
Große Sprachmodelle (LLMs) lokal auszuführen, war früher die Domäne von Hardcore-CLI-Nutzern und Systemtüftlern. Aber das ändert sich schnell. Ollama, bekannt für seine einfache Befehlszeilenschnittstelle zum Ausführen von Open-Source-LLMs auf lokalen Maschinen, hat gerade native Desktop-Apps für macOS und Windows veröffentlicht.
Und es sind nicht nur einfache Wrapper. Diese Apps bieten leistungsstarke Funktionen, die das Chatten mit Modellen, das Analysieren von Dokumenten, das Schreiben von Dokumentationen und sogar die Arbeit mit Bildern für Entwickler drastisch erleichtern.
In diesem Artikel werden wir untersuchen, wie die neue Desktop-Erfahrung den Entwickler-Workflow verbessert, welche Funktionen hervorstechen und wo diese Tools im täglichen Programmierleben tatsächlich glänzen.
Warum lokale LLMs immer noch wichtig sind
Während Cloud-basierte Tools wie ChatGPT, Claude und Gemini die Schlagzeilen dominieren, gibt es eine wachsende Bewegung hin zur Local-First-KI-Entwicklung. Entwickler wünschen sich Tools, die:
- Privat sind – Ihr Code und Ihre Dokumente bleiben auf Ihrem Rechner.
- Anpassbar sind – Sie wählen die Modelle, Speichergrenzen und Hardware.
