
Entwickler suchen zunehmend nach robusten Tools, um Echtzeit-Websuchfunktionen in ihre KI-gesteuerten Anwendungen zu integrieren. Die Perplexity Search API hebt sich als leistungsstarke Lösung hervor, die Zugriff auf einen umfangreichen Index von Webinhalten mit hoher Genauigkeit und Geschwindigkeit bietet. Diese API ermöglicht die nahtlose Integration von Suchfunktionen, die mit führenden Antwort-Engines konkurrieren können, sodass Sie anspruchsvolle Systeme aufbauen können, ohne komplexe Infrastruktur verwalten zu müssen.
Darüber hinaus erfordert das Verständnis der Perplexity Search API ein grundlegendes Wissen über ihre Kernkomponenten, von der Authentifizierung bis hin zu fortgeschrittenen Abfragen. Ingenieure schätzen ihr KI-zentriertes Design, das Relevanz und Effizienz priorisiert. Folglich bietet dieser Leitfaden einen schrittweisen Ansatz, der auf offizieller Dokumentation und technischen Einblicken basiert. Sie finden detaillierte Erklärungen, Code-Snippets und praktische Tipps zur effektiven Implementierung. Bevor Sie jedoch fortfahren, sollten Sie die Entwicklung der API berücksichtigen – sie wurde eingeführt, um den Zugang zu internetweitem Wissen zu demokratisieren und schließt Lücken in traditionellen Such-APIs, indem sie sich auf die KI-Kompatibilität konzentriert.
Was ist die Perplexity Search API?
Die Perplexity Search API liefert rohe Websuchergebnisse und ermöglicht Entwicklern, hybride Suchen durchzuführen, die semantisches Verständnis mit lexikalischem Abgleich kombinieren. Sie greift auf einen Index von Hunderten von Milliarden Webseiten zu und verarbeitet Aktualisierungen mit einer Rate von Zehntausenden pro Sekunde, um Aktualität zu gewährleisten. Im Gegensatz zu herkömmlichen Suchtools betont diese API KI-Workloads und liefert strukturierte Antworten mit individuell bewerteten Dokumenteinheiten für ein präzises Snippet-Ranking.
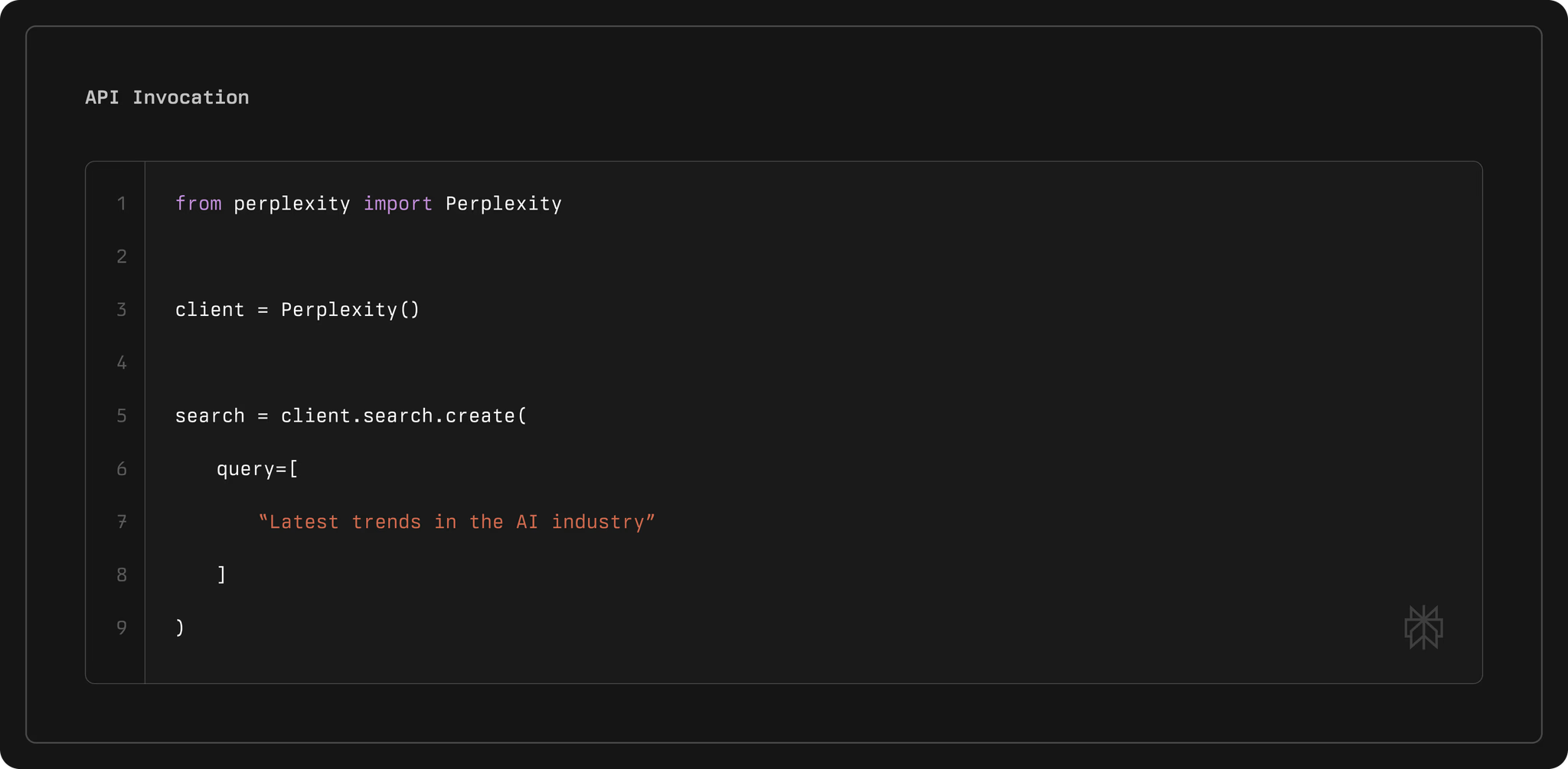
Die Ingenieure von Perplexity haben die API so konzipiert, dass sie an vorderster Front in Bezug auf Relevanz und Geschwindigkeit steht und Konkurrenten bei Latenz- und Qualitätsmetriken übertrifft. Zum Beispiel erreicht sie eine mittlere Latenz von 358 Millisekunden, weit unter Alternativen wie Exa mit 1375 Millisekunden. Zusätzlich integriert die API menschliche Feedbackschleifen und LLM-Ranking, um Ergebnisse zu verfeinern, was sie ideal für Anwendungen macht, die eine vertrauenswürdige Informationsbeschaffung erfordern.
