
Heute ist ein weiterer großartiger Tag für die Open-Source-KI-Community, die besonders in solchen Momenten aufblüht, indem sie das neue State-of-the-Art eifrig dekonstruiert, testet und darauf aufbaut. Im Juli 2025 löste Alibabas Qwen-Team ein solches Ereignis mit der Einführung seiner Qwen3-Serie aus, einer leistungsstarken neuen Modellfamilie, die darauf abzielt, Leistungsbenchmarks neu zu definieren. Im Mittelpunkt dieser Veröffentlichung steht eine faszinierende und hochspezialisierte Variante: Qwen3-235B-A22B-Thinking-2507.
Dieses Modell ist nicht nur ein weiteres inkrementelles Update; es stellt einen bewussten und strategischen Schritt zur Schaffung von KI-Systemen mit tiefgreifenden Denkfähigkeiten dar. Schon sein Name ist eine Absichtserklärung, die einen Fokus auf Logik, Planung und mehrstufige Problemlösung signalisiert. Dieser Artikel bietet einen tiefen Einblick in die Architektur, den Zweck und die potenzielle Auswirkung von Qwen3-Thinking, untersucht seinen Platz innerhalb des breiteren Qwen3-Ökosystems und was er für die Zukunft der KI-Entwicklung bedeutet.
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!
Die Qwen3-Familie: Ein vielschichtiger Angriff auf den Stand der Technik
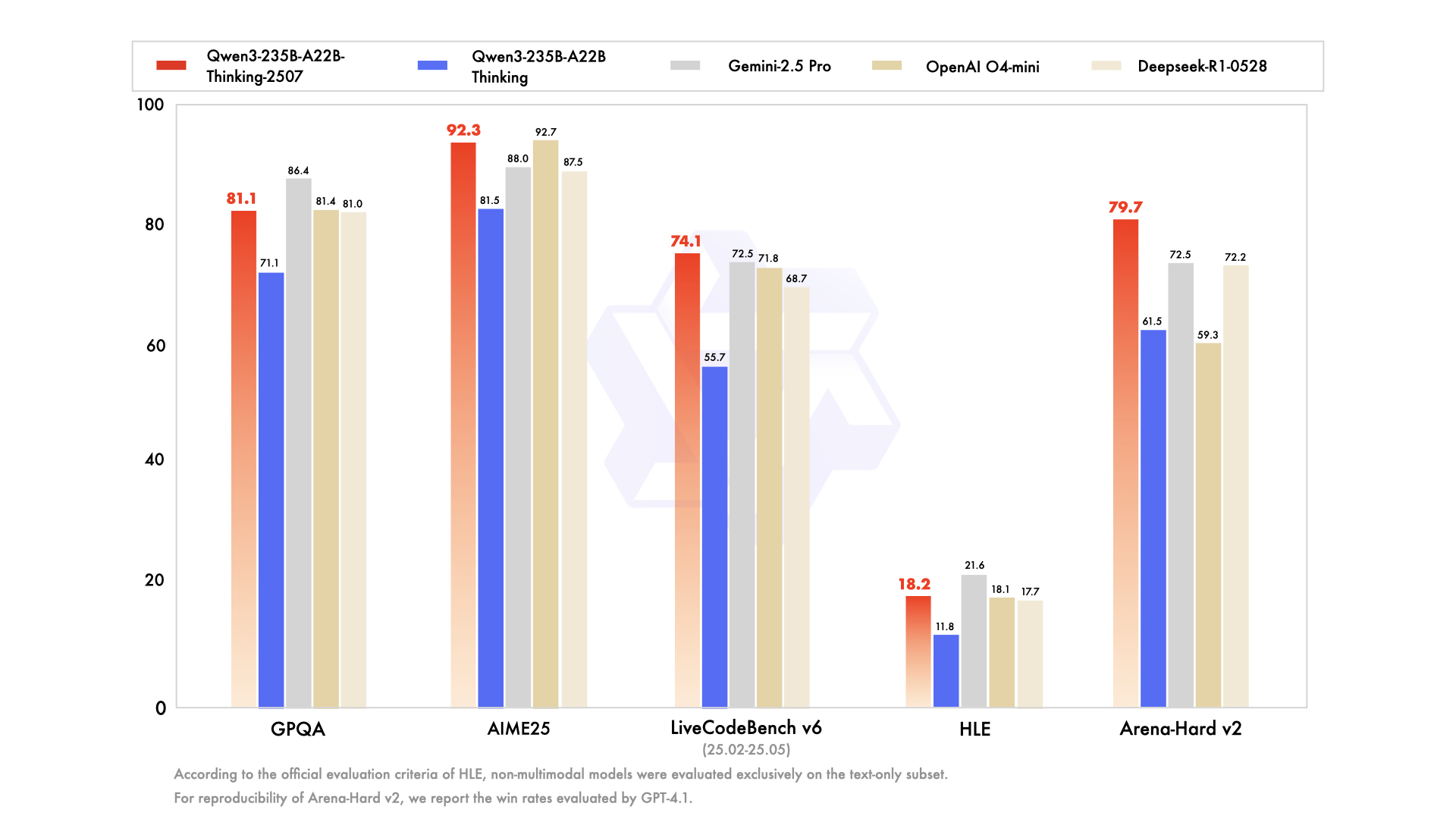
Um das Thinking-Modell zu verstehen, muss man zunächst den Kontext seiner Entstehung würdigen. Es entstand nicht isoliert, sondern als Teil einer umfassenden und strategisch vielfältigen Qwen3-Modellfamilie. Die Qwen-Serie hat bereits eine massive Anhängerschaft gewonnen, mit einer Geschichte von Downloads in Hunderten von Millionen und der Förderung einer lebendigen Community, die über 100.000 abgeleitete Modelle auf Plattformen wie Hugging Face erstellt hat.