- Offline-freundlich sind – Keine Abhängigkeit von externen APIs oder Verfügbarkeit.
- Schnell sind – Keine Netzwerklatenz oder Server-Engpässe.
Ollama greift diesen Trend direkt auf und ermöglicht es Ihnen, Modelle wie LLaMA, Mistral, Gemma, Codellama, Mixtral und andere nativ auf Ihrem Rechner auszuführen – jetzt mit einer viel reibungsloseren Erfahrung.
Schritt 1: Ollama für den Desktop herunterladen
Gehen Sie zu ollama.com und laden Sie die neueste Version für Ihr System herunter:
- macOS (Apple Silicon oder Intel)
- Windows 10/11 (x64)
Installieren Sie es wie eine normale Desktop-App. Für den Einstieg ist keine Befehlszeilen-Einrichtung erforderlich.
Schritt 2: Starten und ein Modell auswählen
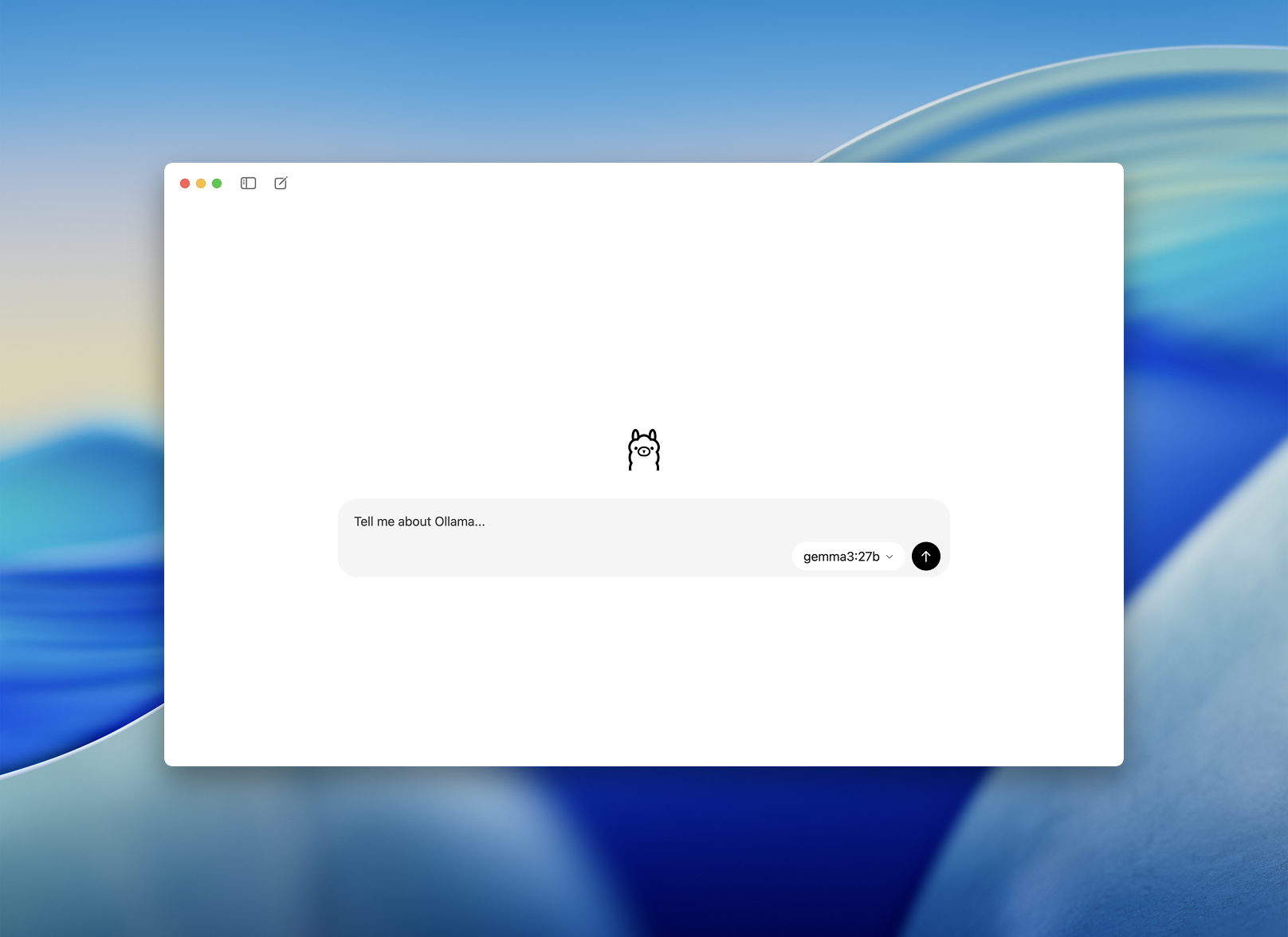
Nach der Installation öffnen Sie die Ollama Desktop-App. Die Oberfläche ist übersichtlich und sieht aus wie ein einfaches Chat-Fenster.
Sie werden aufgefordert, ein Modell auszuwählen, das heruntergeladen und ausgeführt werden soll. Einige Optionen sind:
llama3– Allzweck-Assistentcodellama– hervorragend für Codegenerierung und Refactoringmistral– schnell, klein und präzisegemma– von Google unterstütztes, Open-Weight-Modell
Wählen Sie eines aus, und die App lädt es automatisch herunter und lädt es.
