
Das Ausführen großer Sprachmodelle wie Mistral 3 auf Ihrem lokalen Rechner bietet Entwicklern eine beispiellose Kontrolle über Datenschutz, Inferenzgeschwindigkeit und Anpassung. Da KI-Workloads immer anspruchsvoller werden, wird die lokale Ausführung für das Prototyping, Testen und Offline-Bereitstellen von Anwendungen unerlässlich. Darüber hinaus vereinfachen Tools wie Ollama diesen Prozess und ermöglichen es Ihnen, die Fähigkeiten von Mistral 3 direkt von Ihrem Desktop oder Server aus zu nutzen.
Dieser Leitfaden bietet Ihnen Schritt-für-Schritt-Anleitungen zur lokalen Installation und Ausführung von Mistral 3-Varianten. Wir konzentrieren uns auf die Open-Source-Reihe Ministral 3, die sich hervorragend für Edge-Deployments eignet. Am Ende werden Sie die Leistung für reale Aufgaben optimieren und so reaktionsschnelle Antworten und Ressourceneffizienz gewährleisten.
Mistral 3 verstehen: Das Open-Source-Kraftpaket in der KI
Mistral AI verschiebt mit seiner neuesten Version weiterhin die Grenzen: Mistral 3. Entwickler und Forscher loben diese Modellfamilie für die Ausgewogenheit von Genauigkeit, Effizienz und Zugänglichkeit. Im Gegensatz zu proprietären Giganten遵循 Mistral 3 Open-Source-Prinzipien und wird unter der Apache 2.0-Lizenz veröffentlicht. Dieser Schritt ermöglicht es der Community, ohne Einschränkungen zu modifizieren, zu verteilen und zu innovieren.
