
Ollama verbessert lokale KI-Fähigkeiten mit seiner neuen Web-Such-API und dem MCP-Server. Entwickler greifen nun auf Echtzeitinformationen zu, um die Modellleistung zu steigern. Darüber hinaus optimiert dieses Update die Tool-Integrationen über verschiedene Clients hinweg.
Ollama ist eine robuste Plattform zum lokalen Ausführen großer Sprachmodelle. Ingenieure nutzen sie, um Modelle bereitzustellen, ohne auf Cloud-Dienste angewiesen zu sein. Die Hinzufügung der Web-Such-API erweitert jedoch ihren Anwendungsbereich. Diese API ermöglicht es Modellen, das Internet direkt abzufragen. Folglich können Anwendungen aktuelle Ereignisse und dynamische Daten effektiver verarbeiten.

Der MCP-Server ergänzt dies, indem er ein standardisiertes Protokoll für den Kontextaustausch bereitstellt. Entwickler verbinden Modelle mühelos mit externen Tools. Zum Beispiel integriert sich der MCP-Server mit Clients wie Cline, Codex und Goose. Diese Einrichtung ermöglicht komplexe Workflows, bei denen Modelle in Echtzeit mit Web-Suchergebnissen interagieren.
Zu den technischen Details: Ollamas Web-Such-API arbeitet über REST-Endpunkte. Benutzer senden POST-Anfragen an https://ollama.com/api/web_search mit einem Abfrageparameter. Das System gibt relevante Ergebnisse zurück, standardmäßig auf maximal 10 begrenzt. Zusätzlich ruft die Web-Fetch-API unter https://ollama.com/api/web_fetch Inhalte von bestimmten URLs ab. Beide erfordern einen API-Schlüssel von einem Ollama-Konto.
Ollama gewährleistet plattformübergreifende Zugänglichkeit. Unter macOS installieren Benutzer über Homebrew. Windows-Benutzer laden die ausführbare Datei direkt herunter. Linux unterstützt einfache Paketmanager. Unabhängig von der Plattform integriert sich die API einheitlich.
Was Entwickler über Ollama wissen müssen
Ollama ermöglicht lokale Inferenz für Modelle wie Llama und Qwen. Es lädt quantisierte Modelle effizient herunter. Benutzer ziehen Modelle mit Befehlen wie ollama pull qwen3:4b. Dieser Prozess optimiert für Hardware wie NVIDIA GPUs oder Apple Silicon.

Darüber hinaus unterstützt Ollama multimodale Aufgaben. Zum Beispiel verarbeitet es Bilder und Videos neben Text. Die Plattform entwickelt sich schnell weiter, mit Updates, die die Planung und Kontextverarbeitung verbessern.
Entwickler schätzen Ollamas Open-Source-Charakter. Sie passen Modelle ohne Anbieterbindung an. Bei statischem Wissen treten jedoch Einschränkungen auf. Modelle, die mit vergangenen Daten trainiert wurden, tun sich schwer mit aktuellen Informationen. Hier greift die Web-Such-API ein.
Ollamas API schließt diese Lücke. Sie erweitert Antworten mit frischen Daten. Dadurch nehmen Halluzinationen erheblich ab. Ingenieure entwickeln zuverlässige Anwendungen für Forschung oder Automatisierung.
Der MCP-Server standardisiert Interaktionen. MCP, oder Model Context Protocol, erleichtert den Datenaustausch zwischen Modellen und Systemen. Ollama implementiert den MCP-Server in Python, was eine nahtlose Tool-Nutzung ermöglicht.
Zum Beispiel ermöglicht der MCP-Server Dateioperationen, Berechnungen und Webzugriff. Entwickler konfigurieren ihn für lokale LLMs, wodurch die Funktionen über die grundlegende Inferenz hinaus erweitert werden.
Ollamas Web-Such-API im Detail
Ollamas Web-Such-API liefert strukturierte Ergebnisse. Benutzer geben Abfragen und optionale max_results an. Die Antwort enthält Snippets, URLs und Metadaten. Dieses Format hilft beim Parsen für Agenten.
