
Willkommen! Wenn Sie sich jemals gefragt haben, wie Sie modernste KI-Tools für Web Scraping und Inhaltsanalyse nutzen können, dann sind Sie hier genau richtig. Heute werden wir tief in ein aufregendes Projekt eintauchen, das OpenAI SWARM, Streamlit und Multi-Agenten-Systeme kombiniert, um Web Scraping intelligenter und die Inhaltsanalyse aufschlussreicher zu machen. Wir werden auch untersuchen, wie Apidog API-Tests vereinfachen und als günstigere Alternative für Ihre API-Anforderungen dienen kann.
Lassen Sie uns nun mit dem Aufbau eines voll funktionsfähigen Web Scraping- und Inhaltsanalysesystems beginnen!
1. Was ist OpenAI SWARM?
OpenAI SWARM ist ein neuer Ansatz zur Nutzung von KI und Multi-Agenten-Systemen zur Automatisierung verschiedener Aufgaben, einschließlich Web Scraping und Inhaltsanalyse. Im Kern konzentriert sich SWARM auf die Verwendung mehrerer Agenten, die unabhängig voneinander arbeiten oder bei bestimmten Aufgaben zusammenarbeiten können, um ein gemeinsames Ziel zu erreichen.

Wie SWARM funktioniert
Stellen Sie sich vor, Sie möchten mehrere Websites scrapen, um Daten für die Analyse zu sammeln. Die Verwendung eines einzelnen Scraper-Bots kann funktionieren, ist aber anfällig für Engpässe, Fehler oder sogar das Blockieren durch die Website. Mit SWARM können Sie jedoch mehrere Agenten einsetzen, um verschiedene Aspekte der Aufgabe zu bewältigen – einige Agenten konzentrieren sich auf die Datenextraktion, andere auf die Datenbereinigung und wieder andere auf die Transformation der Daten für die Analyse. Diese Agenten können miteinander kommunizieren und so eine effiziente Abwicklung der Aufgaben gewährleisten.
Durch die Kombination von OpenAIs leistungsstarken Sprachmodellen und SWARM-Methoden können Sie intelligente, adaptive Systeme aufbauen, die das menschliche Problemlösen nachahmen. Wir werden in diesem Tutorial SWARM-Techniken für intelligenteres Web Scraping und Datenverarbeitung verwenden.
2. Einführung in Multi-Agenten-Systeme
Ein Multi-Agenten-System (MAS) ist eine Sammlung autonomer Agenten, die in einer gemeinsamen Umgebung interagieren, um komplexe Probleme zu lösen. Die Agenten können Aufgaben parallel ausführen, wodurch MAS ideal für Situationen ist, in denen Daten aus verschiedenen Quellen gesammelt oder verschiedene Verarbeitungsstufen benötigt werden.
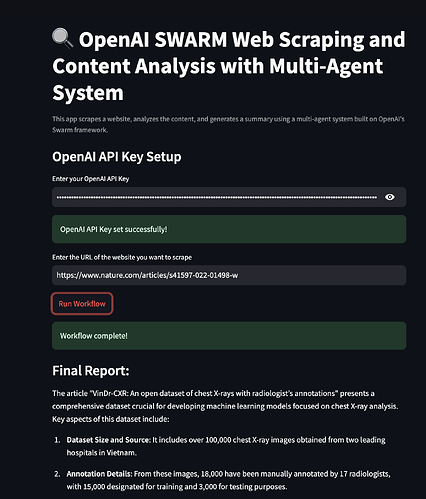
Im Kontext von Web Scraping könnte ein Multi-Agenten-System Agenten für Folgendes umfassen:
- Data Extraction: Crawling verschiedener Webseiten, um relevante Daten zu sammeln.
- Content Parsing: Bereinigen und Organisieren der Daten für die Analyse.
- Data Analysis: Anwenden von Algorithmen, um Erkenntnisse aus den gesammelten Daten zu gewinnen.
- Reporting: Präsentation der Ergebnisse in einem benutzerfreundlichen Format.
Warum Multi-Agenten-Systeme für Web Scraping verwenden?
