
Qwen-Image, ein hochmodernes 20B MMDiT Bild-Grundlagenmodell vom Qwen-Team von Alibaba Cloud, definiert die Möglichkeiten der KI-gesteuerten visuellen Erstellung neu. Am 4. August 2025 eingeführt, bietet dieses Modell unübertroffene Fähigkeiten bei der Generierung hochwertiger Bilder, dem Rendern komplexer mehrsprachiger Texte und der Durchführung präziser Bildbearbeitungen. Egal, ob Sie dynamische Marketingvisuals erstellen oder komplexe Bilddaten analysieren, Qwen-Image stattet Entwickler mit robusten Werkzeugen aus, um Ideen zum Leben zu erwecken.
Was ist Qwen-Image? Ein technischer Überblick
Qwen-Image, Teil der Qwen-Serie von Alibaba Cloud, ist ein multimodales Diffusions-Transformer-Modell (MMDiT) mit 20 Milliarden Parametern, das sowohl für die Bilderzeugung als auch für die Bildbearbeitung entwickelt wurde. Im Gegensatz zu traditionellen Modellen, die sich ausschließlich auf die Generierung von Visuals konzentrieren, integriert Qwen-Image fortschrittliches Text-Rendering und Bildverständnis, was es zu einem vielseitigen Werkzeug für kreative und analytische Aufgaben macht. Das Modell, das unter der Apache 2.0 Lizenz als Open Source veröffentlicht wurde, ist über Plattformen wie GitHub, Hugging Face und ModelScope zugänglich, sodass Entwickler es in verschiedene Workflows integrieren können.

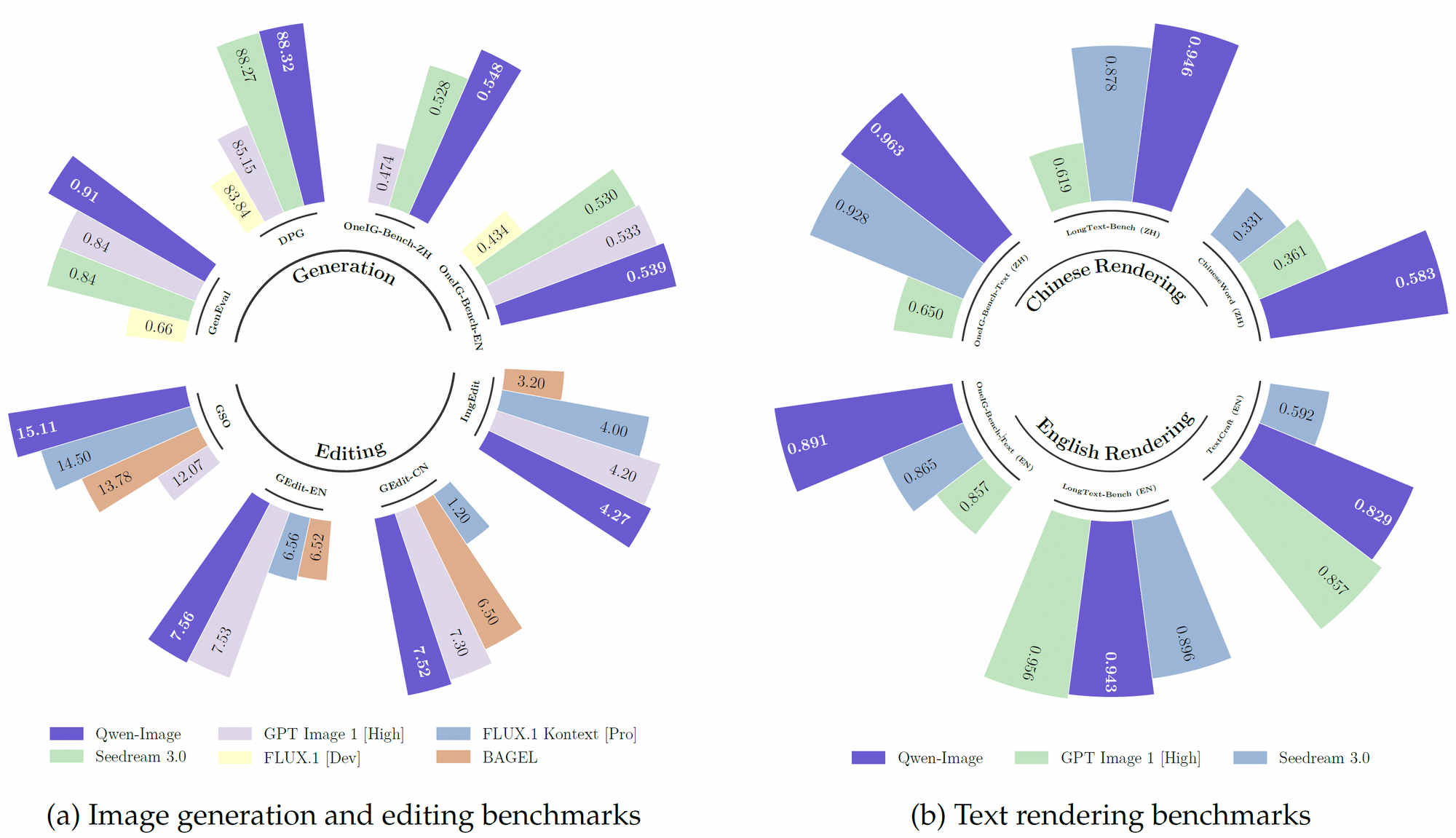
Darüber hinaus nutzt Qwen-Image einen robusten Vortrainingsdatensatz, der über 30 Billionen Tokens in 119 Sprachen umfasst, mit einem Schwerpunkt auf Chinesisch und Englisch. Dieser umfangreiche Datensatz, kombiniert mit Reinforcement-Learning-Techniken, ermöglicht es dem Modell, komplexe Aufgaben wie mehrsprachiges Text-Rendering und präzise Objektmanipulation zu bewältigen. Folglich übertrifft es viele bestehende Modelle bei Benchmarks wie GenEval, DPG und LongText-Bench.
Hauptmerkmale von Qwen-Image
Überragendes Text-Rendering für mehrsprachige Visuals