Darüber hinaus zeichnet sich die Perplexity Search API durch Datenschutzverpflichtungen – keine Nutzerdaten trainieren die zugrunde liegenden LLMs – und Erschwinglichkeit aus, mit führenden Preisen für Suchanfragen. Entwickler setzen sie in verschiedenen Szenarien ein, von einfachen Q&A-Bots bis hin zu komplexen Forschungsagenten. Daher dient sie als grundlegende Schicht für den Aufbau von KI-Agenten, die tiefgreifende Untersuchungen im Web durchführen.
Hauptmerkmale und Vorteile der Perplexity Search API
Die Perplexity Search API verfügt über mehrere herausragende Funktionen, die ihren Nutzen für technische Implementierungen erhöhen. Erstens bietet sie ein feingranulares Inhaltsverständnis, indem sie Dokumente in Untereinheiten für gezielte Abrufe segmentiert. Dieser Ansatz reduziert den Vorverarbeitungsaufwand und beschleunigt die Integration in KI-Pipelines. Darüber hinaus unterstützt die API erweiterte Filter, mit denen Sie Parameter für Echtzeitdaten festlegen und irrelevante Inhalte ausschließen können.
Ein weiteres wichtiges Merkmal ist ihr hybrides Abrufsystem, das lexikalische und semantische Signale zusammenführt, um umfassende Kandidatensätze zu generieren. Ingenieure schätzen dies, da es die Vollständigkeit gewährleistet und gleichzeitig eine geringe Latenz beibehält. Darüber hinaus liefert die API strukturierte Ausgaben, einschließlich bewerteter Snippets und Zitate, die das Vertrauen in die Ergebnisse fördern.
Die Vorteile gehen über die technische Leistungsfähigkeit hinaus. Entwickler sparen Kosten mit ihrem Preismodell – 5 $ pro 1.000 Anfragen für Rohsuchen – was sie wirtschaftlicher macht als vergleichbare Angebote. Darüber hinaus skaliert sie mühelos und verarbeitet bis zu 200 Millionen tägliche Abfragen ohne Leistungseinbußen. Infolgedessen übernehmen Startups und Unternehmen gleichermaßen die API, um schnell Innovationen voranzutreiben und Produkte in weniger als einer Stunde mithilfe des zugehörigen SDK zu prototypisieren.
Der wahre Vorteil liegt jedoch in ihren kontinuierlichen Verbesserungen. Perplexity integriert Benutzersignale aus Millionen von Interaktionen, um die API iterativ zu verbessern und sicherzustellen, dass sie sich mit der Dynamik von Webinhalten weiterentwickelt. Folglich erhalten Sie Zugang zu einem Tool, das nicht nur aktuelle Anforderungen erfüllt, sondern auch zukünftige Anforderungen in der KI-Suche antizipiert.
Die Architektur der Perplexity Search API verstehen
Perplexity konzipiert die Search API mit Fokus auf Skalierbarkeit und Intelligenz. Im Kern verwendet das System eine mehrstufige Speicherarchitektur, einschließlich über 400 Petabyte in Hot Storage, um Milliarden von Dokumenten effizient zu verwalten. Maschinelles Lernen priorisiert das Crawling und die Indexierung und prognostiziert die URL-Wichtigkeit basierend auf Faktoren wie der Aktualisierungsfrequenz.