Multi-Agenten-Systeme sind robust gegenüber Ausfällen und können asynchron arbeiten. Dies bedeutet, dass selbst wenn ein Agent ausfällt oder auf ein Problem stößt, die anderen ihre Aufgaben fortsetzen können. Der SWARM-Ansatz gewährleistet somit höhere Effizienz, Skalierbarkeit und Fehlertoleranz in Web Scraping-Projekten.
3. Streamlit: Ein Überblick
Streamlit ist eine beliebte Open-Source-Python-Bibliothek, mit der Sie ganz einfach benutzerdefinierte Webanwendungen für Datenanalyse-, Machine-Learning- und Automatisierungsprojekte erstellen und freigeben können. Es bietet ein Framework, in dem Sie interaktive UIs ohne Frontend-Erfahrung erstellen können.
Warum Streamlit?
- Benutzerfreundlichkeit: Schreiben Sie Python-Code, und Streamlit wandelt ihn in eine benutzerfreundliche Weboberfläche um.
- Schnelles Prototyping: Ermöglicht das schnelle Testen und Bereitstellen neuer Ideen.
- Integration mit KI-Modellen: Lässt sich nahtlos in Machine-Learning-Bibliotheken und APIs integrieren.
- Anpassung: Flexibel genug, um anspruchsvolle Apps für verschiedene Anwendungsfälle zu erstellen.
In unserem Projekt verwenden wir Streamlit, um Web Scraping-Ergebnisse zu visualisieren, Metriken zur Inhaltsanalyse anzuzeigen und eine interaktive Oberfläche zur Steuerung unseres Multi-Agenten-Systems zu erstellen.
4. Warum Apidog ein Game-Changer ist
Apidog ist eine robuste Alternative zu herkömmlichen API-Entwicklungs- und Testtools. Es unterstützt den gesamten API-Lebenszyklus, vom Design über das Testen bis hin zur Bereitstellung, alles innerhalb einer einheitlichen Plattform.
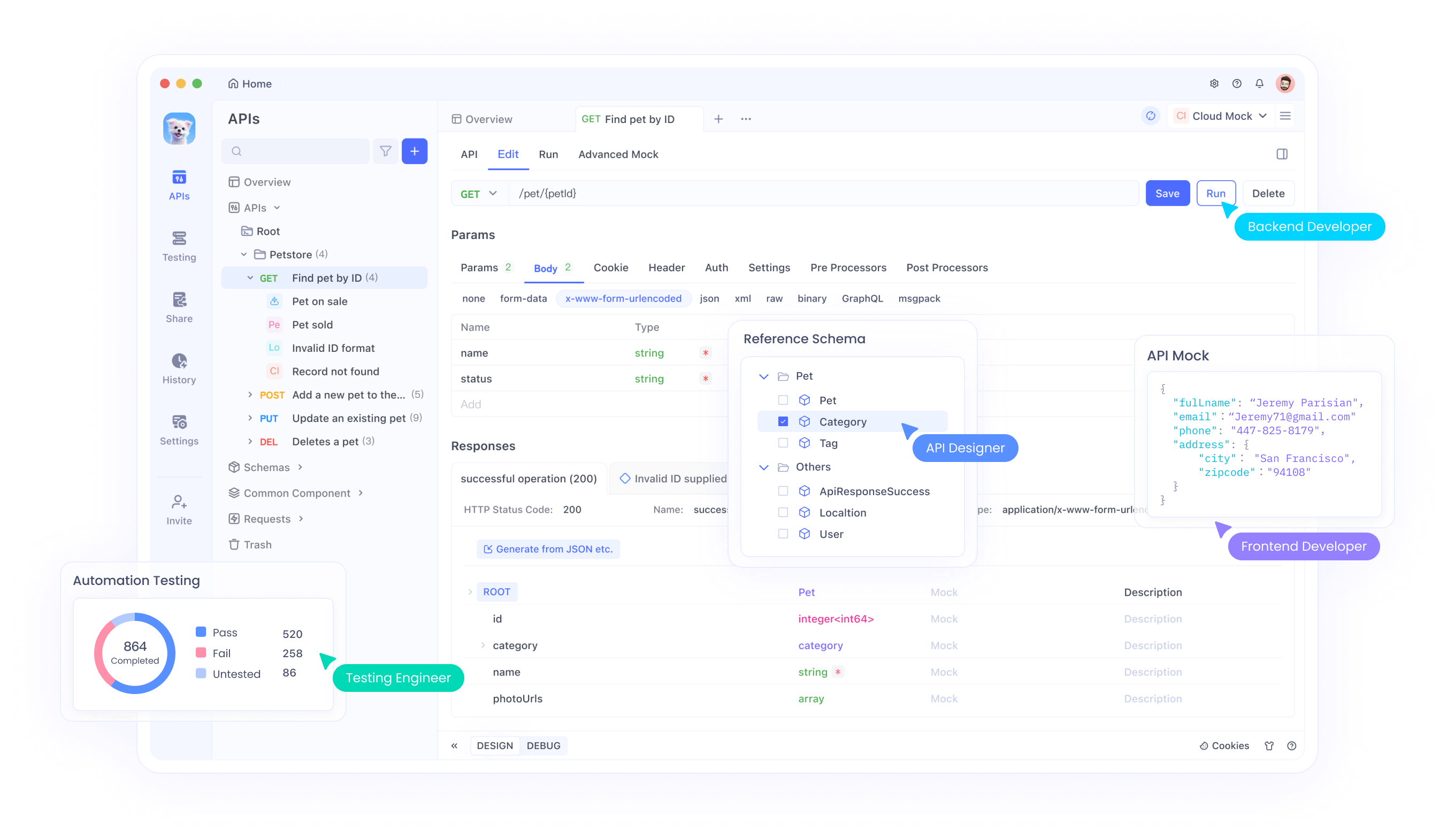
Hauptmerkmale von Apidog:
- Benutzerfreundliche Oberfläche: Einfach zu bedienendes Drag-and-Drop-API-Design.
- Automatisierte Tests: Führen Sie umfassende API-Tests durch, ohne zusätzliche Skripte schreiben zu müssen.
- Integrierte Dokumentation: Generieren Sie automatisch detaillierte API-Dokumentation.
- Günstigere Preispläne: Bietet eine günstigere Option im Vergleich zu Wettbewerbern.
Apidog ist die perfekte Lösung für Projekte, bei denen API-Integration und -Tests unerlässlich sind, und macht es zu einer kostengünstigen und umfassenden Lösung.
Laden Sie Apidog kostenlos herunter, um diese Vorteile aus erster Hand zu erleben.