Qwen-Image zeichnet sich durch das Rendern komplexer Texte innerhalb von Bildern aus, eine Funktion, die es von Mitbewerbern abhebt. Es unterstützt sowohl alphabetische Sprachen (z. B. Englisch) als auch logographische Schriften (z. B. Chinesisch) und gewährleistet eine hochpräzise Textintegration. Zum Beispiel kann das Modell ein Filmplakat mit präzisen Textlayouts generieren, wie einen Titel wie „Imagination Unleashed“ und Untertitel in mehreren Zeilen, wobei die typografische Kohärenz erhalten bleibt. Diese Fähigkeit resultiert aus seinem Training auf verschiedenen Datensätzen, einschließlich LongText-Bench und ChineseWord, wo es eine Spitzenleistung erzielt.
Darüber hinaus verarbeitet Qwen-Image mehrzeilige Layouts und Semantik auf Absatzzebene mit bemerkenswerter Genauigkeit. In einem Testszenario rendert es ein handgeschriebenes Gedicht auf vergilbtem Papier innerhalb eines Bildes präzise, obwohl der Text weniger als ein Zehntel des visuellen Raums einnimmt. Diese Präzision macht es ideal für Anwendungen wie digitale Beschilderung, Plakatgestaltung und Dokumentenvisualisierung.
Erweiterte Bildbearbeitungsfunktionen
Neben dem Text-Rendering bietet Qwen-Image ausgeklügelte Bildbearbeitungsfunktionen. Es unterstützt Operationen wie Stilübertragung, Objekteinfügung, Detailverbesserung und Manipulation menschlicher Posen. Zum Beispiel können Benutzer das Modell anweisen, „einen sonnigen Himmel zu diesem Bild hinzuzufügen“ oder „dieses Gemälde in einen Van-Gogh-Stil zu ändern“, und Qwen-Image liefert kohärente Ergebnisse. Sein erweitertes Multi-Task-Trainingsparadigma stellt sicher, dass Bearbeitungen die semantische Bedeutung und den visuellen Realismus bewahren.
Besonders hervorzuheben ist die Fähigkeit des Modells, Text innerhalb von Bildern zu bearbeiten. Entwickler können Text auf Schildern oder Plakaten ändern, ohne den umgebenden visuellen Kontext zu stören, eine Funktion, die für Werbung und Inhaltserstellung wertvoll ist. Diese Fähigkeiten werden durch das tiefe visuelle Verständnis von Qwen-Image unterstützt, das es ihm ermöglicht, Bildelemente präzise zu interpretieren und zu manipulieren.
