
Die lokale Ausführung von Gemma 3 mit Ollama gibt Ihnen die volle Kontrolle über Ihre KI-Umgebung, ohne sich auf Cloud-Dienste verlassen zu müssen. Dieser Leitfaden führt Sie durch die Einrichtung von Ollama, das Herunterladen von Gemma 3 und die Ausführung auf Ihrem Rechner.
Fangen wir an.
Warum Gemma 3 lokal mit Ollama ausführen?
„Warum sollte man Gemma 3 lokal ausführen?“ Nun, es gibt einige überzeugende Gründe. Zum einen gibt Ihnen die lokale Bereitstellung die volle Kontrolle über Ihre Daten und Ihre Privatsphäre – Sie müssen keine sensiblen Informationen in die Cloud senden. Außerdem ist es kostengünstig, da Sie keine laufenden API-Nutzungsgebühren zahlen müssen. Darüber hinaus bedeutet die Effizienz von Gemma 3, dass selbst das 27B-Modell auf einer einzigen GPU ausgeführt werden kann, was es für Entwickler mit bescheidener Hardware zugänglich macht.
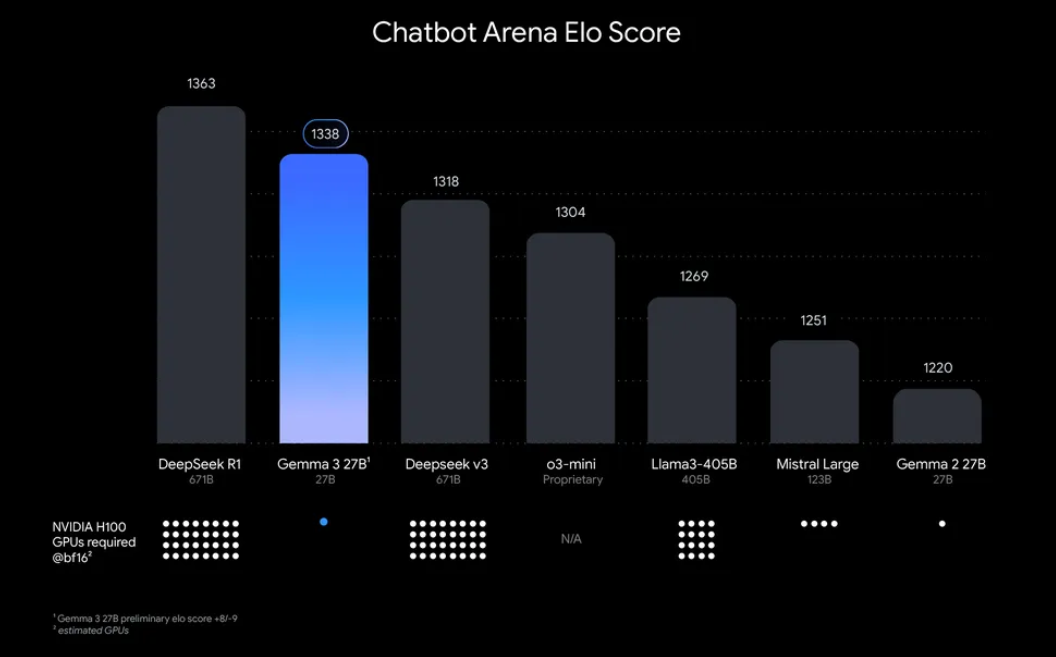
Ollama, eine leichtgewichtige Plattform für die lokale Ausführung großer Sprachmodelle (LLMs), vereinfacht diesen Prozess. Es verpackt alles, was Sie benötigen – Modellgewichte, Konfigurationen und Abhängigkeiten – in ein benutzerfreundliches Format. Diese Kombination aus Gemma 3 und Ollama ist perfekt zum Basteln, Erstellen von Anwendungen oder Testen von KI-Workflows auf Ihrem Rechner. Also krempeln wir die Ärmel hoch und legen los!