5. Einrichten Ihrer Entwicklungsumgebung
Bevor wir uns in den Code stürzen, stellen wir sicher, dass unsere Umgebung bereit ist. Sie benötigen:
- Python 3.7+
- Streamlit: Installieren Sie mit
pip install streamlit - BeautifulSoup für Web Scraping: Installieren Sie mit
pip install beautifulsoup4 - Requests: Installieren Sie mit
pip install requests - Apidog: Für API-Tests können Sie es von Apidogs offizieller Website herunterladen
Stellen Sie sicher, dass Sie alles oben Genannte installiert haben. Konfigurieren wir nun die Umgebung.
6. Aufbau eines Multi-Agenten-Systems für Web Scraping
Lassen Sie uns ein Multi-Agenten-System für Web Scraping mit OpenAI SWARM und Python-Bibliotheken erstellen. Das Ziel hier ist es, mehrere Agenten zu erstellen, um Aufgaben wie das Crawlen, Parsen und Analysieren von Daten von verschiedenen Websites auszuführen.
Schritt 1: Definieren der Agenten
Wir erstellen Agenten für verschiedene Aufgaben:
- Crawler Agent: Sammelt rohes HTML von Webseiten.
- Parser Agent: Extrahiert aussagekräftige Informationen.
- Analyzer Agent: Verarbeitet die Daten für Erkenntnisse.
So können Sie einen einfachen CrawlerAgent in Python definieren:
import requests
from bs4 import BeautifulSoup
class CrawlerAgent:
def __init__(self, url):
self.url = url
def fetch_content(self):
try:
response = requests.get(self.url)
if response.status_code == 200:
return response.text
else:
print(f"Failed to fetch content from {self.url}")
except Exception as e:
print(f"Error: {str(e)}")
return None
crawler = CrawlerAgent("https://example.com")
html_content = crawler.fetch_content()
Schritt 2: Hinzufügen eines Parser-Agenten
Der ParserAgent bereinigt und strukturiert das rohe HTML:
class ParserAgent:
def __init__(self, html_content):
self.html_content = html_content
def parse(self):
soup = BeautifulSoup(self.html_content, 'html.parser')
parsed_data = soup.find_all('p') # Example: Extracting all paragraphs
return [p.get_text() for p in parsed_data]
parser = ParserAgent(html_content)
parsed_data = parser.parse()
Schritt 3: Hinzufügen eines Analyzer-Agenten
Dieser Agent wendet Techniken der natürlichen Sprachverarbeitung (NLP) an, um den Inhalt zu analysieren.