Umfassendes visuelles Verständnis
Qwen-Image erstellt oder bearbeitet nicht nur – es versteht. Das Modell unterstützt eine Reihe von Aufgaben zum Bildverständnis, darunter Objekterkennung, semantische Segmentierung, Tiefenschätzung, Kantenerkennung (Canny), neuartige Ansichtssynthese und Super-Resolution. Diese Aufgaben werden durch seine Fähigkeit ermöglicht, hochauflösende Eingaben zu verarbeiten und feine Details zu extrahieren. Zum Beispiel kann Qwen-Image Begrenzungsrahmen für Objekte generieren, die in natürlicher Sprache beschrieben werden, wie „Erkenne den Husky-Hund in der U-Bahn-Szene“, was es zu einem leistungsstarken Werkzeug für die visuelle Analyse macht.
Darüber hinaus verbessert die Unterstützung mehrerer Sprachen seine Nutzbarkeit in globalen Anwendungen. Durch die Integration mit Tools wie dem Qwen-Plus Prompt Enhancement Tool können Entwickler Prompts für eine bessere mehrsprachige Leistung optimieren und so genaue Ergebnisse in verschiedenen sprachlichen Kontexten gewährleisten.
Exzellente Leistung über Benchmarks hinweg
Qwen-Image übertrifft Mitbewerber bei mehreren öffentlichen Benchmarks, darunter GenEval, DPG, OneIG-Bench, GEdit, ImgEdit und GSO, konstant. Seine überragende Leistung beim Text-Rendering, insbesondere für Chinesisch, zeigt sich in Benchmarks wie TextCraft, wo es bestehende State-of-the-Art-Modelle übertrifft. Darüber hinaus unterstützen seine allgemeinen Bildgenerierungsfähigkeiten eine breite Palette künstlerischer Stile, von fotorealistischen Szenen bis hin zu Anime-Ästhetiken, was es zu einer vielseitigen Wahl für Kreativprofis.
Technische Architektur von Qwen-Image
Multimodaler Diffusions-Transformer (MMDiT)
Im Kern verwendet Qwen-Image eine multimodale Diffusions-Transformer-Architektur (MMDiT), die die Stärken von Diffusionsmodellen und Transformatoren kombiniert. Dieser hybride Ansatz ermöglicht es dem Modell, sowohl visuelle als auch textuelle Eingaben effizient zu verarbeiten. Der Diffusionsprozess verfeinert iterative verrauschte Eingaben zu kohärenten Bildern, während die Transformer-Komponente komplexe Beziehungen zwischen Text und visuellen Elementen handhabt.
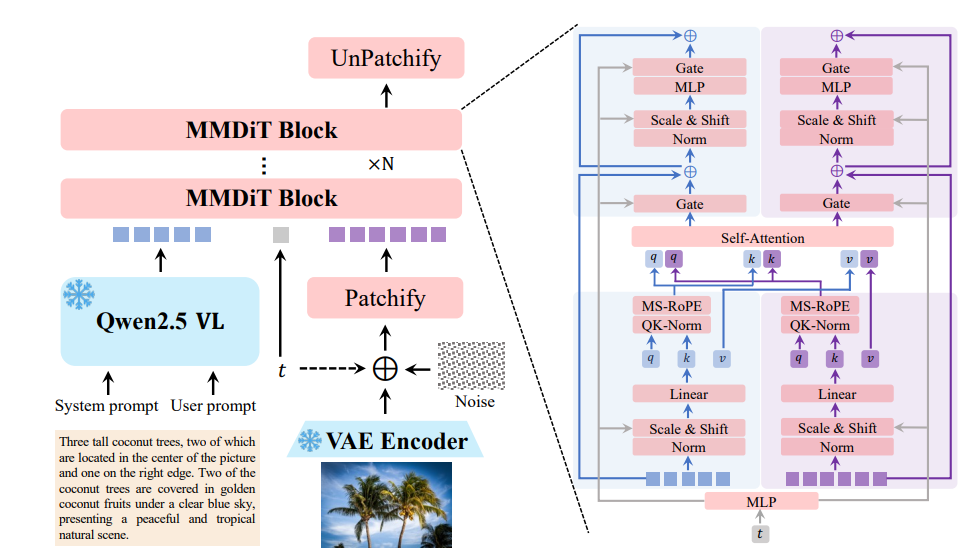
Die 20 Milliarden Parameter des Modells sind auf Effizienz optimiert, sodass es auf Consumer-Hardware mit nur 4 GB VRAM ausgeführt werden kann, wenn Techniken wie FP8-Quantisierung und Layer-by-Layer-Offloading verwendet werden. Diese Zugänglichkeit macht Qwen-Image sowohl für Unternehmens- als auch für individuelle Entwickler geeignet.