Was Sie benötigen, um Gemma 3 mit Ollama auszuführen
Bevor wir uns mit der Einrichtung befassen, stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllen:
- Ein kompatibler Rechner: Sie benötigen einen Computer mit einer GPU (vorzugsweise NVIDIA für optimale Leistung) oder einer leistungsstarken CPU. Das 27B-Modell benötigt erhebliche Ressourcen, aber kleinere Versionen wie 1B oder 4B können auf weniger leistungsstarker Hardware ausgeführt werden.
- Ollama installiert: Laden Sie Ollama herunter und installieren Sie es, verfügbar für MacOS, Windows und Linux. Sie können es von ollama.com beziehen.
- Grundkenntnisse der Befehlszeile: Sie interagieren mit Ollama über das Terminal oder die Eingabeaufforderung.
- Internetverbindung: Zunächst müssen Sie Gemma 3-Modelle herunterladen, aber nach dem Herunterladen können Sie sie offline ausführen.
- Optional: Apidog für API-Tests: Wenn Sie Gemma 3 in eine API integrieren oder ihre Antworten programmgesteuert testen möchten, kann die intuitive Benutzeroberfläche von Apidog Ihnen Zeit und Mühe sparen.
Nun, da Sie ausgestattet sind, wollen wir uns mit dem Installations- und Einrichtungsprozess befassen.
Schritt-für-Schritt-Anleitung: Installieren von Ollama und Herunterladen von Gemma 3
1. Installieren Sie Ollama auf Ihrem Rechner
Ollama macht die lokale LLM-Bereitstellung zum Kinderspiel, und die Installation ist unkompliziert. So geht's:
- Für MacOS/Windows: Besuchen Sie ollama.com und laden Sie das Installationsprogramm für Ihr Betriebssystem herunter. Befolgen Sie die Anweisungen auf dem Bildschirm, um die Installation abzuschließen.
- Für Linux (z. B. Ubuntu): Öffnen Sie Ihr Terminal und führen Sie den folgenden Befehl aus:
curl -fsSL https://ollama.com/install.sh | sh
Dieses Skript erkennt automatisch Ihre Hardware (einschließlich GPUs) und installiert Ollama.
