
Alibabas Qwen-Serie verschiebt weiterhin die Grenzen bei großen Sprachmodellen, und Qwen3-Next-80B-A3B sticht als Paradebeispiel für Effizienz in Verbindung mit hoher Leistung hervor. Ingenieure und Entwickler suchen Modelle, die eine robuste Argumentation ohne den Rechenaufwand dichter Giganten liefern. Dieses Modell erfüllt diese Anforderung direkt, indem es 80 Milliarden Parameter aufweist, aber nur 3 Milliarden pro Token aktiviert. Folglich erzielen Teams schnellere Inferenzgeschwindigkeiten und reduzierte Trainingskosten, was es ideal für reale Implementierungen macht.
In diesem Beitrag erkunden Sie die Kernkomponenten von Qwen3-Next-80B-A3B, sezieren seine innovative Architektur, überprüfen empirische Leistungsdaten und beherrschen seine API durch praktische Schritte. Darüber hinaus integrieren Sie Tools wie Apidog, um Ihren Workflow zu verbessern. Am Ende verfügen Sie über das Wissen, dieses Modell effektiv in Ihren Anwendungen einzusetzen.
Was definiert Qwen3-Next-80B-A3B? Kernfunktionen und Innovationen
Qwen3-Next-80B-A3B entstammt Alibabas Qwen-Familie als spärliches Mixture-of-Experts (MoE)-Modell, das sowohl auf Geschwindigkeit als auch auf Leistungsfähigkeit optimiert ist. Entwickler aktivieren während der Inferenz nur einen Bruchteil seiner Parameter, was zu erheblichen Ressourceneinsparungen führt. Insbesondere verwendet dieses Modell ein ultra-spärliches MoE-Setup mit 512 Experten, die 10 pro Token neben einem gemeinsamen Experten routen. Dadurch erreicht es die Leistung dichterer Gegenstücke wie Qwen3-32B, verbraucht aber deutlich weniger Energie.
Darüber hinaus unterstützt das Modell die Multi-Token-Vorhersage, eine Technik, die die spekulative Dekodierung beschleunigt. Diese Funktion ermöglicht es dem Modell, mehrere Tokens gleichzeitig zu generieren, was den Durchsatz in den Dekodierungsphasen erhöht. Entwickler schätzen dies für Anwendungen, die schnelle Antworten erfordern, wie Chatbots oder Echtzeit-Analysetools.
Die Serie umfasst Varianten, die auf spezifische Bedürfnisse zugeschnitten sind: das Basismodell für das allgemeine Vortraining, die Instruct-Version für fein abgestimmte Konversationsaufgaben und die Thinking-Variante für fortgeschrittene Schlussfolgerungsketten. Zum Beispiel übertrifft Qwen3-Next-80B-A3B-Thinking bei der Lösung komplexer Probleme Modelle wie Gemini-2.5-Flash-Thinking bei Benchmarks. Zusätzlich unterstützt es 119 Sprachen, was mehrsprachige Bereitstellungen ohne erneutes Training ermöglicht.
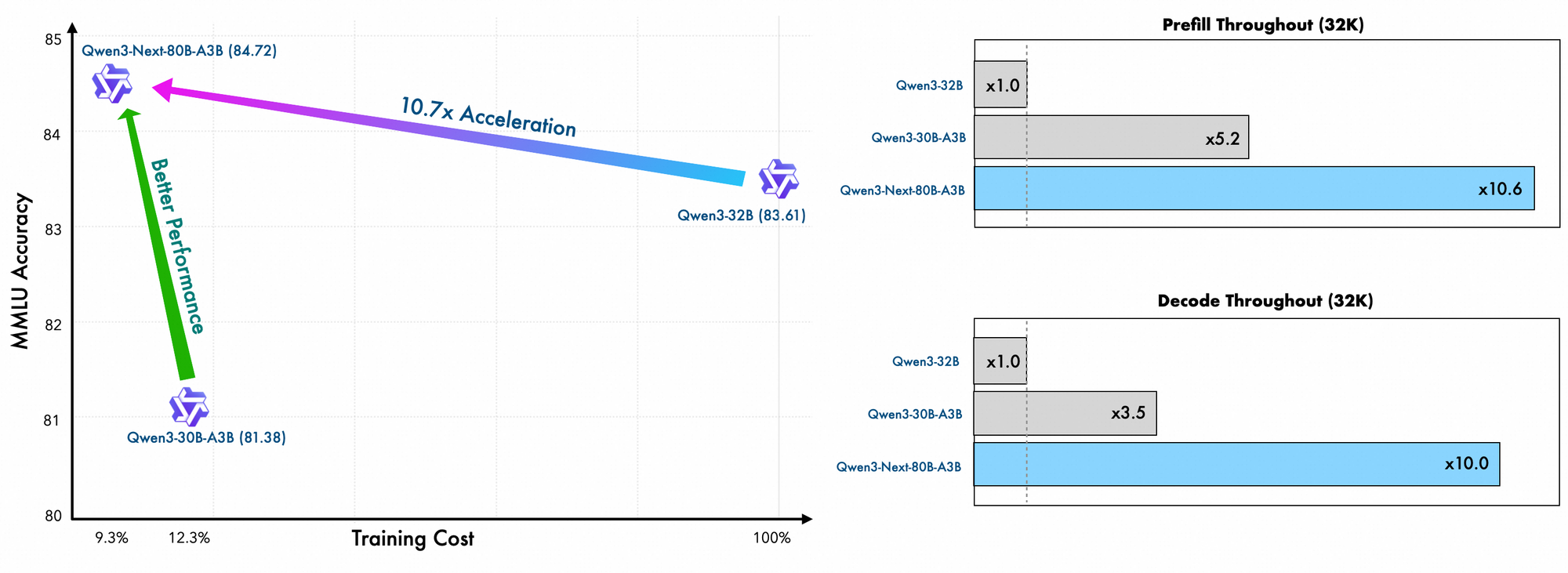
Trainingsdetails offenbaren weitere Effizienzen. Alibabas Ingenieure trainieren dieses Modell mit skalierungseffizienten Methoden vor, wodurch nur 10 % der Kosten im Vergleich zu Qwen3-32B anfallen. Sie nutzen ein hybrides Layout über 48 Schichten mit einer verborgenen Dimension von 2048, um eine ausgewogene Rechenverteilung zu gewährleisten. Folglich zeigt das Modell ein überragendes Verständnis langer Kontexte und behält die Genauigkeit über 32K Tokens hinaus bei, wo andere versagen.