Vortraining und Feinabstimmung
Qwen-Images Vortrainingsdatensatz ist ein Eckpfeiler seiner Leistung. Der Datensatz, der über 30 Billionen Tokens umfasst, enthält Webdaten, PDF-ähnliche Dokumente und synthetische Daten, die von Modellen wie Qwen2.5-VL und Qwen2.5-Coder generiert wurden. Der Vortrainingsprozess erfolgt in drei Stufen:

- Stufe 1 (S1): Das Modell wird mit 30 Billionen Tokens und einer Kontextlänge von 4K Tokens vortrainiert, wodurch grundlegende Sprach- und visuelle Fähigkeiten etabliert werden.
- Stufe 2: Reinforcement Learning verbessert die Denkfähigkeiten und aufgabenspezifischen Funktionen des Modells.
- Stufe 3: Die Feinabstimmung mit kuratierten Datensätzen verbessert die Anpassung an Benutzerpräferenzen und spezifische Aufgaben wie Text-Rendering und Bildbearbeitung.
Dieser mehrstufige Ansatz stellt sicher, dass Qwen-Image sowohl robust als auch anpassungsfähig ist und vielfältige Aufgaben mit hoher Genauigkeit bewältigen kann.
Integration mit Entwicklungstools
Qwen-Image lässt sich nahtlos in beliebte Entwicklungsframeworks wie Diffusers und DiffSynth-Studio integrieren. Zum Beispiel können Entwickler den folgenden Python-Code verwenden, um Bilder mit Qwen-Image zu generieren:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Dieser Codeausschnitt zeigt, wie Entwickler die Funktionen von Qwen-Image nutzen können, um hochwertige Visuals mit minimalem Aufwand zu generieren. Tools wie Apidog vereinfachen die API-Integration zusätzlich und ermöglichen schnelles Prototyping und Deployment.
Praktische Anwendungen von Qwen-Image
Generierung kreativer Inhalte
Die Fähigkeit von Qwen-Image, fotorealistische Szenen, impressionistische Gemälde und Visuals im Anime-Stil zu generieren, macht es zu einem leistungsstarken Werkzeug für Künstler und Designer. Zum Beispiel kann ein Grafikdesigner ein Filmplakat mit dynamischen Textlayouts und lebendigen Bildern erstellen, wie in einem Testfall gezeigt, bei dem Qwen-Image ein Plakat für „Imagination Unleashed“ mit einem futuristischen Computer, der skurrile Kreaturen aussendet, produzierte.

Werbung und Marketing
In der Werbung ermöglichen die Text-Rendering- und Bearbeitungsfunktionen von Qwen-Image die Erstellung visuell ansprechender Kampagnen. Vermarkter können Plakate mit präziser Textplatzierung generieren oder bestehende Visuals bearbeiten, um Werbebotschaften zu aktualisieren und so Markenkonsistenz und visuelle Kohärenz zu gewährleisten.

Visuelle Analyse und Automatisierung
Für Branchen wie E-Commerce und autonome Systeme bieten die Bildverständnisaufgaben von Qwen-Image – wie Objekterkennung und semantische Segmentierung – einen erheblichen Mehrwert. Einzelhandelsplattformen können das Modell verwenden, um Produkte in Bildern automatisch zu kennzeichnen, während autonome Fahrzeuge seine Tiefenschätzung zur Navigation nutzen können.
Bildungstools
Die Fähigkeit von Qwen-Image, Bildungsvisualisierungen wie Diagramme mit präzisen Textanmerkungen zu generieren, unterstützt E-Learning-Plattformen. Zum Beispiel kann es eine detaillierte Illustration eines wissenschaftlichen Konzepts mit beschrifteten Komponenten erstellen, was das Engagement und Verständnis der Schüler verbessert.

Qwen-Image im Vergleich zu Mitbewerbern
Im Vergleich zu Modellen wie DALL-E 3 und Stable Diffusion zeichnet sich Qwen-Image durch sein mehrsprachiges Text-Rendering und seine erweiterten Bearbeitungsfunktionen aus. Während DALL-E 3 bei der kreativen Bilderzeugung hervorragend ist, hat es Schwierigkeiten mit komplexen Textlayouts, insbesondere bei logographischen Schriften. Stable Diffusion ist zwar vielseitig, aber es fehlt ihm das tiefe visuelle Verständnis, das Qwen-Image mit seiner Suite von Verständnisaufgaben bietet.