Ein reibungsloserer Einstieg für Entwickler – Eine einfachere Möglichkeit, mit Modellen zu chatten
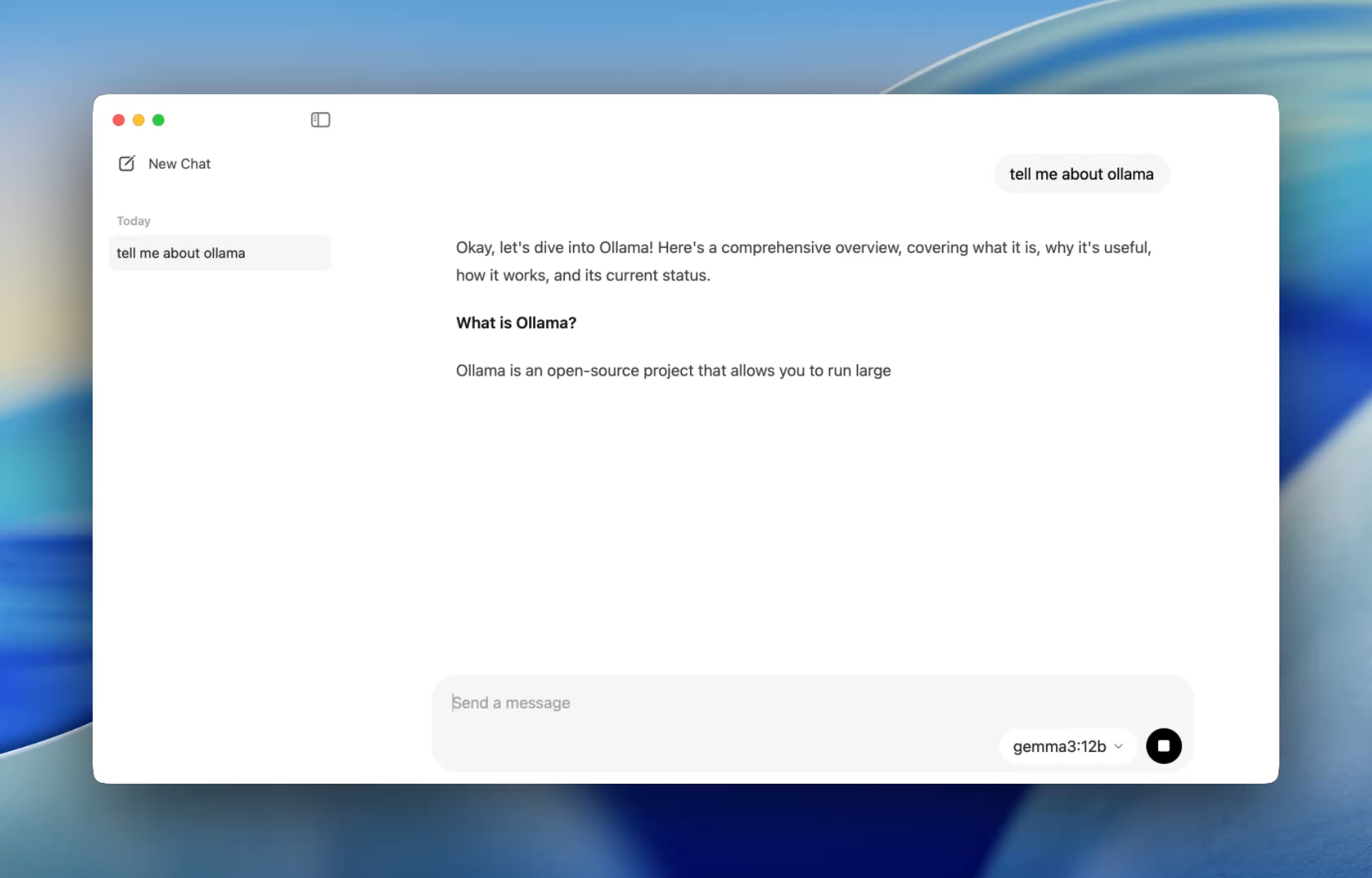
Bisher bedeutete die Verwendung von Ollama, ein Terminal zu starten und ollama run-Befehle auszugeben, um eine Modellsitzung zu starten. Jetzt öffnet sich die Desktop-App wie jede native Anwendung und bietet eine einfache und übersichtliche Chat-Oberfläche.
Sie können jetzt mit Modellen sprechen, genau wie in ChatGPT – aber vollständig offline. Das ist perfekt für:
- Code-Review-Unterstützung
- Testgenerierung
- Refactoring-Tipps
- Das Erlernen neuer APIs oder Sprachen
Die App bietet Ihnen sofortigen Zugriff auf lokale Modelle wie codellama oder mistral, ohne dass über eine einfache Installation hinausgehende Einrichtung erforderlich ist.
