
Das Feld der künstlichen Intelligenz entwickelt sich rasant weiter und bringt innovative Modelle hervor, die die Grenzen der Computertechnik neu definieren. Unter diesen Fortschritten tritt MiniMax-M1 als bahnbrechende Entwicklung hervor und etabliert sich als das weltweit erste Open-Weight, großskalige Hybrid-Attention Reasoning Modell. Dieses von MiniMax entwickelte Modell verspricht, die Art und Weise, wie wir komplexe Schlussfolgerungsaufgaben angehen, zu verändern, indem es ein beeindruckendes Kontextfenster von 1 Million Eingabe-Tokens und 80.000 Ausgabe-Tokens bietet.
Verständnis der Kernarchitektur von MiniMax-M1
MiniMax-M1 zeichnet sich durch seine einzigartige hybride Mixture-of-Experts (MoE)-Architektur in Kombination mit einem blitzschnellen Aufmerksamkeitsmechanismus aus. Dieses Design baut auf der Grundlage seines Vorgängers, MiniMax-Text-01, auf, der über beeindruckende 456 Milliarden Parameter verfügt, wovon 45,9 Milliarden pro Token aktiviert werden. Der MoE-Ansatz ermöglicht es dem Modell, basierend auf der Eingabe nur eine Teilmenge seiner Parameter zu aktivieren, was die Recheneffizienz optimiert und Skalierbarkeit ermöglicht. Gleichzeitig verbessert der Hybrid-Attention-Mechanismus die Fähigkeit des Modells, Daten mit langem Kontext zu verarbeiten, wodurch es ideal für Aufgaben ist, die ein tiefes Verständnis über längere Sequenzen erfordern.

Die Integration dieser Komponenten führt zu einem Modell, das Leistung und Ressourcennutzung effektiv ausbalanciert. Durch die selektive Einbindung von Experten innerhalb des MoE-Frameworks reduziert MiniMax-M1 den Rechenaufwand, der typischerweise mit großskaligen Modellen verbunden ist. Darüber hinaus beschleunigt der Lightning-Attention-Mechanismus die Verarbeitung von Aufmerksamkeitsgewichten und stellt sicher, dass das Modell auch bei seinem umfangreichen Kontextfenster einen hohen Durchsatz beibehält.
Trainingseffizienz: Die Rolle des Reinforcement Learning
Einer der bemerkenswertesten Aspekte von MiniMax-M1 ist sein Trainingsprozess, der großskaliges Reinforcement Learning (RL) mit einer beispiellosen Effizienz nutzt. Das Modell wurde zu Kosten von nur 534.700 US-Dollar trainiert, eine Zahl, die das innovative RL-Skalierungsframework von MiniMax unterstreicht. Dieses Framework führt CISPO (Clipped Importance Sampling with Policy Optimization) ein, einen neuartigen Algorithmus, der Importance Sampling Gewichte anstelle von Token-Updates clippt. Dieser Ansatz übertrifft traditionelle RL-Varianten und bietet einen stabileren und effizienteren Trainingsprozess.

Darüber hinaus spielt das Hybrid-Attention-Design eine entscheidende Rolle bei der Steigerung der RL-Effizienz. Durch die Bewältigung einzigartiger Herausforderungen im Zusammenhang mit der Skalierung von RL innerhalb einer hybriden Architektur erreicht MiniMax-M1 ein Leistungsniveau, das mit Closed-Weight-Modellen konkurriert, trotz seiner Open-Source-Natur. Diese Trainingsmethodik senkt nicht nur die Kosten, sondern setzt auch einen neuen Maßstab für die Entwicklung leistungsstarker KI-Modelle mit begrenzten Ressourcen.
Leistungskennzahlen: Benchmarking von MiniMax-M1
Um die Fähigkeiten von MiniMax-M1 zu bewerten, führten die Entwickler umfangreiche Benchmarks für eine Reihe von Aufgaben durch, darunter Mathematik auf Wettbewerbsniveau, Codierung, Softwareentwicklung, agentische Werkzeugnutzung und Verständnis langer Kontexte. Die Ergebnisse unterstreichen die Überlegenheit des Modells gegenüber anderen Open-Weight-Modellen wie DeepSeek-R1 und Qwen3-235B-A22B.
