
Alibabas Qwen-Team hat mit der Veröffentlichung des Modells Qwen2.5-VL-32B-Instruct, einem bahnbrechenden Vision-Language-Modell (VLM), das sowohl intelligenter als auch leichter sein soll, erneut die Grenzen der künstlichen Intelligenz verschoben.
Am 24. März 2025 angekündigt, bietet dieses Modell mit 32 Milliarden Parametern ein optimales Gleichgewicht zwischen Leistung und Effizienz und ist damit die ideale Wahl für Entwickler und Forscher. Aufbauend auf dem Erfolg der Qwen2.5-VL-Serie führt diese neue Iteration signifikante Fortschritte in mathematischem Denken, der Ausrichtung auf menschliche Präferenzen und Vision-Aufgaben ein, und das alles bei gleichzeitiger Beibehaltung einer überschaubaren Größe für den lokalen Einsatz.
Für Entwickler, die dieses leistungsstarke Modell in ihre Projekte integrieren möchten, ist die Erforschung robuster API-Tools unerlässlich. Aus diesem Grund empfehlen wir den kostenlosen Download von Apidog – einer benutzerfreundlichen API-Entwicklungsplattform, die das Testen und Integrieren von Modellen wie Qwen in Ihre Anwendungen vereinfacht. Mit Apidog können Sie nahtlos mit der Qwen-API interagieren, Workflows optimieren und das volle Potenzial dieses innovativen VLM erschließen. Laden Sie Apidog noch heute herunter und beginnen Sie mit der Entwicklung intelligenterer Anwendungen!
Mit diesem API-Tool können Sie die Endpunkte Ihres Modells mühelos testen und debuggen. Laden Sie Apidog noch heute kostenlos herunter und optimieren Sie Ihren Workflow, während Sie die Fähigkeiten von Mistral Small 3.1 erkunden!
Qwen2.5-VL-32B: Ein intelligenteres Vision-Language-Modell
Was Qwen2.5-VL-32B einzigartig macht
Qwen2.5-VL-32B zeichnet sich als Vision-Language-Modell mit 32 Milliarden Parametern aus, das entwickelt wurde, um die Einschränkungen sowohl größerer als auch kleinerer Modelle der Qwen-Familie zu beheben. Während Modelle mit 72 Milliarden Parametern wie Qwen2.5-VL-72B robuste Fähigkeiten bieten, erfordern sie oft erhebliche Rechenressourcen, was sie für den lokalen Einsatz unpraktisch macht. Umgekehrt kann es kleineren Modellen mit 7 Milliarden Parametern, obwohl sie leichter sind, an der Tiefe mangeln, die für komplexe Aufgaben erforderlich ist. Qwen2.5-VL-32B schließt diese Lücke, indem es hohe Leistung mit einem überschaubareren Footprint liefert.
Dieses Modell baut auf der Qwen2.5-VL-Serie auf, die für ihre multimodalen Fähigkeiten weitreichende Anerkennung fand. Qwen2.5-VL-32B führt jedoch wichtige Verbesserungen ein, einschließlich der Optimierung durch Reinforcement Learning (RL). Dieser Ansatz verbessert die Ausrichtung des Modells auf menschliche Präferenzen und gewährleistet detailliertere, benutzerfreundlichere Ergebnisse. Darüber hinaus demonstriert das Modell überlegenes mathematisches Denken, ein wichtiges Merkmal für Aufgaben, die komplexes Problemlösen und Datenanalyse umfassen.

Wichtige technische Verbesserungen
Qwen2.5-VL-32B nutzt Reinforcement Learning, um seinen Ausgabestil zu verfeinern und Antworten kohärenter, detaillierter und für eine bessere menschliche Interaktion formatiert zu machen. Darüber hinaus haben sich seine mathematischen Denkfähigkeiten erheblich verbessert, wie seine Leistung bei Benchmarks wie MathVista und MMMU beweist. Diese Verbesserungen resultieren aus fein abgestimmten Trainingsprozessen, die Genauigkeit und logische Ableitung priorisieren, insbesondere in multimodalen Kontexten, in denen Text- und visuelle Daten interagieren.