Und für Entwickler, die Anpassung lieben, funktioniert die CLI immer noch im Hintergrund und ermöglicht es Ihnen, bei Bedarf Kontextlänge, Systemprompts und Modellversionen über das Terminal umzuschalten.
Ziehen. Ablegen. Fragen stellen.
Mit Dateien chatten
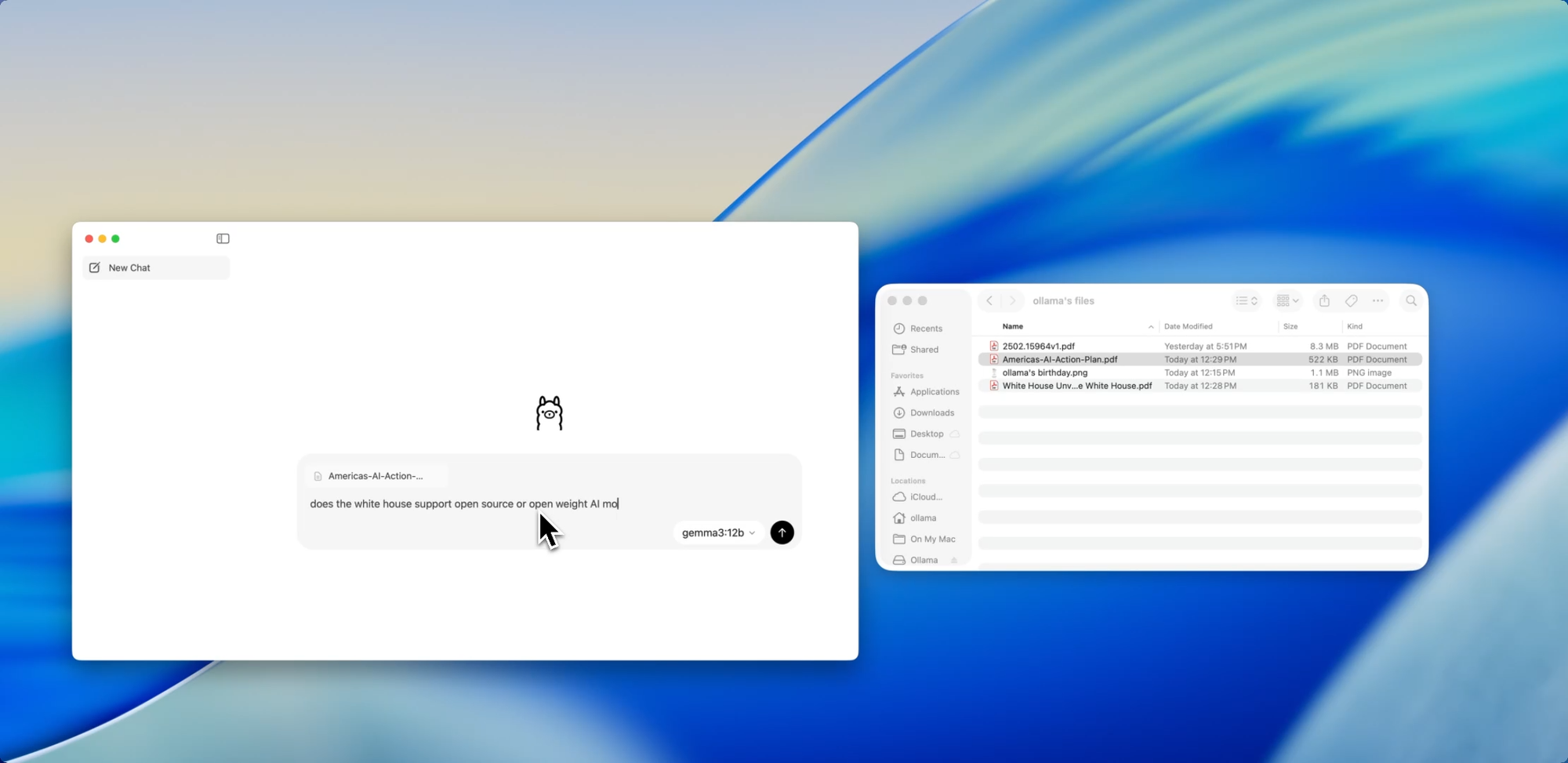