Zur Integration verwenden Entwickler Python-Bibliotheken. Installieren Sie mit pip install ollama. Rufen Sie dann ollama.web_search(query="example") auf. Die Funktion handhabt die Authentifizierung über Umgebungsvariablen.
Ähnlich nutzen JavaScript-Benutzer ollama-js. Importieren Sie das Modul und rufen Sie Ollama().webSearch({query: "example"}) auf. Beispiele in Repositories zeigen Fehlerbehandlung und Wiederholungsversuche.
cURL bietet eine Low-Level-Option. Erstellen Sie Anfragen mit Headern für die Autorisierung. Dieser Ansatz eignet sich für Skripte oder Tests.
Apidog verbessert diesen Prozess jedoch. Als API-Management-Tool visualisiert Apidog Endpunkte und Parameter. Es generiert Code-Snippets für Ollamas API und beschleunigt die Entwicklung.
Die API unterstützt lange Kontexte. Ergebnisse können Tausende von Tokens umfassen. Daher funktionieren Modelle mit erweiterten Fenstern am besten. Ollama empfiehlt mindestens 32.000 Tokens.
Darüber hinaus ergänzt der Fetch-Endpunkt die Suche. Er extrahiert Inhalte aus URLs, wodurch direkte Browseranforderungen umgangen werden. Kombinieren Sie beides für umfassende Agenten.
Sicherheit bleibt von größter Bedeutung. Ollama erfordert API-Schlüssel, um unbefugten Zugriff zu verhindern. Benutzer generieren Schlüssel unter https://ollama.com/settings/keys.
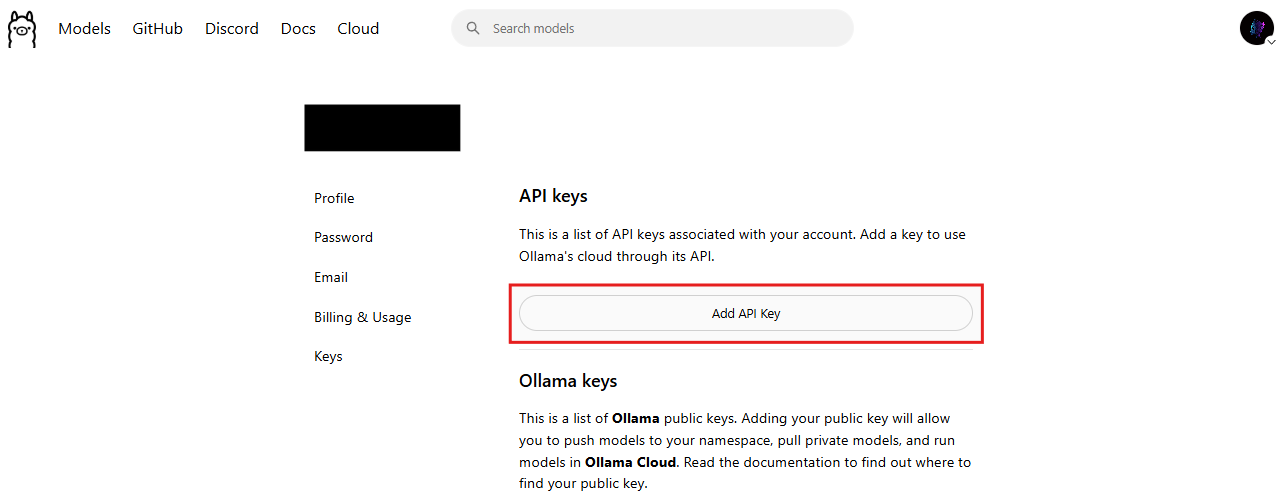
Für die praktische Anwendung stellen Sie sich einen Forschungsagenten vor. Der Agent fragt die Websuche ab, ruft Seiten ab und synthetisiert Antworten. Dieser Workflow übertrifft statische Modelle.