Die Qwen3-Serie umfasst mehrere Schlüsselvarianten, die jeweils für verschiedene Bereiche maßgeschneidert sind:
- Qwen3-Instruct: Ein Allzweckmodell zur Befolgung von Anweisungen, das für eine Vielzahl von Konversations- und aufgabenorientierten Anwendungen entwickelt wurde. Die Variante
Qwen3-235B-A22B-Instruct-2507ist beispielsweise für ihre verbesserte Ausrichtung an Benutzerpräferenzen bei offenen Aufgaben und ihre breite Wissensabdeckung bekannt. - Qwen3-Coder: Eine Reihe von Modellen, die explizit für agentische Codierung entwickelt wurden. Das leistungsstärkste davon, ein massives Modell mit 480 Milliarden Parametern, setzt einen neuen Standard für die Open-Source-Codegenerierung und Softwareentwicklungsautomatisierung. Es wird sogar mit einem Befehlszeilentool, Qwen Code, geliefert, um seine agentischen Fähigkeiten besser zu nutzen.
- Qwen3-Thinking: Der Schwerpunkt unserer Analyse, spezialisiert auf komplexe kognitive Aufgaben, die über einfache Anweisungsbefolgung oder Codegenerierung hinausgehen.
Dieser Familienansatz demonstriert eine ausgeklügelte Strategie: Anstatt eines einzelnen, monolithischen Modells, das versucht, ein Alleskönner zu sein, bietet Alibaba eine Suite spezialisierter Werkzeuge an, die es Entwicklern ermöglichen, die richtige Grundlage für ihre spezifischen Bedürfnisse zu wählen.
Sprechen wir über den "Thinking"-Teil von Qwen3-235B-A22B-Thinking-2507
Der Name des Modells, Qwen3-235B-A22B-Thinking-2507, ist voll von Informationen, die seine zugrunde liegende Architektur und Designphilosophie offenbaren. Lassen Sie uns ihn Stück für Stück aufschlüsseln.