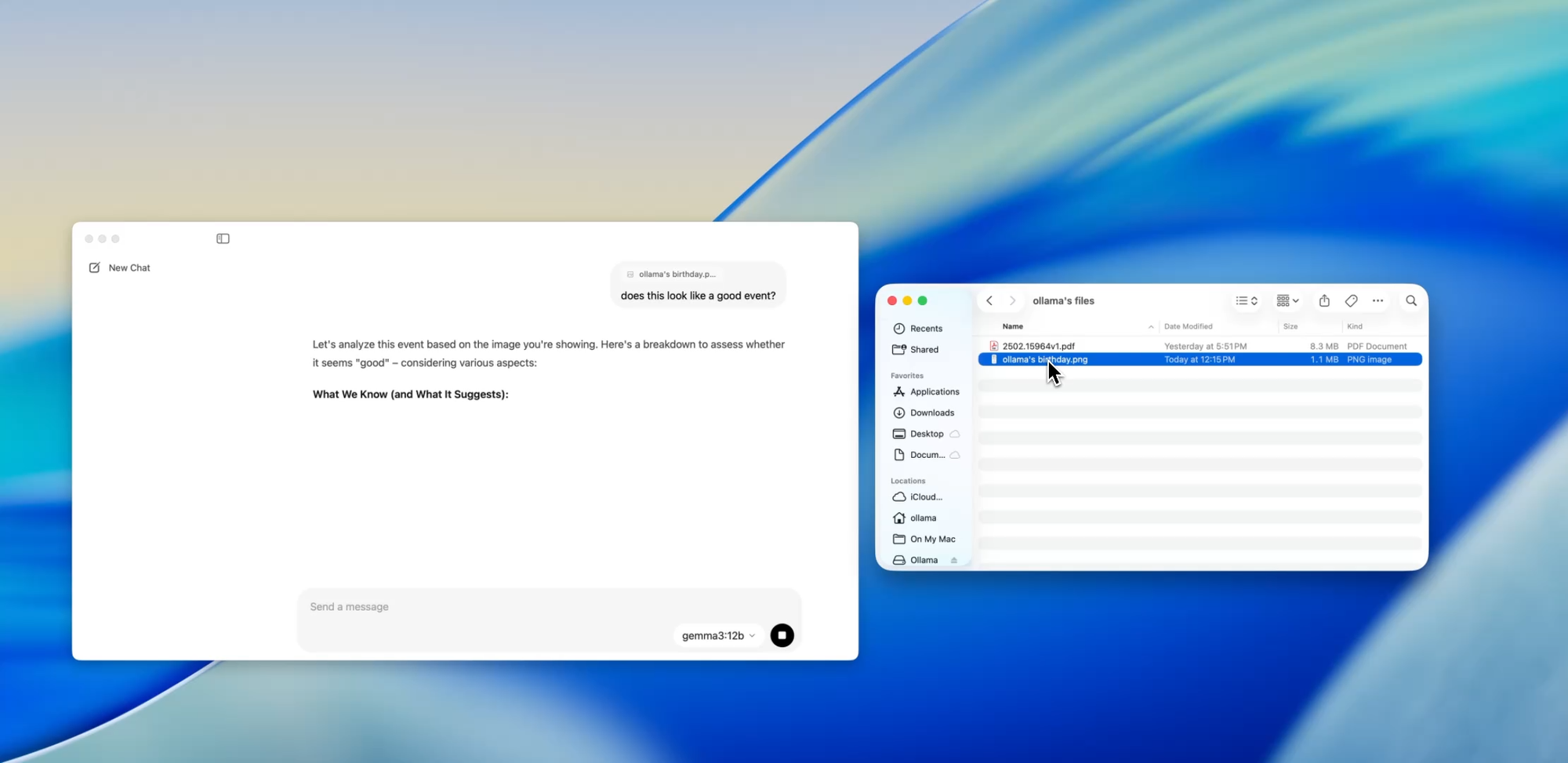
Eine der entwicklerfreundlichsten Funktionen in der neuen App ist die Dateiaufnahme. Ziehen Sie einfach eine Datei in das Chat-Fenster – egal ob es sich um eine .pdf, .md oder .txt handelt – und das Modell liest deren Inhalt.