Das Modell zeichnet sich auch durch differenziertes Bildverständnis und -denken aus, was eine präzise Analyse visueller Inhalte wie Diagramme, Grafiken und Dokumente ermöglicht. Diese Fähigkeit positioniert Qwen2.5-VL-32B als Top-Anwärter für Anwendungen, die fortschrittliche visuelle Logikableitung und Inhaltswiedererkennung erfordern.
Qwen2.5-VL-32B Leistungs-Benchmarks: Übertrifft größere Modelle
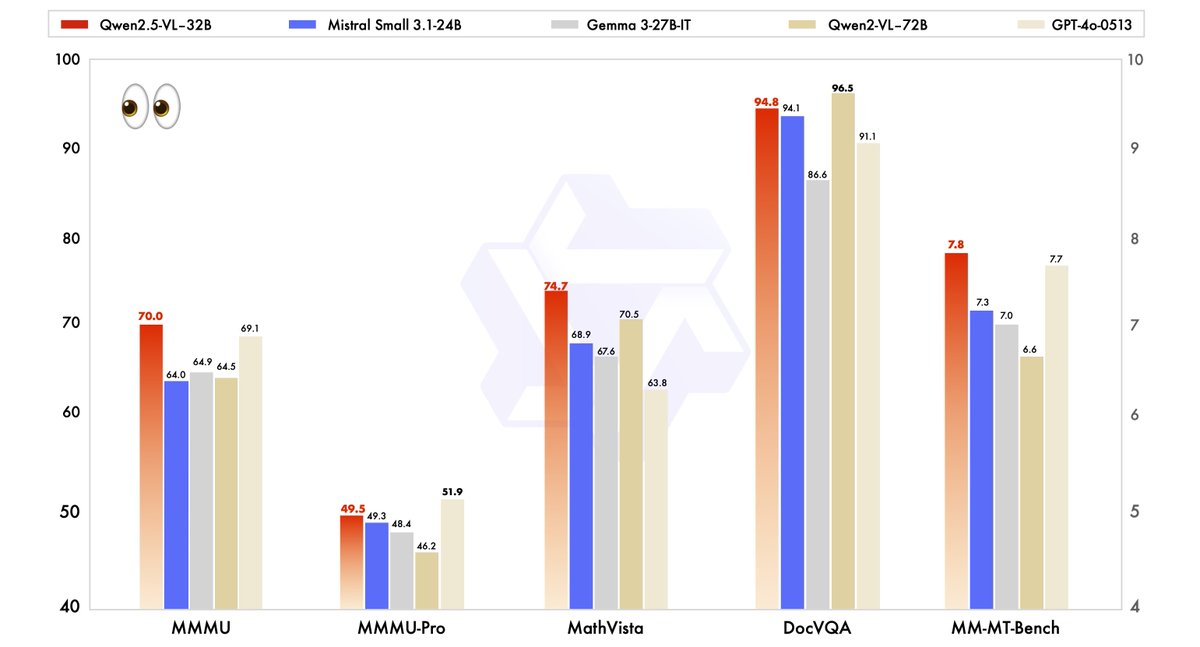
Die Leistung von Qwen2.5-VL-32B wurde rigoros mit modernsten Modellen verglichen, darunter sein größerer Bruder, Qwen2.5-VL-72B, sowie Wettbewerber wie Mistral-Small-3.1–24B und Gemma-3–27B-IT. Die Ergebnisse unterstreichen die Überlegenheit des Modells in mehreren Schlüsselbereichen.
- MMMU (Massive Multitask Language Understanding): Qwen2.5-VL-32B erreicht einen Wert von 70,0 und übertrifft damit die 64,5 von Qwen2.5-VL-72B. Dieser Benchmark testet komplexes, mehrstufiges Denken über verschiedene Aufgaben hinweg und demonstriert die verbesserten kognitiven Fähigkeiten des Modells.
- MathVista: Mit einem Wert von 74,7 übertrifft Qwen2.5-VL-32B die 70,5 von Qwen2.5-VL-72B und unterstreicht damit seine Stärke bei mathematischen und visuellen Denkaufgaben.
- MM-MT-Bench: Dieser subjektive Benchmark zur Bewertung der Benutzererfahrung zeigt, dass Qwen2.5-VL-32B seinen Vorgänger um einen erheblichen Vorsprung übertrifft, was eine verbesserte Ausrichtung auf menschliche Präferenzen widerspiegelt.