from collections import Counter
class AnalyzerAgent:
def __init__(self, text_data):
self.text_data = text_data
def analyze(self):
word_count = Counter(" ".join(self.text_data).split())
return word_count.most_common(10) # Example: Top 10 most common words
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
print(analysis_result)
7. Inhaltsanalyse mit SWARM und Streamlit
Nachdem unsere Agenten nun zusammenarbeiten, visualisieren wir die Ergebnisse mit Streamlit.
Schritt 1: Erstellen einer Streamlit-App
Beginnen Sie mit dem Import von Streamlit und dem Einrichten der grundlegenden App-Struktur:
import streamlit as st
st.title("Web Scraping und Inhaltsanalyse mit Multi-Agenten-Systemen")
st.write("Verwendung von OpenAI SWARM und Streamlit für intelligentere Datenextraktion.")
Schritt 2: Integrieren von Agenten
Wir integrieren unsere Agenten in die Streamlit-App, sodass Benutzer eine URL eingeben und die Scraping- und Analyseergebnisse sehen können.
url = st.text_input("Geben Sie eine URL zum Scrapen ein:")
if st.button("Scrapen und Analysieren"):
if url:
crawler = CrawlerAgent(url)
html_content = crawler.fetch_content()
if html_content:
parser = ParserAgent(html_content)
parsed_data = parser.parse()
analyzer = AnalyzerAgent(parsed_data)
analysis_result = analyzer.analyze()
st.subheader("Top 10 der am häufigsten vorkommenden Wörter")
st.write(analysis_result)
else:
st.error("Fehler beim Abrufen des Inhalts. Bitte versuchen Sie es mit einer anderen URL.")
else:
st.warning("Bitte geben Sie eine gültige URL ein.")
Schritt 3: Bereitstellen der App
Sie können die App mit dem Befehl bereitstellen:
streamlit run your_script_name.py

8. Testen von APIs mit Apidog
Sehen wir uns nun an, wie Apidog beim Testen von APIs in unserer Web Scraping-Anwendung helfen kann.
Schritt 1: Einrichten von Apidog
Laden Sie Apidog von Apidogs offizieller Website herunter und installieren Sie es. Befolgen Sie die Installationsanleitung, um die Umgebung einzurichten.
Schritt 2: Erstellen von API-Anfragen
Sie können Ihre API-Anfragen direkt in Apidog erstellen und testen. Es unterstützt verschiedene Anfragetypen wie GET, POST, PUT und DELETE, wodurch es vielseitig für jedes Web Scraping-Szenario einsetzbar ist.
Schritt 3: Automatisieren von API-Tests
Mit Apidog automatisieren Sie Testskripte, um die Antwort Ihres Multi-Agenten-Systems beim Verbinden mit externen Diensten zu validieren. Dies stellt sicher, dass Ihr System im Laufe der Zeit robust und konsistent bleibt.