Darüber hinaus verschafft Qwen-Images Open-Source-Natur und Kompatibilität mit Hardware mit geringem Speicher Entwicklern mit begrenzten Ressourcen einen Vorteil. Seine Leistung bei Benchmarks wie TextCraft und GEdit festigt seine Position als führendes Modell in der multimodalen KI zusätzlich.
Herausforderungen und Einschränkungen
Trotz seiner Stärken steht Qwen-Image vor Herausforderungen. Die Abhängigkeit des Modells von großen Datensätzen wirft Bedenken hinsichtlich des Datenschutzes und der ethischen Beschaffung auf, obwohl Alibaba Cloud strenge Richtlinien einhält. Obwohl das Modell über 100 Sprachen unterstützt, kann seine Leistung bei weniger vertretenen Dialekten variieren, was eine weitere Feinabstimmung erfordert.
Darüber hinaus können die Rechenanforderungen des 20B-Parameter-Modells ohne Optimierungstechniken wie FP8-Quantisierung erheblich sein. Entwickler müssen bei der Bereitstellung von Qwen-Image in Produktionsumgebungen Leistung und Ressourcenbeschränkungen abwägen.
Zukunftsaussichten für Qwen-Image
Mit Blick in die Zukunft ist Qwen-Image bereit, sich weiterzuentwickeln. Das Qwen-Team plant die Veröffentlichung einer bearbeitungsspezifischen Version des Modells, die seine Fähigkeiten für professionelle Anwendungen verbessert. Die Integration mit neuen Frameworks wie vLLM und die fortlaufende Unterstützung für LoRA- und Feinabstimmungs-Workflows werden seine Zugänglichkeit erweitern.
Darüber hinaus deuten Fortschritte im Reinforcement Learning, wie sie bei Modellen wie Qwen3 zu sehen sind, darauf hin, dass Qwen-Image tiefere Denkfähigkeiten integrieren könnte, was komplexere visuelle Denkaufgaben ermöglicht. Da die KI-Gemeinschaft weiterhin zu seiner Entwicklung beiträgt, hat Qwen-Image das Potenzial, die visuelle Erstellung und das Verständnis neu zu definieren.
Erste Schritte mit Qwen-Image
Um Qwen-Image zu verwenden, können Entwickler auf die Modellgewichte auf GitHub oder Hugging Face zugreifen. Der offizielle Blog unter qwenlm.github.io bietet detaillierte Einrichtungsanweisungen und Anwendungsfälle. Für eine praktische Erfahrung besuchen Sie Qwen Chat und wählen Sie „Image Generation“, um die Fähigkeiten des Modells zu testen.
Für die API-Integration vereinfachen Tools wie Apidog den Prozess, indem sie eine benutzerfreundliche Oberfläche zum Testen und Bereitstellen der Funktionen von Qwen-Image bieten. Laden Sie Apidog kostenlos herunter, um Ihren Entwicklungsworkflow zu optimieren.
Fazit: Warum Qwen-Image wichtig ist
Qwen-Image stellt einen bedeutenden Fortschritt in der multimodalen KI dar, indem es fortschrittliches Text-Rendering, präzise Bildbearbeitung und robustes visuelles Verständnis kombiniert. Seine Open-Source-Verfügbarkeit, das umfangreiche Vortraining und die Kompatibilität mit Entwicklungstools machen es zu einer vielseitigen Wahl für Kreative, Entwickler und Forscher. Durch die Bewältigung von Herausforderungen wie mehrsprachiger Unterstützung und Ressourceneffizienz setzt Qwen-Image einen neuen Standard für die KI-gesteuerte visuelle Erstellung.
Während sich die KI weiterentwickelt, werden Modelle wie Qwen-Image eine zentrale Rolle dabei spielen, die Lücke zwischen Sprache und Bildern zu schließen und neue Möglichkeiten für kreative und analytische Anwendungen zu erschließen. Egal, ob Sie eine Marketingkampagne erstellen, visuelle Daten analysieren oder Bildungsinhalte schaffen, Qwen-Image bietet die Werkzeuge, um Ihre Vision zum Leben zu erwecken.