- Textbasierte Aufgaben (z. B. MMLU, MATH, HumanEval): Das Modell konkurriert effektiv mit größeren Modellen wie GPT-4o-Mini und erreicht Werte von 78,4 auf MMLU, 82,2 auf MATH und 91,5 auf HumanEval, trotz seiner geringeren Parameteranzahl.
Diese Benchmarks zeigen, dass Qwen2.5-VL-32B nicht nur die Leistung größerer Modelle erreicht, sondern diese oft übertrifft, und das alles bei geringerem Rechenaufwand. Dieses Gleichgewicht aus Leistung und Effizienz macht es zu einer attraktiven Option für Entwickler und Forscher, die mit begrenzter Hardware arbeiten.
Warum die Größe wichtig ist: Der 32B-Vorteil
Die Größe von 32 Milliarden Parametern von Qwen2.5-VL-32B trifft den Sweet Spot für den lokalen Einsatz. Im Gegensatz zu 72B-Modellen, die umfangreiche GPU-Ressourcen erfordern, lässt sich dieses leichtere Modell nahtlos in Inferenz-Engines wie SGLang und vLLM integrieren, wie in verwandten Webergebnissen festgestellt. Diese Kompatibilität gewährleistet eine schnellere Bereitstellung und einen geringeren Speicherverbrauch, wodurch es für eine breitere Palette von Benutzern zugänglich wird, von Start-ups bis hin zu großen Unternehmen.
Darüber hinaus beeinträchtigt die Optimierung des Modells für Geschwindigkeit und Effizienz seine Fähigkeiten nicht. Seine Fähigkeit, multimodale Aufgaben zu bewältigen – wie das Erkennen von Objekten, das Analysieren von Diagrammen und das Verarbeiten strukturierter Ausgaben wie Rechnungen und Tabellen – bleibt robust und positioniert es als vielseitiges Werkzeug für reale Anwendungen.

Qwen2.5-VL-32B lokal mit MLX ausführen
Um dieses leistungsstarke Modell lokal auf Ihrem Mac mit Apple Silicon auszuführen, gehen Sie wie folgt vor:
Systemanforderungen
- Ein Mac mit Apple Silicon (M1-, M2- oder M3-Chip)
- Mindestens 32 GB RAM (64 GB empfohlen)
- 60 GB+ freier Speicherplatz
- macOS Sonoma oder neuer
Installationsschritte
- Python-Abhängigkeiten installieren
pip install mlx mlx-llm transformers pillow
- Das Modell herunterladen
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Das Modell in das MLX-Format konvertieren
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Ein einfaches Skript erstellen, um mit dem Modell zu interagieren
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Load the model
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Load an image
image = Image.open("path/to/your/image.jpg")
# Create a prompt with the image
prompt = "Was sehen Sie auf diesem Bild?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Praktische Anwendungen: Nutzung von Qwen2.5-VL-32B
Vision-Aufgaben und darüber hinaus
Die erweiterten visuellen Fähigkeiten von Qwen2.5-VL-32B eröffnen eine Vielzahl von Anwendungen. So kann es beispielsweise als visueller Agent dienen, der dynamisch mit Computer- oder Telefonschnittstellen interagiert, um Aufgaben wie Navigation oder Datenextraktion auszuführen. Seine Fähigkeit, lange Videos (bis zu einer Stunde) zu verstehen und relevante Segmente zu lokalisieren, verbessert seine Nützlichkeit in der Videoanalyse und zeitlichen Lokalisierung weiter.
Bei der Dokumentenanalyse zeichnet sich das Modell durch die Verarbeitung von Multi-Szenen-, mehrsprachigen Inhalten aus, einschließlich handschriftlichem Text, Tabellen, Diagrammen und chemischen Formeln. Dies macht es für Branchen wie Finanzen, Bildung und Gesundheitswesen von unschätzbarem Wert, in denen die genaue Extraktion strukturierter Daten von entscheidender Bedeutung ist.