Im Kern besteht Mistral 3 aus zwei Hauptzweigen: der kompakten Ministral 3-Serie und dem umfangreichen Mistral Large 3. Die Ministral 3-Modelle – erhältlich in den Parametergrößen 3B, 8B und 14B – sind für ressourcenbeschränkte Umgebungen konzipiert. Ingenieure entwickeln diese für lokale und Edge-Anwendungsfälle, bei denen jedes Watt und jeder Kern zählt. So passt die 3B-Variante bequem auf Laptops mit bescheidener GPU, während die 14B auf Multi-GPU-Setups an Grenzen stößt, ohne an Geschwindigkeit einzubüßen.
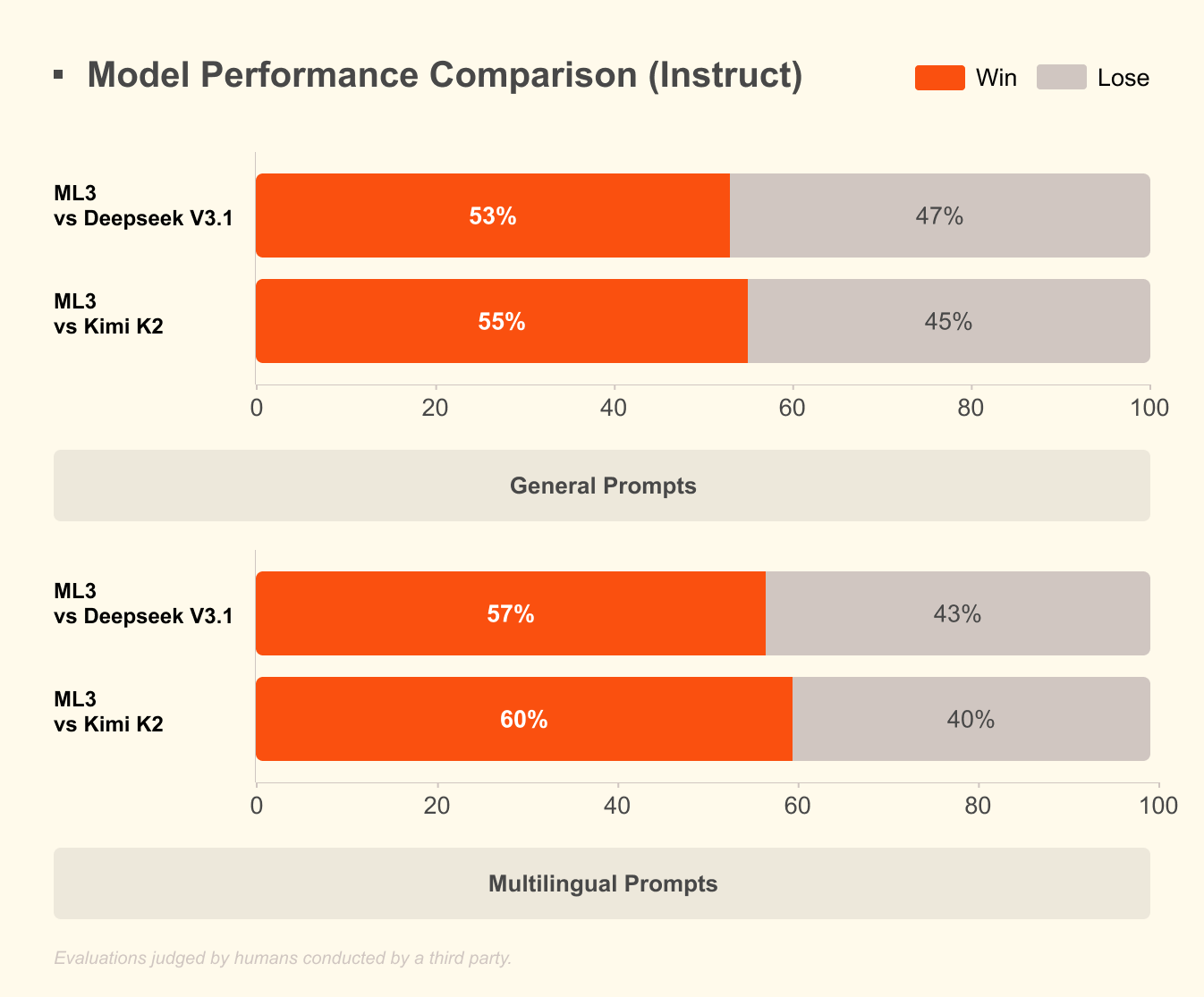
Mistral Large 3 hingegen verwendet eine spärliche Mixture-of-Experts-Architektur mit 41 Mrd. aktiven Parametern und insgesamt 675 Mrd. Dieser Entwurf aktiviert nur relevante Experten pro Abfrage, was den Rechenaufwand drastisch reduziert. Entwickler greifen auf anweisungsoptimierte Versionen für Aufgaben wie Code-Unterstützung, Dokumentenzusammenfassung und mehrsprachige Übersetzung zu. Das Modell unterstützt nativ über 40 Sprachen und übertrifft andere Modelle in nicht-englischen Dialogen.