Müssen Sie ein 60-seitiges Design-Dokument verstehen? Möchten Sie TODOs aus einer unordentlichen README extrahieren? Oder eine Produktbeschreibung eines Kunden zusammenfassen? Ziehen Sie es hinein und stellen Sie Fragen in natürlicher Sprache wie:
- „Was sind die Hauptmerkmale, die in diesem Dokument besprochen werden?“
- „Fassen Sie dies in einem Absatz zusammen.“
- „Gibt es fehlende Abschnitte oder Inkonsistenzen?“
Diese Funktion kann die Zeit, die für das Scannen von Dokumentationen, das Überprüfen von Spezifikationen oder das Einarbeiten in neue Projekte aufgewendet wird, drastisch reduzieren.
Über Text hinausgehen
Multimodale Unterstützung
Ausgewählte Modelle innerhalb von Ollama (wie z.B. Llava-basierte) unterstützen jetzt Bildeingabe. Das bedeutet, Sie können ein Bild hochladen, und das Modell wird es interpretieren und darauf reagieren.
Einige Anwendungsfälle sind:
- Diagramme oder Tabellen aus einem Screenshot lesen
- UI-Mockups beschreiben
- Gescannte handschriftliche Notizen überprüfen
- Einfache Infografiken analysieren
Obwohl dies im Vergleich zu Tools wie GPT-4 Vision noch im Frühstadium ist, ist die multimodale Unterstützung, die in einer lokal-ersten App integriert ist, ein großer Schritt für Entwickler, die Multi-Input-Systeme oder KI-Schnittstellen testen.
Private, lokale Dokumente – auf Ihren Befehl
Dokumentationserstellung
