
Die Ingenieure von Mistral AI haben Magistral Small 1.2 als ein Modell mit 24 Milliarden Parametern entwickelt, das die Effizienz der Argumentation priorisiert. Diese Version baut direkt auf Mistral Small 1.1 auf. Die Ingenieure wendeten überwachtes Fine-Tuning unter Verwendung von Spuren von Magistral Medium an, gefolgt von Phasen des Reinforcement Learnings. Folglich zeichnet sich das Modell durch mehrstufige Logik ohne übermäßigen Rechenaufwand aus.
Die Entwicklung der Magistral Modellfamilie verstehen
Architektur-Grundlagen und technische Spezifikationen
Das Magistral Small 1.2 baut auf der robusten Grundlage von Magistral 1.1 auf und integriert erweiterte Argumentationsfähigkeiten durch überwachtes Fine-Tuning (SFT) aus Magistral Medium Spuren in Kombination mit Reinforcement Learning (RL) Optimierung. Aufbauend auf Magistral 1.1, mit zusätzlichen Argumentationsfähigkeiten, unterläuft es SFT von Magistral Medium Spuren und RL obendrauf, es ist ein kleines, effizientes Argumentationsmodell mit 24 Milliarden Parametern.

Darüber hinaus ermöglicht das architektonische Design effiziente Bereitstellungsszenarien. Magistral Small kann lokal bereitgestellt werden und passt nach der Quantisierung in eine einzelne RTX 4090 oder ein 32-GB-RAM MacBook. Diese Zugänglichkeit macht das Modell sowohl für Unternehmens- als auch für individuelle Entwicklerumgebungen geeignet.
Wichtige technische Verbesserungen in Version 1.2
Der Übergang von Version 1.1 zu 1.2 führt mehrere entscheidende Verbesserungen ein, die die Modellleistung und Benutzerfreundlichkeit erheblich beeinflussen. Insbesondere beheben diese Updates grundlegende Einschränkungen und erweitern gleichzeitig die Fähigkeitsgrenzen.
Durchbruch bei der multimodalen Integration
Ausgestattet mit einem Vision-Encoder verarbeiten diese Modelle Text und Bilder nahtlos. Diese Integration stellt einen Paradigmenwechsel von rein textbasierter Argumentation zu einem umfassenden multimodalen Verständnis dar. Die Vision-Encoder-Architektur ermöglicht es den Modellen, visuelle Informationen zu verarbeiten, während ihre Text-Argumentationsfähigkeiten erhalten bleiben.
Ergebnisse der Leistungsoptimierung
15 % Verbesserungen bei Mathematik- und Coding-Benchmarks wie AIME 24/25 und LiveCodeBench v5/v6. Diese Leistungssteigerungen lassen sich direkt in praktische Anwendungen umsetzen, insbesondere profitieren Entwickler, die an mathematischen Berechnungen, Algorithmenentwicklung und komplexen Problemlösungsszenarien arbeiten.
Umfassende Funktionsanalyse
Erweiterte Argumentationsfähigkeiten
Die Argumentationsarchitektur integriert spezialisierte Denk-Token, die den internen Argumentationsprozess des Modells strukturieren. Die Implementierung verwendet [THINK] und [/THINK] Token, um Argumentationsinhalte zu kapseln, wodurch Transparenz im Entscheidungsprozess des Modells geschaffen und gleichzeitig Verwirrung während der Prompt-Verarbeitung verhindert wird.
Darüber hinaus arbeitet das Argumentationssystem durch erweiterte Ketten logischer Schlussfolgerungen, bevor es endgültige Antworten generiert. Dieser Ansatz ermöglicht es dem Modell, komplexe Probleme zu bewältigen, die eine mehrstufige Analyse, mathematische Ableitungen und logische Deduktionen erfordern.
Infrastruktur für mehrsprachige Unterstützung
Die Modelle demonstrieren umfassende Sprachunterstützung über verschiedene Sprachfamilien hinweg. Die unterstützten Sprachen umfassen europäische, asiatische, nahöstliche und südasiatische Regionen, darunter Englisch, Französisch, Deutsch, Griechisch, Hindi, Indonesisch, Italienisch, Japanisch, Koreanisch, Malaiisch, Nepali, Polnisch, Portugiesisch, Rumänisch, Russisch, Serbisch, Spanisch, Türkisch, Ukrainisch, Vietnamesisch, Arabisch, Bengali, Chinesisch und Farsi.
