
Large Language Models (LLMs) wie Qwen3 revolutionieren die KI-Landschaft mit ihren beeindruckenden Fähigkeiten in den Bereichen Programmierung, Argumentation und dem Verständnis natürlicher Sprache. Entwickelt vom Qwen-Team bei Alibaba, bietet Qwen3 quantisierte Modelle, die eine effiziente lokale Bereitstellung ermöglichen und es Entwicklern, Forschern und Enthusiasten ermöglichen, diese leistungsstarken Modelle auf ihrer eigenen Hardware auszuführen. Egal, ob Sie Ollama, LM Studio oder vLLM verwenden, dieser Leitfaden führt Sie durch den Prozess der Einrichtung und Ausführung von quantisierten Qwen3-Modellen lokal.
In diesem technischen Leitfaden werden wir den Einrichtungsprozess, die Modellauswahl, die Bereitstellungsmethoden und die API-Integration untersuchen. Fangen wir an.
Was sind Qwen3 quantisierte Modelle?
Qwen3 ist die neueste Generation von LLMs von Alibaba, die für hohe Leistung bei Aufgaben wie Programmierung, Mathematik und allgemeiner Argumentation entwickelt wurde. Quantisierte Modelle, wie z. B. in den Formaten BF16, FP8, GGUF, AWQ und GPTQ, reduzieren die Rechen- und Speicheranforderungen und sind somit ideal für die lokale Bereitstellung auf Hardware für Endverbraucher.
Die Qwen3-Familie umfasst verschiedene Modelle:
- Qwen3-235B-A22B (MoE): Ein Mixture-of-Experts-Modell mit den Formaten BF16, FP8, GGUF und GPTQ-int4.
- Qwen3-30B-A3B (MoE): Eine weitere MoE-Variante mit ähnlichen Quantisierungsoptionen.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Dichte Modelle, die in den Formaten BF16, FP8, GGUF, AWQ und GPTQ-int8 verfügbar sind.
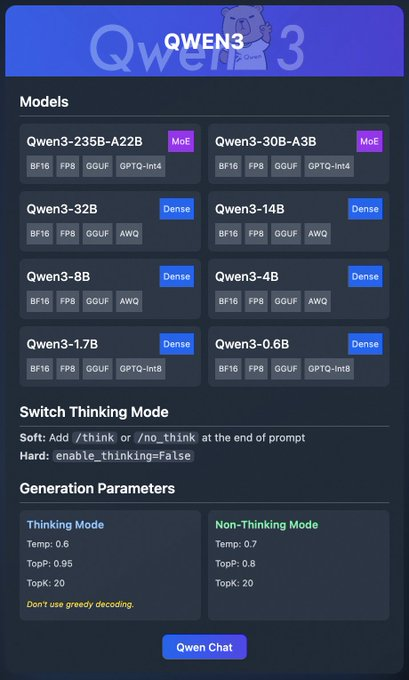
Diese Modelle unterstützen eine flexible Bereitstellung über Plattformen wie Ollama, LM Studio und vLLM, die wir im Detail behandeln werden. Darüber hinaus bietet Qwen3 Funktionen wie den "Thinking Mode", der für eine bessere Argumentation umgeschaltet werden kann, und Generierungsparameter zur Feinabstimmung der Ausgabequalität.
Nachdem wir nun die Grundlagen verstanden haben, gehen wir zu den Voraussetzungen für die lokale Ausführung von Qwen3 über.
Voraussetzungen für die lokale Ausführung von Qwen3
Bevor Sie quantisierte Qwen3-Modelle bereitstellen, stellen Sie sicher, dass Ihr System die folgenden Anforderungen erfüllt:
Hardware:
- Eine moderne CPU oder GPU (NVIDIA GPUs werden für vLLM empfohlen).
- Mindestens 16 GB RAM für kleinere Modelle wie Qwen3-4B; 32 GB oder mehr für größere Modelle wie Qwen3-32B.
