Das lokale Ausführen großer Sprachmodelle (LLMs) verschafft Entwicklern Datenschutz, Kontrolle und Kosteneinsparungen. Die Open-Weight-Modelle von OpenAI, gemeinsam bekannt als GPT-OSS (gpt-oss-120b und gpt-oss-20b), bieten leistungsstarke Denkfähigkeiten für Aufgaben wie Codierung, agentenbasierte Workflows und Datenanalyse. Mit Ollama, einer Open-Source-Plattform, können Sie diese Modelle auf Ihrer eigenen Hardware ohne Cloud-Abhängigkeiten bereitstellen. Dieser technische Leitfaden führt Sie durch die Installation von Ollama, die Konfiguration von GPT-OSS-Modellen und das Debugging mit Apidog, einem Tool, das API-Tests für lokale LLMs vereinfacht.
Warum GPT-OSS lokal mit Ollama ausführen?
Das lokale Ausführen von GPT-OSS mit Ollama bietet Entwicklern und Forschern deutliche Vorteile. Erstens gewährleistet es Datenschutz, da Ihre Eingaben und Ausgaben auf Ihrem Gerät verbleiben. Zweitens eliminiert es wiederkehrende Cloud-API-Kosten, was es ideal für Anwendungsfälle mit hohem Volumen oder experimentelle Zwecke macht. Drittens ermöglicht die Kompatibilität von Ollama mit der API-Struktur von OpenAI eine nahtlose Integration mit bestehenden Tools, während die Unterstützung für quantisierte Modelle wie gpt-oss-20b (die nur 16 GB Speicher benötigen) die Zugänglichkeit auf bescheidener Hardware gewährleistet.

Darüber hinaus vereinfacht Ollama die Komplexität der LLM-Bereitstellung. Es verwaltet Modellgewichte, Abhängigkeiten und Konfigurationen über eine einzige Modelfile, ähnlich einem Docker-Container für KI. Gepaart mit Apidog, das eine Echtzeit-Visualisierung von gestreamten KI-Antworten bietet, erhalten Sie ein robustes Ökosystem für die lokale KI-Entwicklung. Als Nächstes wollen wir die Voraussetzungen für die Einrichtung dieser Umgebung untersuchen.
Voraussetzungen für das lokale Ausführen von GPT-OSS
Bevor Sie fortfahren, stellen Sie sicher, dass Ihr System die folgenden Anforderungen erfüllt:
- Hardware:
- Für gpt-oss-20b: Mindestens 16 GB RAM, idealerweise mit einer GPU (z. B. NVIDIA 1060 4 GB).
- Für gpt-oss-120b: 80 GB GPU-Speicher (z. B. eine einzelne 80-GB-GPU oder eine High-End-Rechenzentrumskonfiguration).
- 20-50 GB freier Speicherplatz für Modellgewichte und Abhängigkeiten.
- Software:
- Betriebssystem: Linux oder macOS empfohlen; Windows wird mit zusätzlicher Einrichtung unterstützt.
- Ollama: Download von ollama.com.
- Optional: Docker zum Ausführen von Open WebUI oder Apidog für API-Tests.
- Internet: Stabile Verbindung für anfängliche Modell-Downloads.
- Abhängigkeiten: NVIDIA/AMD GPU-Treiber bei Verwendung von GPU-Beschleunigung; der CPU-only-Modus funktioniert, ist aber langsamer.
Mit diesen Voraussetzungen sind Sie bereit, Ollama zu installieren und GPT-OSS bereitzustellen. Gehen wir zum Installationsprozess über.
Schritt 1: Ollama auf Ihrem System installieren
Die Installation von Ollama ist unkompliziert und unterstützt macOS, Linux und Windows. Befolgen Sie diese Schritte, um es einzurichten:
Ollama herunterladen:
- Besuchen Sie ollama.com und laden Sie das Installationsprogramm für Ihr Betriebssystem herunter.