Zusätzlich gewährleistet diese umfassende mehrsprachige Fähigkeit globale Zugänglichkeit und ermöglicht es Entwicklern, Anwendungen für internationale Märkte zu erstellen, ohne separate Modellimplementierungen für verschiedene Sprachen zu benötigen.
Architektur für die Bildverarbeitung
Die Integration des Vision-Encoders ermöglicht eine ausgeklügelte Bildanalyse und Argumentation. Das Modell verarbeitet visuelle Inhalte und kombiniert sie mit textuellen Informationen, um umfassende Antworten zu generieren. Diese Fähigkeit geht über die einfache Bilderkennung hinaus und umfasst kontextuelles Verständnis, räumliches Denken und visuelle Problemlösung.
Leistungsbenchmarks und Vergleichsanalyse
Leistung bei mathematischer Argumentation
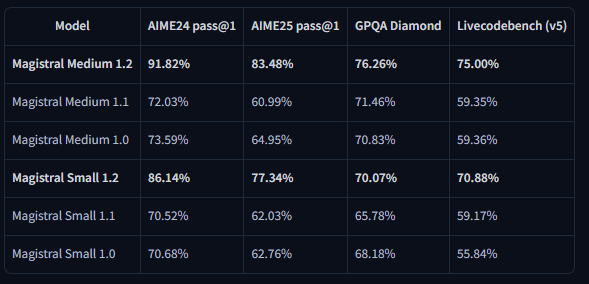
Die Benchmark-Ergebnisse zeigen erhebliche Verbesserungen über wichtige Bewertungsmetriken hinweg. Magistral Small 1.2 erreicht 86,14 % bei AIME24 pass@1 und 77,34 % bei AIME25 pass@1, was signifikante Fortschritte gegenüber den 70,52 % und 62,03 % der Version 1.1 darstellt.
