
In der sich rasch entwickelnden Landschaft der großen Sprachmodelle sticht NVIDIA's Llama Nemotron Ultra 253B als Kraftpaket für Unternehmen hervor, die fortschrittliche Denkfähigkeiten suchen. Dieser umfassende Leitfaden untersucht die beeindruckenden Benchmarks des Modells, vergleicht es mit anderen führenden Open-Source-Modellen und bietet klare Schritte zur Implementierung seiner API in Ihren Anwendungen.
llama-3.1-nemotron-ultra-253b Benchmark
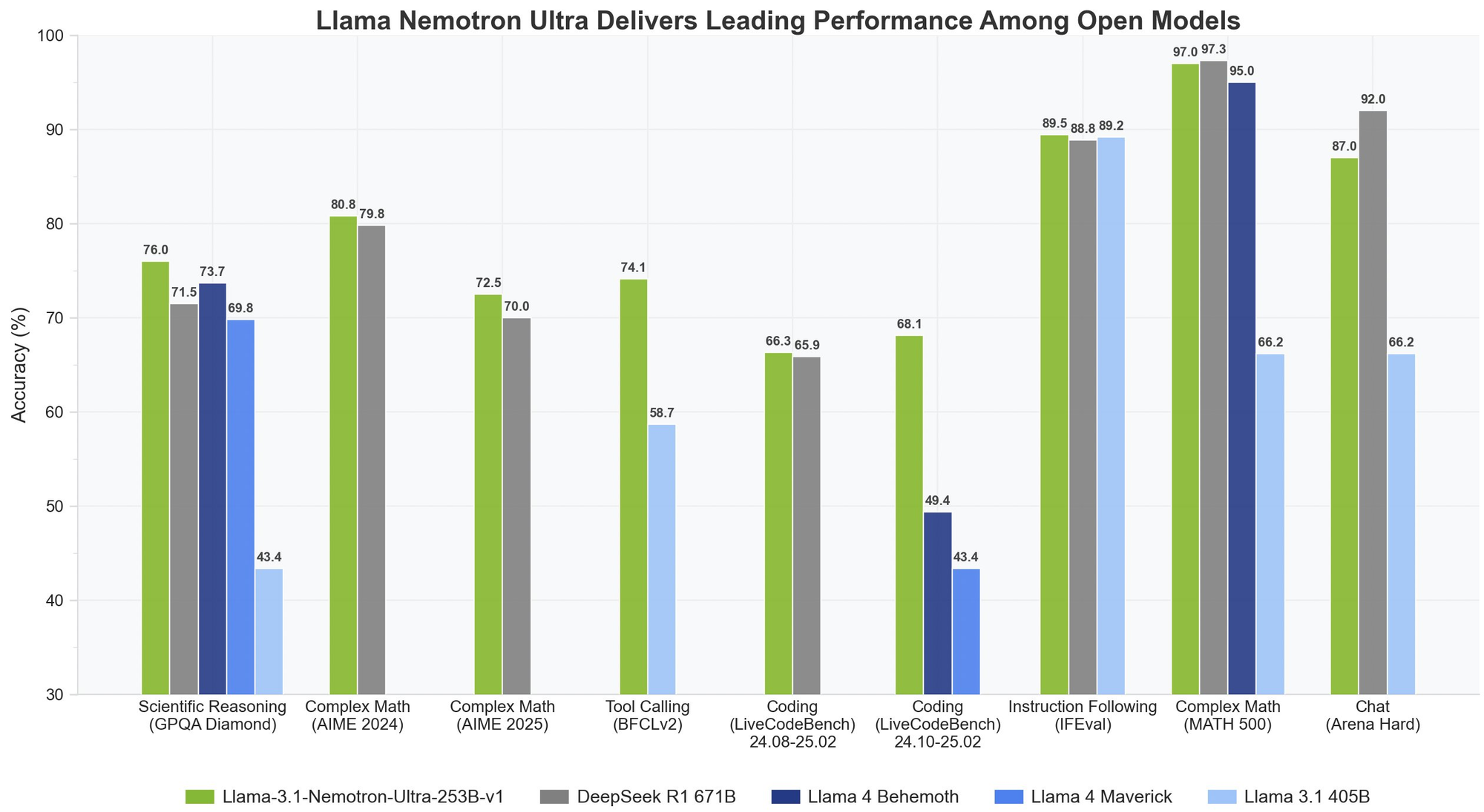
Der Llama Nemotron Ultra 253B liefert außergewöhnliche Ergebnisse in kritischen Denk- und Agenten-Benchmarks, wobei seine einzigartige "Reasoning ON/OFF"-Fähigkeit dramatische Leistungsunterschiede zeigt:
Mathematisches Denken
Der Llama Nemotron Ultra 253B glänzt wirklich bei mathematischen Denkaufgaben:
- MATH500
- Reasoning OFF: 80.4% pass@1
- Reasoning ON: 97.0% pass@1
Mit 97% Genauigkeit mit Reasoning ON perfektioniert der Llama Nemotron Ultra 253B fast diesen anspruchsvollen mathematischen Benchmark.