Überprüfen Sie nach der Installation die Installation, indem Sie Folgendes ausführen:
ollama --version

Sie sollten die aktuelle Versionsnummer sehen, die bestätigt, dass Ollama einsatzbereit ist.
2. Gemma 3-Modelle mit Ollama abrufen
Die Modellbibliothek von Ollama enthält Gemma 3, dank der Integration mit Plattformen wie Hugging Face und den KI-Angeboten von Google. Um Gemma 3 herunterzuladen, verwenden Sie den Befehl ollama pull.
ollama pull gemma3

Für kleinere Modelle können Sie Folgendes verwenden:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
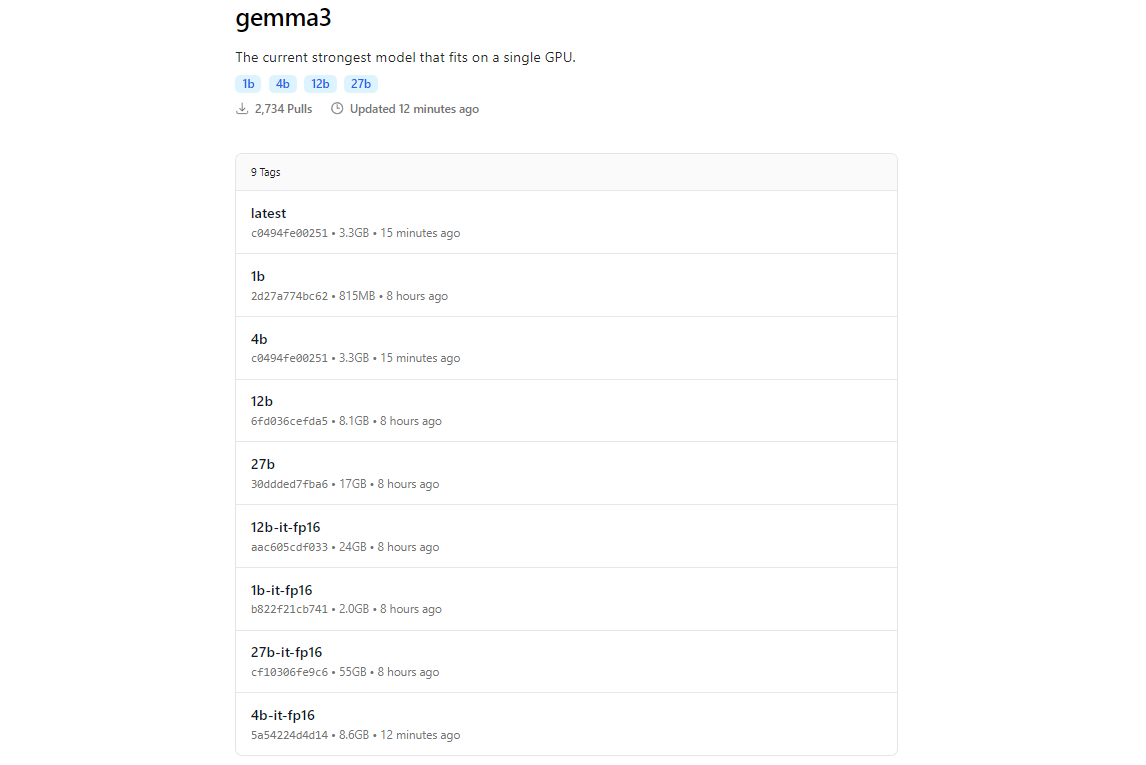
Die Downloadgröße variiert je nach Modell. Erwarten Sie, dass das 27B-Modell mehrere Gigabyte groß ist, also stellen Sie sicher, dass Sie über ausreichend Speicherplatz verfügen. Gemma 3-Modelle sind auf Effizienz optimiert, benötigen aber dennoch anständige Hardware für die größeren Varianten.
3. Überprüfen Sie die Installation
Überprüfen Sie nach dem Herunterladen, ob das Modell verfügbar ist, indem Sie alle Modelle auflisten:
ollama list

Sie sollten gemma3 (oder Ihre gewählte Größe) in der Liste sehen. Wenn es da ist, können Sie Gemma 3 lokal ausführen!
Gemma 3 mit Ollama ausführen: Interaktiver Modus und API-Integration
Interaktiver Modus: Chatten mit Gemma 3
Mit dem interaktiven Modus von Ollama können Sie direkt über das Terminal mit Gemma 3 chatten. Führen Sie dazu Folgendes aus:
ollama run gemma3
Sie sehen eine Eingabeaufforderung, in die Sie Abfragen eingeben können. Versuchen Sie zum Beispiel:
What are the key features of Gemma 3?
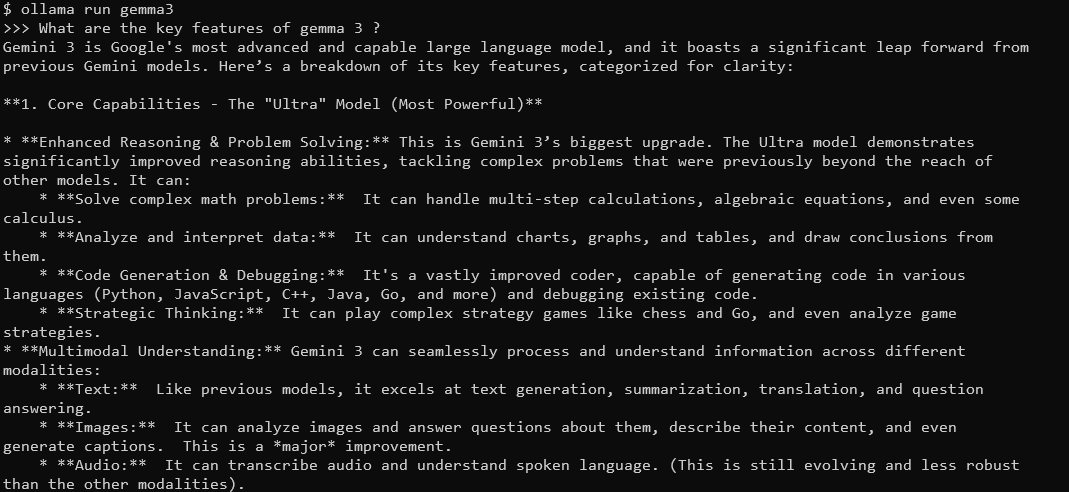
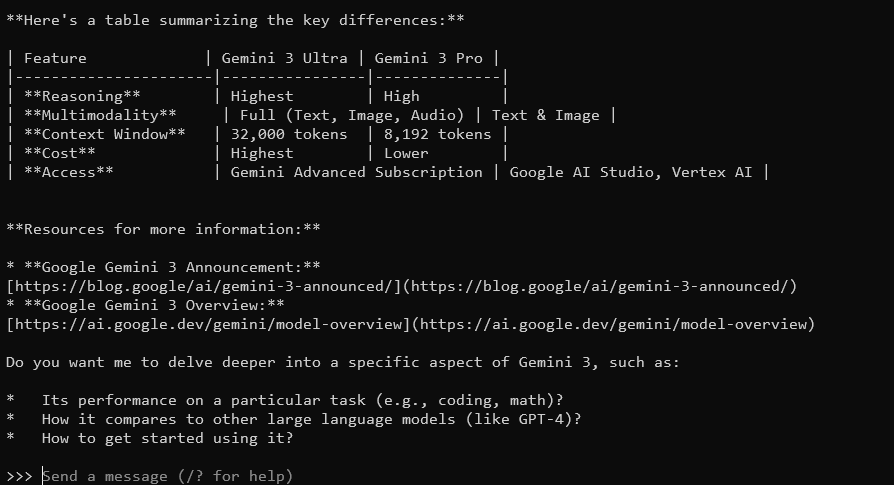
Gemma 3 wird mit seinem 128K-Kontextfenster und seinen multimodalen Fähigkeiten mit detaillierten, kontextbezogenen Antworten antworten. Es unterstützt über 140 Sprachen und kann Text, Bilder und sogar Videoeingaben (für bestimmte Größen) verarbeiten.
