
Alibabas Qwen-Team hat Qwen3-Coder-Flash veröffentlicht, ihre neueste Codierungsmodellvariante, die „blitzschnelle, präzise Codegenerierung“ mit einigen beeindruckenden technischen Spezifikationen verspricht. Die eigentliche Frage, die sich Entwickler jedoch stellen, ist, ob dieses neue Modell wirklich Codierungsherausforderungen auf Unternehmensebene bewältigen kann oder ob es nur eine weitere inkrementelle Verbesserung ist.
Was Qwen3-Coder-Flash anders macht
Um Qwen3-Coder-Flash zu verstehen, muss man seine Architektur und Positionierung innerhalb des wachsenden Modell-Ökosystems von Alibaba untersuchen. Dieses Modell verfügt über insgesamt 30,5 Milliarden Parameter, von denen jederzeit 3,3 Milliarden aktiv sind, und nutzt eine Mixture-of-Experts-Architektur, die es ermöglicht, effizient auf 64-GB-Mac-Systemen oder sogar auf 32-GB-Systemen zu laufen, wenn es quantisiert ist.
Die Namenskonvention offenbart eine strategische Positionierung. Während die breitere Qwen3-Coder-Familie massive Varianten wie das 480-Milliarden-Parameter-Modell umfasst, richtet sich Qwen3-Coder-Flash speziell an Entwickler, die eine schnelle, effiziente Codegenerierung benötigen, ohne enorme Rechenressourcen zu erfordern. Dieser Ansatz macht fortschrittliche KI-Codierung für einzelne Entwickler und kleinere Teams zugänglich.
Darüber hinaus betont die Bezeichnung „Flash“ die Geschwindigkeitsoptimierung. Das Modell ist als „nicht-denkendes Modell konzipiert, das speziell für Codierungsaufgaben trainiert wurde“, was bedeutet, dass es sich auf die schnelle Codegenerierung konzentriert und nicht auf komplexe Denkprozesse, die Entwicklungs-Workflows verlangsamen könnten.
Detaillierte Analyse der technischen Architektur
Die Mixture-of-Experts (MoE)-Architektur stellt einen bedeutenden technischen Fortschritt in der Funktionsweise von Codierungsmodellen dar. Im Gegensatz zu traditionellen dichten Modellen, die alle Parameter für jede Berechnung aktivieren, aktiviert Qwen3-Coder-Flash selektiv nur die relevantesten Expertennetzwerke für spezifische Codierungsaufgaben. Diese selektive Aktivierung reduziert den Rechenaufwand drastisch, während gleichzeitig hohe Leistungsniveaus beibehalten werden.
Zusätzlich integriert das Modell mehrere architektonische Innovationen, die es von Konkurrenten unterscheiden. Die Parameterverteilung ermöglicht es spezialisierten Expertennetzwerken, verschiedene Programmiersprachen und Codierungsparadigmen effektiver zu handhaben. Die Python-Codegenerierung könnte andere Expertenkombinationen aktivieren als JavaScript- oder C++-Entwicklungsaufgaben.
Die Trainingsmethodik betont auch praktische Codierungsszenarien. Das Modell nutzte Qwen2.5-Coder, um verrauschte Daten zu bereinigen und neu zu schreiben, wodurch die Gesamtleistung durch fortschrittliche Techniken zur Generierung synthetischer Daten erheblich verbessert wurde. Dieser Ansatz stellt sicher, dass das Modell reale Codierungsmuster versteht und nicht nur akademische Programmierbeispiele.
Kontextlängenfunktionen transformieren Entwicklungs-Workflows
Einer der bedeutendsten Vorteile von Qwen3-Coder-Flash liegt in seinen Kontextverarbeitungsfähigkeiten. Das Modell bietet native 256K Kontextunterstützung mit Erweiterungsmöglichkeiten auf bis zu 1 Million Tokens unter Verwendung der YaRN (Yet another RoPE extensioN)-Technologie. Dieses erweiterte Kontextfenster verändert grundlegend, wie Entwickler mit KI-Codierungsassistenten interagieren können.