Den MCP-Server für Ollama-Benutzer entmystifizieren
Der MCP-server verbindet Modelle und Tools. Er implementiert das Model Context Protocol, ein Framework für den Kontextaustausch. In Ollama führt ein Python-Skript den Server aus.
Die Einrichtung umfasst das Klonen von Repositories und das Festlegen von Umgebungen. Zum Beispiel startet uv run web-search-mcp.py ihn. Clients verbinden sich über kompatible Schnittstellen.
Cline konfiguriert mit Befehlen in den Einstellungen. Fügen Sie OLLAMA_API_KEY zu den Umgebungen hinzu. Codex bearbeitet config.toml-Dateien. Goose folgt ähnlichen Mustern.
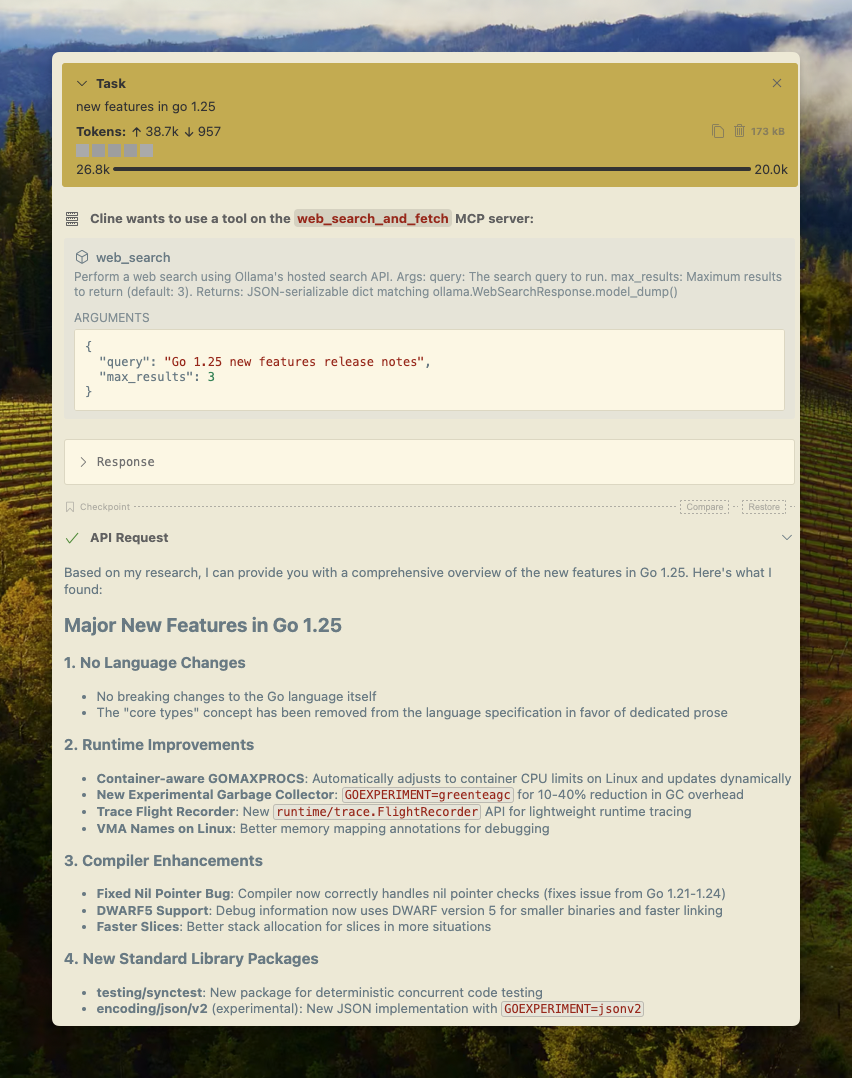
Diese Integration ermöglicht die Websuche in Clients. Modelle rufen Tools dynamisch auf und verbessern so die Interaktivität.