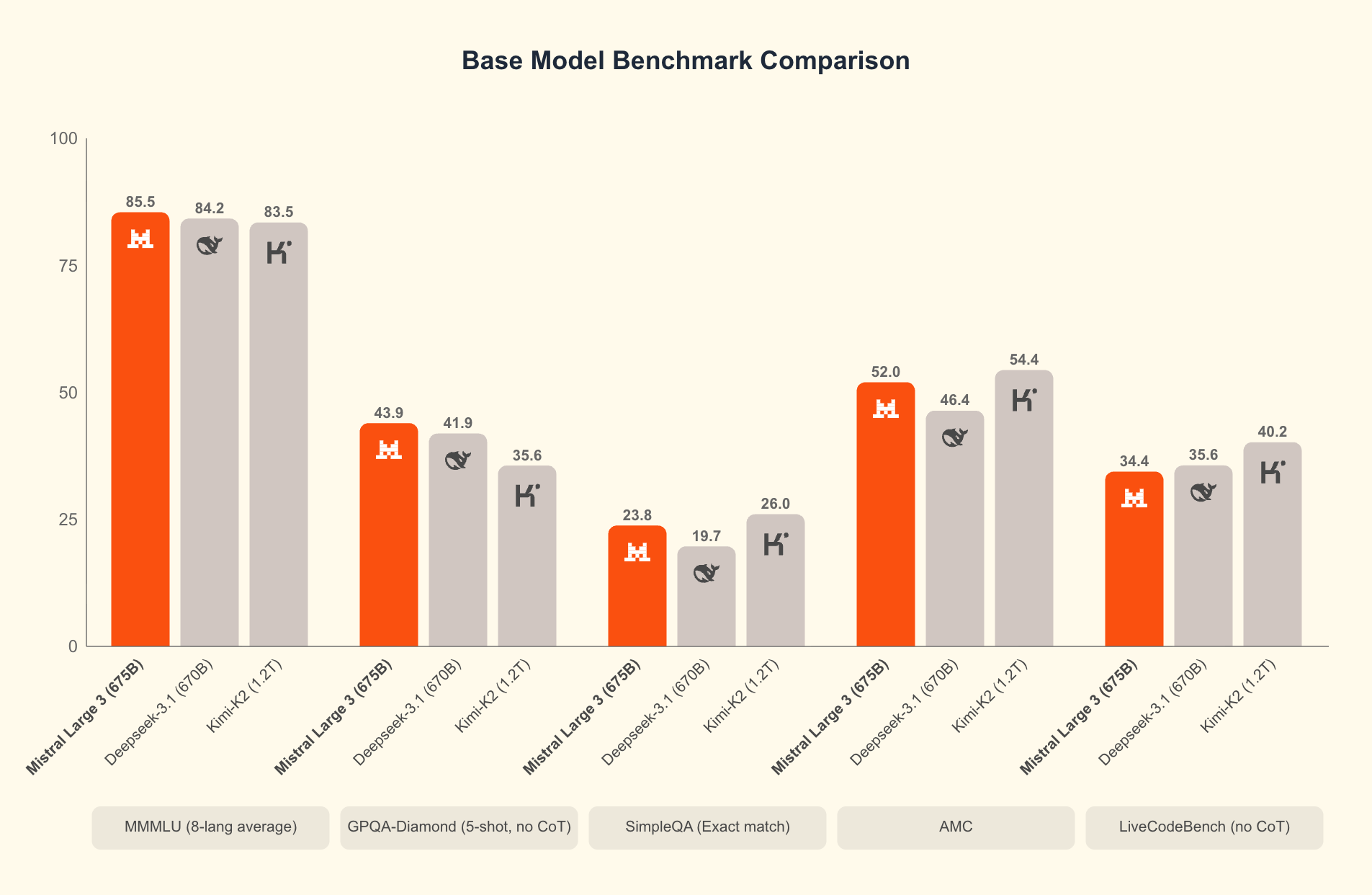
Was unterscheidet Mistral 3? Benchmarks zeigen seinen Vorsprung in realen Szenarien. Auf dem GPQA Diamond-Datensatz – einem strengen Test des wissenschaftlichen Denkens – behalten Mistral 3-Varianten auch bei skalierenden Ausgabetokens eine hohe Genauigkeit bei. Beispielsweise behält das Ministral 3B Instruct-Modell eine Genauigkeit von etwa 35-40 % bei bis zu 20.000 Tokens bei, was größeren Modellen wie Gemma 2 9B Konkurrenz macht, während es weniger Ressourcen verbraucht. Diese Effizienz beruht auf fortschrittlichen Quantisierungstechniken wie der NVFP4-Kompression, die die Modellgröße reduziert, ohne die Ausgabequalität zu beeinträchtigen.