Traditionelle Codierungsmodelle haben oft Schwierigkeiten mit großen Codebasen, da sie nicht genügend Kontext über Projektstruktur, Abhängigkeiten und Architekturmuster aufrechterhalten können. Der erweiterte Kontext von Qwen3-Coder-Flash ermöglicht es jedoch, ganze Repositories, komplexe Vererbungshierarchien und Multi-Datei-Abhängigkeiten gleichzeitig zu verstehen.
Darüber hinaus erweist sich der erweiterte Kontext als besonders wertvoll für API-Entwicklungs-Workflows. In Verbindung mit Tools wie Apidog können Entwickler umfassende API-Dokumentation, mehrere Endpunkt-Spezifikationen und komplexe Datenschemata innerhalb eines einzigen Kontextfensters bereitstellen. Diese Fähigkeit ermöglicht eine genauere Codegenerierung, die API-Integrationsanforderungen korrekt handhabt und die Konsistenz über verschiedene Endpunkte hinweg aufrechterhält.
Die praktischen Auswirkungen gehen über die einfache Code-Vervollständigung hinaus. Entwickler können nun ganze Projektspezifikationen, Architekturdiagramme und Anforderungsdokumente als Kontext bereitstellen, wodurch das Modell Code generieren kann, der mit umfassenderen Projektzielen übereinstimmt und nicht nur mit isolierter Funktionalität.
Plattformintegration und Entwickler-Ökosystem
Qwen3-Coder-Flash wurde für Plattformen wie Qwen Code, Cline, Roo Code und Kilo Code optimiert, was Alibabas strategischen Fokus auf die Ökosystementwicklung und nicht auf die Bereitstellung von Standalone-Modellen zeigt. Dieser plattformzentrierte Ansatz erkennt an, dass moderne Entwicklungs-Workflows integrierte Toolchains und keine isolierten KI-Fähigkeiten erfordern.
Die Integrationsstrategie erstreckt sich auf Funktionsaufrufe und Agenten-Workflows. Das Modell verfügt über ein speziell entwickeltes Funktionsaufruf-Format, das agentenbasierte Codierung über mehrere Plattformen hinweg unterstützt. Diese Standardisierung ermöglicht es Entwicklern, komplexere Automatisierungs-Workflows zu erstellen, die mit mehreren Entwicklungstools und -diensten interagieren können.
Darüber hinaus reduziert die Kompatibilität des Modells mit gängigen Entwicklungsumgebungen die Akzeptanzhürden. Entwickler können Qwen3-Coder-Flash in bestehende Workflows integrieren, ohne wesentliche Infrastrukturänderungen vornehmen oder neue Schnittstellenparadigmen erlernen zu müssen. Dieser nahtlose Integrationsansatz steht im Gegensatz zu Modellen, die spezielle Umgebungen oder umfangreiche Konfigurationsprozesse erfordern.
Die Agenten-Workflow-Fähigkeiten ermöglichen auch eine anspruchsvollere Entwicklungsautomatisierung. Teams können KI-Agenten erstellen, die routinemäßige Codierungsaufgaben, Code-Review-Prozesse und Dokumentationsgenerierung übernehmen, während die Konsistenz mit Projektstandards und Architekturmustern gewahrt bleibt.