Um zu beenden, geben Sie Ctrl+D oder /bye ein.
Integration von Gemma 3 mit der Ollama-API
Wenn Sie Anwendungen erstellen oder Interaktionen automatisieren möchten, stellt Ollama eine API bereit, die Sie verwenden können. Hier glänzt Apidog – seine benutzerfreundliche Oberfläche hilft Ihnen, API-Anfragen effizient zu testen und zu verwalten. So geht's:
Starten Sie den Ollama-Server: Führen Sie den folgenden Befehl aus, um den API-Server von Ollama zu starten:
ollama serve
Dadurch wird der Server standardmäßig auf localhost:11434 gestartet.
API-Anfragen stellen: Sie können über HTTP-Anfragen mit Gemma 3 interagieren. Verwenden Sie beispielsweise curl, um eine Eingabeaufforderung zu senden:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "What is the capital of France?"}'
Die Antwort enthält die Ausgabe von Gemma 3, formatiert als JSON.
Verwenden Sie Apidog zum Testen: Laden Sie Apidog kostenlos herunter und erstellen Sie eine API-Anfrage, um die Antworten von Gemma 3 zu testen. Mit der visuellen Oberfläche von Apidog können Sie den Endpunkt (http://localhost:11434/api/generate) eingeben, die JSON-Nutzlast festlegen und Antworten analysieren, ohne komplexen Code schreiben zu müssen. Dies ist besonders nützlich für das Debuggen und Optimieren Ihrer Integration.
Schritt-für-Schritt-Anleitung zur Verwendung von SSE-Tests auf Apidog
Gehen wir den Prozess der Verwendung der optimierten SSE-Testfunktion auf Apidog durch, komplett mit den neuen Auto-Merge-Erweiterungen. Befolgen Sie diese Schritte, um Ihr Echtzeit-Debugging-Erlebnis einzurichten und zu maximieren.
Schritt 1: Erstellen Sie eine neue API-Anfrage
Beginnen Sie mit dem Start eines neuen HTTP-Projekts auf Apidog. Fügen Sie einen neuen Endpunkt hinzu und geben Sie die URL für den Endpunkt Ihres API- oder KI-Modells ein. Dies ist Ihr Ausgangspunkt für das Testen und Debuggen Ihrer Echtzeit-Datenströme.