- Ausreichend Speicher (z. B. Qwen3-235B-A22B GGUF kann ~150 GB erfordern).
Software:
- Ein kompatibles Betriebssystem (Windows, macOS oder Linux).
- Python 3.8+ für vLLM und API-Interaktionen.
- Docker (optional, für vLLM).
- Git zum Klonen von Repositories.
Abhängigkeiten:
- Installieren Sie erforderliche Bibliotheken wie
torch,transformersundvllm(für vLLM). - Laden Sie Ollama- oder LM Studio-Binärdateien von deren offiziellen Websites herunter.
Mit diesen Voraussetzungen können wir nun mit dem Herunterladen der quantisierten Qwen3-Modelle fortfahren.
Schritt 1: Herunterladen von quantisierten Qwen3-Modellen
Zuerst müssen Sie die quantisierten Modelle von vertrauenswürdigen Quellen herunterladen. Das Qwen-Team stellt Qwen3-Modelle auf Hugging Face und ModelScope bereit
- Hugging Face: Qwen3 Collection
- ModelScope: Qwen3 Collection
So laden Sie von Hugging Face herunter
- Besuchen Sie die Hugging Face Qwen3-Sammlung.
- Wählen Sie ein Modell aus, z. B. Qwen3-4B im GGUF-Format für eine einfache Bereitstellung.
- Klicken Sie auf die Schaltfläche "Download" oder verwenden Sie den Befehl
git clone, um die Modelldateien abzurufen:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Speichern Sie die Modelldateien in einem Verzeichnis, z. B.
/models/qwen3-4b-gguf.
So laden Sie von ModelScope herunter
- Navigieren Sie zur ModelScope Qwen3-Sammlung.
- Wählen Sie Ihr gewünschtes Modell und Quantisierungsformat (z. B. AWQ oder GPTQ).
- Laden Sie die Dateien manuell herunter oder verwenden Sie deren API für den programmgesteuerten Zugriff.
Sobald die Modelle heruntergeladen sind, wollen wir uns ansehen, wie man sie mit Ollama bereitstellt.
Schritt 2: Bereitstellen von Qwen3 mit Ollama
Ollama bietet eine benutzerfreundliche Möglichkeit, LLMs lokal mit minimalem Setup auszuführen. Es unterstützt das GGUF-Format von Qwen3 und ist somit ideal für Anfänger.
Ollama installieren
- Besuchen Sie die offizielle Ollama-Website und laden Sie die Binärdatei für Ihr Betriebssystem herunter.
- Installieren Sie Ollama, indem Sie das Installationsprogramm ausführen oder den Befehlszeilenanweisungen folgen:
curl -fsSL https://ollama.com/install.sh | sh
- Überprüfen Sie die Installation:
ollama --version
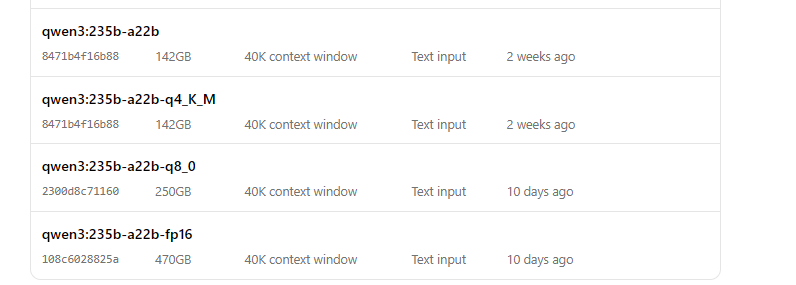
Führen Sie Qwen3 mit Ollama aus
- Starten Sie das Modell:
ollama run qwen3:235b-a22b-q8_0- Sobald das Modell ausgeführt wird, können Sie über die Befehlszeile mit ihm interagieren:
>>> Hello, how can I assist you today?
Ollama bietet auch einen lokalen API-Endpunkt (normalerweise http://localhost:11434) für den programmgesteuerten Zugriff, den wir später mit Apidog testen werden.