Leistungsbenchmarks und Praxistests
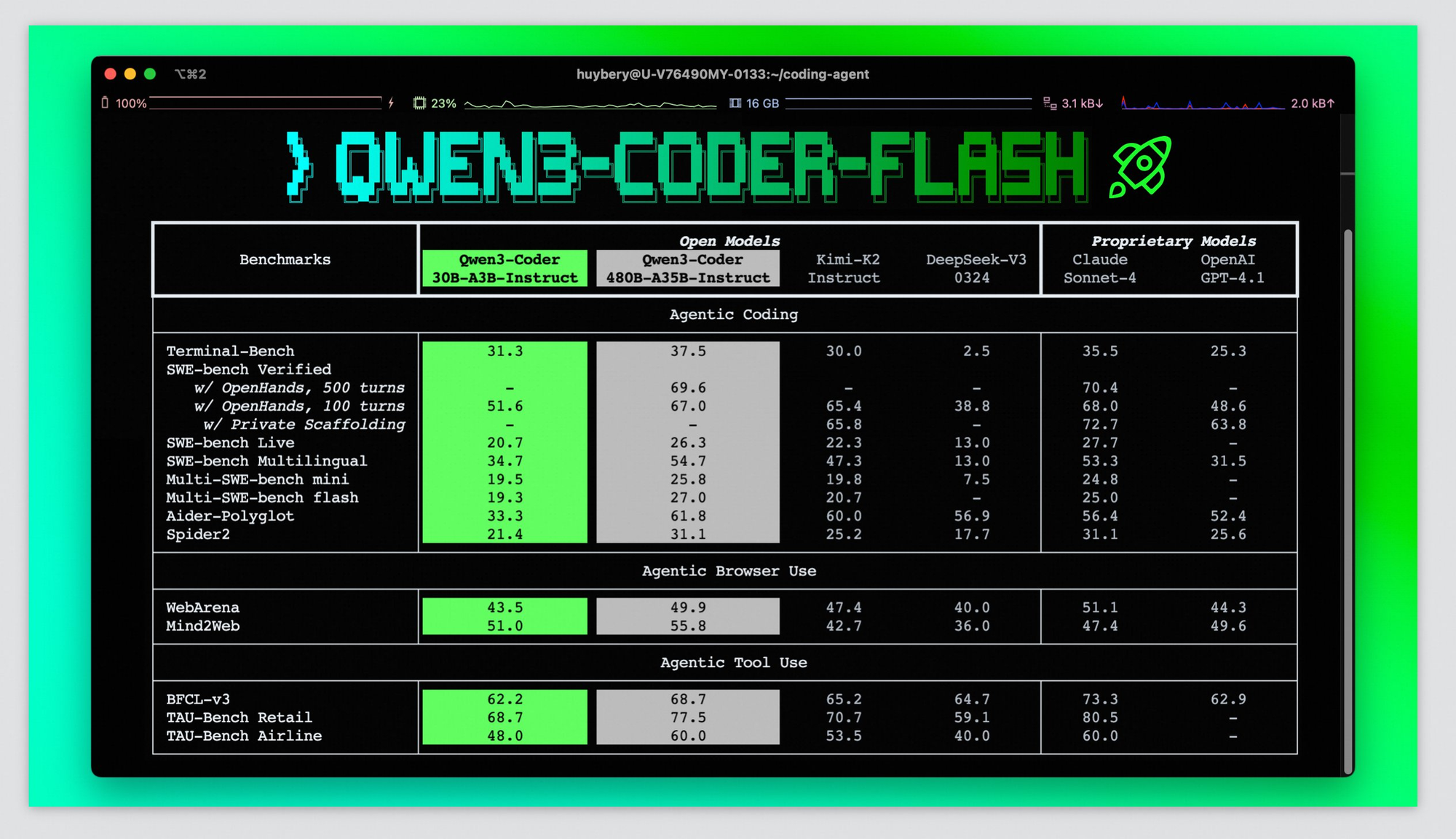
Die Bewertung der Leistung von Qwen3-Coder-Flash erfordert die Untersuchung sowohl synthetischer Benchmarks als auch realer Entwicklungsszenarien. Die breitere Qwen3-Coder-Familie erreicht eine Spitzenleistung bei der Codierung, die mit Claude Sonnet-4, GPT-4.1 und Kimi K2 mithalten kann, mit 61,8 % Leistung bei Aider Polygot-Benchmarks. Obwohl spezifische Benchmarks für die Flash-Variante noch nicht verfügbar sind, deuten ihre architektonischen Ähnlichkeiten auf vergleichbare Leistungsniveaus hin.
