. Ollama verwendet automatisch kompatible GPUs (NVIDIA, Apple Silicon). Die Menge an VRAM bestimmt das größte Modell, das Sie bequem vollständig auf der GPU ausführen können, was die Inferenz erheblich beschleunigt.
- CPU: Obwohl Ollama Modelle auf der CPU ausführen kann, ist die Leistung deutlich langsamer als auf einer GPU.
Ollama eignet sich hervorragend für den schnellen Einstieg, die lokale Entwicklung, das Experimentieren und für Einzelbenutzer-Chat-Anwendungen, insbesondere auf Hardware für Endverbraucher (innerhalb von Grenzen).
So führen Sie Ollama lokal mit vLLM aus
vLLM ist eine Bibliothek für das LLM-Serving mit hohem Durchsatz, die Optimierungen wie PagedAttention verwendet, um die Inferenzgeschwindigkeit und Speichereffizienz erheblich zu verbessern, wodurch sie sich ideal für anspruchsvolle Anwendungen und das Serving größerer Modelle eignet. Das vLLM-Team bietet exzellenten Support für neue Architekturen, einschließlich Day-0-Support für Qwen3 bei seiner Veröffentlichung.
1. Installation:
Installieren Sie vLLM mit pip. Es wird im Allgemeinen empfohlen, eine virtuelle Umgebung zu verwenden:
pip install -U vllm
Stellen Sie sicher, dass Sie die erforderlichen Voraussetzungen haben, typischerweise eine kompatible NVIDIA-GPU mit dem entsprechenden installierten CUDA-Toolkit. Informationen zu spezifischen Anforderungen finden Sie in der vLLM-Dokumentation.
2. Serving von Qwen3-Modellen:
vLLM verwendet den Befehl vllm serve, um ein Modell zu laden und einen OpenAI-kompatiblen API-Server zu starten. Das Qwen-Team und die vLLM-Dokumentation geben Anleitungen zur Ausführung von Qwen3.
Basierend auf den bereitgestellten Informationen und der gängigen vLLM-Nutzung erfahren Sie hier, wie Sie das große Qwen3-235B-MoE-Modell mit FP8-Quantisierung (zur Reduzierung des Speicherverbrauchs) und Tensorparallelität über 4 GPUs bedienen können:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Lassen Sie uns diesen Befehl aufschlüsseln:
Qwen/Qwen3-235B-A22B-FP8: Dies ist der Modellbezeichner, der wahrscheinlich auf einen Hugging Face-Repository-Speicherort verweist.FP8weist auf die Verwendung der 8-Bit-Gleitpunktquantisierung hin, wodurch der Speicherbedarf des Modells im Vergleich zu FP16 oder BF16 reduziert wird, was für ein so großes Modell entscheidend ist.--enable-reasoning: Dieses Flag ist entscheidend für die Aktivierung der hybriden Denkfähigkeiten von Qwen3 innerhalb von vLLM.--reasoning-parser deepseek_r1: Die Denk-Ausgabe von Qwen3 hat ein bestimmtes Format. vLLM benötigt einen Parser, um dies zu verarbeiten. Der Blogbeitrag weist darauf hin, dass für vLLM der Parserdeepseek_r1verwendet werden sollte (während SGLang einenqwen3-Parser verwendet). Dies stellt sicher, dass vLLM die Denkschritte korrekt interpretieren und potenziell von der endgültigen Antwort trennen kann.--tensor-parallel-size 4: Dies weist vLLM an, die Gewichte und Berechnungen des Modells auf 4 GPUs zu verteilen. Tensorparallelität ist unerlässlich, um Modelle auszuführen, die zu groß sind, um auf eine einzelne GPU zu passen. Sie würden diese Zahl basierend auf Ihren verfügbaren GPUs anpassen.