- Für Linux/macOS verwenden Sie den Terminalbefehl:
curl -fsSL https://ollama.com/install.sh | sh
Dieses Skript automatisiert den Download- und Einrichtungsprozess.
Installation überprüfen:
- Führen Sie
ollama --versionin Ihrem Terminal aus. Sie sollten eine Versionsnummer sehen (z. B. 0.1.44). Falls nicht, überprüfen Sie das Ollama GitHub zur Fehlerbehebung.
Den Ollama-Server starten:
- Führen Sie
ollama serveaus, um den Server zu starten, der aufhttp://localhost:11434lauscht. Lassen Sie dieses Terminal geöffnet oder konfigurieren Sie Ollama als Hintergrunddienst für die kontinuierliche Nutzung.
Nach der Installation ist Ollama bereit, **GPT-OSS**-Modelle herunterzuladen und auszuführen. Fahren wir mit dem Herunterladen der Modelle fort.
Schritt 2: GPT-OSS-Modelle herunterladen
Die **GPT-OSS**-Modelle von OpenAI (gpt-oss-120b und gpt-oss-20b) sind auf Hugging Face verfügbar und für Ollama mit MXFP4-Quantisierung optimiert, was den Speicherbedarf reduziert. Befolgen Sie diese Schritte, um sie herunterzuladen:
Das Modell auswählen:
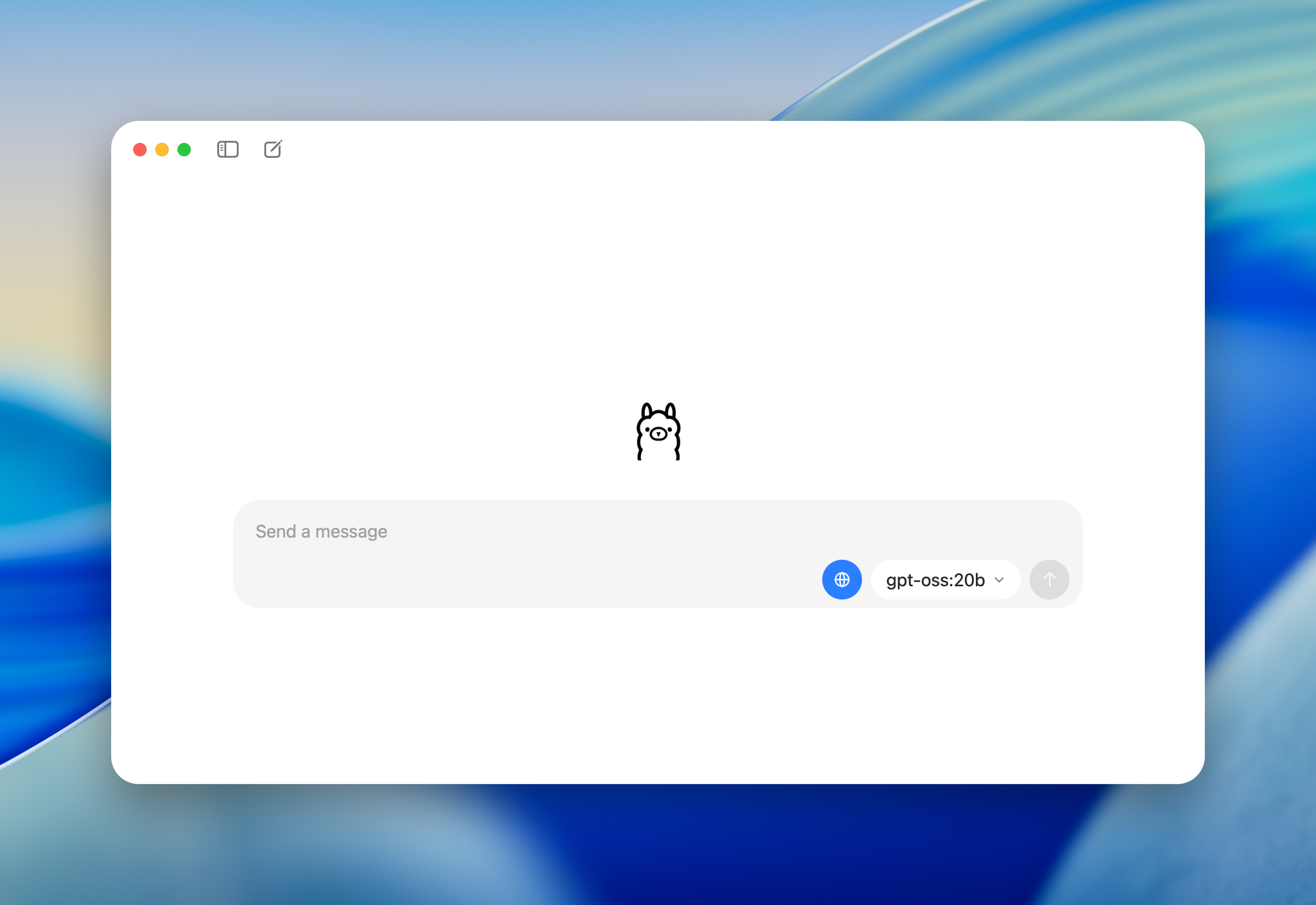
- gpt-oss-20b: Ideal für Desktops/Laptops mit 16 GB RAM. Es aktiviert 3,6 Milliarden Parameter pro Token, geeignet für Edge-Geräte.