Qwen3: Dies bedeutet, dass das Modell zur dritten Generation der Qwen-Serie gehört und auf dem Wissen und den Fortschrritt der Vorgänger aufbaut.235B-A22B(Mixture of Experts - MoE): Dies ist das wichtigste architektonische Detail. Das Modell ist kein dichtes Netzwerk mit 235 Milliarden Parametern, bei dem jeder Parameter für jede einzelne Berechnung verwendet wird. Stattdessen verwendet es eine Mixture-of-Experts (MoE)-Architektur.Thinking: Dieses Suffix bezeichnet die Spezialisierung des Modells, das auf Daten feinabgestimmt wurde, die logische Deduktion und schrittweise Analyse belohnen.2507: Dies ist ein Versions-Tag, der wahrscheinlich für Juli 2025 steht und das Veröffentlichungs- oder Trainingsabschlussdatum des Modells angibt.
Die MoE-Architektur ist der Schlüssel zur Kombination von Leistung und Effizienz dieses Modells. Man kann sie sich als ein großes Team spezialisierter "Experten" – kleinerer neuronaler Netze – vorstellen, die von einem "Gating-Netzwerk" oder "Router" verwaltet werden. Für jedes gegebene Eingabetoken wählt der Router dynamisch eine kleine Untergruppe der relevantesten Experten aus, um die Informationen zu verarbeiten.
Im Falle von Qwen3-235B-A22B sind die Besonderheiten:
- Gesamtparameter (
235B): Dies stellt das riesige Wissensrepository dar, das über alle verfügbaren Experten verteilt ist. Das Modell enthält insgesamt 128 verschiedene Experten. - Aktive Parameter (
A22B): Für jeden einzelnen Inferenzdurchlauf wählt das Gating-Netzwerk 8 Experten zur Aktivierung aus. Die kombinierte Größe dieser aktiven Experten beträgt ungefähr 22 Milliarden Parameter.
Die Vorteile dieses Ansatzes sind immens. Er ermöglicht es dem Modell, das riesige Wissen, die Nuancen und Fähigkeiten eines Modells mit 235 Milliarden Parametern zu besitzen, während die Rechenkosten und die Inferenzgeschwindigkeit näher an einem viel kleineren dichten Modell mit 22 Milliarden Parametern liegen. Dies macht den Einsatz und Betrieb eines so großen Modells praktikabler, ohne seine Wissens tiefe zu opfern.
Technische Spezifikationen und Leistungsprofil
Über die übergeordnete Architektur hinaus zeichnen die detaillierten Spezifikationen des Modells ein klareres Bild seiner Fähigkeiten.
- Modellarchitektur: Mixture-of-Experts (MoE)
- Gesamtparameter: ~235 Milliarden
- Aktive Parameter: ~22 Milliarden pro Token
- Anzahl der Experten: 128
- Pro Token aktivierte Experten: 8
- Kontextlänge: Das Modell unterstützt ein Kontextfenster von 128.000 Tokens. Dies ist eine massive Verbesserung, die es ermöglicht, extrem lange Dokumente, ganze Codebasen oder umfangreiche Konversationsverläufe zu verarbeiten und darüber nachzudenken, ohne wichtige Informationen vom Anfang der Eingabe zu verlieren.
- Tokenizer: Es verwendet einen benutzerdefinierten Byte Pair Encoding (BPE)-Tokenizer mit einem Vokabular von über 150.000 Tokens. Diese große Vokabulargröße ist ein Indikator für sein starkes mehrsprachiges Training, das es ihm ermöglicht, Text aus einer Vielzahl von Sprachen, einschließlich Englisch, Chinesisch, Deutsch, Spanisch und vielen anderen, sowie Programmiersprachen effizient zu kodieren.