Darüber hinaus unterstützt der MCP-Server Erweiterungen. Entwickler fügen benutzerdefinierte Tools für E-Mail, GitHub oder Bilder hinzu. Diese Flexibilität positioniert Ollama als Infrastruktur für Agenten.
Unter Windows mit NVIDIA umfassen Installationen CUDA-Treiber. Linux verwendet Docker zur Isolation. macOS profitiert von nativer Beschleunigung.
Für fortgeschrittene Setups können mehrere MCP-Server geclustert werden. Dies verteilt die Lasten für Unternehmensmaßstäbe.
So integrieren Sie Ollamas API und MCP-Server
Die Integration beginnt mit der Kontoerstellung. Melden Sie sich kostenlos auf Ollamas Website an. Generieren Sie sofort einen API-Schlüssel.
Installieren Sie anschließend Ollama lokal. Führen Sie ollama serve aus, um den Server zu starten. Ziehen Sie Modelle, die für Tools geeignet sind, wie gpt-oss.
Für die Websuche legen Sie OLLAMA_API_KEY fest. Testen Sie mit Python:
import ollama
response = ollama.web_search(query="latest AI news", max_results=5)
print(response)
Dies gibt JSON mit Ergebnissen zurück.
Um den MCP-Server zu integrieren, laden Sie Beispiele von GitHub herunter. Führen Sie das Skript aus und konfigurieren Sie die Clients.