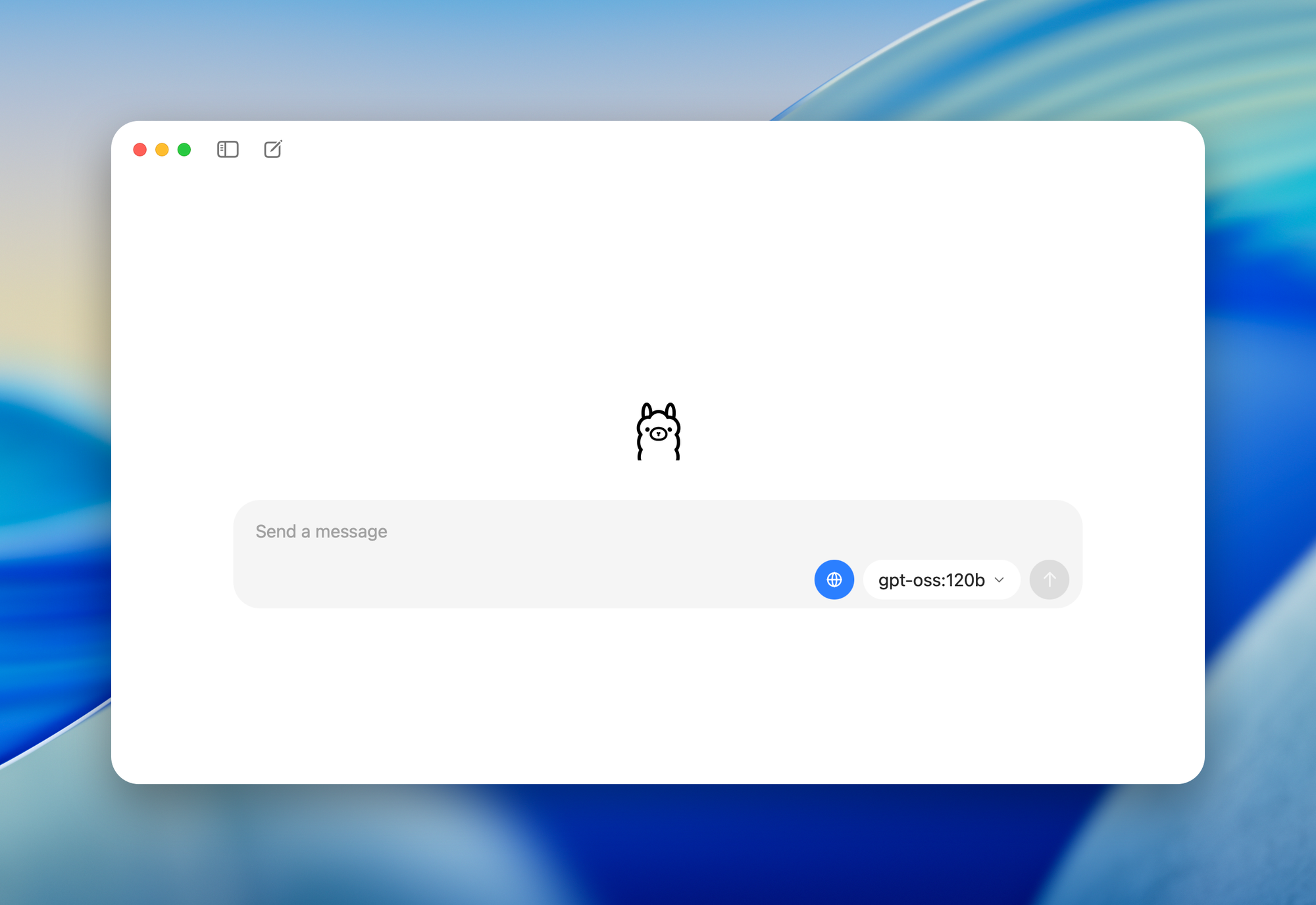
- gpt-oss-120b: Entwickelt für Rechenzentren oder High-End-GPUs mit 80 GB Speicher, aktiviert 5,1 Milliarden Parameter pro Token.
Download über Ollama:
- In Ihrem Terminal, führen Sie aus:
ollama pull gpt-oss-20b
oder
ollama pull gpt-oss-120b
Je nach Ihrer Hardware kann der Download (20-50 GB) einige Zeit in Anspruch nehmen. Stellen Sie eine stabile Internetverbindung sicher.
Download überprüfen:
- Installierte Modelle auflisten mit:
ollama list
Suchen Sie nach gpt-oss-20b:latest oder gpt-oss-120b:latest.
Nachdem das Modell heruntergeladen wurde, können Sie es nun lokal ausführen. Lassen Sie uns untersuchen, wie man mit GPT-OSS interagiert.
Schritt 3: GPT-OSS-Modelle mit Ollama ausführen
Ollama bietet mehrere Möglichkeiten zur Interaktion mit GPT-OSS-Modellen: Befehlszeilenschnittstelle (CLI), API oder grafische Benutzeroberflächen wie Open WebUI. Beginnen wir der Einfachheit halber mit der CLI.
Eine interaktive Sitzung starten:
- Führen Sie aus:
ollama run gpt-oss-20b
Dies öffnet eine Echtzeit-Chatsitzung. Geben Sie Ihre Abfrage ein (z. B. „Schreiben Sie eine Python-Funktion für die binäre Suche“) und drücken Sie Enter. Verwenden Sie /help für spezielle Befehle.