In der Praxis ermöglichen diese Funktionen Entwicklern, KI-Lösungen kosteneffizient zu skalieren. Egal, ob Sie Unternehmenssuchmaschinen oder automatisierte Inhaltsgeneratoren entwickeln, Qwen3-Next-80B-A3B bildet das Rückgrat für innovative Anwendungen. Aufbauend auf dieser Grundlage untersucht der nächste Abschnitt die architektonischen Elemente, die solche Effizienzen ermöglichen.
Analyse der Architektur von Qwen3-Next-80B-A3B: Ein technischer Bauplan
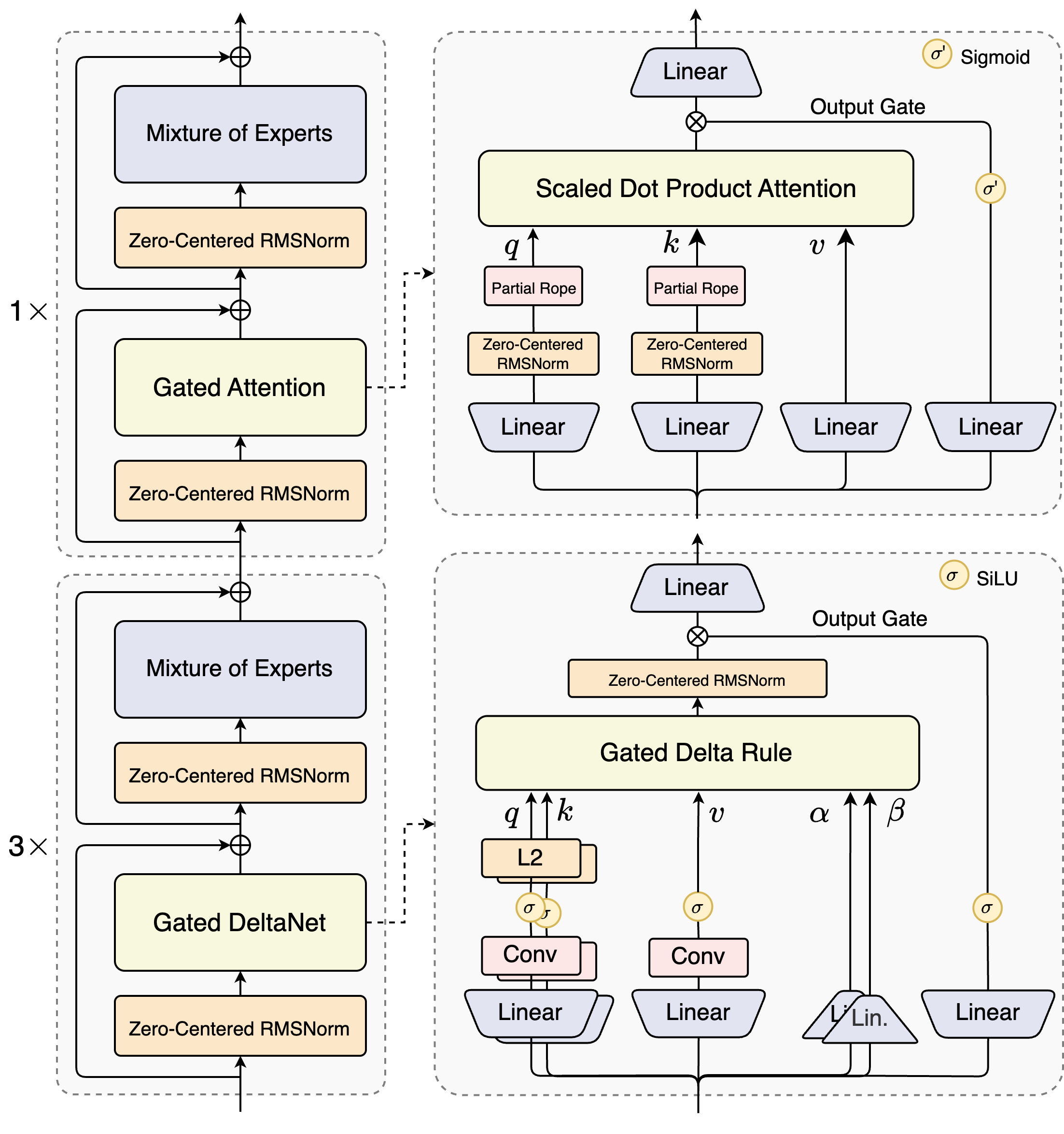
Die Architekten von Qwen3-Next-80B-A3B führen ein hybrides Design ein, das Gating-Mechanismen mit fortschrittlichen Normalisierungstechniken kombiniert. Im Mittelpunkt steht eine Mixture-of-Experts (MoE)-Schicht, in der sich Experten auf unterschiedliche Berechnungspfade spezialisieren. Das Modell routet Eingaben dynamisch und aktiviert eine Untermenge, um den Overhead zu minimieren. Zum Beispiel verarbeitet der Gated-Attention-Block Abfragen, Schlüssel und Werte durch partielle RoPE-Einbettungen und Zero-Centered-RMSNorm-Schichten, wodurch die Stabilität in langen Sequenzen verbessert wird.