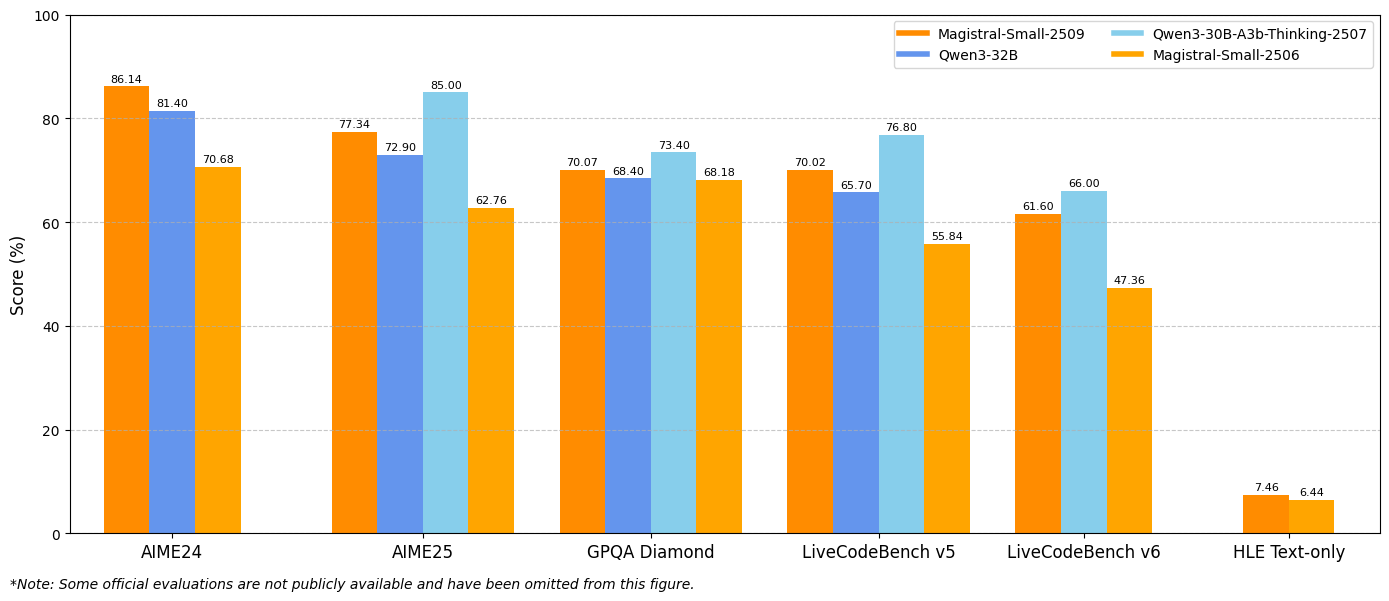
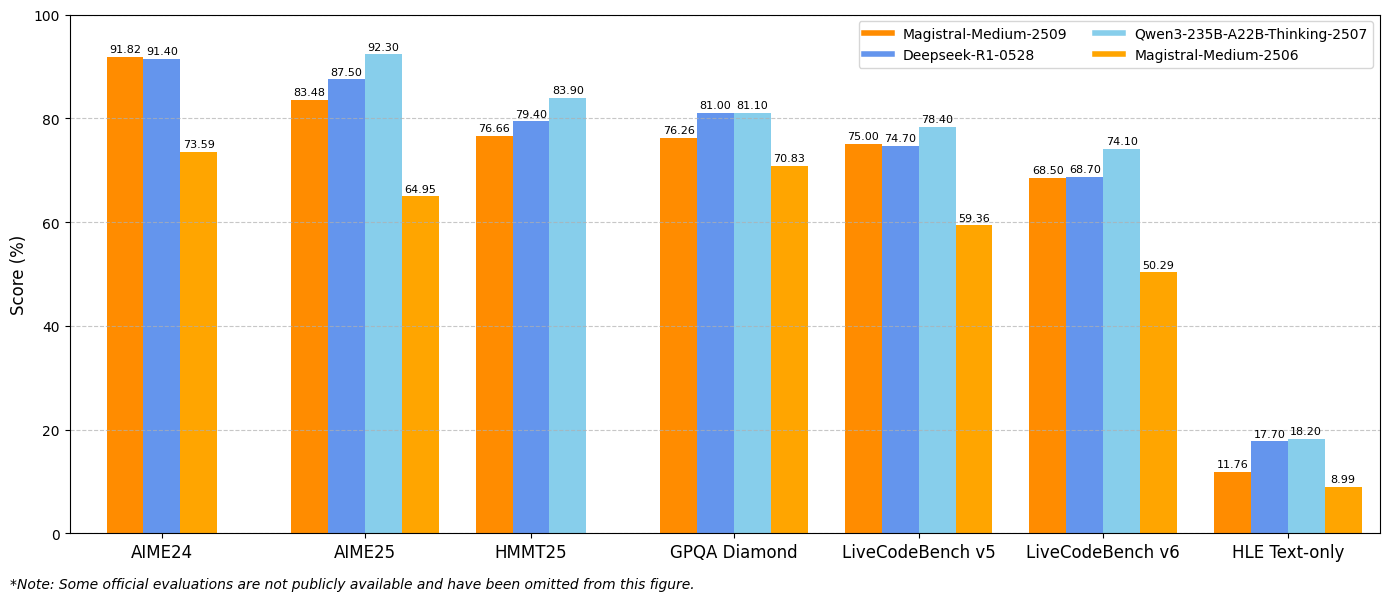
Ähnlich liefert Magistral Medium 1.2 eine außergewöhnliche Leistung mit 91,82 % bei AIME24 pass@1 und 83,48 % bei AIME25 pass@1, womit es die 72,03 % und 60,99 % der Version 1.1 übertrifft. Diese Verbesserungen deuten auf erweiterte mathematische Argumentationsfähigkeiten hin, die direkt wissenschaftlichem Rechnen, technischen Anwendungen und Forschungsumgebungen zugutekommen.
Metriken zur Coding-Leistung
LiveCodeBench-Evaluierungen zeigen erhebliche Verbesserungen der Coding-Fähigkeiten. Magistral Small 1.2 erzielt 70,88 % bei LiveCodeBench v5, während Magistral Medium 1.2 75,00 % erreicht. Diese Ergebnisse stellen bedeutsame Fortschritte bei Aufgaben der Code-Generierung, des Debuggings und der Algorithmenimplementierung dar.