Text- und mathematisches Denken
Über Vision-Aufgaben hinaus glänzt Qwen2.5-VL-32B in textbasierten Anwendungen, insbesondere in solchen, die mathematisches Denken und Codierung umfassen. Seine hohen Werte bei Benchmarks wie MATH und HumanEval weisen auf seine Fähigkeit hin, komplexe algebraische Probleme zu lösen, Funktionsgraphen zu interpretieren und genaue Code-Snippets zu generieren. Diese doppelte Kompetenz in Vision und Text positioniert Qwen2.5-VL-32B als eine ganzheitliche Lösung für multimodale KI-Herausforderungen.

Wo Sie Qwen2.5-VL-32B verwenden können
Open Source und API-Zugriff
Qwen2.5-VL-32B ist unter der Apache 2.0-Lizenz verfügbar, wodurch es Open Source ist und Entwicklern weltweit zugänglich ist. Sie können über mehrere Plattformen auf das Modell zugreifen:
- Hugging Face: Das Modell wird auf Hugging Face gehostet, wo Sie es für den lokalen Gebrauch herunterladen oder über die Transformers-Bibliothek integrieren können.
- ModelScope: Alibabas ModelScope-Plattform bietet einen weiteren Weg zum Zugriff auf und zur Bereitstellung des Modells.
Für eine nahtlose Integration können Entwickler die Qwen-API verwenden, die die Interaktion mit dem Modell vereinfacht. Unabhängig davon, ob Sie eine benutzerdefinierte Anwendung erstellen oder mit multimodalen Aufgaben experimentieren, gewährleistet die Qwen-API eine effiziente Konnektivität und robuste Leistung.
Bereitstellung mit Inferenz-Engines
Qwen2.5-VL-32B unterstützt die Bereitstellung mit Inferenz-Engines wie SGLang und vLLM. Diese Tools optimieren das Modell für schnelle Inferenz und reduzieren Latenz und Speicherverbrauch. Durch die Nutzung dieser Engines können Entwickler das Modell auf lokaler Hardware oder Cloud-Plattformen bereitstellen und es auf bestimmte Anwendungsfälle zuschneiden.
Installieren Sie zunächst die erforderlichen Bibliotheken (z. B. transformers, vllm) und befolgen Sie die Anweisungen auf der Qwen-GitHub-Seite oder in der Hugging Face-Dokumentation. Dieser Prozess gewährleistet eine reibungslose Integration, sodass Sie das volle Potenzial des Modells nutzen können.
Optimierung der lokalen Leistung
Beachten Sie beim lokalen Ausführen von Qwen2.5-VL-32B diese Optimierungstipps:
- Quantisierung: Fügen Sie während der Konvertierung das Flag
--quantizehinzu, um den Speicherbedarf zu reduzieren - Kontextlänge verwalten: Begrenzen Sie die Eingabe-Token für schnellere Antworten
- Ressourcenintensive Anwendungen schließen, wenn das Modell ausgeführt wird
- Stapelverarbeitung: Verarbeiten Sie bei mehreren Bildern diese in Stapeln und nicht einzeln
Fazit: Warum Qwen2.5-VL-32B wichtig ist
Qwen2.5-VL-32B stellt einen bedeutenden Meilenstein in der Entwicklung von Vision-Language-Modellen dar. Durch die Kombination von intelligenterem Denken, geringeren Ressourcenanforderungen und robuster Leistung erfüllt dieses Modell mit 32 Milliarden Parametern die Anforderungen von Entwicklern und Forschern gleichermaßen. Seine Fortschritte in mathematischem Denken, der Ausrichtung auf menschliche Präferenzen und Vision-Aufgaben positionieren es als Top-Wahl für den lokalen Einsatz und reale Anwendungen.
Egal, ob Sie Bildungstools, Business-Intelligence-Systeme oder Kundensupportlösungen erstellen, Qwen2.5-VL-32B bietet die Vielseitigkeit und Effizienz, die Sie benötigen. Mit dem Zugriff über Open-Source-Plattformen und die Qwen-API ist die Integration dieses Modells in Ihre Projekte einfacher denn je. Da das Qwen-Team weiterhin Innovationen vorantreibt, können wir in Zukunft noch aufregendere Entwicklungen im Bereich der multimodalen KI erwarten.
Mit diesem API-Tool können Sie die Endpunkte Ihres Modells mühelos testen und debuggen. Laden Sie Apidog noch heute kostenlos herunter und optimieren Sie Ihren Workflow, während Sie die Fähigkeiten von Mistral Small 3.1 erkunden!