
Die Landschaft der künstlichen Intelligenz wurde mit Metas Veröffentlichung von Llama 4 grundlegend verändert – nicht nur durch inkrementelle Verbesserungen, sondern durch architektonische Durchbrüche, die die Leistungs-Kosten-Verhältnisse in der gesamten Branche neu definieren. Diese neuen Modelle repräsentieren die Konvergenz von drei entscheidenden Innovationen: native Multimodalität durch frühe Fusionstechniken, Sparse-Mixture-of-Experts (MoE)-Architekturen, die die Parametereffizienz radikal verbessern, und Kontextfenstererweiterungen, die sich auf beispiellose 10 Millionen Tokens erstrecken.
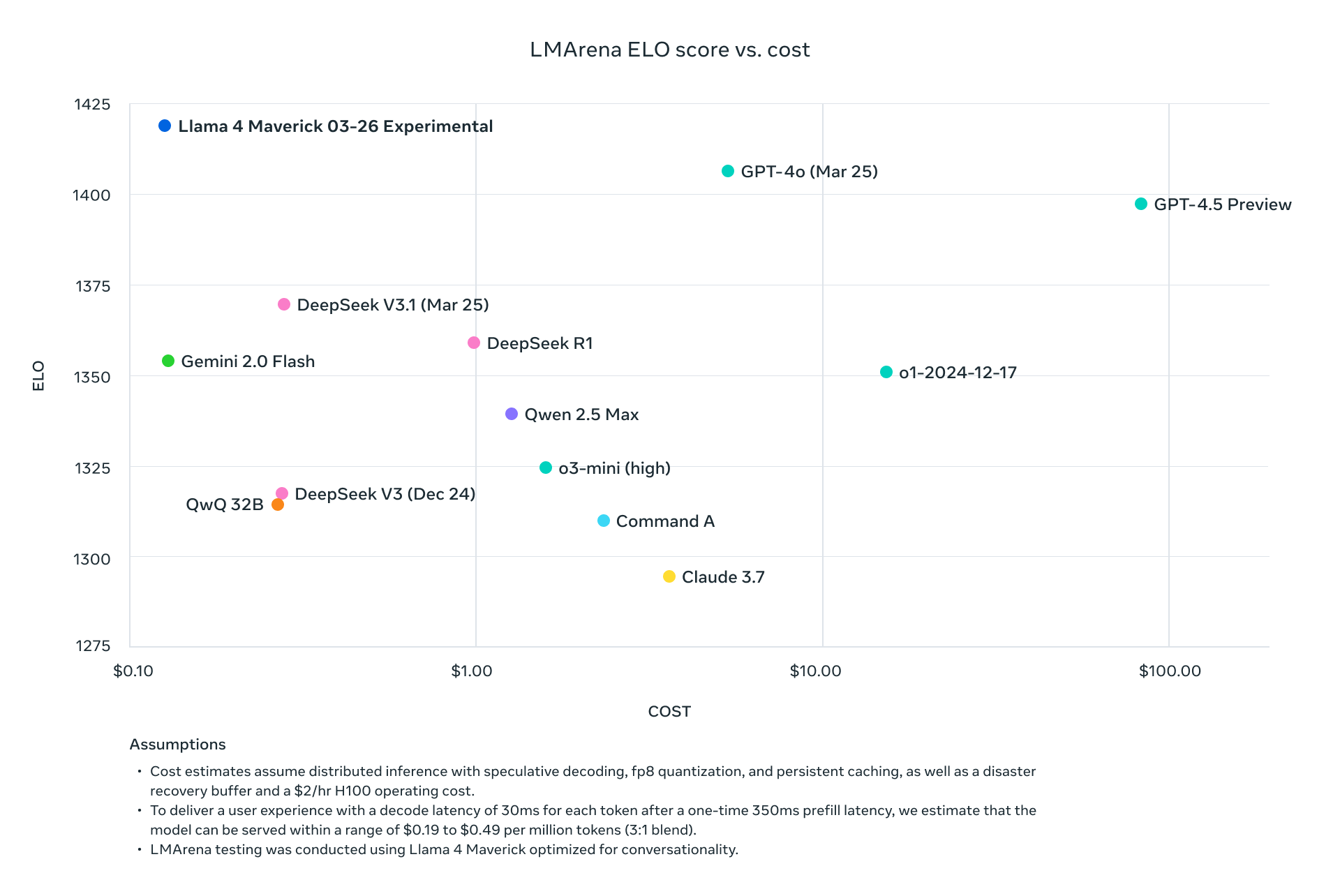
Llama 4 Scout und Maverick konkurrieren nicht nur mit den aktuellen Branchenführern – sie übertreffen diese systematisch über Standard-Benchmarks hinweg und reduzieren gleichzeitig den Rechenaufwand drastisch. Mit Maverick, der bei etwa einem Neuntel der Kosten pro Token bessere Ergebnisse erzielt als GPT-4o, und Scout, der auf einer einzigen H100-GPU Platz findet und gleichzeitig eine höhere Leistung als Modelle erzielt, die mehrere GPUs benötigen, hat Meta die Wirtschaftlichkeit des fortschrittlichen KI-Einsatzes grundlegend verändert.