Für Cline: Bearbeiten Sie die Konfiguration, um auf den MCP-Endpunkt zu verweisen. Testen Sie Prompts, die die Suche aufrufen.
Codex erfordert toml-Updates. Geben Sie den Befehl und die Argumente an.
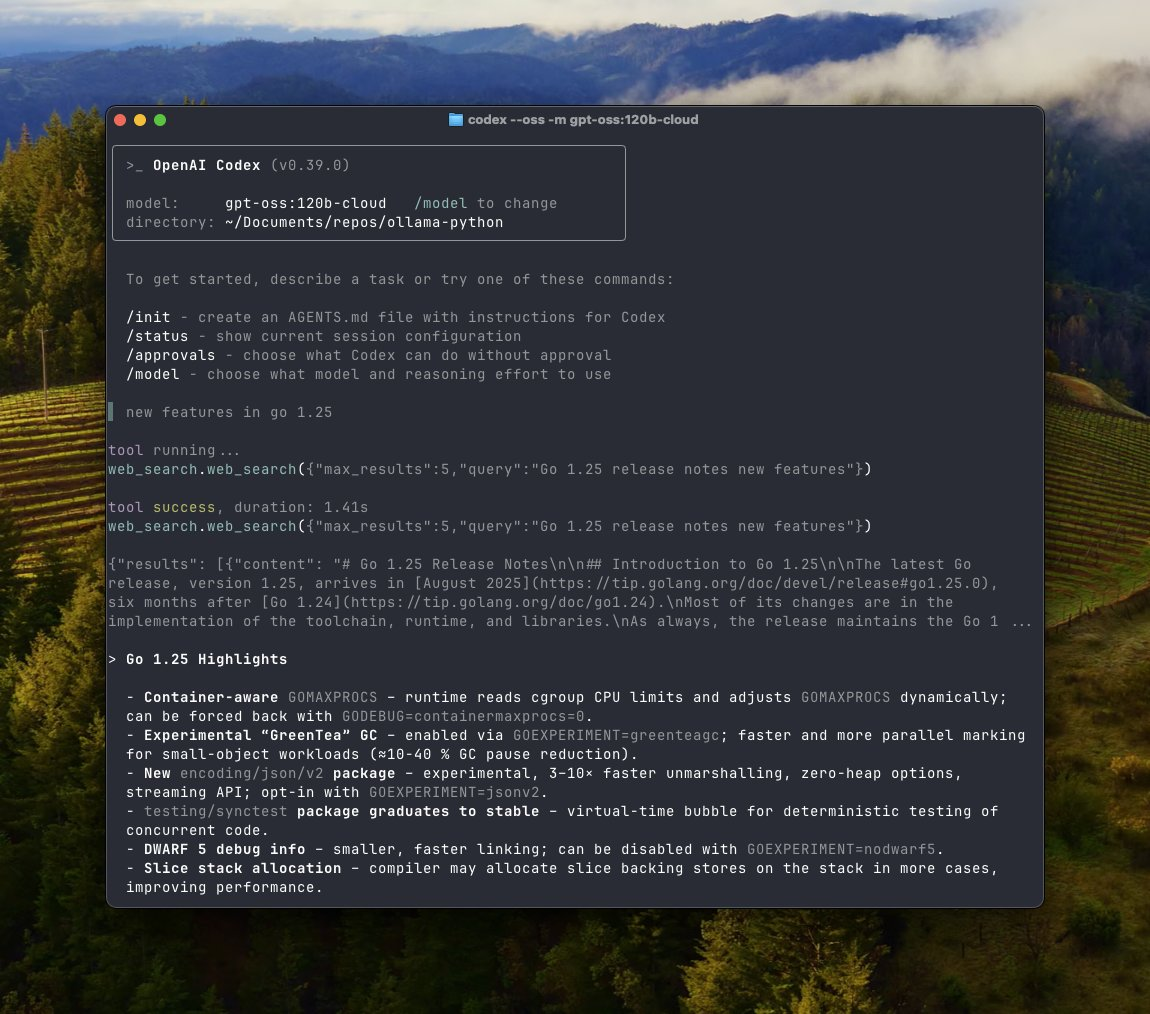
Goose integriert sich über MCP-Einstellungen und ermöglicht Web-Tools.
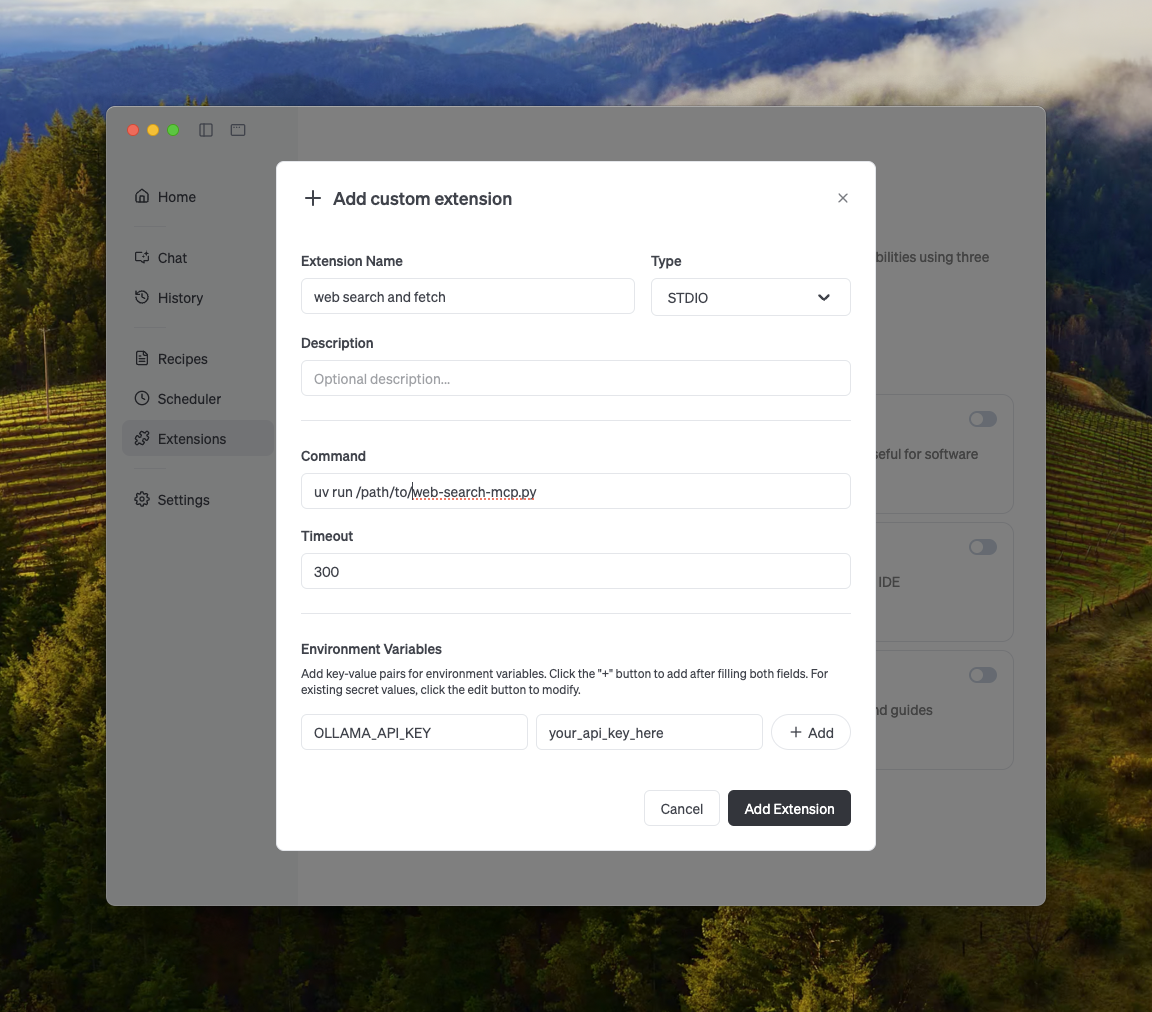
Darüber hinaus können Sie benutzerdefinierte Agenten erstellen. Verwenden Sie Schleifen, um Interaktionen mit mehreren Runden zu verarbeiten. Parsen Sie Tool-Aufrufe und geben Sie Ergebnisse zurück.
Fehlerbehandlung erweist sich als entscheidend. Implementieren Sie Wiederholungsversuche für Ratenbegrenzungen. Überwachen Sie die Nutzung, um innerhalb der Stufen zu bleiben.
Apidog hilft hier. Es simuliert Antworten, testet die Authentifizierung und dokumentiert Workflows. Laden Sie Apidog herunter, um Ollama-Integrationen schnell zu prototypen.
Leistungsstarke Suchagenten mit Ollama erstellen
Agenten stellen einen zentralen Anwendungsfall dar. Ollama bietet Beispiele mit Qwen 3.
Modell ziehen: ollama pull qwen3:4b.
In Python Tools definieren:
tools = [