Darüber hinaus verwendet das Modul zum Inhaltsverständnis eine dynamische Parsing-Logik, die von führenden LLMs angetrieben wird, um sich an verschiedene Website-Layouts anzupassen. Dieses Modul verarbeitet stündlich Millionen von Abfragen und verbessert sich selbst durch Bewertungszyklen, um Vollständigkeit und Qualität zu optimieren. Ingenieure segmentieren Dokumente in Untereinheiten, um Kontextbeschränkungen in KI-Modellen zu adressieren und präzises Ranking zu ermöglichen.
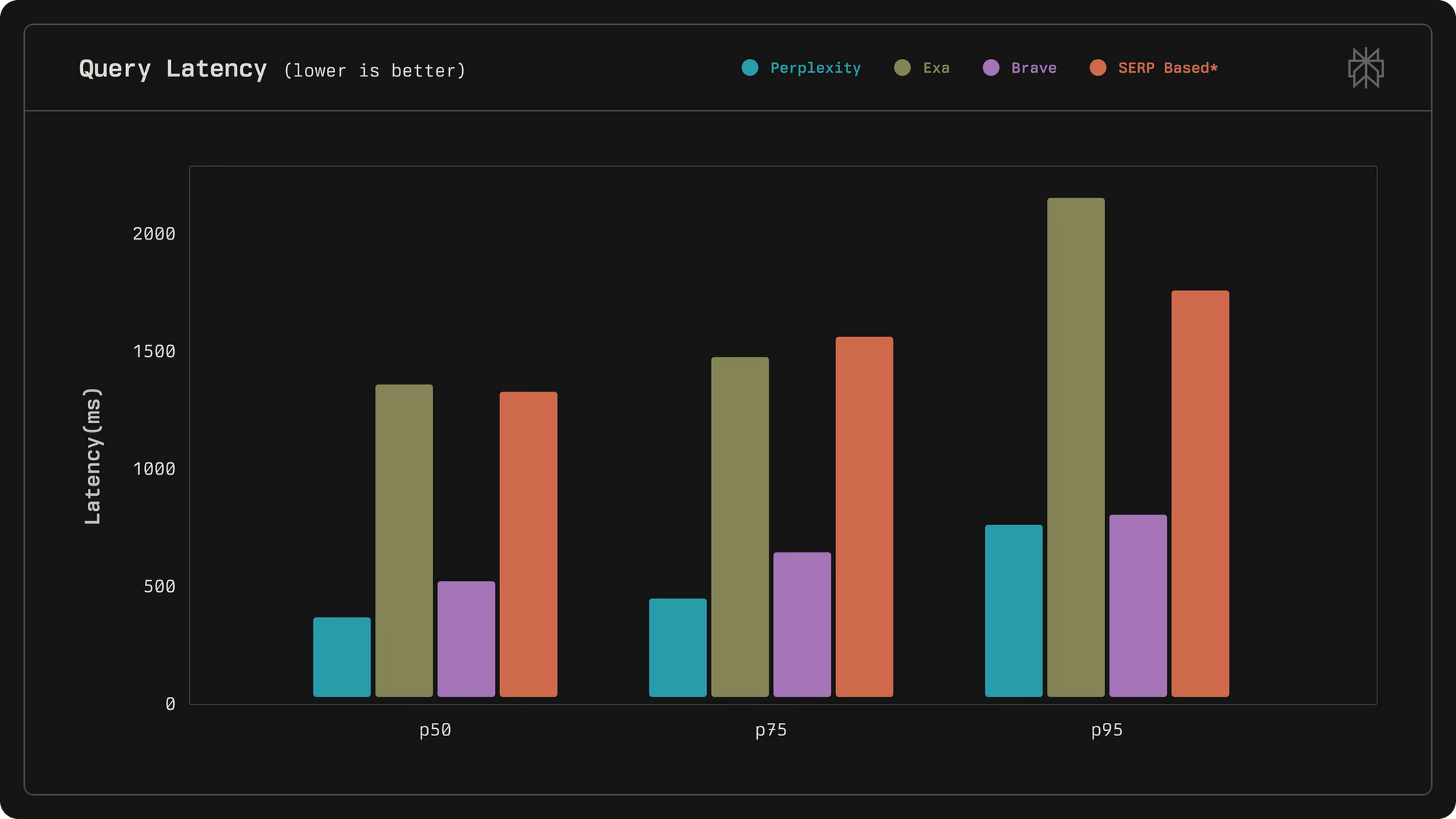
Die Abruf-Pipeline folgt einem mehrstufigen Prozess: Die anfängliche hybride Abrufung generiert Kandidaten, die Vorfilterung entfernt Rauschen, und das progressive Ranking wendet lexikalische, embedding-basierte und Cross-Encoder-Modelle an. Dieses Design nutzt Live-Signale für das Training, das gemeinsam mit den Produkten von Perplexity entwickelt wurde, um die Genauigkeit zu steigern.