Als Nächstes wollen wir uns ansehen, wie man LM Studio zum Ausführen von Qwen3 verwendet.
Schritt 3: Bereitstellen von Qwen3 mit LM Studio
LM Studio ist ein weiteres beliebtes Tool zum lokalen Ausführen von LLMs, das eine grafische Benutzeroberfläche für die Modellverwaltung bietet.
LM Studio installieren
- Laden Sie LM Studio von der offiziellen Website herunter.
- Installieren Sie die Anwendung, indem Sie den Anweisungen auf dem Bildschirm folgen.
- Starten Sie LM Studio und stellen Sie sicher, dass es ausgeführt wird.
Laden Sie Qwen3 in LM Studio
Gehen Sie in LM Studio zum Abschnitt "Local Models".
Klicken Sie auf "Add Model" und suchen Sie nach dem Modell, um es herunterzuladen:
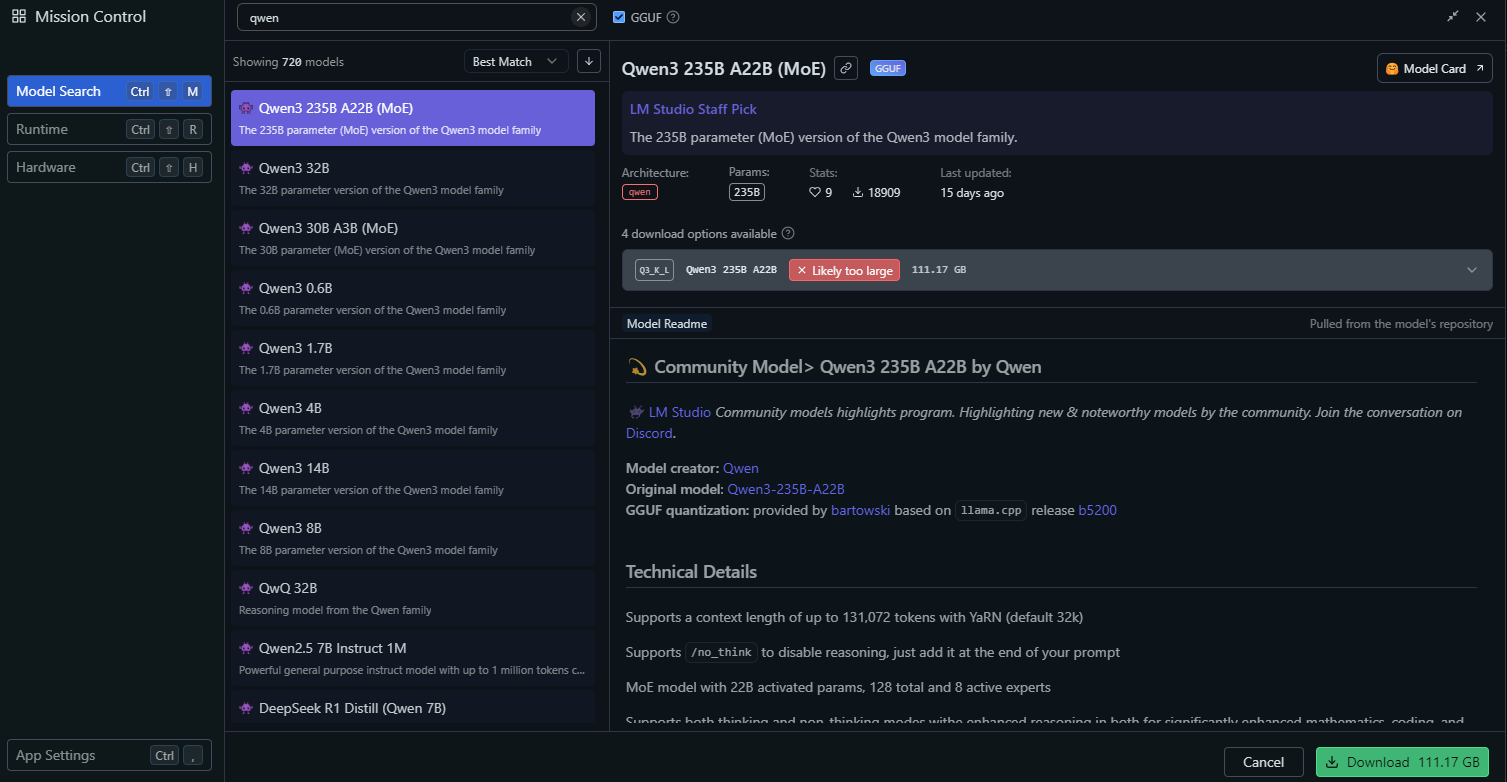
Konfigurieren Sie die Modelleinstellungen, wie z. B.:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
Diese Einstellungen entsprechen den empfohlenen Parametern für den Thinking Mode von Qwen3.