Einmalige Abfragen:
- Für schnelle Antworten ohne interaktiven Modus verwenden Sie:
ollama run gpt-oss-20b "Explain quantum computing in simple terms"
Parameter anpassen:
- Passen Sie das Modellverhalten mit Parametern wie Temperatur (Kreativität) und Top-p (Antwortvielfalt) an. Zum Beispiel:
ollama run gpt-oss-20b --temperature 0.1 --top-p 1.0 "Write a factual summary of blockchain technology"
Eine niedrigere Temperatur (z. B. 0,1) gewährleistet deterministische, faktische Ausgaben, ideal für technische Aufgaben.
Als Nächstes passen wir das Verhalten des Modells mithilfe von Modelfiles für spezifische Anwendungsfälle an.
Schritt 4: GPT-OSS mit Ollama Modelfiles anpassen
Ollamas Modelfiles ermöglichen es Ihnen, das Verhalten von GPT-OSS ohne erneutes Training anzupassen. Sie können System-Prompts festlegen, die Kontextgröße anpassen oder Parameter feinabstimmen. So erstellen Sie ein benutzerdefiniertes Modell:
Eine Modelfile erstellen:
- Erstellen Sie eine Datei namens
Modelfilemit folgendem Inhalt:
FROM gpt-oss-20b
SYSTEM "You are a technical assistant specializing in Python programming. Provide concise, accurate code with comments."