Herausforderungen in dieser Architektur umfassen das Gleichgewicht zwischen Aktualität und Vollständigkeit unter Budgetbeschränkungen. Perplexity löst diese durch ML-gesteuerte Priorisierung und horizontale Skalierung. Als Best Practice empfiehlt das Team hybride Signale und strenge Bewertungen mithilfe ihres Open-Source-Frameworks search_evals.
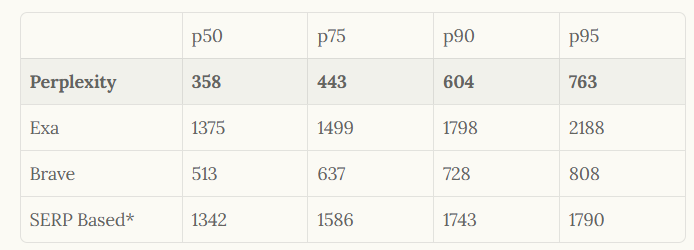
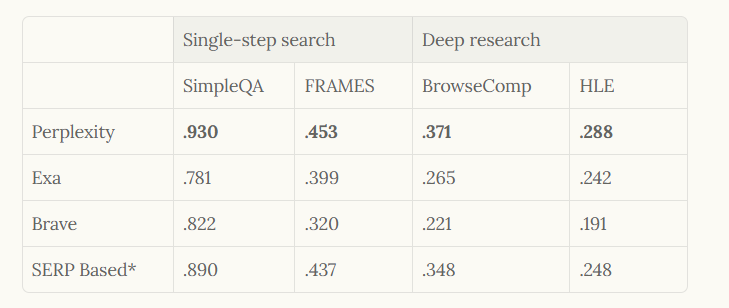
Bei der Bewertung verwendet Perplexity Benchmarks wie SimpleQA für einstufige Suchen und BrowseComp für tiefe Forschung und erzielt Top-Ergebnisse wie 0,930 in SimpleQA. Daher unterstützt diese Architektur nicht nur eine hohe Nutzung, sondern setzt auch einen Standard für KI-zentrierte Suchsysteme.
Preise und Abonnementpläne für die Perplexity Search API
Perplexity strukturiert die Preisgestaltung der Search API, um Erschwinglichkeit und Transparenz zu priorisieren. Die Grundkosten für rohe Websuchergebnisse betragen 5 $ pro 1.000 Anfragen, ohne zusätzliche tokenbasierte Gebühren für diesen Endpunkt. Dieses Modell eignet sich für Entwickler, die eine unkomplizierte Suchintegration ohne komplexe Abrechnung benötigen.
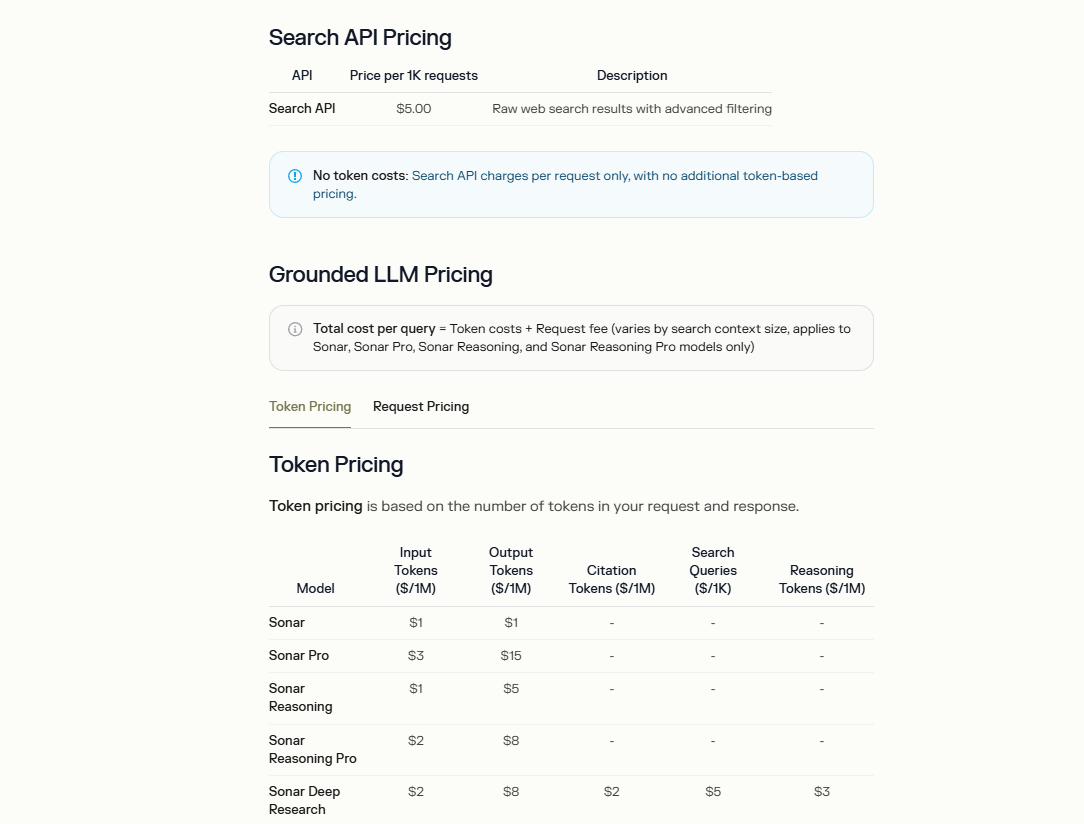
Für fundierte LLM-Integrationen umfassen die Preise Token-Kosten zuzüglich einer Anfragegebühr, die je nach Modell variiert. Zum Beispiel berechnet das Sonar-Modell 1 $ pro Million Eingabe-Tokens und 1 $ pro Million Ausgabe-Tokens. Fortgeschrittene Varianten wie Sonar Pro steigen auf 3 $ pro Million Eingabe und 15 $ pro Million Ausgabe. Zusätzlich beinhaltet Sonar Deep Research Gebühren für Zitat-Tokens (2 $ pro Million), Suchanfragen (5 $ pro 1.000) und Reasoning-Tokens (3 $ pro Million).