Die Benchmark-Leistung erzählt jedoch nur einen Teil der Geschichte. Die reale Entwicklung umfasst komplexe Szenarien, die Standard-Benchmarks nicht erfassen: Debugging von Legacy-Code, Integration mit schlecht dokumentierten APIs, Behandlung von Randfällen in Produktionssystemen und Aufrechterhaltung der Codequalität in großen Teams.
Frühes Entwickler-Feedback deutet darauf hin, dass Qwen3-Coder-Flash in Szenarien des Rapid Prototyping hervorragend ist, wo Geschwindigkeit wichtiger ist als perfekte Optimierung. Das Modell generiert schnell funktionsfähigen Code, was Entwicklern ermöglicht, in Explorationsphasen schnell zu iterieren. Die Produktionsbereitstellung erfordert jedoch oft zusätzliche Überprüfung und Optimierung, die das Modell nicht automatisch bereitstellen kann.
Die Leistung des Modells variiert auch erheblich zwischen verschiedenen Programmiersprachen und Frameworks. Während es starke Fähigkeiten bei gängigen Sprachen wie Python und JavaScript zeigt, kann die Leistung bei spezialisierten Sprachen oder aufkommenden Frameworks weniger konsistent sein.
Integration mit API-Entwicklungstools
Die Synergie zwischen Qwen3-Coder-Flash und API-Entwicklungsplattformen wie Apidog schafft leistungsstarke Entwicklungs-Workflows, die den gesamten API-Lebenszyklus optimieren. Wenn Entwickler die umfassenden API-Design- und Testfunktionen von Apidog zusammen mit den Codegenerierungsfunktionen von Qwen3-Coder-Flash nutzen, können sie API-Endpunkte mit beispielloser Effizienz schnell prototypisieren, implementieren und testen.
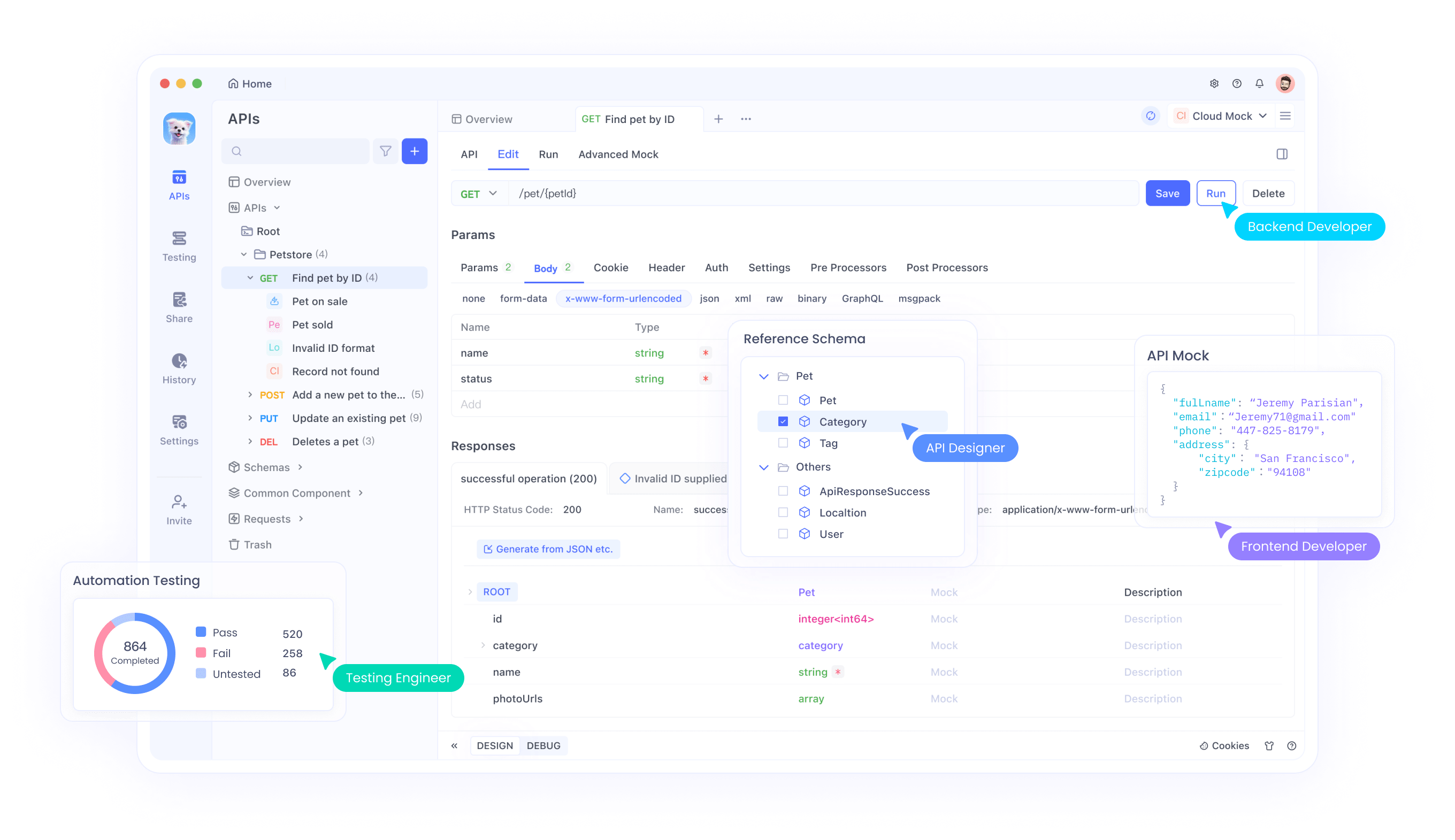