PARAMETER temperature 0.5
PARAMETER num_ctx 4096
Dies konfiguriert das Modell als Python-fokussierten Assistenten mit moderater Kreativität und einem 4k-Token-Kontextfenster.
Das benutzerdefinierte Modell erstellen:
- Navigieren Sie in das Verzeichnis, das die Modelfile enthält, und führen Sie aus:
ollama create python-gpt-oss -f Modelfile
Das benutzerdefinierte Modell ausführen:
- Starten Sie es mit:
ollama run python-gpt-oss
Nun priorisiert das Modell Python-bezogene Antworten mit dem angegebenen Verhalten.
Diese Anpassung verbessert GPT-OSS für spezifische Domänen, wie Codierung oder technische Dokumentation. Nun integrieren wir das Modell in Anwendungen mithilfe der Ollama-API.
Schritt 5: GPT-OSS mit der Ollama-API integrieren
Ollamas API, die auf http://localhost:11434 läuft, ermöglicht den programmatischen Zugriff auf GPT-OSS. Dies ist ideal für Entwickler, die KI-gestützte Anwendungen erstellen. So verwenden Sie sie:
API-Endpunkte:
- POST /api/generate: Generiert Text für einen einzelnen Prompt. Beispiel:
curl http://localhost:11434/api/generate -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "prompt": "Write a Python script for a REST API"}'
- POST /api/chat: Unterstützt konversationelle Interaktionen mit Nachrichtenverlauf:
curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "messages": [{"role": "user", "content": "Explain neural networks"}]}'
- POST /api/embeddings: Generiert Vektor-Embeddings für semantische Aufgaben wie Suche oder Klassifizierung.
OpenAI-Kompatibilität:
- Ollama unterstützt das Chat Completions API-Format von OpenAI. Verwenden Sie Python mit der OpenAI-Bibliothek:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="gpt-oss-20b",
messages=[{"role": "user", "content": "What is machine learning?"}]
)
print(response.choices[0].message.content)
Diese API-Integration ermöglicht es GPT-OSS, Chatbots, Codegeneratoren oder Datenanalysetools zu betreiben. Das Debuggen von Streaming-Antworten kann jedoch eine Herausforderung sein. Sehen wir uns an, wie Apidog dies vereinfacht.
Schritt 6: GPT-OSS mit Apidog debuggen
Apidog ist ein leistungsstarkes API-Testtool, das Streaming-Antworten von Ollamas Endpunkten visualisiert und so das Debuggen von GPT-OSS-Ausgaben erleichtert. So verwenden Sie es:
Apidog installieren:
- Laden Sie Apidog von apidog.com herunter und installieren Sie es auf Ihrem System.
Ollama-API in Apidog konfigurieren:
- Erstellen Sie eine neue API-Anfrage in Apidog.
- Stellen Sie die URL auf
http://localhost:11434/api/generateein. - Verwenden Sie einen JSON-Body wie:
{
"model": "gpt-oss-20b",
"prompt": "Generate a Python function for sorting",
"stream": true
}
Antworten visualisieren:
- Apidog führt gestreamte Tokens in einem lesbaren Format zusammen, im Gegensatz zu rohen JSON-Ausgaben. Dies hilft, Formatierungsfehler oder logische Fehler in der Argumentation des Modells zu identifizieren.
- Nutzen Sie die Argumentationsanalyse von Apidog, um den schrittweisen Denkprozess von GPT-OSS zu untersuchen, insbesondere bei komplexen Aufgaben wie Codierung oder Problemlösung.
Vergleichende Tests:
- Erstellen Sie Prompt-Sammlungen in Apidog, um zu testen, wie verschiedene Parameter (z. B. Temperatur, Top-p) die GPT-OSS-Ausgaben beeinflussen. Dies gewährleistet eine optimale Modellleistung für Ihren Anwendungsfall.