{"type": "function", "function": {"name": "web_search", "description": "Search the web"}},
{"type": "function", "function": {"name": "web_fetch", "description": "Fetch URL content"}}
]
Die Chat-Schleife verarbeitet Nachrichten, ruft Tools auf und fügt Ergebnisse hinzu.
Dieser Agent beantwortet Anfragen wie "Wie ist das aktuelle Wetter in Tokio?" durch Suchen und Abrufen.
Erweitern Sie auf Vision: Analysieren Sie Bilder über multimodale Modelle und suchen Sie dann nach Kontext.
Für die Optimierung erhöhen Sie die Kontextlängen. Cloud-Modelle verarbeiten bis zur vollen Kapazität.
Agenten senken Kosten, indem sie unnötige Aufrufe minimieren. Ergebnisse lokal cachen.
Kombinieren Sie außerdem mit anderen APIs. Integrieren Sie Datenbanken oder Berechnungstools über MCP.
Preisdetails für Ollama auf verschiedenen Plattformen
Ollama bietet gestaffelte Preise an. Die Basisversion ist kostenlos und hat großzügige Suchlimits. Dies ist für Hobbyisten und Tests geeignet.
Für die Produktion aktualisieren Sie Abonnements. Der Cloud-Zugang beginnt bei etwa 20 $ pro Monat, basierend auf Community-Diskussionen. Höhere Stufen bieten unbegrenzte Abfragen und vorrangigen Support.