Betrachten Sie das skalierte Dot-Product-Attention-Modul. Es integriert lineare Projektionen, gefolgt von Ausgabetoren, die durch Sigmoid-Aktivierungen moduliert werden. Dieser Aufbau ermöglicht eine präzise Kontrolle des Informationsflusses und verhindert eine Verdünnung in hochdimensionalen Räumen. Darüber hinaus geht Zero-Centered-RMSNorm diesen Operationen voraus und folgt ihnen, wodurch Aktivierungen um Null zentriert werden, um Gradientenprobleme während des Trainings zu mindern.
Das Diagramm veranschaulicht zwei primäre Blöcke: Der obere konzentriert sich auf Gated Attention mit skalierter Dot-Product-Attention, während der untere Gated DeltaNet hervorhebt. Im Attention-Pfad (1x Expansion) fließen Eingaben durch eine Zero-Centered-RMSNorm und dann in den Gated-Attention-Kern. Hier verwenden Query (q)-, Key (k)- und Value (v)-Projektionen partielle RoPE für die Positionskodierung. Nach der Attention speisen eine weitere RMSNorm und lineare Schichten in das MoE ein, das einen Sigmoid-Gated-Output verwendet.
Im Übergang zum DeltaNet-Pfad (3x Expansion) verwendet die Architektur eine Gated-Delta-Regel für verfeinerte Vorhersagen. Sie weist L2-Normalisierung auf q und k, Faltungsschichten zur lokalen Merkmalsextraktion und SiLU-Aktivierungen für Nichtlinearität auf. Das Ausgabetor, kombiniert mit einer linearen Projektion, gewährleistet kohärente Multi-Token-Ausgaben. Das Design dieses Blocks unterstützt die spekulative Dekodierung des Modells, bei der es mehrere Tokens im Voraus vorhersagt, die in nachfolgenden Durchläufen überprüft werden.
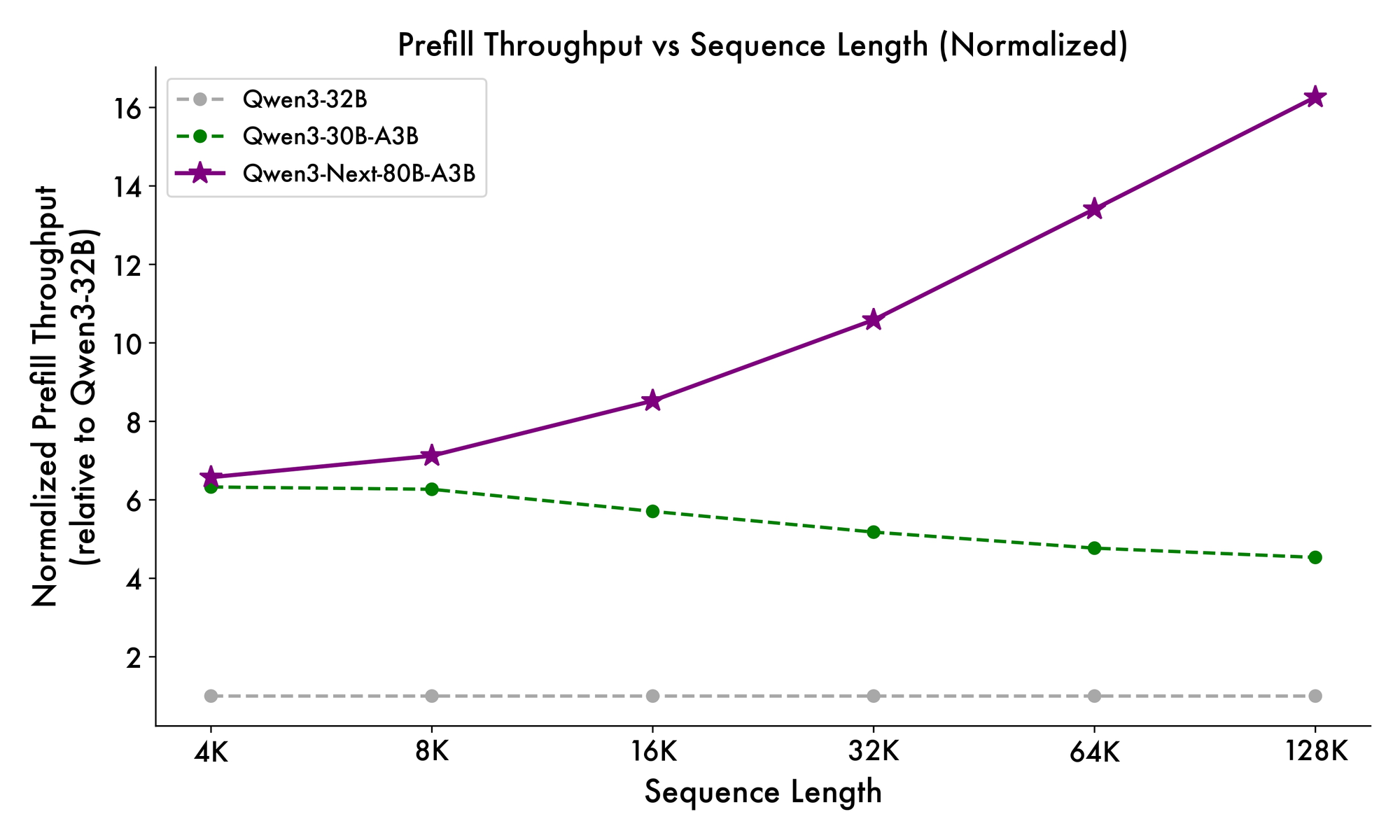
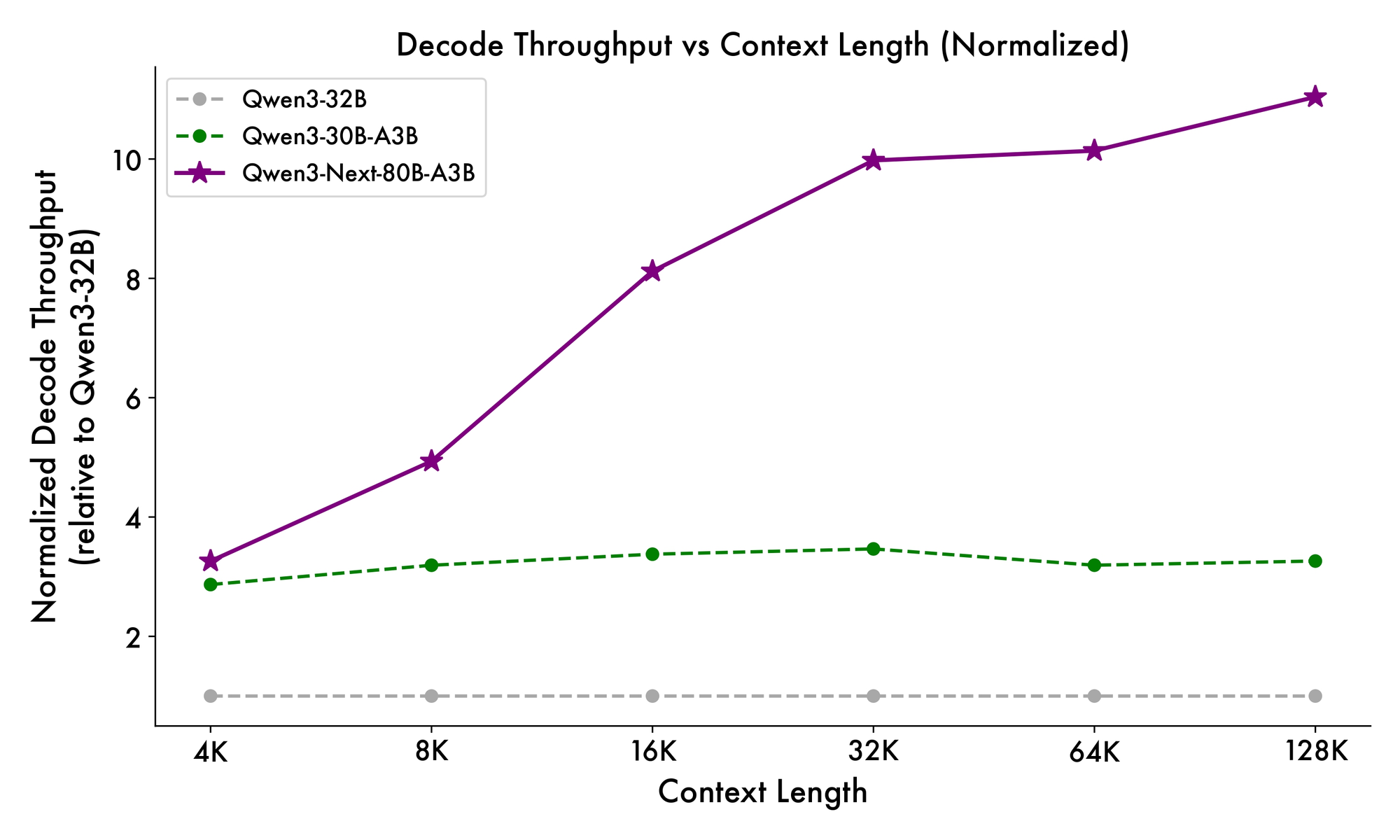
Darüber hinaus integriert die Gesamtstruktur einen gemeinsamen Experten im MoE, um gemeinsame Muster über Tokens hinweg zu verarbeiten und Redundanz zu reduzieren. Partielle RoPE-Einbettungen in Projektionen bewahren die Rotationsinvarianz für erweiterte Kontexte. Wie in Benchmarks gezeigt, liefert diese Konfiguration einen fast 7-fach höheren Durchsatz bei 4K Kontextlängen im Vergleich zu Qwen3-32B. Jenseits von 32K Tokens übersteigen die Geschwindigkeiten das 10-fache, wodurch es für Dokumentenanalyse- oder Codegenerierungsaufgaben geeignet ist.