Die Visualisierung von Apidog verwandelt das Debugging von einer mühsamen Aufgabe in einen klaren, umsetzbaren Prozess und verbessert Ihren Entwicklungs-Workflow. Nun gehen wir auf häufige Probleme ein, die auftreten können.
Schritt 7: Häufige Probleme beheben
Das lokale Ausführen von GPT-OSS kann Herausforderungen mit sich bringen. Hier sind Lösungen für häufige Probleme:
GPU-Speicherfehler:
- Problem: gpt-oss-120b schlägt aufgrund von unzureichendem GPU-Speicher fehl.
- Lösung: Wechseln Sie zu gpt-oss-20b oder stellen Sie sicher, dass Ihr System eine 80-GB-GPU besitzt. Überprüfen Sie die Speichernutzung mit
nvidia-smi.
Modell startet nicht:
- Problem:
ollama runschlägt mit einem Fehler fehl. - Lösung: Überprüfen Sie, ob das Modell heruntergeladen wurde (
ollama list) und der Ollama-Server läuft (ollama serve). Überprüfen Sie die Protokolle unter~/.ollama/logs.
API antwortet nicht:
- Problem: API-Anfragen an
localhost:11434schlagen fehl. - Lösung: Stellen Sie sicher, dass
ollama serveaktiv ist und Port 11434 geöffnet ist. Verwenden Sienetstat -tuln | grep 11434zur Bestätigung.
Langsame Leistung:
- Problem: CPU-basierte Inferenz ist träge.
- Lösung: Aktivieren Sie die GPU-Beschleunigung mit den entsprechenden Treibern oder verwenden Sie ein kleineres Modell wie gpt-oss-20b.
Bei anhaltenden Problemen konsultieren Sie das Ollama GitHub oder die Hugging Face-Community für **GPT-OSS**-Support.
Schritt 8: GPT-OSS mit Open WebUI erweitern
Für eine benutzerfreundliche Oberfläche koppeln Sie Ollama mit Open WebUI, einem browserbasierten Dashboard für **GPT-OSS**:
Open WebUI installieren:
- Verwenden Sie Docker:
docker run -d -p 3000:8080 --name open-webui ghcr.io/open-webui/open-webui:main
Auf die Oberfläche zugreifen:
- Öffnen Sie
http://localhost:3000in Ihrem Browser. - Wählen Sie
gpt-oss-20bodergpt-oss-120bund beginnen Sie zu chatten. Funktionen umfassen Chat-Verlauf, Prompt-Speicherung und Modellwechsel.
Dokument-Uploads:
- Laden Sie Dateien für kontextbezogene Antworten hoch (z. B. Code-Reviews oder Datenanalyse) mithilfe von Retrieval-Augmented Generation (RAG).
Open WebUI vereinfacht die Interaktion für nicht-technische Benutzer und ergänzt die technischen Debugging-Fähigkeiten von **Apidog**.
Fazit: GPT-OSS mit Ollama und Apidog entfesseln
Das lokale Ausführen von GPT-OSS mit Ollama ermöglicht es Ihnen, die Open-Weight-Modelle von OpenAI kostenlos zu nutzen, mit voller Kontrolle über Datenschutz und Anpassung. Indem Sie diesem Leitfaden gefolgt sind, haben Sie gelernt, Ollama zu installieren, **GPT-OSS**-Modelle herunterzuladen, das Verhalten anzupassen, über die API zu integrieren und mit **Apidog** zu debuggen. Ob Sie KI-gestützte Anwendungen entwickeln oder mit Denkaufgaben experimentieren, diese Einrichtung bietet unübertroffene Flexibilität. Kleine Anpassungen, wie das Anpassen von Parametern oder die Verwendung der Visualisierung von **Apidog**, können Ihren Workflow erheblich verbessern. Beginnen Sie noch heute, lokale KI zu erkunden und das Potenzial von **GPT-OSS** freizuschalten!