Nutzungslimits sind direkt an diese Metriken gebunden, wobei ein Token ungefähr vier Zeichen im englischen Text entspricht. Entwickler überwachen den Verbrauch über den Admin-Bereich des API-Portals, der Abrechnung und Zahlungen verwaltet. Die Dokumentation enthält jedoch keine kostenlosen Stufen für die Search API, was die Betonung auf kostenpflichtigen Zugang für den Produktionseinsatz legt.
Folglich ermöglicht diese Preisgestaltung eine skalierbare Einführung. Kleine Teams beginnen mit grundlegenden Suchen, während Unternehmen fortschrittliche Modelle für umfassende Anwendungen nutzen. Überprüfen Sie immer die neuesten Details im offiziellen Portal, um sie an das Budget Ihres Projekts anzupassen.
Erste Schritte: Registrierung und Beschaffung eines API-Schlüssels
Um die Perplexity Search API zu verwenden, navigieren Sie zur API-Plattform. Erstellen Sie ein Konto, falls Sie noch keines haben, und greifen Sie dann auf den Tab "API Keys" zu, um einen neuen Schlüssel zu generieren. Dieser Schlüssel authentifiziert alle Anfragen, bewahren Sie ihn daher sicher auf.
Als Nächstes legen Sie den Schlüssel als Umgebungsvariable fest. Unter Windows verwenden Sie den Befehl setx PERPLEXITY_API_KEY "your_api_key_here". Für andere Systeme exportieren Sie ihn in Ihrer Shell. Diese Einrichtung ermöglicht es SDK-Clients, den Schlüssel automatisch zu erkennen, was die Authentifizierung vereinfacht.
Erwägen Sie außerdem die Verwendung von Tools wie python-dotenv zur Verwaltung von Geheimnissen in Entwicklungsumgebungen. Laden Sie die .env-Datei in Ihrem Code, um das Hardcodieren sensibler Informationen zu vermeiden. Nach der Konfiguration können Sie Clients in Python oder Node.js nahtlos instanziieren.
Überprüfen Sie jedoch Ihre Einrichtung, indem Sie eine Testanfrage stellen. Sollten Probleme auftreten, konsultieren Sie die Community-Foren oder die Dokumentation zur Fehlerbehebung. Dieser erste Schritt gewährleistet einen reibungslosen Übergang zur Implementierung.
Installation des Perplexity SDK für Python und Node.js
Das Perplexity SDK erleichtert die Interaktion mit der Search API in Python 3.8+ und Node.js. Für Python installieren Sie es über pip: pip install perplexityai. Dieser Befehl ruft das Paket ab, einschließlich Typdefinitionen für Parameter und Antworten.
In Node.js verwenden Sie, obwohl die spezifischen Installationsdetails variieren, typischerweise npm oder yarn, um das Paket hinzuzufügen. Das SDK unterstützt synchrone und asynchrone Operationen, was die Flexibilität für verschiedene Anwendungsarchitekturen erhöht.