Darüber hinaus zeigen die Modelle ein verbessertes Verständnis von Programmierkonzepten, Softwarearchitekturmustern und Debugging-Methoden. Diese verbesserte Coding-Leistung kommt Softwareentwicklungsteams, automatisierten Test-Frameworks und Bildungs-Programmierumgebungen zugute.
GPQA Diamond Ergebnisse
Die Benchmark-Ergebnisse des General Purpose Question Answering (GPQA) Diamond zeigen die breiten Wissensanwendungsfähigkeiten der Modelle. Magistral Small 1.2 erreicht 70,07 %, während Magistral Medium 1.2 76,26 % erreicht. Diese Ergebnisse spiegeln die Fähigkeit der Modelle wider, verschiedene Fragetypen zu bearbeiten, die interdisziplinäres Wissen und Argumentation erfordern.
Implementierungs- und Integrationsstrategien
Konfiguration der Entwicklungsumgebung
Die Implementierung von Magistral Small 1.2 und Magistral Medium 1.2 erfordert spezifische technische Konfigurationen zur Leistungsoptimierung. Die empfohlenen Sampling-Parameter umfassen top_p: 0.95, temperature: 0.7 und max_tokens: 131072. Diese Einstellungen gleichen Kreativität mit Konsistenz aus und unterstützen gleichzeitig erweiterte Argumentationssequenzen.
Zusätzlich unterstützen die Modelle verschiedene Bereitstellungs-Frameworks, darunter vLLM, Transformers, llama.cpp und spezialisierte Quantisierungsformate. Diese Flexibilität ermöglicht die Integration in verschiedene Computerumgebungen und Anwendungsfälle.
API-Integration mit Apidog
Apidog bietet umfassende Tools zum Testen und Integrieren von Magistral APIs in Ihre Anwendungen. Die Plattform unterstützt erweiterte API-Testszenarien, einschließlich multimodaler Eingabeverarbeitung, Argumentations-Trace-Analyse und Leistungsüberwachung. Über die Benutzeroberfläche von Apidog können Entwickler Bild-Text-Kombinationen effizient testen, Argumentationsausgaben validieren und API-Aufrufparameter optimieren.
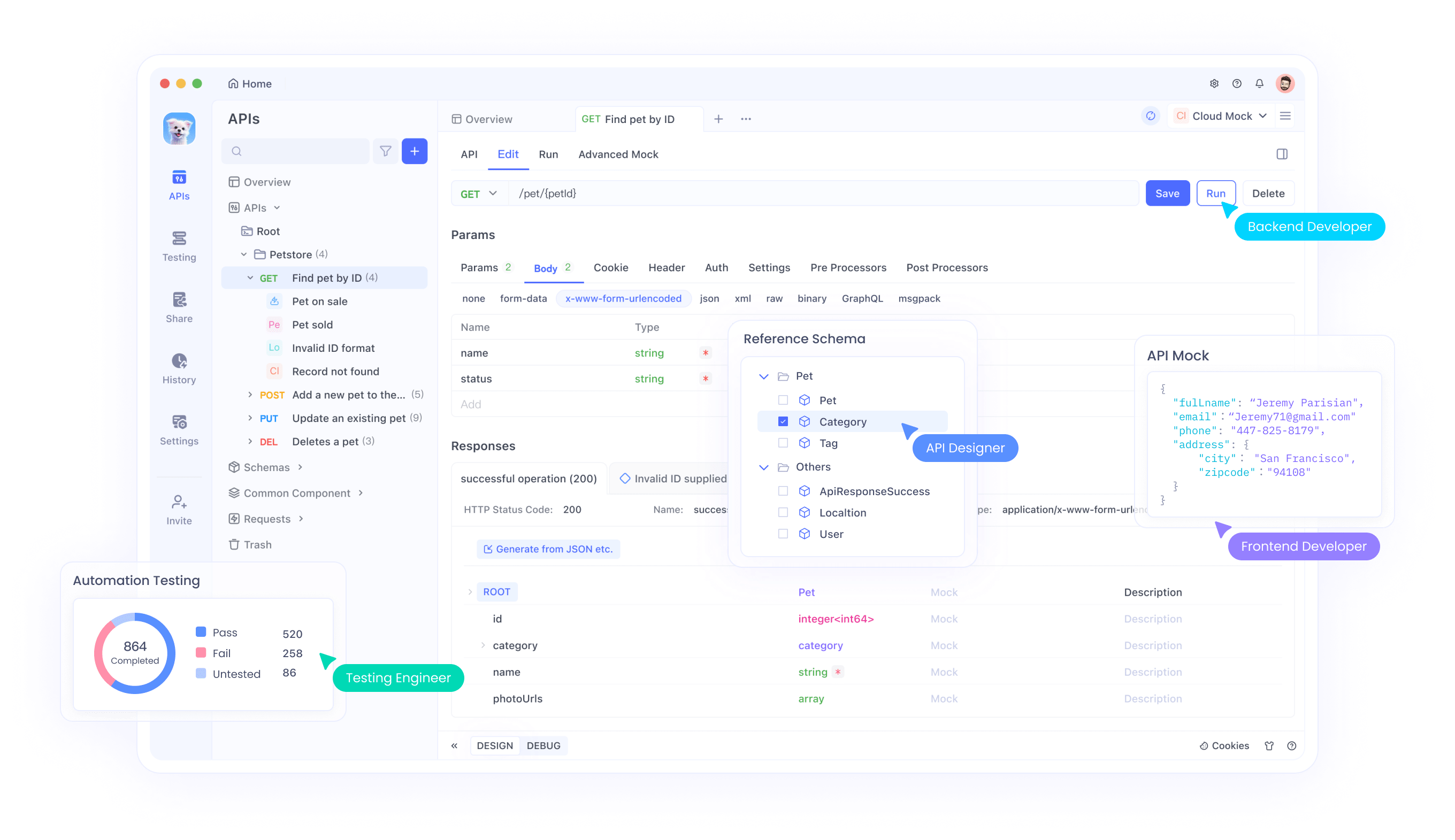