- AIME25 (American Invitational Mathematics Examination)
- Reasoning OFF: 16.7% pass@1
- Reasoning ON: 72.50% pass@1
Diese bemerkenswerte Verbesserung um 56 Punkte zeigt, wie die Denkfähigkeiten des Llama Nemotron Ultra 253B seine Leistung bei komplexen Mathematikproblemen verändern.
Wissenschaftliches Denken
- GPQA (Graduate-level Physics Questions and Answers)
- Reasoning OFF: 56.6% pass@1
- Reasoning ON: 76.01% pass@1
Die signifikante Verbesserung zeigt, wie der Llama Nemotron Ultra 253B durch methodische Analyse, wenn das Denken aktiviert ist, Probleme auf Hochschulniveau in der Physik angehen kann.
Programmierung und Werkzeugnutzung
- LiveCodeBench (20240801-20250201)
- Reasoning OFF: 29.03% pass@1
- Reasoning ON: 66.31% pass@1
Der Llama Nemotron Ultra 253B verdoppelt seine Programmierleistung mit aktiviertem Denken mehr als.
- BFCL V2 Live (Function Calling)
- Reasoning OFF: 73.62 score
- Reasoning ON: 74.10 score
Dieser Benchmark demonstriert die starken Werkzeugnutzungsfähigkeiten des Modells in beiden Modi, was für den Aufbau effektiver KI-Agenten entscheidend ist.
Befolgen von Anweisungen
- IFEval (Instruction Following Evaluation)
- Reasoning OFF: 88.85% strict accuracy
- Reasoning ON: 89.45% strict accuracy
Beide Modi funktionieren hervorragend und zeigen, dass der Llama Nemotron Ultra 253B unabhängig vom Denkmodus starke Fähigkeiten zur Befolgung von Anweisungen beibehält.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1 war der Goldstandard für Open-Source-Denkmodelle, aber Llama Nemotron Ultra 253B erreicht oder übertrifft seine Leistung bei wichtigen Denkbenchmarks:
- Auf GPQA erreicht Llama Nemotron Ultra 253B 76,01% Genauigkeit und konkurriert mit der erstklassigen Leistung von DeepSeek-R1
- Der Llama Nemotron Ultra 253B bietet duale Denkmodi, im Gegensatz zum festen Denkansatz von DeepSeek-R1
- Llama Nemotron Ultra 253B bietet überlegene Funktionsaufruffähigkeiten, was ihn vielseitiger für Agentenanwendungen macht
Llama Nemotron Ultra 253B vs. Llama 4
Im Vergleich zu den kommenden Llama 4 Behemoth- und Maverick-Modellen:
- Llama Nemotron Ultra 253B zeigt überlegene Leistung bei wissenschaftlichen und komplexen mathematischen Denkbenchmarks
- Der explizite Denkschalter in Llama Nemotron Ultra 253B bietet mehr Flexibilität als Standard-Llama-4-Modelle
- Llama Nemotron Ultra 253B ist speziell für NVIDIA-Hardware optimiert und bietet eine bessere Inferenz-Effizienz
Testen wir Llama Nemotron Ultra 253B über die API
Die Implementierung des Llama Nemotron Ultra 253B in Ihren Anwendungen erfordert die Befolgung bestimmter Schritte, um eine optimale Leistung zu gewährleisten:
Schritt 1: API-Zugriff erhalten
Um auf den Llama Nemotron Ultra 253B zuzugreifen:
- Besuchen Sie das NVIDIA API-Portal unter https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Registrieren Sie sich für einen API-Schlüssel, falls Sie noch keinen haben
- Wenn Sie in der NGC-Umgebung von NVIDIA arbeiten, kann die API-Schlüsselkonfiguration vereinfacht werden
Schritt 2: Richten Sie Ihre Entwicklungsumgebung ein
Bevor Sie API-Aufrufe tätigen:
- Installieren Sie das OpenAI Python-Paket mit
pip install openai - Importieren Sie die erforderliche Bibliothek:
from openai import OpenAI - Konfigurieren Sie Ihre Umgebung, um den API-Schlüssel sicher zu speichern
Schritt 3: Konfigurieren Sie den API-Client
Initialisieren Sie den OpenAI-Client mit den NVIDIA-Endpunkten:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- Im Gegensatz zu Postman bietet Apidog eine stärker integrierte Erfahrung mit integrierter API-Dokumentation, automatisierten Tests und Mock-Servern, die speziell für KI-Modell-Endpunkte optimiert sind.