Insbesondere kann Apidogs visueller API-Designer umfassende Spezifikationen generieren, die Qwen3-Coder-Flash dann in funktionale Code-Implementierungen umwandeln kann. Das erweiterte Kontextfenster des Modells ermöglicht es, komplexe API-Schemata, Authentifizierungsanforderungen und Datenvalidierungsregeln gleichzeitig zu verstehen, wodurch Code erzeugt wird, der alle angegebenen Anforderungen korrekt handhabt.
Zusätzlich ermöglicht die Integration automatisierte Test-Workflows, bei denen Qwen3-Coder-Flash Testfälle basierend auf API-Spezifikationen generiert, während Apidog diese Tests ausführt und detailliertes Feedback zur Implementierungskorrektheit liefert. Dieser geschlossene Entwicklungszyklus reduziert die Zeit zwischen API-Design und funktionaler Implementierung erheblich.
Das kollaborative Potenzial erstreckt sich auf Team-Entwicklungsszenarien, in denen mehrere Entwickler an verschiedenen API-Komponenten arbeiten. Qwen3-Coder-Flash kann die Konsistenz über verschiedene Endpunkt-Implementierungen hinweg aufrechterhalten, indem es die breitere API-Architektur durch Apidogs zentralisiertes Spezifikationsmanagement versteht.
Einschränkungen und Überlegungen
Trotz seiner beeindruckenden Fähigkeiten weist Qwen3-Coder-Flash mehrere Einschränkungen auf, die Entwickler berücksichtigen müssen. Der Fokus des Modells auf Geschwindigkeit geht manchmal zu Lasten der Code-Optimierung und bewährter Praktiken. Generierter Code mag funktional korrekt sein, ihm fehlen jedoch möglicherweise die Effizienzoptimierungen, die erfahrene Entwickler implementieren würden.