Plattformen beeinflussen die Kosten indirekt. Lokale Ausführungen unter macOS, Windows, Linux verursachen keine Gebühren außer für Hardware. Cloud-Modelle werden pro Nutzung abgerechnet.
Die Web-Such-API berechnet pro Aufruf in erweiterten Plänen. Kostenlose Stufen decken jedoch die meisten Anforderungen ab.
Vergleich zu Alternativen: OpenAIs Suche kostet 10 $ pro 1.000 Aufrufe. Ollama unterbietet dies für Benutzer, die lokale Lösungen bevorzugen.
Unternehmen berechnen den ROI. Lokale Inferenz spart Datenübertragung, während die API nur minimalen Overhead hinzufügt.
Für die Budgetierung überwachen Sie über Dashboards. Ollama bietet Nutzungsstatistiken.
Anwendungsfälle und Beispiele aus der Praxis
Entwickler wenden dies in Chatbots an. Ein Bot sucht Nachrichten, ruft Artikel ab und fasst zusammen.
In der Bildung fragen Tools Fakten ab und reduzieren Fehler.
Forscher erstellen Agenten für Literaturrecherchen. Durchsuchen Sie akademische Websites, rufen Sie PDFs ab.
E-Commerce integriert sich für Produktempfehlungen. Suchen Sie nach Trends, rufen Sie Bewertungen ab.
Codebeispiel für Agenten:
import ollama
import json
def run_agent(prompt):
messages = [{"role": "user", "content": prompt}]
while True:
response = ollama.chat(model="qwen3:4b", messages=messages, tools=tools)
if "tool_calls" in response["message"]:
for call in response["message"]["tool_calls"]:
if call["function"]["name"] == "web_search":
args = json.loads(call["function"]["arguments"])
result = ollama.web_search(**args)
messages.append({"role": "tool", "content": str(result)})
else:
return response["message"]["content"]
Diese Schleife verarbeitet Iterationen.
Darüber hinaus die Vision-Nutzung: Bilder beschreiben, nach Übereinstimmungen suchen.
Unternehmen automatisieren Berichte. Agenten kompilieren Daten aus Webquellen.
Vorteile der Einführung von Ollamas neuen Funktionen
Ollama verbessert den Datenschutz. Daten bleiben lokal, API-Aufrufe sind optional.
Die Genauigkeit verbessert sich durch Echtzeit-Augmentierung. Modelle verarbeiten sich entwickelnde Themen.
Skalierbarkeit folgt. Der MCP-Server verteilt Aufgaben.
Kosteneffizienz sticht hervor. Kostenlose Stufen minimieren Ausgaben.
Die Entwicklerproduktivität steigt. Integrationen wie Apidog beschleunigen Workflows.
In der Community diskutieren Foren über Optimierungen.
Das Ökosystem wächst. Tools wie OpenWebUI interagieren mit Ollama.
Potenzielle Herausforderungen und Lösungen
Herausforderungen umfassen Ratenbegrenzungen. Lösung: Abonnements aktualisieren.
Hardwarebeschränkungen limitieren Modelle. Cloud-Varianten verwenden.
Integrationskomplexität entsteht. Befolgen Sie Dokumentation und Beispiele.
Sicherheit: API-Schlüssel regelmäßig rotieren.
Das Debuggen von Agenten erfordert Protokollierung. Implementieren Sie ausführliche Modi.
Testen Sie außerdem plattformübergreifend auf Konsistenz.
Zusammenfassung der Fortschritte von Ollama
Ollamas Web-Such-API und der MCP-Server stellen einen bedeutenden Fortschritt dar. Entwickler nutzen diese für leistungsstarke Anwendungen. Mit kostenlosen Stufen und plattformübergreifender Unterstützung beschleunigt sich die Akzeptanz. Erkunden Sie weiter, integrieren Sie mit Apidog und bauen Sie die nächste Generation von KI-Tools.