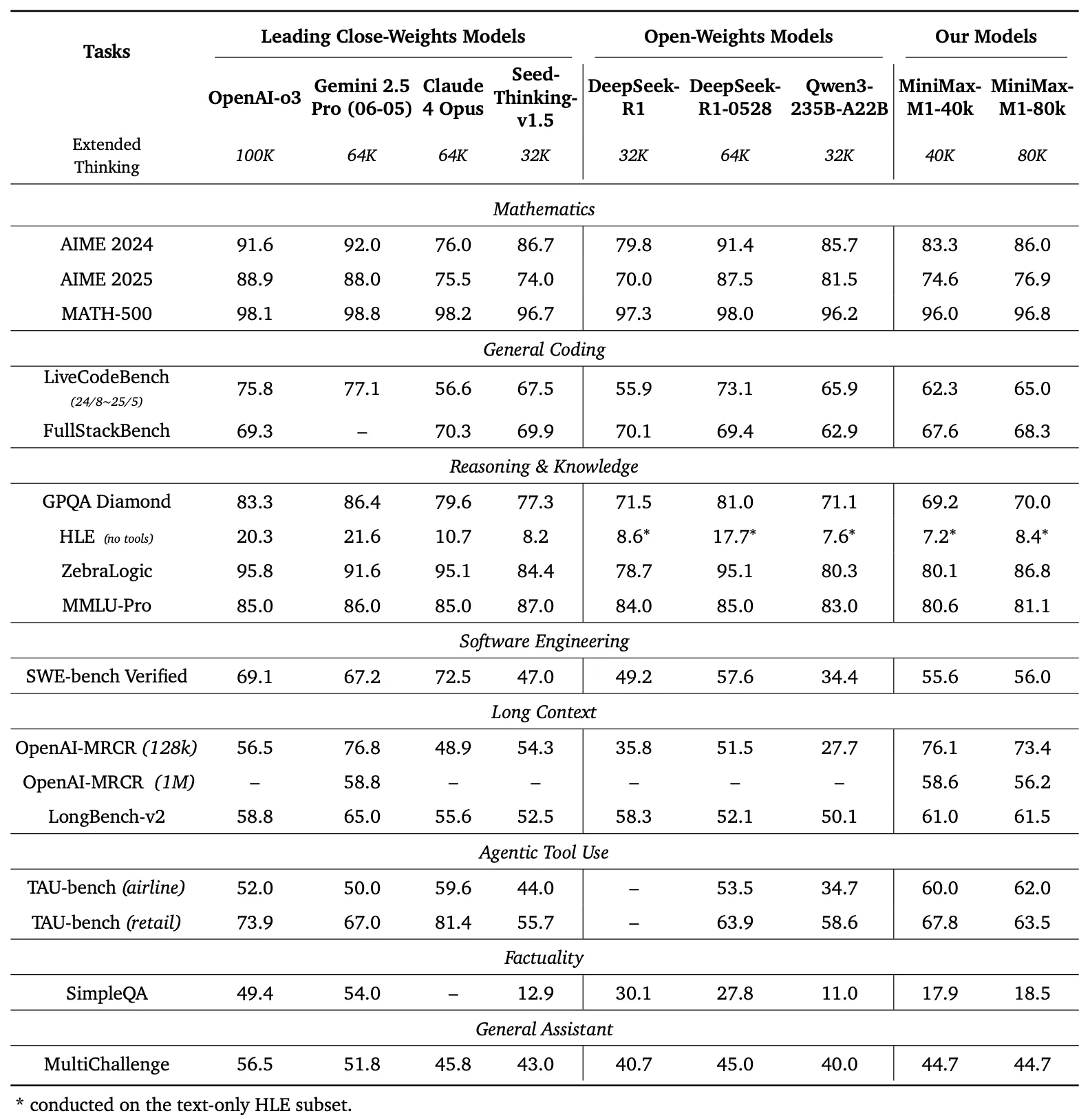
Benchmark-Vergleich
Die linke Tafel von Abbildung 1 vergleicht die Leistung von MiniMax-M1 mit führenden kommerziellen und Open-Weight-Modellen in mehreren Benchmarks

- AIME 2024: MiniMax-M1 erreicht eine Genauigkeit von 86,0 % und übertrifft damit OpenAI o3 (88,0 %) und Claude 4 Opus (80,0 %), was seine Fähigkeiten im mathematischen Schlussfolgern unter Beweis stellt.