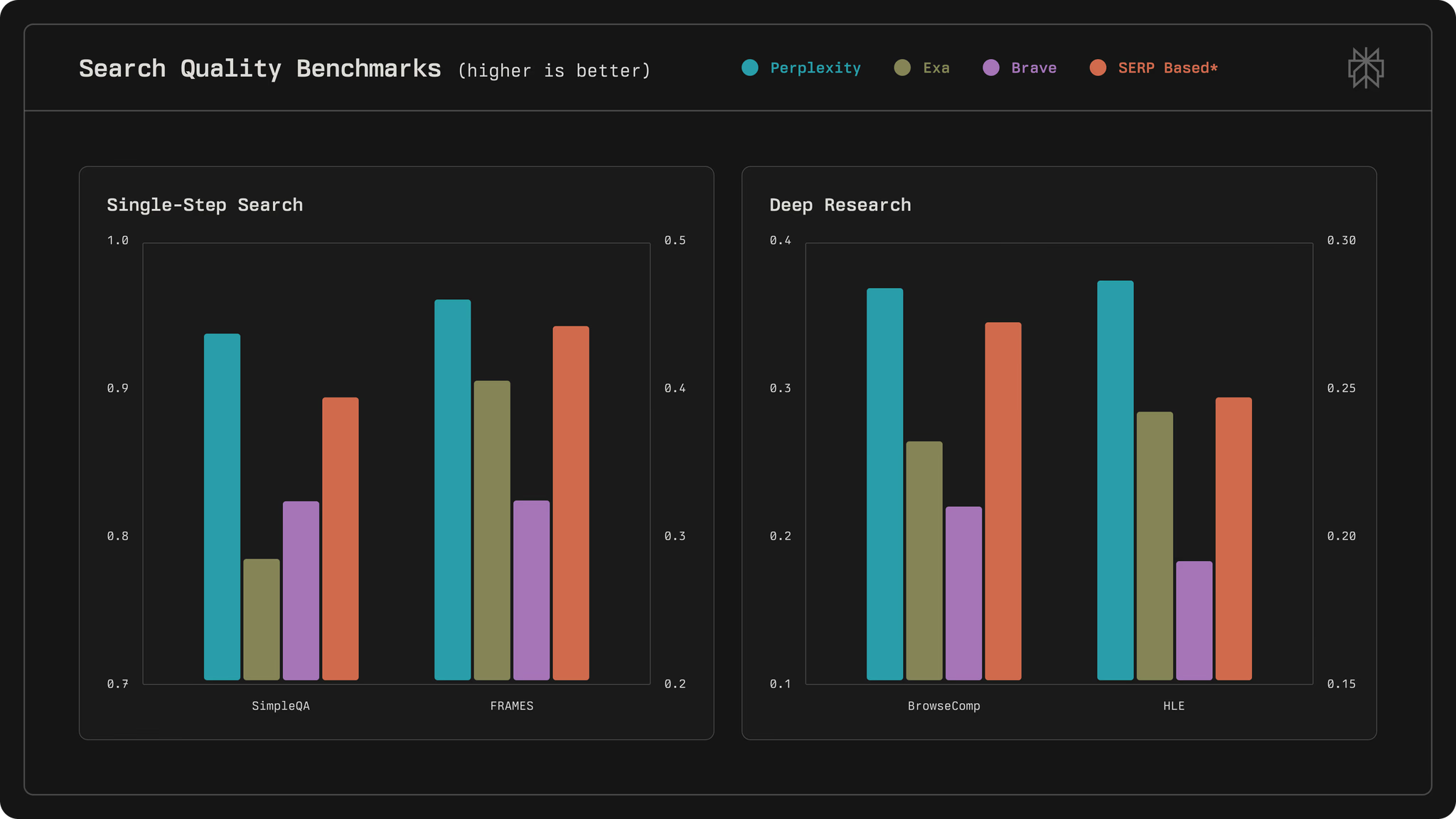
Nach der Installation importieren Sie die Bibliothek. In Python verwenden Sie from perplexity import Perplexity und erstellen einen Client: client = Perplexity(). Dieser Client ruft den API-Schlüssel automatisch aus den Umgebungsvariablen ab.
Darüber hinaus bietet das SDK umfassende Unterstützung für alle API-Endpunkte, um sicherzustellen, dass Sie Anfragen effizient bearbeiten. Testen Sie die Installation, indem Sie sie fehlerfrei importieren, um die Bereitschaft zum Codieren zu bestätigen.
Ihre erste Suchanfrage mit der Perplexity Search API stellen
Nachdem das SDK installiert ist, initiieren Sie Ihre erste Anfrage. In Python verwenden Sie die Suchmethode des Clients mit einem Abfrageparameter. Zum Beispiel:
import os
from perplexity import Perplexity
client = Perplexity()
response = client.search("example query")
print(response)
Dieser Code sendet eine grundlegende Suche und gibt die strukturierte Antwort aus, einschließlich Ergebnisse und Bewertungen.
Darüber hinaus können Sie die Anfrage anpassen, indem Sie Filter wie Datumsbereiche oder Domänen hinzufügen, um die Ausgaben zu verfeinern. Die API gibt JSON mit Dokumenteinheiten, Snippets und Relevanzbewertungen zurück, bereit zur Verarbeitung in Ihrer Anwendung.
Behandeln Sie Fehler jedoch elegant. Implementieren Sie try-except-Blöcke, um Authentifizierungsprobleme oder Ratenbegrenzungen abzufangen. Protokollieren Sie bei Experimenten die Antworten, um das Ausgabeformat genau zu verstehen.
Folglich demonstriert diese einfache Anfrage die Benutzerfreundlichkeit der API und ebnet den Weg für komplexere Integrationen.