Sie können diesen Befehl an andere Qwen3-Modelle anpassen (z. B. Qwen/Qwen3-30B-A3B oder Qwen/Qwen3-32B) und Parameter wie tensor-parallel-size basierend auf Ihrer Hardware anpassen.
3. Interaktion mit dem vLLM-Server:
Sobald vllm serve ausgeführt wird, hostet es einen API-Server (standardmäßig http://localhost:8000), der die OpenAI-API-Spezifikation widerspiegelt. Sie können mit ihm mit Standardtools interagieren:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Use the model name you served
"prompt": "Explain the concept of Mixture-of-Experts in LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- Python OpenAI Client:
from openai import OpenAI
# Point to the local vLLM server
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Use the model name you served
prompt="Write a short story about a robot discovering music.",
max_tokens=200
)
print(completion.choices[0].text)
4. Leistung und Anwendungsfälle:
vLLM glänzt in Szenarien, die einen hohen Durchsatz (viele Anfragen pro Sekunde) und eine geringe Latenz erfordern. Seine Optimierungen machen es geeignet für:
- Entwicklung von Anwendungen, die von lokalen LLMs betrieben werden.
- Bedienung von Modellen für mehrere Benutzer gleichzeitig.
- Bereitstellung großer Modelle, die Multi-GPU-Setups erfordern.
- Produktionsumgebungen, in denen die Leistung entscheidend ist.
Testen der lokalen Ollama-API mit Apidog
Apidog ist ein API-Testtool, das gut mit dem API-Modus von Ollama harmoniert. Es ermöglicht Ihnen, Anfragen zu senden, Antworten anzuzeigen und Ihr Qwen 3-Setup effizient zu debuggen.
So verwenden Sie Apidog mit Ollama:
- Erstellen Sie eine neue API-Anfrage:
- Endpunkt:
http://localhost:11434/api/generate - Senden Sie die Anfrage und überwachen Sie die Antwort in der Echtzeit-Zeitleiste von Apidog.
- Verwenden Sie die JSONPath-Extraktion von Apidog, um Antworten automatisch zu parsen, eine Funktion, die Tools wie Postman übertrifft.


Streaming-Antworten:
- Aktivieren Sie für Echtzeitanwendungen das Streaming:
- Die Auto-Merge-Funktion von Apidog konsolidiert gestreamte Nachrichten und vereinfacht so das Debugging.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Write a poem about AI.", "stream": true}'

Dieser Prozess stellt sicher, dass Ihr Modell wie erwartet funktioniert, was Apidog zu einer wertvollen Ergänzung macht.
Fazit
Die Veröffentlichung der leistungsstarken und vielfältigen Qwen3-Modellfamilie, kombiniert mit ausgereiften lokalen Ausführungstools wie Ollama und vLLM, markiert eine aufregende Zeit für KI-Praktiker. Unabhängig davon, ob Sie die Plug-and-Play-Einfachheit von Ollama für den persönlichen Gebrauch und das Experimentieren oder die Hochleistungs-Serving-Fähigkeiten von vLLM für den Aufbau robuster Anwendungen priorisieren, ist die lokale Ausführung hochmoderner LLMs machbarer als je zuvor.
Indem Sie Modelle wie Qwen3-30B-A3B oder sogar die größeren dichten Varianten auf Ihre eigene Hardware bringen, erhalten Sie beispiellose Kontrolle, Datenschutz und Kosteneffizienz. Sie können ihre erweiterten Funktionen wie hybrides Denken und umfassende mehrsprachige Unterstützung für innovative Projekte nutzen. Da sich die Hardware- und Software-Ökosysteme weiter verbessern, wird die Leistung großer Sprachmodelle zunehmend demokratisiert und von entfernten Cloud-Servern direkt auf unsere lokalen Maschinen verlagert. Experimentieren Sie mit Qwen3 mit Ollama und vLLM, um die Spitze dieser lokalen KI-Revolution zu erleben.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demans, and replaces Postman at a much more affordable price!