Sicherheitsaspekte erfordern ebenfalls sorgfältige Aufmerksamkeit. Obwohl das Modell syntaktisch korrekten Code generiert, implementiert es möglicherweise nicht immer geeignete Sicherheitsmaßnahmen wie Eingabevalidierung, SQL-Injection-Prävention oder korrekte Authentifizierungsbehandlung. Entwickler müssen weiterhin Sicherheitsüberprüfungen durchführen und entsprechende Schutzmaßnahmen implementieren.
Darüber hinaus bedeuten die Einschränkungen der Trainingsdaten des Modells, dass es Schwierigkeiten mit modernsten Frameworks, neu veröffentlichten Sprachfunktionen oder hochspezialisiertem Domänenwissen haben könnte. Entwickler, die mit aufkommenden Technologien arbeiten, sollten erwarten, zusätzlichen Kontext und Anleitung bereitzustellen, um optimale Ergebnisse zu erzielen.
Auch die Kosten- und Infrastrukturanforderungen stellen praktische Herausforderungen dar. Obwohl Qwen3-Coder-Flash effizienter ist als größere Modelle, benötigt es immer noch erhebliche Rechenressourcen für optimale Leistung. Organisationen müssen den Produktivitätsnutzen gegen Infrastrukturkosten und Komplexität abwägen.
Implementierungsstrategien für Entwicklungsteams
Die erfolgreiche Implementierung von Qwen3-Coder-Flash erfordert eine strategische Planung, die sowohl technische Anforderungen als auch Teamdynamiken berücksichtigt. Organisationen sollten mit Pilotprojekten beginnen, die die Stärken des Modells nutzen und gleichzeitig die Exposition gegenüber seinen Einschränkungen minimieren.
Die anfängliche Implementierung sollte sich auf Anwendungsfälle konzentrieren, bei denen die schnelle Codegenerierung einen klaren Mehrwert bietet: Erstellung von API-Endpunkten, Generierung von Testfällen, Dokumentationsautomatisierung und Prototypenentwicklung. Diese Szenarien ermöglichen es Teams, Erfahrungen mit dem Modell zu sammeln und gleichzeitig greifbare Produktivitätsverbesserungen zu erzielen.
Schulung und Änderungsmanagement erfordern ebenfalls sorgfältige Aufmerksamkeit. Entwicklungsteams benötigen Anleitung für effektives Prompt Engineering, das Verständnis von Modellbeschränkungen und die Integration von KI-generiertem Code in bestehende Qualitätssicherungsprozesse. Ohne entsprechende Schulung könnten Teams die Fähigkeiten des Modells entweder unzureichend nutzen oder sich übermäßig auf dessen Ausgabe verlassen, ohne eine angemessene Validierung.
Die Integration mit bestehenden Entwicklungstools sollte schrittweise und wohlüberlegt erfolgen. Anstatt etablierte Workflows vollständig zu ersetzen, sollten Organisationen spezifische Schwachstellen identifizieren, bei denen Qwen3-Coder-Flash sofortige Verbesserungen bieten kann, während die allgemeine Workflow-Stabilität erhalten bleibt.
Fazit
Qwen3-Coder-Flash stellt einen bedeutenden Fortschritt in der zugänglichen KI-Codierungsassistenz dar und bietet Funktionen auf Unternehmensebene in einem effizienteren und kostengünstigeren Paket. Seine erweiterten Kontextfähigkeiten, die MoE-Architektur und die Plattformintegrationen schaffen leistungsstarke Möglichkeiten für Entwicklungsteams, die ihre Codierungs-Workflows beschleunigen möchten.
Der Erfolg mit Qwen3-Coder-Flash erfordert jedoch realistische Erwartungen und eine strategische Implementierung. Das Modell zeichnet sich durch schnelle Codegenerierung und Prototyping aus, kann aber menschliche Expertise in Architekturdesign, Sicherheitsimplementierung und Code-Optimierung nicht ersetzen. Organisationen, die diese Grenzen verstehen und entsprechende Prozesse implementieren, werden erhebliche Produktivitätssteigerungen erzielen.