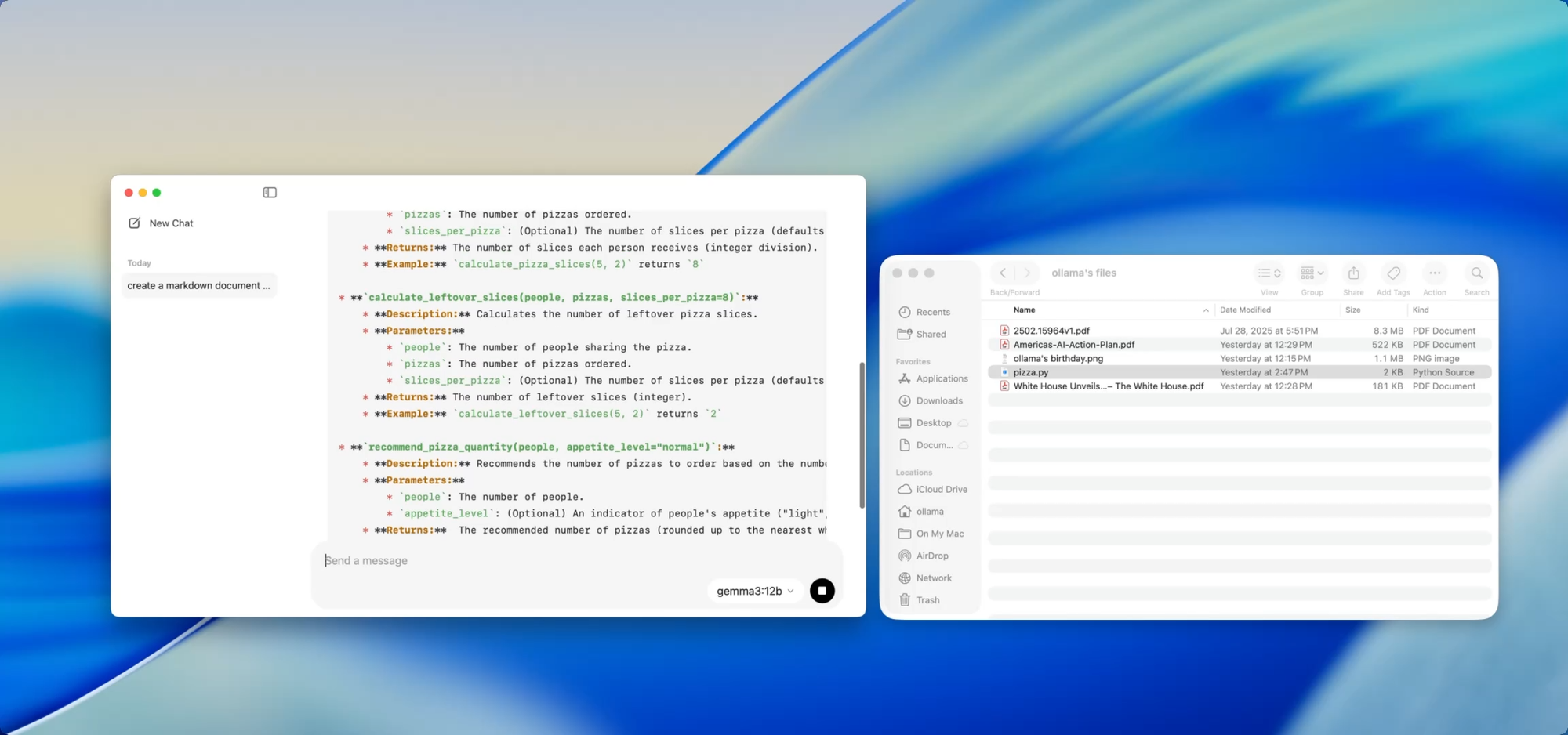
Wenn Sie eine wachsende Codebasis pflegen, kennen Sie den Schmerz der Dokumentationsdrift. Mit Ollama können Sie lokale Modelle verwenden, um Dokumentationen zu generieren oder zu aktualisieren, ohne jemals sensible Codes in die Cloud zu übertragen.
Ziehen Sie einfach eine Datei – zum Beispiel utils.py – in die App und fragen Sie:
- „Schreiben Sie Docstrings für diese Funktionen.“
- „Erstellen Sie eine Markdown-Übersicht darüber, was diese Datei tut.“
- „Welche Abhängigkeiten verwendet dieses Modul?“
Dies wird noch leistungsfähiger, wenn es mit Tools wie [Deepdocs] kombiniert wird, die Dokumentations-Workflows mithilfe von KI automatisieren. Sie können die README- oder Schema-Dateien Ihres Projekts vorladen und dann Folgefragen stellen oder Änderungslogs, Migrationshinweise oder Update-Anleitungen generieren – alles lokal.
Leistungsoptimierung unter der Haube
Mit dieser neuen Version hat Ollama auch die Leistung auf breiter Front verbessert:
- Die GPU-Beschleunigung ist besser für Apple Silicon und moderne Nvidia/AMD-Karten optimiert.
- Die Kontextlänge ist jetzt mit Einstellungen wie
num_ctx=8192konfigurierbar, sodass Sie längere Eingaben verarbeiten können. - Der Netzwerkmodus ermöglicht es Ollama, als lokaler API-Server zu laufen, den Sie von anderen Apps oder Geräten in Ihrem LAN aufrufen können.