Darüber hinaus ermöglichen die Kollaborationsfunktionen von Apidog Teams, API-Testkonfigurationen zu teilen, Integrationsmuster zu dokumentieren und konsistente Teststandards über Entwicklungszyklen hinweg aufrechtzuerhalten. Dieser kollaborative Ansatz beschleunigt Entwicklungszeitpläne und gewährleistet gleichzeitig robuste API-Implementierungen.
System-Prompt-Optimierung
Die Modelle erfordern sorgfältig ausgearbeitete System-Prompts, um eine optimale Leistung zu erzielen. Die empfohlene System-Prompt-Struktur umfasst Argumentationsanweisungen, Formatierungsrichtlinien und Sprachanweisungen. Der Prompt sollte explizit Denkprozesse unter Verwendung der spezialisierten Token anfordern und gleichzeitig eine konsistente Antwortformatierung beibehalten.
Darüber hinaus ermöglicht die Anpassung des System-Prompts anwendungsspezifische Optimierungen. Entwickler können Prompts ändern, um bestimmte Argumentationsmuster hervorzuheben, Ausgabeformate anzupassen oder domänenspezifische Wissensanforderungen zu integrieren.
Technischer Implementierungs-Deep-Dive
Speicher- und Rechenanforderungen
Magistral Small 1.2 arbeitet effizient in Hardwareumgebungen mit eingeschränkten Ressourcen und behält dabei eine hohe Leistung bei. Die Architektur mit 24 Milliarden Parametern ermöglicht die Bereitstellung auf Consumer-Hardware, wenn sie richtig quantisiert wird, wodurch fortgeschrittene Argumentationsfähigkeiten für einzelne Entwickler und kleine Teams zugänglich werden.
Darüber hinaus reduzieren die Verbesserungen der Recheneffizienz in Version 1.2 die Inferenzlatenz bei gleichzeitiger Beibehaltung der Argumentationsqualität. Diese Optimierung ermöglicht Echtzeitanwendungen und interaktive Systeme, die eine sofortige Antwortgenerierung erfordern.
Kontextfenster und Verarbeitungsfähigkeiten
Die Modelle unterstützen ein Kontextfenster von 128.000 Token, was die Verarbeitung umfangreicher Dokumente, komplexer Konversationen und groß angelegter Analyseaufgaben ermöglicht. Obwohl die Leistung jenseits von 40.000 Token abnehmen kann, behalten die Modelle eine vernünftige Funktionalität über den gesamten Kontextbereich bei.