Starten Sie den Modellserver, indem Sie auf "Start Server" klicken. LM Studio stellt einen lokalen API-Endpunkt bereit (z. B. http://localhost:1234).
Interagieren Sie mit Qwen3 in LM Studio
- Verwenden Sie die integrierte Chat-Oberfläche von LM Studio, um das Modell zu testen.
- Greifen Sie alternativ über den API-Endpunkt des Modells auf das Modell zu, was wir im Abschnitt API-Tests untersuchen werden.
Nachdem LM Studio eingerichtet ist, wollen wir uns einer fortgeschritteneren Bereitstellungsmethode mit vLLM zuwenden.
Schritt 4: Bereitstellen von Qwen3 mit vLLM
vLLM ist eine Hochleistungs-Serving-Lösung, die für LLMs optimiert ist und die quantisierten FP8- und AWQ-Modelle von Qwen3 unterstützt. Es ist ideal für Entwickler, die robuste Anwendungen erstellen.
vLLM installieren
- Stellen Sie sicher, dass Python 3.8+ auf Ihrem System installiert ist.
- Installieren Sie vLLM mit pip:
pip install vllm
- Überprüfen Sie die Installation:
python -c "import vllm; print(vllm.__version__)"
Führen Sie Qwen3 mit vLLM aus
Starten Sie einen vLLM-Server mit Ihrem Qwen3-Modell
# Laden und Ausführen des Modells:
vllm serve "Qwen/Qwen3-235B-A22B"Das Flag --enable-thinking=False deaktiviert den Thinking Mode von Qwen3.
Sobald der Server startet, stellt er einen API-Endpunkt unter http://localhost:8000 bereit.
Konfigurieren Sie vLLM für optimale Leistung
vLLM unterstützt erweiterte Konfigurationen, wie z. B.:
- Tensor Parallelism: Passen Sie
--tensor-parallel-sizebasierend auf Ihrem GPU-Setup an. - Context Length: Qwen3 unterstützt bis zu 32.768 Tokens, die über
--max-model-len 32768eingestellt werden können. - Generation Parameters: Verwenden Sie die API, um
temperature,top_pundtop_kfestzulegen (z. B. 0,7, 0,8, 20 für den Non-Thinking-Mode).
Während vLLM läuft, wollen wir den API-Endpunkt mit Apidog testen.
Schritt 5: Testen Sie die Qwen3-API mit Apidog
Apidog ist ein leistungsstarkes Tool zum Testen von API-Endpunkten und eignet sich daher perfekt für die Interaktion mit Ihrem lokal bereitgestellten Qwen3-Modell.
Richten Sie Apidog ein
- Laden Sie Apidog von der offiziellen Website herunter und installieren Sie es.
- Starten Sie Apidog und erstellen Sie ein neues Projekt.
Testen Sie die Ollama-API
- Erstellen Sie in Apidog eine neue API-Anfrage.