Entwickler profitieren von dieser Modularität beim Fine-Tuning. Sie können Experten austauschen oder Routing-Schwellenwerte anpassen, um das Modell für Bereiche wie Finanzen oder Gesundheitswesen zu spezialisieren. Im Wesentlichen optimiert die Architektur nicht nur die Berechnung, sondern fördert auch die Anpassungsfähigkeit. Mit diesen Erkenntnissen wenden Sie sich nun der Frage zu, wie sich diese Elemente in messbare Leistungssteigerungen umsetzen lassen.
Benchmarking von Qwen3-Next-80B-A3B: Leistungsmetriken, die zählen
Empirische Evaluierungen positionieren Qwen3-Next-80B-A3B als führend in der effizienzorientierten KI. Bei Standard-Benchmarks wie MMLU und HumanEval übertrifft das Basismodell Qwen3-32B, obwohl es ein Zehntel der aktiven Parameter verwendet. Insbesondere erreicht es 78,5 % auf MMLU für allgemeines Wissen und übertrifft Konkurrenten in den Reasoning-Untergruppen um 2-3 Punkte.
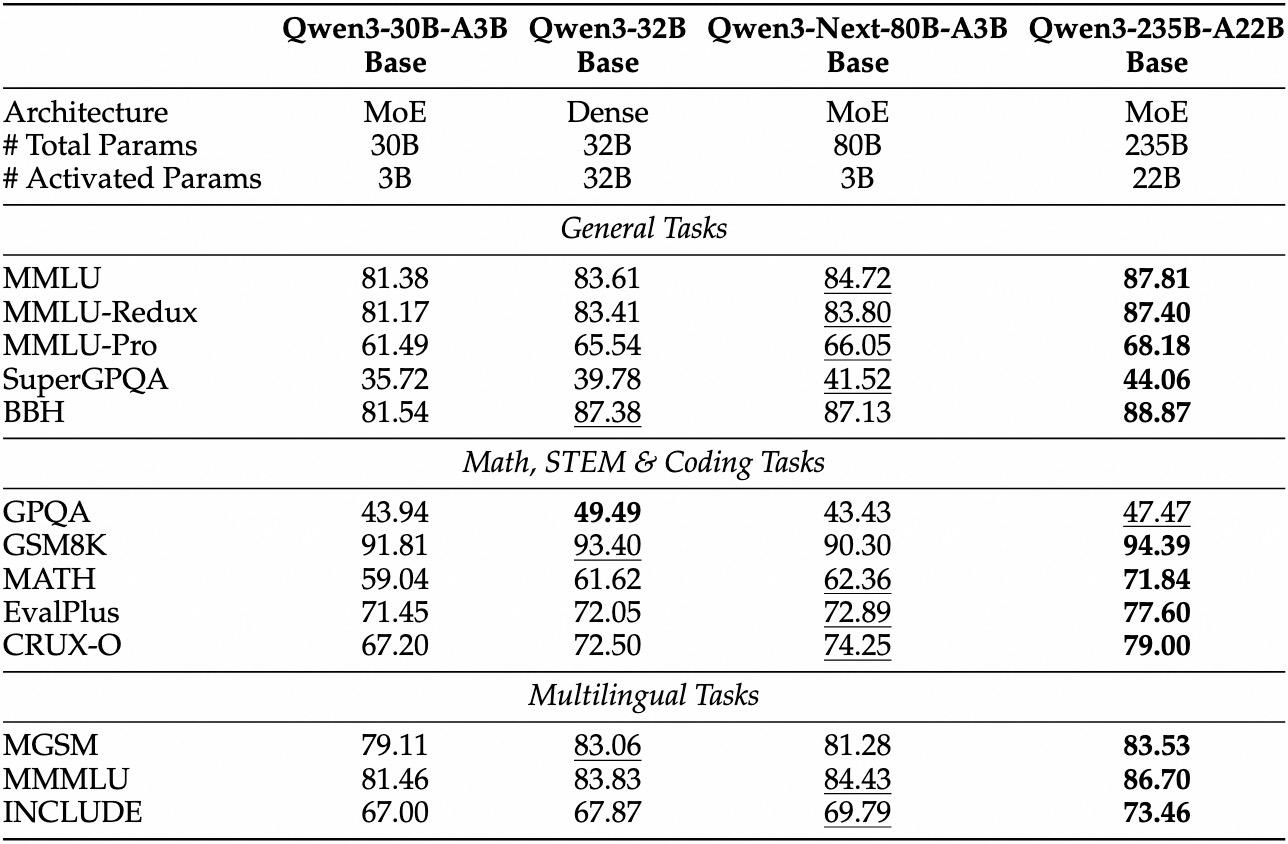
Für die Instruct-Variante zeigen Konversationsaufgaben Stärken in der Befolgung von Anweisungen. Sie erzielt 85 % auf MT-Bench und demonstriert kohärente mehrstufige Dialoge. Währenddessen glänzt das Thinking-Modell in Chain-of-Thought-Szenarien und erreicht 92 % auf GSM8K für mathematische Probleme – und übertrifft Qwen3-30B-A3B-Thinking um 4 %.