Zusätzlich ermöglicht die erweiterte Kontextfähigkeit eine umfassende Dokumentenanalyse, langwierige Argumentationsaufgaben und mehrstufige Konversationen mit beibehaltener Kontextsensibilität. Diese Kapazität unterstützt Unternehmensanwendungen, die eine umfangreiche Informationsverarbeitung erfordern.
Quantisierungs- und Optimierungstechniken
Die Modelle unterstützen verschiedene Quantisierungsformate durch GGUF-Implementierungen, was die Bereitstellung über verschiedene Hardwarekonfigurationen hinweg ermöglicht. Diese Optimierungen reduzieren den Speicherbedarf bei gleichzeitiger Beibehaltung der Argumentationsfähigkeiten, wodurch die Modelle in ressourcenbeschränkten Umgebungen zugänglich werden.
Darüber hinaus erhalten spezialisierte Optimierungstechniken die Inferenzgeschwindigkeit bei gleichzeitiger Unterstützung komplexer Argumentationsoperationen. Diese technischen Verbesserungen gewährleisten die praktische Bereitstellungsfähigkeit in verschiedenen Computerumgebungen.
Testen und Validieren mit Apidog
Umfassende API-Teststrategien
Apidog bietet wesentliche Tools zur Validierung von Magistral-Modellintegrationen durch umfassende Test-Frameworks. Die Plattform unterstützt multimodales Input-Testing, Argumentations-Trace-Validierung und Leistungs-Benchmarking. Teams können Test-Suites erstellen, die sowohl die funktionale Korrektheit als auch die Leistungsmerkmale überprüfen.
Die automatisierten Testfunktionen von Apidog ermöglichen kontinuierliche Integrations-Workflows, die die Konsistenz der Modellleistung über Entwicklungszyklen hinweg sicherstellen. Diese Automatisierung reduziert den manuellen Testaufwand bei gleichzeitiger Aufrechterhaltung der Qualitätssicherungsstandards.
Leistungsüberwachung und -optimierung
Durch die Überwachungsfunktionen von Apidog können Entwicklungsteams API-Leistungsmetriken verfolgen, Optimierungsmöglichkeiten identifizieren und die Servicezuverlässigkeit aufrechterhalten. Die Plattform bietet detaillierte Analysen zu Antwortzeiten, Argumentationsqualität und Ressourcennutzungsmustern.
Darüber hinaus ermöglichen die Überwachungsdaten proaktive Optimierungsstrategien, die die Anwendungsleistung und Benutzererfahrung verbessern. Dieser datengesteuerte Ansatz gewährleistet eine optimale Modellnutzung in Produktionsumgebungen.
Fazit
Magistral Small 1.2 und Magistral Medium 1.2 stellen bedeutende Fortschritte in der multimodalen KI-Argumentationstechnologie dar. Die Kombination aus verbesserter mathematischer Leistung, Bildverarbeitungsfähigkeiten und verbesserter Argumentationstransparenz schafft leistungsstarke Tools für vielfältige Anwendungen, die von der wissenschaftlichen Forschung bis zur Softwareentwicklung reichen.
Die Verbesserungen der Zugänglichkeit durch lokale Bereitstellungsoptionen und umfassende API-Unterstützung demokratisieren den Zugang zu erweiterten Argumentationsfähigkeiten. Organisationen können nun ausgeklügelte KI-Argumentation in ihre Workflows integrieren, ohne umfangreiche Infrastrukturinvestitionen zu benötigen.
Ganz gleich, ob Sie Bildungsanwendungen entwickeln, wissenschaftliche Forschung betreiben oder komplexe Softwaresysteme erstellen, Magistral Small 1.2 und Magistral Medium 1.2 bieten die Argumentationsfähigkeiten, die für KI-Anwendungen der nächsten Generation erforderlich sind. In Kombination mit robusten Test- und Integrationstools wie Apidog ermöglichen diese Modelle umfassende Entwicklungs-Workflows, die Innovationen beschleunigen und gleichzeitig Qualitätsstandards aufrechterhalten.