- Trainingsdaten: Während die genaue Zusammensetzung des Trainingskorpus proprietär ist, wird ein
Thinking-Modell sicherlich auf einer spezialisierten Datenmischung trainiert, die darauf ausgelegt ist, logisches Denken zu fördern. Dieser Datensatz würde weit über Standard-Webtext hinausgehen und wahrscheinlich Folgendes umfassen: - Akademische und wissenschaftliche Arbeiten: Große Textmengen aus Quellen wie arXiv, PubMed und anderen Forschungsrepositorien, um komplexes wissenschaftliches und mathematisches Denken zu absorbieren.
- Logische und mathematische Datensätze: Datensätze wie GSM8K (Grundschulmathematik) und der MATH-Datensatz, die Textaufgaben enthalten, die schrittweise Lösungen erfordern.
- Programmier- und Codeprobleme: Datensätze wie HumanEval und MBPP, die logisches Denken durch Codegenerierung testen.
- Philosophische und juristische Texte: Dokumente, die das Verständnis dichter, abstrakter und hochstrukturierter logischer Argumente erfordern.
- Chain-of-Thought (CoT)-Daten: Synthetisch generierte oder von Menschen kuratierte Beispiele, bei denen dem Modell explizit gezeigt wird, wie es "Schritt für Schritt denken" muss, um zu einer Antwort zu gelangen.
Diese kuratierte Datenmischung ist es, die das Thinking-Modell von seinem Instruct-Geschwistermodell unterscheidet. Es ist nicht nur darauf trainiert, hilfreich zu sein; es ist darauf trainiert, rigoros zu sein.
Die Kraft des "Denkens": Ein Fokus auf komplexe Kognition
Das Versprechen des Qwen3-Thinking-Modells liegt in seiner Fähigkeit, Probleme anzugehen, die historisch gesehen große Herausforderungen für große Sprachmodelle darstellten. Dies sind Aufgaben, bei denen einfaches Mustervergleich oder Informationsabruf nicht ausreichen. Die Spezialisierung "Thinking" deutet auf Kompetenzen in Bereichen wie:
- Mehrstufiges Denken: Lösen von Problemen, die das Zerlegen einer Anfrage in eine Abfolge logischer Schritte erfordern. Zum Beispiel die Berechnung der finanziellen Auswirkungen einer Geschäftsentscheidung auf der Grundlage mehrerer Marktvariablen oder die Planung der Flugbahn eines Projektils unter Berücksichtigung einer Reihe physikalischer Einschränkungen.
- Logische Deduktion: Analyse einer Reihe von Prämissen und Ziehen einer gültigen Schlussfolgerung. Dies könnte das Lösen eines Logikgitterrätsels, das Identifizieren logischer Fehlschlüsse in einem Text oder das Bestimmen der Konsequenzen einer Reihe von Regeln in einem rechtlichen oder vertraglichen Kontext umfassen.
- Strategische Planung: Entwicklung einer Abfolge von Aktionen zur Erreichung eines Ziels. Dies findet Anwendung in komplexen Spielen (wie Schach oder Go), Geschäftssimulationen, Lieferkettenoptimierung und automatisiertem Projektmanagement.
- Kausale Inferenz: Der Versuch, Ursache-Wirkungs-Beziehungen innerhalb eines komplexen Systems, das im Text beschrieben wird, zu identifizieren – ein Eckpfeiler des wissenschaftlichen und analytischen Denkens, mit dem Modelle oft Schwierigkeiten haben.
- Abstraktes Denken: Verstehen und Manipulieren abstrakter Konzepte und Analogien. Dies ist wesentlich für kreative Problemlösung und wahre Intelligenz auf menschlichem Niveau, die über konkrete Fakten hinaus zu den Beziehungen zwischen ihnen führt.
Das Modell ist darauf ausgelegt, bei Benchmarks zu glänzen, die diese fortgeschrittenen kognitiven Fähigkeiten spezifisch messen, wie MMLU (Massive Multitask Language Understanding) für allgemeines Wissen und Problemlösung, und die bereits erwähnten GSM8K und MATH für mathematisches Denken.