Darüber hinaus integriert Mistral 3 multimodale Funktionen, die Bilder zusammen mit Text für Anwendungen in der visuellen Fragebeantwortung oder Inhaltserstellung verarbeiten. Die Open-Sourcing dieser Modelle fördert eine schnelle Iteration; Gemeinschaften stimmen sie bereits für spezialisierte Bereiche wie Rechtsanalyse oder kreatives Schreiben ab. Infolgedessen demokratisiert Mistral 3 die Frontier-KI und ermöglicht Startups und einzelnen Entwicklern, mit großen Technologieunternehmen zu konkurrieren.

Der Übergang von der Theorie zur Praxis, das lokale Ausführen dieser Modelle, erschließt ihr volles Potenzial. Cloud-APIs verursachen Latenz und Kosten, aber die lokale Inferenz liefert Antworten im Sub-Sekundenbereich. Als Nächstes untersuchen wir die Hardware-Voraussetzungen, die dies ermöglichen.
Warum Mistral 3 lokal ausführen? Vorteile für Entwickler und Effizienzsteigerungen
Entwickler entscheiden sich aus mehreren zwingenden Gründen für die lokale Ausführung. Erstens hat der Datenschutz oberste Priorität: Sensible Daten bleiben auf Ihrem Rechner und vermeiden Server von Drittanbietern. In regulierten Branchen wie dem Gesundheitswesen oder dem Finanzwesen erweist sich dieser Compliance-Vorteil als von unschätzbarem Wert. Zweitens sammeln sich Kosteneinsparungen schnell an. Die hohe Effizienz von Mistral 3 bedeutet, dass Sie Gebühren pro Token vermeiden, ideal für Tests mit hohem Volumen.
Darüber hinaus beschleunigen lokale Ausführungen das Experimentieren. Iterieren Sie Prompts, stimmen Sie Hyperparameter ab oder verketten Sie Modelle ohne Netzwerkverzögerungen. Benchmarks bestätigen dies: Auf Consumer-Hardware erreicht Ministral 8B 50-60 Tokens pro Sekunde, vergleichbar mit Cloud-Setups, aber ohne Ausfallzeiten.
Effizienz definiert die Attraktivität von Mistral 3. Die Modelle sind für kostengünstige Inferenz optimiert, wie die GPQA Diamond-Ergebnisse zeigen, bei denen Ministral-Varianten Gemma 3 4B und 12B in Bezug auf die anhaltende Genauigkeit übertreffen. Dies ist wichtig für Aufgaben mit langem Kontext; wenn die Ausgaben auf 20.000 Tokens erweitert werden, sinkt die Genauigkeit nur minimal, was eine zuverlässige Leistung in Chatbots oder Code-Generatoren gewährleistet.
Darüber hinaus ermöglicht der Open-Source-Zugriff über Plattformen wie Hugging Face eine nahtlose Integration mit Tools wie Apidog für das API-Prototyping. Testen Sie Mistral 3-Endpunkte lokal, bevor Sie skalieren, und schließen Sie so die Lücke zwischen Entwicklung und Produktion.
Der Erfolg hängt jedoch von der richtigen Einrichtung ab. Mit der installierten Hardware fahren Sie mit der Installation fort. Diese Vorbereitung gewährleistet einen reibungslosen Betrieb und maximiert den Durchsatz.
Hardware- und Softwareanforderungen für die lokale Mistral 3-Bereitstellung
Bevor Sie Mistral 3 starten, bewerten Sie die Fähigkeiten Ihres Systems. Die Mindestanforderungen umfassen eine moderne CPU (Intel i7 oder AMD Ryzen 7) mit 16 GB RAM für das 3B-Modell. Für die 8B- und 14B-Varianten sollten Sie 32 GB RAM und eine NVIDIA-GPU mit mindestens 8 GB VRAM – denken Sie an RTX 3060 oder besser – bereitstellen. Benutzer von Apple Silicon profitieren von vereinheitlichtem Speicher; M1 Pro mit 16 GB bewältigt 3B mühelos, während M3 Max bei 14B herausragt.