- Legen Sie den Endpunkt auf
http://localhost:11434/api/generatefest. - Konfigurieren Sie die Anfrage:
- Methode: POST
- Body (JSON):
{
"model": "qwen3-4b",
"prompt": "Hello, how can I assist you today?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Senden Sie die Anfrage und überprüfen Sie die Antwort.
Testen Sie die vLLM-API
- Erstellen Sie in Apidog eine weitere API-Anfrage.
- Legen Sie den Endpunkt auf
http://localhost:8000/v1/completionsfest. - Konfigurieren Sie die Anfrage:
- Methode: POST
- Body (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Write a Python script to calculate factorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Senden Sie die Anfrage und überprüfen Sie die Ausgabe.
Apidog erleichtert die Validierung Ihrer Qwen3-Bereitstellung und stellt sicher, dass die API ordnungsgemäß funktioniert. Nun wollen wir die Leistung des Modells optimieren.
Schritt 6: Feinabstimmung der Qwen3-Leistung
Um die Leistung von Qwen3 zu optimieren, passen Sie die folgenden Einstellungen basierend auf Ihrem Anwendungsfall an:
Thinking Mode
Qwen3 unterstützt einen "Thinking Mode" für erweiterte Argumentation, wie im X-Post-Bild hervorgehoben. Sie können ihn auf zwei Arten steuern:
- Soft Switch: Fügen Sie
/thinkoder/no_thinkzu Ihrer Eingabeaufforderung hinzu.
- Beispiel:
Solve this math problem /think.
- Hard Switch: Deaktivieren Sie das Denken vollständig in vLLM mit
--enable-thinking=False.
Generierungsparameter
Optimieren Sie die Generierungsparameter für eine bessere Ausgabequalität:
- Temperature: Verwenden Sie 0,6 für den Thinking Mode oder 0,7 für den Non-Thinking-Mode.
- Top-P: Stellen Sie auf 0,95 (Thinking) oder 0,8 (Non-Thinking) ein.
- Top-K: Verwenden Sie 20 für beide Modi.
- Vermeiden Sie gieriges Decodieren, wie vom Qwen-Team empfohlen.
Experimentieren Sie mit diesen Einstellungen, um das gewünschte Gleichgewicht zwischen Kreativität und Genauigkeit zu erreichen.
Behebung häufiger Probleme
Bei der Bereitstellung von Qwen3 können einige Probleme auftreten. Hier sind Lösungen für häufige Probleme:
Modell kann in Ollama nicht geladen werden:
- Stellen Sie sicher, dass der GGUF-Dateipfad in der
Modelfilekorrekt ist. - Überprüfen Sie, ob Ihr System über genügend Speicher verfügt, um das Modell zu laden.
vLLM Tensor Parallelism Fehler:
- Wenn Sie einen Fehler wie "output_size is not divisible by weight quantization block_n" sehen, reduzieren Sie die
--tensor-parallel-size(z. B. auf 4).
API-Anfrage schlägt in Apidog fehl:
- Vergewissern Sie sich, dass der Server (Ollama, LM Studio oder vLLM) ausgeführt wird.
- Überprüfen Sie die Endpunkt-URL und die Anforderungsnutzlast.
Durch die Behebung dieser Probleme können Sie ein reibungsloses Bereitstellungserlebnis gewährleisten.
Fazit
Das Ausführen von quantisierten Qwen3-Modellen lokal ist ein unkomplizierter Prozess mit Tools wie Ollama, LM Studio und vLLM. Egal, ob Sie ein Entwickler sind, der Anwendungen erstellt, oder ein Forscher, der mit LLMs experimentiert, Qwen3 bietet die Flexibilität und Leistung, die Sie benötigen. Indem Sie diesem Leitfaden folgen, haben Sie gelernt, wie Sie Modelle von Hugging Face und ModelScope herunterladen, sie mithilfe verschiedener Frameworks bereitstellen und ihre API-Endpunkte mit Apidog testen können.
Beginnen Sie noch heute mit der Erkundung von Qwen3 und erschließen Sie die Leistungsfähigkeit lokaler LLMs für Ihre Projekte!