- Die intuitive Benutzeroberfläche von Apidog erleichtert die Konfiguration der komplexen Parametersätze, die für API-Tests benötigt werden, und seine Antwortvisualisierungsfunktionen sind besonders hilfreich für die Analyse der Streaming-Ausgaben des Modells.
- Während Postman ein beliebtes allgemeines API-Testtool bleibt, können die KI-fokussierten Funktionen und der optimierte Workflow von Apidog Ihren Entwicklungsprozess erheblich beschleunigen.

Schritt 4: Bestimmen Sie den geeigneten Denkmodus
Der Llama Nemotron Ultra 253B bietet zwei verschiedene Betriebsmodi:
- Reasoning ON: Am besten für komplexe Probleme, die schrittweises Denken erfordern (Mathematik, Physik, Programmierung)
- Reasoning OFF: Optimal für das direkte Befolgen von Anweisungen und allgemeines Chatten
Schritt 5: Erstellen Sie Ihre System- und Benutzeraufforderungen
Für den Reasoning ON-Modus:
- Setzen Sie die Systemaufforderung auf
"detailed thinking on" - Platzieren Sie alle Anweisungen in der Benutzernachricht
- Erwägen Sie die Verwendung spezifischer Vorlagen für Benchmarked-Aufgaben (wie Mathematikprobleme)
Für den Reasoning OFF-Modus:
- Entfernen Sie die Denk-Systemaufforderung
- Verwenden Sie präzise, klare Anweisungen in der Benutzernachricht
Schritt 6: Generierungsparameter konfigurieren
Für optimale Ergebnisse:
- Reasoning ON: Stellen Sie temperature=0.6 und top_p=0.95 ein, wie von NVIDIA empfohlen
- Reasoning OFF: Verwenden Sie Greedy-Decodierung mit temperature=0
- Legen Sie geeignete
max_tokensbasierend auf der erwarteten Antwortlänge fest - Erwägen Sie die Aktivierung von Streaming für Echtzeitantworten
Schritt 7: Stellen Sie die API-Anfrage und verarbeiten Sie Antworten
Erstellen Sie Ihre Completion-Anfrage mit allen konfigurierten Parametern:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Schritt 8: Verarbeiten und Anzeigen der Antwort
Bei Verwendung von Streaming:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Für Nicht-Streaming-Antworten greifen Sie einfach auf completion.choices[0].message.content zu.
Fazit
Der Llama Nemotron Ultra 253B stellt einen bedeutenden Fortschritt in Open-Source-Denkmodellen dar und liefert erstklassige Leistung über eine Vielzahl von Benchmarks hinweg. Seine einzigartigen dualen Denkmodi, kombiniert mit außergewöhnlichen Funktionsaufruffähigkeiten und einem riesigen Kontextfenster, machen ihn zu einer idealen Wahl für Unternehmens-KI-Anwendungen, die fortschrittliche Denkfähigkeiten erfordern.
Mit dem in diesem Artikel beschriebenen Schritt-für-Schritt-API-Implementierungsleitfaden können Entwickler das volle Potenzial von Llama Nemotron Ultra 253B nutzen, um anspruchsvolle KI-Systeme zu erstellen, die komplexe Probleme mit menschenähnlichem Denken angehen. Ob beim Aufbau von KI-Agenten, der Verbesserung von RAG-Systemen oder der Entwicklung spezialisierter Anwendungen, der Llama Nemotron Ultra 253B bietet eine leistungsstarke Grundlage für KI-Fähigkeiten der nächsten Generation in einem kommerziell freundlichen Open-Source-Paket.