- Sie können jetzt den Speicherort für heruntergeladene Modelle ändern – perfekt, wenn Sie von einem externen Laufwerk arbeiten oder Modelle pro Projekt isolieren möchten.
Diese Upgrades machen die App flexibel für alles von lokalen Agenten über Entwicklungstools bis hin zu persönlichen Forschungsassistenten.
CLI und GUI: Das Beste aus beiden Welten
Das Beste daran? Die neue Desktop-App ersetzt das Terminal nicht – sie ergänzt es.
Sie können immer noch:
ollama pull codellama
ollama run codellama
Oder den Modellserver freigeben:
ollama serve --host 0.0.0.0
Wenn Sie also eine benutzerdefinierte KI-Schnittstelle, einen Agenten oder ein Plugin erstellen, das auf einem lokalen LLM basiert, können Sie jetzt auf der Ollama-API aufbauen *und* die GUI für direkte Interaktion oder Tests verwenden.
Ollamas API lokal mit Apidog testen
Möchten Sie Ollama in Ihre KI-App integrieren oder seine lokalen API-Endpunkte testen? Sie können Ollamas REST-API starten mit:
bash tollama serve
Verwenden Sie dann Apidog, um Ihre lokalen LLM-Endpunkte zu testen, zu debuggen und zu dokumentieren.

Warum Apidog mit Ollama verwenden:
- Visuelle Oberfläche zum Senden von POST-Anfragen an Ihren lokalen
http://localhost:11434Server - Unterstützt KI-gestützte Anfragengenerierung und Antwortvalidierung
- Perfekt für selbst gehostete KI-Apps, Agenten-Frameworks oder interne Tools
- Arbeitet nahtlos mit lokalen LLM-Workflows und benutzerdefinierten Modellservern zusammen
Entwickler-Anwendungsfälle, die tatsächlich funktionieren
Hier glänzt die neue Ollama-App in realen Entwickler-Workflows:
| Anwendungsfall | Wie Ollama hilft |
|---|---|
| Code-Review-Assistent | Führen Sie codellama lokal für Refactoring-Feedback aus |
| Dokumentationsaktualisierungen | Bitten Sie Modelle, Dokumentdateien neu zu schreiben, zusammenzufassen oder zu korrigieren |
| Lokaler Entwickler-Chatbot | In Ihre App als kontextsensitiver Assistent einbetten |
| Offline-Recherchetool | PDFs oder Whitepapers laden und Schlüsselfragen stellen |
| Persönlicher LLM-Spielplatz | Experimentieren Sie mit Prompt Engineering & Feinabstimmung |
Für Teams, die sich um Datenschutz oder Modellhalluzinationen sorgen, bieten lokale LLM-Workflows eine zunehmend überzeugende Alternative.
Abschließende Gedanken
Die Desktop-Version von Ollama lässt lokale LLMs weniger wie ein hackiges Wissenschaftsexperiment und mehr wie ein ausgefeiltes Entwicklertool erscheinen.
Mit Unterstützung für Dateiinteraktion, multimodale Eingaben, Dokumentenerstellung und native Leistung ist es eine ernstzunehmende Option für Entwickler, denen Geschwindigkeit, Flexibilität und Kontrolle wichtig sind.
Keine Cloud-API-Schlüssel. Keine Hintergrundverfolgung. Keine Abrechnung pro Token. Nur schnelle, lokale Inferenz mit der Wahl des Open-Source-Modells, das Ihren Anforderungen entspricht.
Wenn Sie schon immer neugierig waren, LLMs auf Ihrem Rechner auszuführen, oder wenn Sie Ollama bereits nutzen und eine reibungslosere Erfahrung wünschen, ist jetzt die Zeit, es erneut zu versuchen.