Die Inferenzgeschwindigkeit bildet einen Eckpfeiler seiner Attraktivität. Bei 4K Kontext erreicht der Dekodierungsdurchsatz das 4-fache von Qwen3-32B und skaliert bei längeren Längen auf das 10-fache. Vorfüllphasen, die für die Prompt-Verarbeitung entscheidend sind, zeigen dank des spärlichen MoE eine 7-fache Verbesserung. Der Stromverbrauch sinkt entsprechend, wobei die Trainingskosten 10 % der dichteren Modelle betragen.
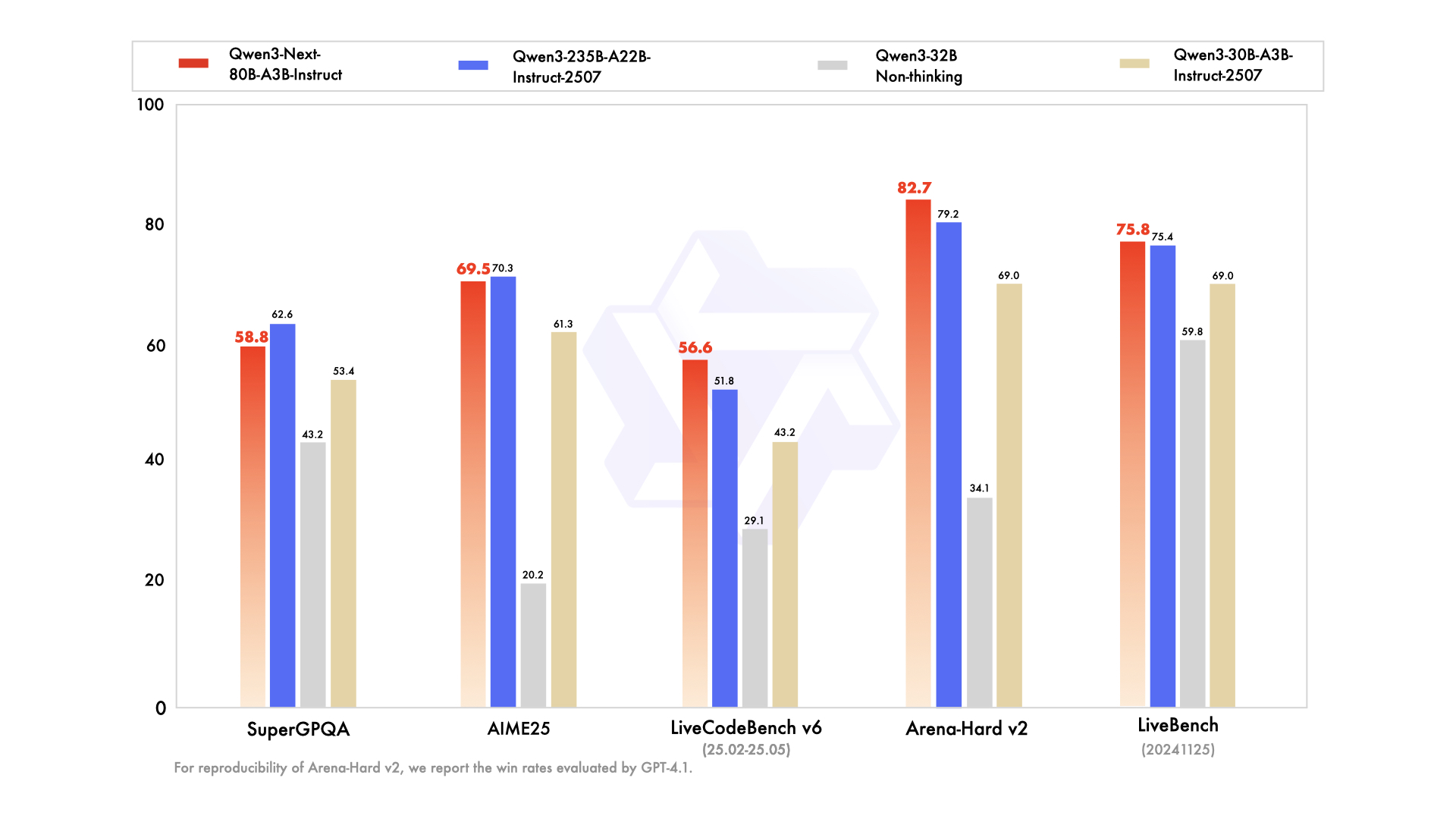
Vergleiche mit Rivalen heben seinen Vorteil hervor. Gegenüber Llama 3.1-70B führt Qwen3-Next-80B-A3B-Thinking in RULER (Long-Context-Recall) um 15 % und ruft Details aus 128K Tokens genau ab. Gegenüber DeepSeek-V2 bietet es bessere mehrsprachige Unterstützung, ohne an Geschwindigkeit einzubüßen.