Schritt 2: Senden Sie die Anfrage
Sobald Ihr Endpunkt eingerichtet ist, senden Sie die API-Anfrage. Beachten Sie sorgfältig die Antwortheader. Wenn der Header Content-Type: text/event-stream enthält, erkennt und interpretiert Apidog die Antwort automatisch als SSE-Stream. Diese Erkennung ist entscheidend für den anschließenden Auto-Merging-Prozess.

Schritt 3: Überwachen Sie die Echtzeit-Zeitleiste
Nachdem die SSE-Verbindung hergestellt wurde, öffnet Apidog eine dedizierte Zeitleistenansicht, in der alle eingehenden SSE-Ereignisse in Echtzeit angezeigt werden. Diese Zeitleiste wird kontinuierlich aktualisiert, wenn neue Daten eintreffen, sodass Sie den Datenfluss mit höchster Präzision überwachen können. Die Zeitleiste ist nicht nur ein Rohdaten-Dump, sondern eine sorgfältig strukturierte Visualisierung, mit der Sie genau sehen können, wann und wie Daten übertragen werden.
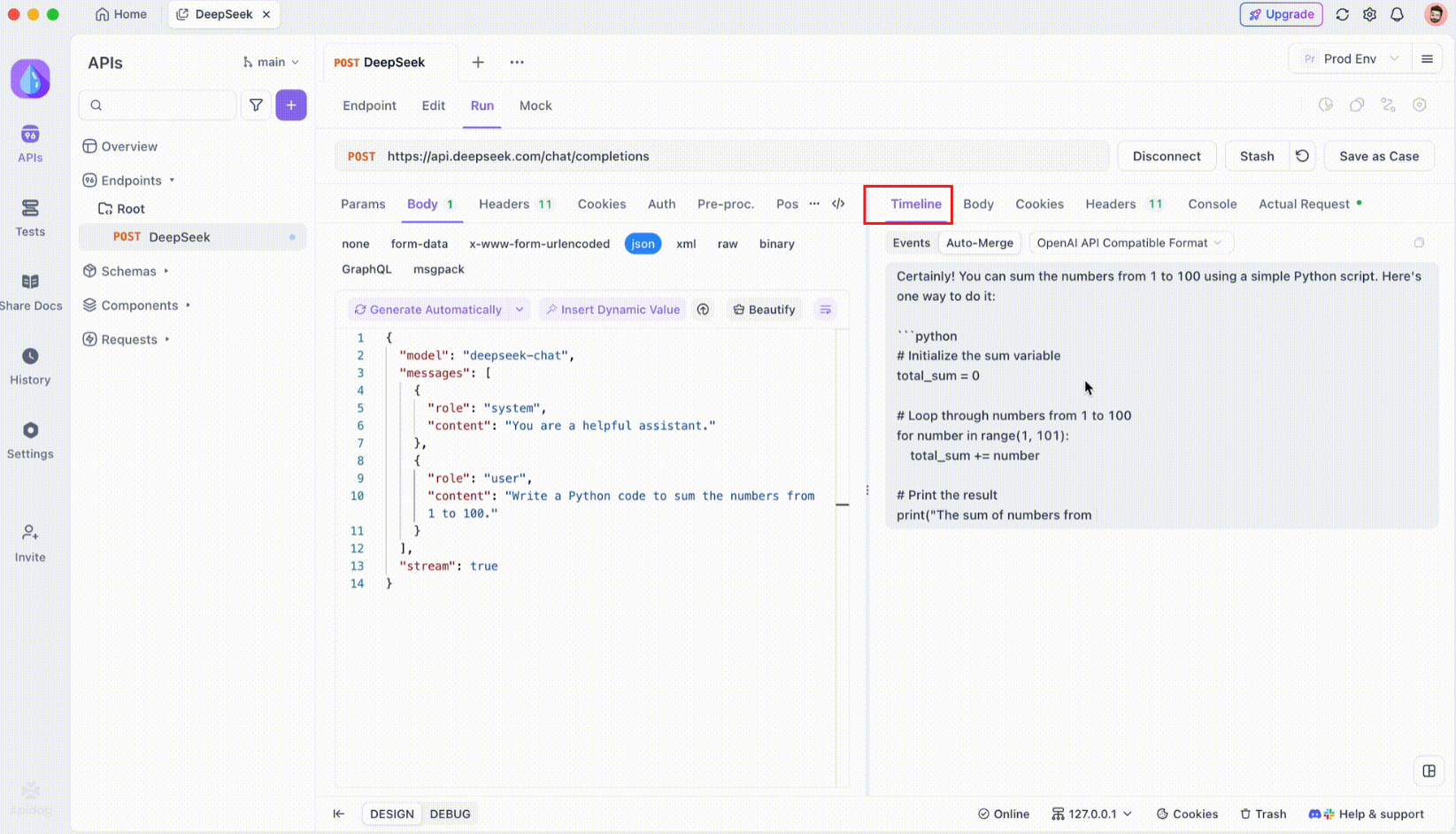
Schritt 4: Auto-Merge-Nachricht
Hier geschieht die Magie. Mit den Auto-Merge-Erweiterungen erkennt Apidog automatisch gängige KI-Modellformate und führt fragmentierte SSE-Antworten zu einer vollständigen Antwort zusammen. Dieser Schritt beinhaltet:
- Automatische Erkennung: Apidog prüft, ob die Antwort in einem unterstützten Format vorliegt (OpenAI, Gemini oder Claude).