Erweiterte Nutzung: Parameter, Filterung und Anpassung
Die Perplexity Search API unterstützt umfangreiche Parameter für maßgeschneiderte Suchen. Geben Sie query als primäre Eingabe an und fügen Sie dann filter für Medientypen oder since/until für zeitbasierte Einschränkungen hinzu. Fügen Sie beispielsweise geocode für ortsspezifische Ergebnisse hinzu, verwenden Sie es jedoch aufgrund von Geo-Tagging-Einschränkungen sparsam.
Nutzen Sie zusätzlich erweiterte Operatoren wie exakte Phrasen oder Ausschlüsse, um die Präzision zu erhöhen. Das hybride System wendet automatisch semantisches Ranking an, Sie können es jedoch durch Modellauswahl in fundierten Aufrufen beeinflussen.
Im Code erweitern Sie die grundlegende Anfrage:
response = client.search(
query="AI search APIs",
filter="news",
since="2025-01-01"
)
Dies ruft aktuelle Nachrichtenartikel ab, die nach Relevanz bewertet wurden.
Darüber hinaus können Sie für tiefe Forschung mit Sonar Deep Research-Modellen integrieren, was zusätzliche Token-Kosten verursacht, aber ein schrittweises Reasoning ermöglicht. Passen Sie reasoning_effort an, um die Abfragetiefe zu steuern.
Daher ermöglicht die Beherrschung dieser Parameter die Optimierung für spezifische Anwendungsfälle, von schnellen Nachschlagen bis hin zu umfassenden Analysen.
Integration der Perplexity Search API in Ihre Anwendungen
Entwickler integrieren die Perplexity Search API mühelos in Web-Apps, Chatbots und KI-Agenten. Für ein Node.js-Backend verwenden Sie das SDK, um asynchrone Anfragen zu verarbeiten und die Ergebnisse an Frontend-Komponenten zu übergeben.
Zum Beispiel in einem Recherchetool fragen Sie die API bei Benutzereingaben ab, parsen die Antworten und zeigen zitierte Snippets an. Stellen Sie die Einhaltung von Ratenbegrenzungen durch Implementierung von Caching oder Warteschlangen sicher.
Kombinieren Sie es außerdem mit anderen Diensten. Koppeln Sie es mit Bibliotheken zur Verarbeitung natürlicher Sprache, um Abfragen vorzuverarbeiten und die Genauigkeit zu verbessern.
Berücksichtigen Sie jedoch die Skalierbarkeit. Überwachen Sie die Nutzung, um Budgetüberschreitungen zu vermeiden, und verwenden Sie, falls verfügbar, Webhooks für Updates.
Dadurch verwandelt diese Integration statische Apps in dynamische, wissensbasierte Systeme.
Testen und Debuggen mit Apidog
Apidog dient als All-in-One-Plattform für die API-Entwicklung, die es Ihnen ermöglicht, Endpunkte wie die Perplexity Search API zu entwerfen, zu debuggen, zu mocken und zu testen. Es optimiert Workflows, indem es reale Szenarien simuliert und Fehler frühzeitig erkennt.