| Benchmark | Qwen3-Next-80B-A3B-Basis | Qwen3-32B-Basis | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruieren) | 81.9% | 83.5% |
Diese Tabelle unterstreicht die konstante Überlegenheit. Infolgedessen setzen Organisationen es in der Produktion ein, um Qualität und Kosten in Einklang zu bringen. Vom theoretischen Wissen zur praktischen Anwendung: Sie rüsten sich nun mit API-Zugriffstools aus.
Einrichtung des Zugriffs auf die Qwen3-Next-80B-A3B API: Voraussetzungen und Authentifizierung
Alibaba stellt die Qwen API über DashScope, ihre Cloud-Plattform, bereit und gewährleistet so eine nahtlose Integration. Erstellen Sie zunächst ein Alibaba Cloud-Konto und navigieren Sie zur Model Studio-Konsole. Wählen Sie Qwen3-Next-80B-A3B aus der Modellliste aus – verfügbar in den Modi Basis, Instruieren und Denken.
Holen Sie Ihren API-Schlüssel aus dem Dashboard unter "API Keys". Dieser Schlüssel authentifiziert Anfragen, wobei die Ratenbegrenzungen auf Ihrem Tarif basieren (der kostenlose Tarif bietet 1 Mio. Tokens/Monat). Für OpenAI-kompatible Aufrufe setzen Sie die Basis-URL auf https://dashscope.aliyuncs.com/compatible-mode/v1. Native DashScope-Endpunkte verwenden https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Installieren Sie das Python SDK über pip: pip install dashscope. Diese Bibliothek übernimmt die Serialisierung, Wiederholungsversuche und Fehleranalyse. Alternativ können Sie HTTP-Clients wie `requests` für benutzerdefinierte Implementierungen verwenden.
Sicherheitsbestimmungen schreiben vor, Schlüssel in Umgebungsvariablen zu speichern: export DASHSCOPE_API_KEY='your_key_here'. Folglich bleibt Ihr Code über verschiedene Umgebungen hinweg portabel. Nach Abschluss der Einrichtung fahren Sie mit der Erstellung Ihres ersten API-Aufrufs fort.
Praktische Anleitung: Verwendung der Qwen3-Next-80B-A3B API mit Python und DashScope
DashScope vereinfacht die Interaktionen mit Qwen3-Next-80B-A3B. Beginnen Sie mit einer grundlegenden Generierungsanfrage unter Verwendung der Instruct-Variante für chatähnliche Antworten.
Hier ist ein Starter-Skript:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
Dieser Code sendet einen Prompt und ruft bis zu 200 Tokens ab. Das Modell antwortet mit einer prägnanten Erklärung, die Effizienzgewinne hervorhebt. Für den Denkmodus wechseln Sie zu 'qwen3-next-80b-a3b-thinking' und fügen Argumentationsanweisungen hinzu: "Schritt für Schritt denken, bevor Sie antworten."
Erweiterte Parameter erhöhen die Kontrolle. Setzen Sie top_p=0.9 für Nucleus-Sampling oder repetition_penalty=1.1, um Schleifen zu vermeiden. Für lange Kontexte geben Sie max_context_length=131072 an, um die 128K-Fähigkeit des Modells zu nutzen.
Streaming für Echtzeit-Apps handhaben:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
Dies liefert Token-für-Token-Ausgabe, ideal für UI-Integrationen. Die Fehlerbehandlung umfasst die Überprüfung von response.code auf Quotenprobleme (z.B. 10402 für unzureichendes Guthaben).
Darüber hinaus erweitert das Function Calling den Nutzen. Definieren Sie Tools im JSON-Schema:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
Das Modell analysiert die Absicht und gibt einen Tool-Aufruf zurück, den Sie extern ausführen. Dieses Muster treibt Agenten-Workflows an. Mit diesen Beispielen bauen Sie robuste Pipelines. Als Nächstes integrieren Sie Apidog, um diese Aufrufe zu testen und zu verfeinern, ohne jedes Mal Code schreiben zu müssen.
Verbessern Sie Ihren Workflow: Integrieren Sie Apidog für das Qwen3-Next-80B-A3B API-Testing
Apidog verwandelt die API-Entwicklung in einen optimierten Prozess, insbesondere für KI-Endpunkte wie Qwen3-Next-80B-A3B. Diese Plattform kombiniert Design, Mocking, Testing und Dokumentation in einer Oberfläche, angetrieben von KI für intelligente Automatisierung.