Die Speicheranforderungen variieren: Das 3B-Modell belegt ~2 GB quantisiert, skaliert auf ~9 GB für 14B. Verwenden Sie SSDs für schnelleres Laden. Betriebssysteme? Linux (Ubuntu 22.04) bietet die beste Leistung, gefolgt von macOS Ventura+. Windows 11 funktioniert über WSL2, obwohl GPU-Passthrough Anpassungen erfordert.
Softwareseitig bildet Python 3.10+ das Rückgrat. Installieren Sie CUDA 12.1 für NVIDIA-Karten, um die GPU-Beschleunigung zu ermöglichen – unerlässlich für Latenzen unter 100 ms. Für reine CPU-Ausführungen nutzen Sie Bibliotheken wie ONNX Runtime.
Quantisierung spielt hier eine zentrale Rolle. Mistral 3 unterstützt 4-Bit- und 8-Bit-Formate, wodurch der Speicherbedarf um 75 % reduziert wird, während 95 % Genauigkeit erhalten bleiben. Tools wie bitsandbytes übernehmen dies automatisch.
Nachdem Sie ausgerüstet sind, folgt die Installation einem unkomplizierten Pfad. Wir empfehlen Ollama wegen seiner Einfachheit, aber es gibt Alternativen. Diese Wahl optimiert den Prozess und führt uns zu den grundlegenden Einrichtungsschritten.
Ollama installieren: Das Tor zu müheloser lokaler KI
Ollama sticht als das führende Tool zum lokalen Ausführen von Open-Source-Modellen wie Mistral 3 hervor. Diese leichtgewichtige Plattform abstrahiert Komplexitäten und bietet eine CLI und einen API-Server in einem Paket. Entwickler schätzen die plattformübergreifende Unterstützung und die GPU-Erkennung ohne Konfiguration.
Beginnen Sie mit dem Herunterladen von Ollama von der offiziellen Website (ollama.com). Unter Linux führen Sie aus:
curl -fsSL https://ollama.com/install.sh | sh
Dieses Skript installiert Binärdateien und richtet Dienste ein. Überprüfen Sie dies mit ollama --version; erwarten Sie eine Ausgabe wie "ollama version 0.3.0". Für macOS kümmert sich der DMG-Installer um Abhängigkeiten, einschließlich Rosetta für die Intel-Emulation auf ARM.
Windows-Benutzer laden die EXE von den GitHub-Releases herunter. Nach der Installation starten Sie über PowerShell: ollama serve. Ollama läuft im Hintergrund als Daemon und stellt eine REST-API auf Port 11434 bereit.
Warum Ollama? Es lädt Modelle aus seinem Register, einschließlich Ministral 3, mit integrierter Quantisierung. Kein manuelles Klonen von Hugging Face erforderlich. Darüber hinaus unterstützt es Modelfiles für benutzerdefiniertes Fine-Tuning, was mit dem Open-Source-Ethos von Mistral 3 übereinstimmt.
Sobald Ollama bereit ist, laden und führen Sie als Nächstes Modelle aus. Dieser Schritt verwandelt Ihr Setup in eine funktionale KI-Workstation.
Ministral 3 Modelle mit Ollama herunterladen und ausführen
Die Bibliothek von Ollama beherbergt Ministral 3-Varianten.
Beginnen Sie mit dem Auflisten der verfügbaren Tags:
ollama list
Um das 3B-Modell herunterzuladen:
ollama pull ministral:3b-instruct-q4_0
Dieser Befehl lädt ~2 GB herunter und überprüft die Integrität über Hashes. Fortschrittsbalken zeigen den Download an, der typischerweise innerhalb weniger Minuten über Breitband abgeschlossen ist.
Eine interaktive Sitzung starten:
ollama run ministral-3
Ollama lädt das Modell in den Speicher und wärmt Caches für nachfolgende Abfragen vor. Geben Sie Prompts direkt ein; zum Beispiel:
>> Explain quantum entanglement in simple terms.