- LiveCodeBench: Mit einem Score von 65,0 % übertrifft MiniMax-M1 DeepSeek-R1-0528 (56,0 %) und erreicht die Leistung von Seed-Thinking v1.5 (65,0 %), was auf starke Programmierfähigkeiten hindeutet.
- SW-E Bench Verified: Das Modell erzielt 62,8 % und übertrifft damit Qwen3-235B-A22B (60,0 %) bei Softwareentwicklungsaufgaben.
- TAU-bench: MiniMax-M1 erreicht eine Genauigkeit von 73,4 % und übertrifft damit Gemini 2.5 Pro (70,0 %) bei der agentischen Werkzeugnutzung.
- MRCR (4-needle): Mit einer Genauigkeit von 74,4 % liegt es bei Aufgaben zum Verständnis langer Kontexte vor anderen Modellen.
Diese Ergebnisse unterstreichen die Vielseitigkeit von MiniMax-M1 und seine Fähigkeit, mit proprietären Modellen zu konkurrieren, was es zu einem wertvollen Gut für Open-Source-Gemeinschaften macht.

MiniMax-M1 zeigt eine lineare Zunahme der FLOPs (Floating Point Operations), wenn die Generierungslänge von 32.000 auf 128.000 Tokens ansteigt. Diese Skalierbarkeit stellt sicher, dass das Modell auch bei erweiterten Ausgaben Effizienz und Leistung beibehält, ein kritischer Faktor für Anwendungen, die detaillierte und lange Antworten erfordern.
Schlussfolgern mit langem Kontext: Eine neue Grenze
Das markanteste Merkmal von MiniMax-M1 ist sein extrem langes Kontextfenster, das bis zu 1 Million Eingabe-Tokens und 80.000 Ausgabe-Tokens unterstützt. Diese Fähigkeit ermöglicht es dem Modell, riesige Datenmengen – das Äquivalent eines ganzen Romans oder einer Reihe von Büchern – in einem einzigen Durchgang zu verarbeiten, was die Grenze von 128.000 Tokens von Modellen wie OpenAI's GPT-4 weit übertrifft. Das Modell bietet zwei Inferenzmodi – 40.000 und 80.000 Denkbudgets – die unterschiedlichen Szenarioanforderungen gerecht werden und eine flexible Bereitstellung ermöglichen.

Dieses erweiterte Kontextfenster verbessert die Leistung des Modells bei Aufgaben mit langem Kontext, wie z. B. dem Zusammenfassen langer Dokumente, dem Führen von Gesprächen über mehrere Runden oder der Analyse komplexer Datensätze. Durch das Beibehalten kontextbezogener Informationen über Millionen von Tokens bietet MiniMax-M1 eine robuste Grundlage für Anwendungen in Forschung, Rechtsanalyse und Inhaltserstellung, bei denen die Kohärenz über lange Sequenzen hinweg von größter Bedeutung ist.
Agentische Werkzeugnutzung und praktische Anwendungen
Neben seinem beeindruckenden Kontextfenster zeichnet sich MiniMax-M1 durch die agentische Werkzeugnutzung aus, ein Bereich, in dem KI-Modelle mit externen Werkzeugen interagieren, um Probleme zu lösen. Die Fähigkeit des Modells, sich in Plattformen wie MiniMax Chat zu integrieren und funktionale Webanwendungen zu generieren – wie z. B. Tippgeschwindigkeitstests und Labyrinthgeneratoren – zeigt seinen praktischen Nutzen. Diese Anwendungen, die mit minimalem Setup und ohne Plugins erstellt wurden, demonstrieren die Fähigkeit des Modells, produktionsreifen Code zu erzeugen.