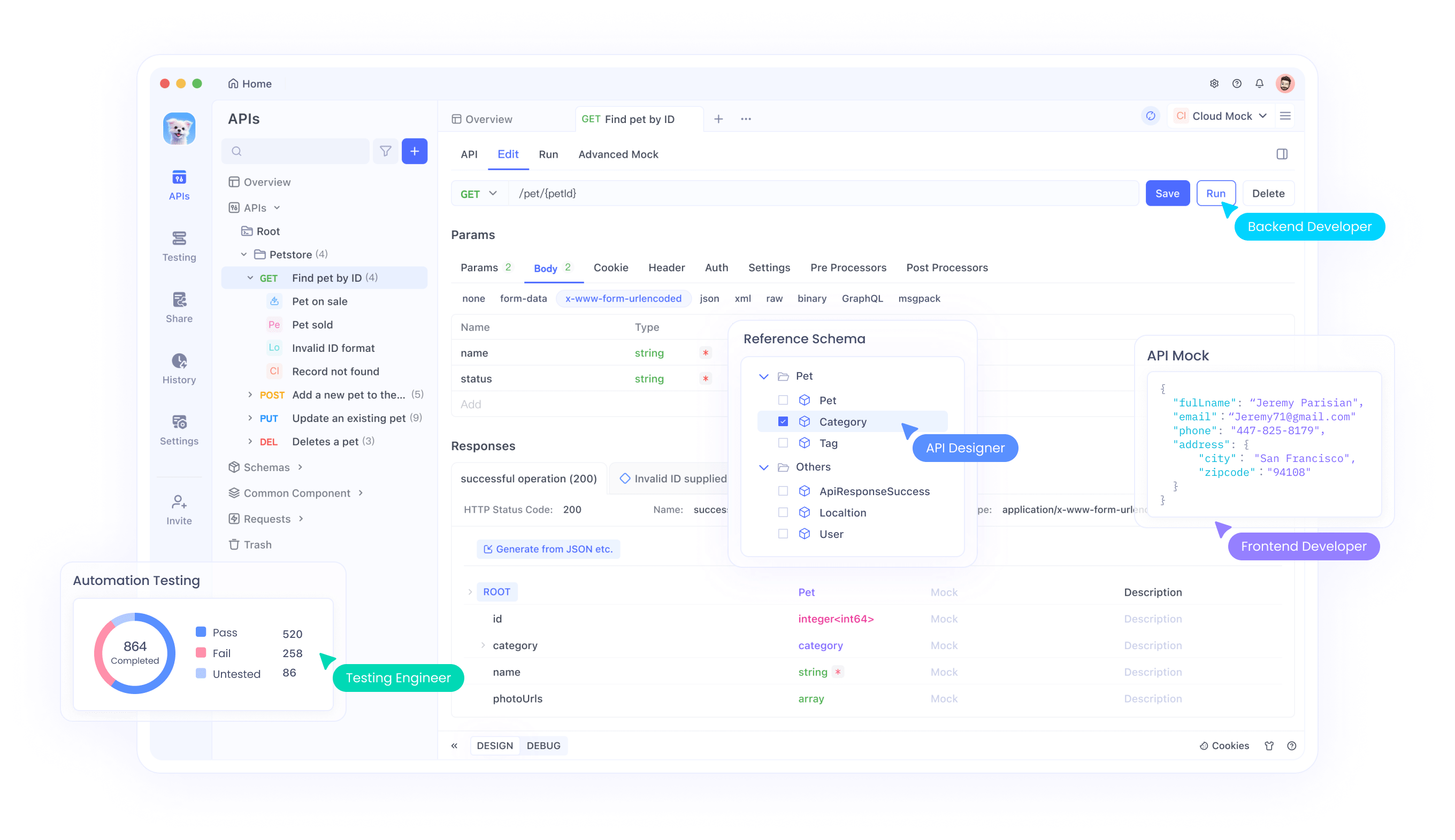
Um Apidog mit der Perplexity Search API zu verwenden, importieren Sie die API-Spezifikation in die Apidog-Oberfläche. Erstellen Sie Testfälle für verschiedene Abfragen und validieren Sie die Antworten anhand erwarteter Strukturen. Die KI-Funktionen von Apidog automatisieren die Dokumentation und das Testen, wodurch der manuelle Aufwand reduziert wird.
Mocken Sie außerdem die API für die Offline-Entwicklung, um sicherzustellen, dass Ihre App Grenzfälle behandelt. Erstellen Sie Referenzen und Berichte, um die Qualität zu gewährleisten.
Folglich beschleunigt Apidog das Debugging und macht es für robuste Integrationen unerlässlich.
Best Practices zur Bewertung und Optimierung der Leistung
Bewerten Sie die Perplexity Search API mithilfe des Open-Source-Frameworks search_evals und vergleichen Sie sie mit Suiten wie FRAMES und HLE. Dieses Tool bewertet Latenz und Qualität neutral.
Implementieren Sie hybride Abrufung in Ihren Pipelines für ausgewogene Ergebnisse. Aktualisieren Sie regelmäßig die Parsing-Logik, um sich an Webänderungen anzupassen.
Integrieren Sie außerdem Benutzerfeedback, um Abfragen zu verfeinern, was dem Ansatz von Perplexity entspricht.
Vermeiden Sie jedoch eine übermäßige Abhängigkeit von Standardeinstellungen; passen Sie Parameter für Ihre Domäne an.
Daher gewährleisten diese Praktiken optimale Leistung und Zuverlässigkeit.
Häufige Herausforderungen und Tipps zur Fehlerbehebung
Benutzer stoßen auf Authentifizierungsfehler; überprüfen Sie die Umgebungsvariablen. Bei Latenzproblemen optimieren Sie die Abfragekomplexität.
Behandeln Sie außerdem Ratenbegrenzungen mit exponentiellem Backoff im Code.
Wenn die Ergebnisse nicht relevant sind, verfeinern Sie Filter oder verwenden Sie erweiterte Modelle.
Dadurch sorgt eine proaktive Fehlerbehebung für einen reibungslosen Betrieb.
Zukünftige Entwicklungen und Community-Ressourcen
Perplexity verbessert die API kontinuierlich mit forschungsgetriebenen Updates. Treten Sie der Entwickler-Community bei, um Einblicke und Veranstaltungen zu erhalten.
Erkunden Sie außerdem Open-Source-Beiträge, um auf dem Laufenden zu bleiben.
Fazit
Die Perplexity Search API ermöglicht es Entwicklern, erweiterte Suche in KI-Anwendungen zu nutzen. Indem Sie diesem Leitfaden folgen, implementieren Sie sie effektiv und nutzen Tools wie Apidog für Effizienz. Experimentieren Sie weiter, um ihr volles Potenzial auszuschöpfen.