- Nachrichten zusammenführen: Wenn das Format erkannt wird, kombiniert die Plattform automatisch alle SSE-Fragmente und liefert eine nahtlose, vollständige Antwort.
- Erweiterte Visualisierung: Für bestimmte KI-Modelle, wie z. B. DeepSeek R1, zeigt die Zeitleiste auch den Denkprozess des Modells an und bietet eine zusätzliche Ebene des Einblicks in die Argumentation hinter der generierten Antwort.
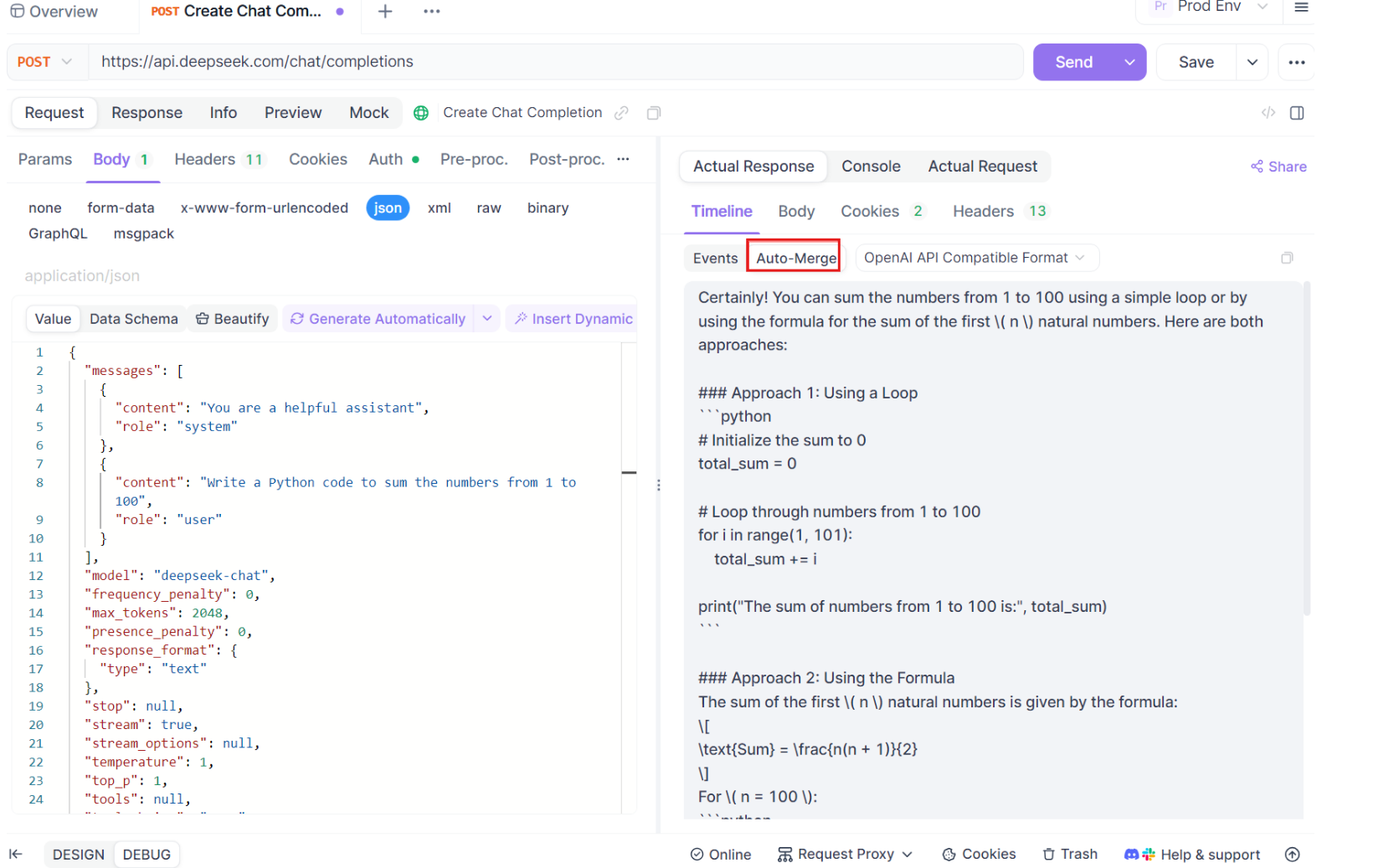
Diese Funktion ist besonders nützlich im Umgang mit KI-gesteuerten Anwendungen, da sichergestellt wird, dass jeder Teil der Antwort erfasst und vollständig ohne manuelles Eingreifen dargestellt wird.
Schritt 5: Konfigurieren Sie JSONPath-Extraktionsregeln
Nicht alle SSE-Antworten entsprechen automatisch den integrierten Formaten. Wenn Sie mit JSON-Antworten arbeiten, die eine benutzerdefinierte Extraktion erfordern, können Sie mit Apidog JSONPath-Regeln konfigurieren. Wenn Ihre rohe SSE-Antwort beispielsweise ein JSON-Objekt enthält und Sie das Feld content extrahieren müssen, können Sie eine JSONPath-Konfiguration wie folgt einrichten:
- JSONPath:
$.choices[0].message.content - Erläuterung:
$bezieht sich auf die Wurzel des JSON-Objekts.choices[0]wählt das erste Element des Arrayschoicesaus.message.contentgibt das Inhaltsfeld innerhalb des Nachrichtenobjekts an.