Das Modell antwortet in Echtzeit und nutzt die Anweisungsabstimmung für kohärente Ausgaben. Beenden Sie mit /bye.
Häufige Probleme beheben? Wenn die GPU nicht ausgelastet ist, setzen Sie die Umgebungsvariable OLLAMA_NUM_GPU=999. Bei OOM-Fehlern gehen Sie zu einer niedrigeren Quantisierung wie q3_K_M über.
Jenseits der Grundlagen ermöglicht die API von Ollama den programmatischen Zugriff. Führen Sie eine Vervollständigung per Curl aus:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
Diese JSON-Antwort enthält den generierten Text, perfekt für die Integration mit Apidog während der API-Entwicklung.
Das Ausführen von Modellen markiert den Anfang; Optimierung steigert die Leistung. Folglich wenden wir uns Techniken zu, die jedes Quäntchen Effizienz aus Ihrer Hardware herausholen.
Mistral 3 Inferenz optimieren: Kompromisse bei Geschwindigkeit, Speicher und Genauigkeit
Effizienz definiert den Erfolg lokaler KI. Das Design von Mistral 3 glänzt hier, aber Anpassungen verstärken die Gewinne. Beginnen Sie mit der Quantisierung: Ollama verwendet standardmäßig Q4_0, was Größe und Wiedergabetreue ausbalanciert. Für extrem geringe Ressourcen versuchen Sie Q2_K – halbieren Sie den Speicher bei 10 % Perplexitätskosten.
Die GPU-Orchestrierung ist wichtig. Aktivieren Sie Flash Attention über OLLAMA_FLASH_ATTENTION=1 für 2-fache Geschwindigkeitssteigerungen bei langen Kontexten. Mistral 3 unterstützt bis zu 128K Tokens; testen Sie mit Prompts im GPQA-Stil, um die anhaltende Genauigkeit zu überprüfen.
Batch-Verarbeitung steigert den Durchsatz. Verwenden Sie Ollamas /api/generate mit mehreren Prompts parallel, indem Sie asynchrone Python-Clients nutzen. Skripten Sie zum Beispiel eine Schleife:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Dies bewältigt über 10 Abfragen pro Sekunde auf Multi-Core-Setups.
Speicherverwaltung verhindert Swaps. Überwachen Sie mit nvidia-smi; lagern Sie Schichten auf die CPU aus, wenn der VRAM ausgeschöpft ist. Bibliotheken wie vLLM integrieren sich mit Ollama für kontinuierliches Batching und erreichen 100 Tokens/Sekunde auf A100s.
Genauigkeitsoptimierung? Fine-Tuning mit LoRA-Adaptern auf Domänendaten. Die PEFT-Bibliothek von Hugging Face wendet diese auf Ministral 3 an, wobei ~1 GB zusätzlicher Speicherplatz benötigt wird. Nach dem Fine-Tuning exportieren Sie es über ollama create in das Ollama-Format.
Messen Sie Ihr Setup mit GPQA Diamond. Skripten Sie Evaluierungen, um die Genauigkeit im Verhältnis zu den Tokens darzustellen, analog zu Mistrals Diagrammen. Hocheffiziente Varianten wie Ministral 8B behalten über 50 % der Scores bei, was ihren Vorteil gegenüber Qwen 2.5 VL unterstreicht.
Diese Optimierungen bereiten Sie auf fortgeschrittene Anwendungen vor. Daher untersuchen wir Integrationen, die die Reichweite von Mistral 3 erweitern.
Mistral 3 in Entwicklungstools integrieren: APIs und darüber hinaus
Lokales Mistral 3 gedeiht in Ökosystemen. Kombinieren Sie es mit Apidog, um KI-gestützte APIs zu mocken. Entwerfen Sie Endpunkte, die Ollama abfragen, Payloads testen und Antworten validieren – alles offline.