Beginnen Sie mit dem Import des DashScope-Schemas in Apidog. Erstellen Sie ein neues Projekt, fügen Sie den Endpunkt POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation hinzu und fügen Sie Ihren API-Schlüssel als Header ein: X-DashScope-API-Key: your_key.
Gestalten Sie Anfragen visuell: Setzen Sie den Modellparameter auf 'qwen3-next-80b-a3b-instruct', geben Sie einen Prompt im Body als JSON ein: {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}}. Apidogs KI schlägt Testfälle vor und generiert Variationen wie Edge-Case-Prompts oder Samples mit hoher Temperatur.
Führen Sie Sammlungen von Tests sequenziell aus. Zum Beispiel, um die Latenz über verschiedene Temperaturen hinweg zu benchmarken:
- Test 1: Temperatur 0.1, Prompt-Länge 100 Tokens.
- Test 2: Temperatur 1.0, Kontext 10K Tokens.
Das Tool verfolgt Metriken – Antwortzeit, Token-Nutzung, Fehlerraten – und visualisiert Trends in Dashboards. Mock-Antworten für die Offline-Entwicklung: Apidog simuliert Qwen-Ausgaben basierend auf historischen Daten und beschleunigt so Frontend-Builds.
Die Dokumentation wird automatisch aus Ihren Sammlungen generiert. Exportieren Sie OpenAPI-Spezifikationen mit Beispielen, einschließlich Qwen3-Next-80B-A3B-spezifischer Details wie MoE-Routing-Notizen. Kollaborationsfunktionen ermöglichen es Teams, Umgebungen zu teilen und so konsistentes Testen zu gewährleisten.
In einem Szenario testet ein Entwickler mehrsprachige Prompts. Apidogs KI erkennt Inkonsistenzen und schlägt Korrekturen vor, wie das Hinzufügen von Sprachhinweisen. Infolgedessen sinkt die Integrationszeit laut Benutzerberichten um 40 %. Für KI-spezifisches Testen nutzen Sie die intelligente Datengenerierung: Geben Sie ein Schema ein, und es erstellt realistische Prompts, die den Produktionsverkehr nachahmen.
Darüber hinaus unterstützt Apidog CI/CD-Hooks, die API-Tests in Pipelines ausführen. Verbinden Sie sich mit GitHub Actions für die automatisierte Validierung nach der Bereitstellung. Dieser geschlossene Ansatz minimiert Fehler in Qwen-gestützten Apps.
Fortgeschrittene Strategien: Optimierung von Qwen3-Next-80B-A3B API-Aufrufen für die Produktion
Optimierung hebt die grundlegende Nutzung auf ein unternehmensweites Zuverlässigkeitsniveau. Zunächst batchweise Anfragen, wo möglich – DashScope unterstützt bis zu 10 Prompts pro Aufruf, was den Overhead für parallele Aufgaben wie Zusammenfassungsfarmen reduziert.
Überwachen Sie die Token-Ökonomie: Das Modell berechnet pro aktivem Parameter, daher führen prägnante Prompts zu Einsparungen. Verwenden Sie result_format='message' der API für strukturierte Ausgaben, um JSON direkt zu parsen und Nachbearbeitung zu vermeiden.
Für hohe Verfügbarkeit implementieren Sie Wiederholungsversuche mit exponentiellem Backoff:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
Dies behandelt vorübergehende Fehler wie 429-Ratenbegrenzungen. Skalieren Sie horizontal, indem Sie Anrufe über Regionen verteilen – DashScope bietet Endpunkte in Singapur und den USA.
Sicherheitsaspekte umfassen die Bereinigung von Eingaben, um Prompt-Injection zu verhindern. Validieren Sie Benutzereingaben anhand von Whitelists, bevor Sie sie an die API weiterleiten. Protokollieren Sie außerdem Antworten anonymisiert zur Prüfung, um die DSGVO einzuhalten.
In Randfällen, wie bei ultra-langen Kontexten, zerlegen Sie Eingaben und verketten Vorhersagen. Die Thinking-Variante hilft hier: Fordern Sie mit "Schritt 1: Abschnitt A analysieren; Schritt 2: Mit B synthetisieren." Dies erhält die Kohärenz über 100K+ Tokens.
Entwickler erforschen auch das Fine-Tuning über Alibabas Plattform, obwohl API-Benutzer sich an Prompt-Engineering halten. Folglich gewährleisten diese Taktiken skalierbare, sichere Bereitstellungen.
Zusammenfassung: Warum Qwen3-Next-80B-A3B Ihre Aufmerksamkeit verdient
Qwen3-Next-80B-A3B definiert effiziente KI mit seinem spärlichen MoE, hybriden Gates und überragenden Benchmarks neu. Entwickler nutzen seine API über DashScope für schnelles Prototyping, ergänzt durch Tools wie Apidog für Testgenauigkeit.
Sie halten nun den Bauplan in der Hand: von architektonischen Nuancen bis hin zu Produktionsoptimierungen. Implementieren Sie diese Erkenntnisse, um schnellere, intelligentere Systeme zu bauen. Experimentieren Sie noch heute – die Zukunft skalierbarer Intelligenz wartet.