Diese Konfiguration weist Apidog an, wie die gewünschten Daten aus Ihrer SSE-Antwort extrahiert werden sollen, um sicherzustellen, dass auch nicht standardmäßige Antworten effektiv verarbeitet werden.
Fazit
Die lokale Ausführung von Gemma 3 mit Ollama ist eine aufregende Möglichkeit, die fortschrittlichen KI-Funktionen von Google zu nutzen, ohne Ihren Rechner zu verlassen. Von der Installation von Ollama und dem Herunterladen des Modells bis zur Interaktion über das Terminal oder die API hat Sie dieser Leitfaden durch jeden Schritt geführt. Mit seinen multimodalen Funktionen, der mehrsprachigen Unterstützung und der beeindruckenden Leistung ist Gemma 3 ein Game-Changer für Entwickler und KI-Enthusiasten gleichermaßen. Vergessen Sie nicht, Tools wie Apidog für nahtlose API-Tests und -Integration zu nutzen – laden Sie es noch heute kostenlos herunter, um Ihre Gemma 3-Projekte zu verbessern!
Egal, ob Sie mit dem 1B-Modell auf einem Laptop basteln oder die Grenzen des 27B-Modells auf einem GPU-Rig ausreizen, Sie sind jetzt bereit, die Möglichkeiten zu erkunden. Viel Spaß beim Programmieren, und lassen Sie uns sehen, welche unglaublichen Dinge Sie mit Gemma 3 bauen!