Zugänglichkeit, Quantisierung und Community-Engagement
Die Leistungsfähigkeit eines Modells ist nur dann sinnvoll, wenn es zugänglich und nutzbar ist. Getreu seinem Open-Source-Engagement hat Alibaba die Qwen3-Familie, einschließlich der Thinking-Variante, auf Plattformen wie Hugging Face und ModelScope weitreichend verfügbar gemacht.
In Anbetracht der erheblichen Rechenressourcen, die zum Betrieb eines Modells dieser Größenordnung erforderlich sind, sind auch quantisierte Versionen verfügbar. Das Modell **Qwen3-235B-A22B-Thinking-2507-FP8** ist ein Paradebeispiel. FP8 (8-Bit-Gleitkommazahl) ist eine hochmoderne Quantisierungstechnik, die den Speicherbedarf des Modells drastisch reduziert und die Inferenzgeschwindigkeit erhöht.
Lassen Sie uns die Auswirkungen aufschlüsseln:
- Ein Modell mit 235 Milliarden Parametern in Standard-16-Bit-Präzision (BF16/FP16) würde über 470 GB VRAM erfordern, eine unerschwingliche Menge für alle außer den größten Serverclustern auf Unternehmensebene.
- Die FP8-quantisierte Version reduziert diesen Bedarf jedoch auf unter 250 GB. Obwohl immer noch beträchtlich, rückt dies das Modell in den Bereich des Möglichen für Forschungseinrichtungen, Startups und sogar Einzelpersonen mit Multi-GPU-Workstations, die mit High-End-Consumer- oder Prosumer-Hardware ausgestattet sind.
Dies macht fortgeschrittenes Denken einem viel breiteren Publikum zugänglich. Für Unternehmensnutzer, die verwaltete Dienste bevorzugen, werden die Modelle auch in Alibabas Cloud-Plattformen integriert. Der API-Zugriff über Model Studio und die Integration in Alibabas Flaggschiff-KI-Assistenten Quark stellen sicher, dass die Technologie in jedem Umfang genutzt werden kann.
Fazit: Ein neues Werkzeug für eine neue Klasse von Problemen
Die Veröffentlichung von Qwen3-235B-A22B-Thinking-2507 ist mehr als nur ein weiterer Punkt auf der ständig steigenden Kurve der KI-Modellleistung. Sie ist eine Aussage über die zukünftige Richtung der KI-Entwicklung: eine Verschiebung von monolithischen, universellen Modellen hin zu einem vielfältigen Ökosystem leistungsstarker, spezialisierter Werkzeuge. Durch den Einsatz einer effizienten Mixture-of-Experts-Architektur hat Alibaba ein Modell mit dem immensen Wissen eines 235-Milliarden-Parameter-Netzwerks und der relativen Rechenfreundlichkeit eines 22-Milliarden-Parameter-Modells geliefert.
Durch die explizite Feinabstimmung dieses Modells auf "Denken" stellt das Qwen-Team der Welt ein Werkzeug zur Verfügung, das sich der Lösung der schwierigsten analytischen und Denkherausforderungen widmet. Es hat das Potenzial, die wissenschaftliche Entdeckung zu beschleunigen, indem es Forschern hilft, komplexe Daten zu analysieren, Unternehmen zu befähigen, bessere strategische Entscheidungen zu treffen, und als Basisschicht für eine neue Generation intelligenter Anwendungen zu dienen, die mit beispielloser Raffinesse planen, deduzieren und denken können. Während die Open-Source-Community beginnt, seine Tiefen vollständig zu erforschen, wird Qwen3-Thinking zu einem kritischen Baustein in der fortwährenden Suche nach fähigerer und wirklich intelligenter KI werden.
Möchten Sie eine integrierte All-in-One-Plattform, damit Ihr Entwicklerteam mit maximaler Produktivität zusammenarbeiten kann?
Apidog erfüllt all Ihre Anforderungen und ersetzt Postman zu einem viel günstigeren Preis!