Zum Beispiel kann das Modell eine saubere, funktionale Webanwendung generieren, um Wörter pro Minute (WPM) in Echtzeit zu verfolgen, oder einen visuell ansprechenden Labyrinthgenerator mit A*-Algorithmus-Visualisierung erstellen. Solche Fähigkeiten positionieren MiniMax-M1 als leistungsstarkes Werkzeug für Entwickler, die Softwareentwicklungs-Workflows automatisieren oder interaktive Benutzererlebnisse schaffen möchten.
Open-Source-Zugänglichkeit und Auswirkungen auf die Gemeinschaft
Die Veröffentlichung von MiniMax-M1 unter der Apache 2.0 Lizenz stellt einen bedeutenden Meilenstein für die Open-Source-Gemeinschaft dar. Verfügbar auf GitHub und Hugging Face, lädt das Modell Entwickler, Forscher und Unternehmen ein, es ohne proprietäre Einschränkungen zu erkunden, zu modifizieren und bereitzustellen. Diese Offenheit fördert Innovationen und ermöglicht die Erstellung kundenspezifischer Lösungen, die auf spezifische Bedürfnisse zugeschnitten sind.
Die Zugänglichkeit des Modells demokratisiert auch den Zugang zu fortschrittlicher KI-Technologie und ermöglicht es kleineren Organisationen und unabhängigen Entwicklern, mit größeren Unternehmen zu konkurrieren. Durch die Bereitstellung detaillierter Dokumentation und eines Tech-Reports stellt MiniMax sicher, dass Benutzer die Fähigkeiten des Modells replizieren und erweitern können, was weitere Fortschritte im KI-Ökosystems beschleunigt.
Technische Implementierung: Bereitstellung und Optimierung
Die Bereitstellung von MiniMax-M1 erfordert sorgfältige Berücksichtigung der Rechenressourcen und Optimierungstechniken. Der Tech-Report empfiehlt die Verwendung von vLLM (Virtual Large Language Model) für die Produktionsbereitstellung, was die Inferenzgeschwindigkeit und den Speicherverbrauch optimiert. Dieses Werkzeug nutzt die hybride Architektur des Modells, um die Rechenlast effizient zu verteilen und einen reibungslosen Betrieb auch bei großskaligen Eingaben zu gewährleisten.
Entwickler können MiniMax-M1 für spezifische Aufgaben feinabstimmen, indem sie das Denkbudget (40.000 oder 80.000) basierend auf ihren Anforderungen anpassen. Zusätzlich ermöglicht das effiziente RL-Trainingsframework des Modells weitere Anpassungen durch Reinforcement Learning, was die Adaption an Nischenanwendungen wie Echtzeitübersetzung oder automatisierten Kundensupport ermöglicht.
Fazit: Die MiniMax-M1 Revolution annehmen
MiniMax-M1 stellt einen bedeutenden Fortschritt im Bereich der Open-Weight, großskaligen Hybrid-Attention Reasoning Modelle dar. Sein beeindruckendes Kontextfenster, der effiziente Trainingsprozess und die überlegene Benchmark-Leistung positionieren es als führend in der KI-Landschaft. Indem MiniMax diese Technologie als Open-Source-Ressource anbietet, befähigt es Entwickler und Forscher, neue Möglichkeiten zu erkunden, von fortgeschrittener Softwareentwicklung bis hin zur Analyse langer Kontexte.
Während die KI-Gemeinschaft weiter wächst, dient MiniMax-M1 als Beweis für die Kraft von Innovation und Zusammenarbeit. Für diejenigen, die bereit sind, sein Potenzial zu erkunden, bietet das kostenlose Herunterladen von Apidog einen praktischen Einstiegspunkt, um mit diesem transformativen Modell zu experimentieren. Die Reise mit MiniMax-M1 hat gerade erst begonnen, und seine Auswirkungen werden zweifellos die Zukunft der künstlichen Intelligenz prägen.