Erstellen Sie beispielsweise eine POST /generate-Route in Apidog, die an Ollamas API weiterleitet. Importieren Sie Sammlungen für Prompt-Vorlagen, um sicherzustellen, dass Mistral 3 mehrsprachige Anfragen fehlerfrei verarbeitet.
LangChain-Benutzer verketten Mistral 3 mit Tools:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
Dieses Setup verarbeitet 50 Abfragen/Minute, ideal für RAG-Pipelines.
Streamlit-Dashboards visualisieren Ausgaben. Betten Sie Ollama-Aufrufe in Apps für interaktive Chats ein, wobei Sie die Argumentationsfähigkeiten von Mistral 3 für dynamische Fragen und Antworten nutzen.
Sicherheitsaspekte? Führen Sie Ollama hinter NGINX-Proxys aus und begrenzen Sie die Rate von Endpunkten. Für die Produktion containerisieren Sie mit Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Dies isoliert Umgebungen und skaliert auf Kubernetes.
Während sich Anwendungen weiterentwickeln, wird Monitoring entscheidend. Tools wie Prometheus verfolgen die Latenz und alarmieren bei Abweichungen von der Basiseffizienz.
Zusammenfassend lässt sich sagen, dass diese Integrationen Mistral 3 von einem eigenständigen Modell in eine vielseitige Engine verwandeln. Doch es entstehen Herausforderungen; deren Bewältigung gewährleistet robuste Bereitstellungen.
Behebung häufiger Probleme bei lokalen Mistral 3-Ausführungen
Selbst optimierte Setups stoßen auf Hürden. CUDA-Fehlpaarungen stehen ganz oben auf der Liste: Überprüfen Sie die Versionen mit nvcc --version. Führen Sie ein Downgrade durch, wenn Konflikte auftreten, da Mistral 3 11.8+ toleriert.
Modell laden fehlgeschlagen? Leeren Sie den Ollama-Cache: ollama rm ministral:3b-instruct-q4_0 und ziehen Sie dann erneut. Beschädigte Downloads stammen aus Netzwerken; verwenden Sie --insecure sparsam.
Auf macOS hinkt die Metal-Beschleunigung CUDA hinterher. Erzwingen Sie die CPU für Stabilität: OLLAMA_METAL=0. Windows WSL-Benutzer aktivieren NVIDIA-Treiber über wsl --update.
Überhitzung plagt Laptops; drosseln Sie mit nvidia-smi -pl 100, um die Leistung zu begrenzen. Bei Genauigkeitsabfällen überprüfen Sie die Prompts – Ministral 3 zeichnet sich durch Anweisungsformate aus.
Community-Foren auf Reddit und Hugging Face lösen 90 % der Grenzfälle. Protokollieren Sie Fehler mit OLLAMA_DEBUG=1 zur Diagnose.
Nachdem Fallstricke umschifft wurden, liefert Mistral 3 einen konsistenten Wert. Abschließend reflektieren wir seine breitere Auswirkung.
Fazit: Mistral 3 lokal nutzen für die KI-Innovationen von morgen
Mistral 3 definiert Open-Source-KI mit seiner Mischung aus Leistung und Praktikabilität neu. Indem Entwickler es lokal über Ollama ausführen, gewinnen sie Geschwindigkeit, Datenschutz und Kostenkontrolle, die anderswo unerreichbar wären. Von der Modellziehung bis zur Feinabstimmung von Integrationen stattet dieser Leitfaden Sie mit umsetzbaren Schritten aus.
Experimentieren Sie mutig: Beginnen Sie mit der 3B-Variante, skalieren Sie auf 14B und messen Sie sich mit Benchmarks. Während Mistral AI iteriert, halten Sie lokale Ausführungen an der Spitze.
Bereit zum Bauen? Laden Sie Apidog kostenlos herunter und prototypen Sie APIs, die von Ihrem Mistral 3-Setup angetrieben werden. Die Zukunft effizienter KI beginnt auf Ihrem Rechner – lassen Sie es zählen.