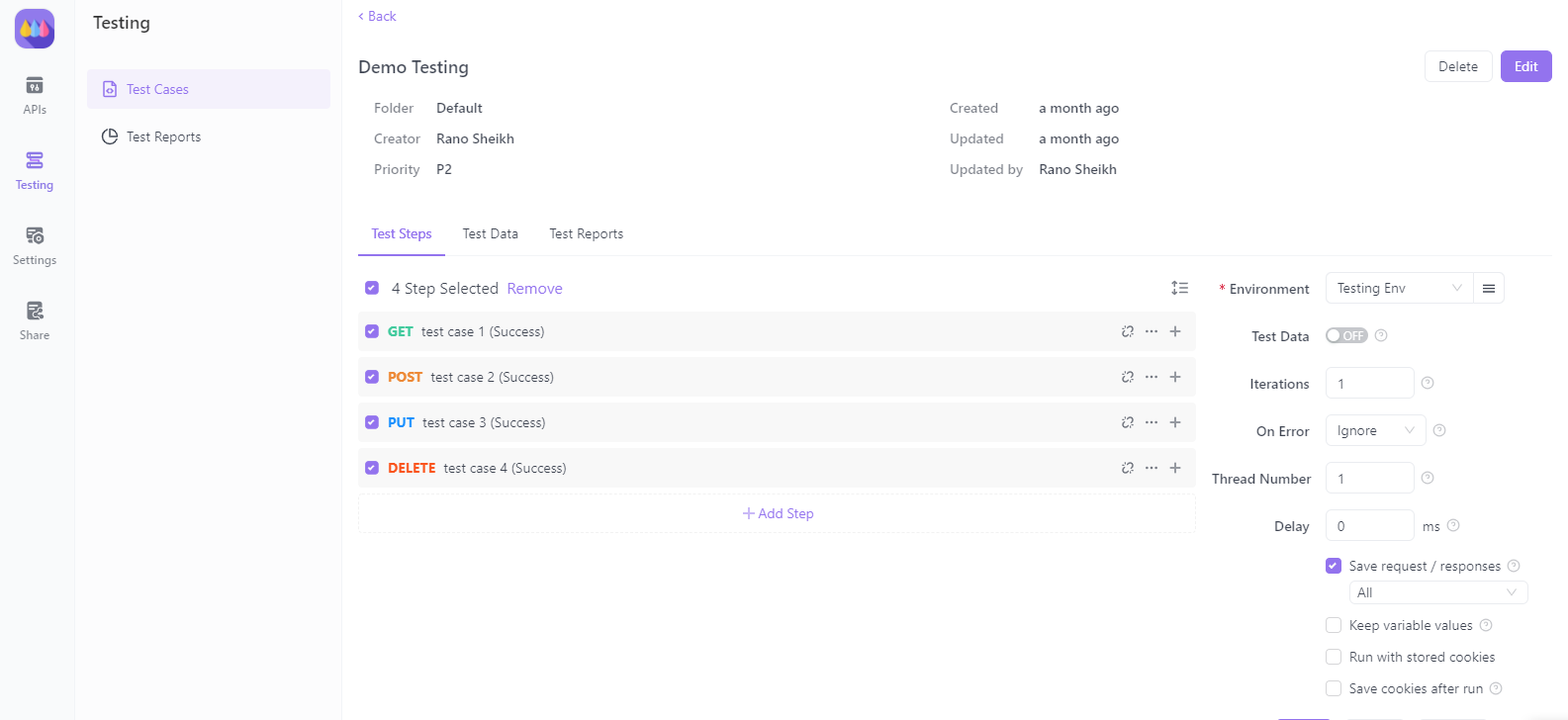
9. Bereitstellen Ihrer Streamlit-Anwendung
Sobald Ihre Anwendung fertig ist, stellen Sie sie für den öffentlichen Zugriff bereit. Streamlit macht dies mit seinem Streamlit Sharing-Dienst einfach.
- Hosten Sie Ihren Code auf GitHub.
- Navigieren Sie zu Streamlit Sharing und verbinden Sie Ihr GitHub-Repository.
- Stellen Sie Ihre App mit einem einzigen Klick bereit.
10. Fazit
Herzlichen Glückwunsch! Sie haben gelernt, wie Sie mit OpenAI SWARM, Streamlit und Multi-Agenten-Systemen ein leistungsstarkes Web Scraping- und Inhaltsanalysesystem erstellen. Wir haben untersucht, wie SWARM-Techniken das Scraping intelligenter und die Inhaltsanalyse genauer machen können. Durch die Integration von Apidog haben Sie auch Einblicke in API-Tests und -Validierung gewonnen, um die Zuverlässigkeit Ihres Systems sicherzustellen.
Laden Sie jetzt Apidog kostenlos herunter, um Ihre Projekte mit leistungsstarken API-Testfunktionen weiter zu verbessern. Apidog zeichnet sich als günstigere und effizientere Alternative zu anderen Lösungen aus und bietet Entwicklern eine nahtlose Erfahrung.
Mit diesem Tutorial sind Sie bereit, komplexe Datenscraping- und Analyseaufgaben effektiver zu bewältigen. Viel Glück und viel Spaß beim Codieren!