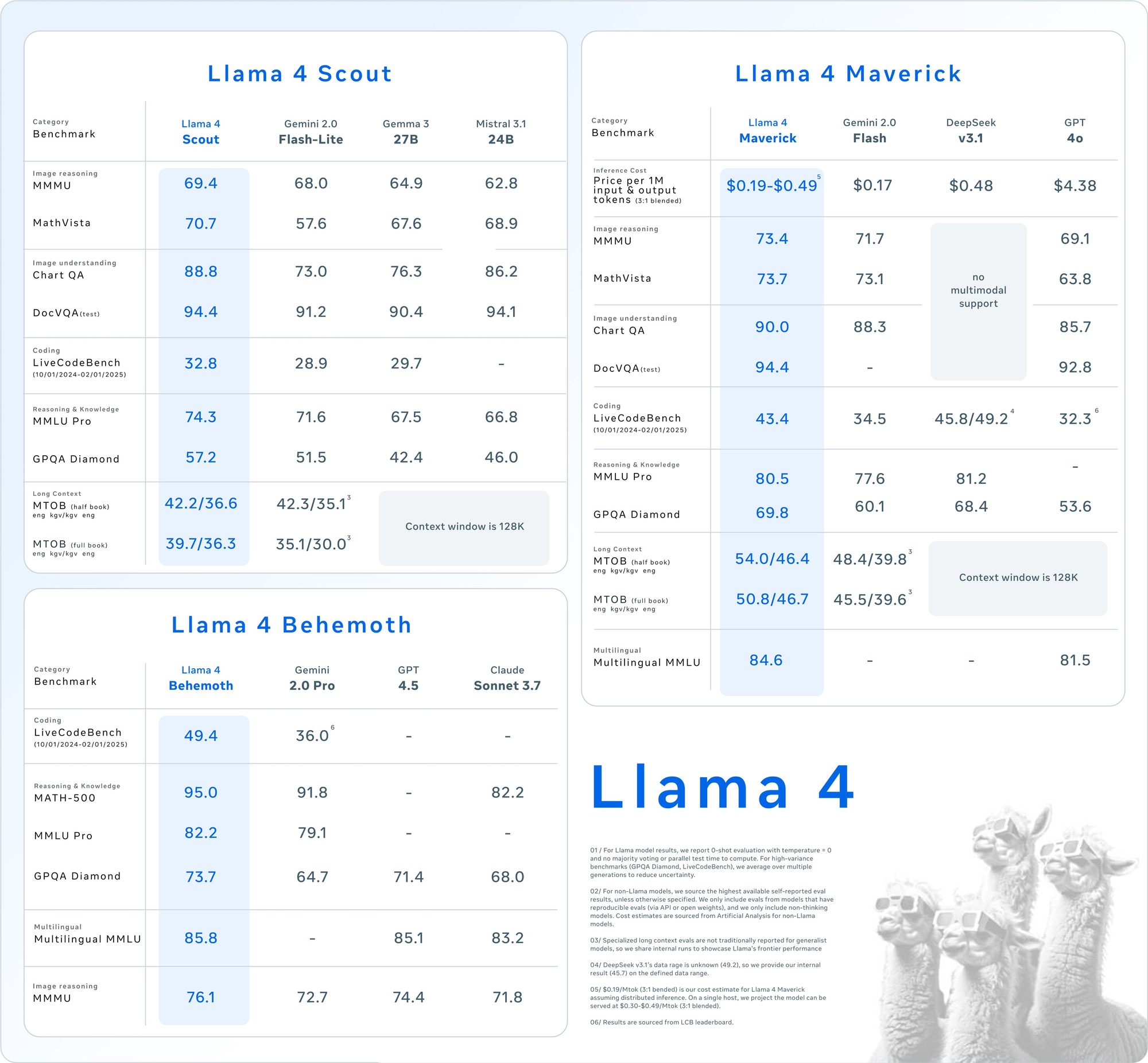
Diese technische Analyse seziert die architektonischen Innovationen, die diese Modelle antreiben, präsentiert umfassende Benchmark-Daten für Aufgaben in den Bereichen Reasoning, Coding, Multilingual und Multimodal und untersucht die API-Preisstrukturen der wichtigsten Anbieter. Für technische Entscheidungsträger, die KI-Infrastrukturoptionen evaluieren, bieten wir detaillierte Leistungs-/Kostenvergleiche und Bereitstellungsstrategien, um die Effizienz dieser bahnbrechenden Modelle in Produktionsumgebungen zu maximieren.
Sie können Meta Llama 4 Open Source und Open Weight ab heute auf Hugging Face herunterladen:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Wie Llama 4 ein 10M-Kontextfenster archiviert hat?
Mixture-of-Experts (MoE)-Implementierung
Alle Llama 4-Modelle verwenden eine ausgeklügelte MoE-Architektur, die die Effizienzgleichung grundlegend verändert:
| Model | Active Parameters | Expert Count | Total Parameters | Parameter Activation Method |
|---|---|---|---|---|
| Llama 4 Scout | 17B | 16 | 109B | Token-specific routing |
| Llama 4 Maverick | 17B | 128 | 400B | Shared + single routed expert per token |
| Llama 4 Behemoth | 288B | 16 | ~2T | Token-specific routing |
Das MoE-Design in Llama 4 Maverick ist besonders ausgeklügelt und verwendet abwechselnd dichte und MoE-Schichten. Jeder Token aktiviert den gemeinsamen Experten plus einen von 128 gerouteten Experten, was bedeutet, dass nur etwa 17B von 400B Gesamtparametern für die Verarbeitung eines bestimmten Tokens aktiv sind.
Multimodale Architektur
Llama 4 Multimodale Architektur:
├── Text Tokens
│ └── Native text processing pathway
├── Vision Encoder (Enhanced MetaCLIP)
│ ├── Image processing
│ └── Converts images to token sequences
└── Early Fusion Layer
└── Unifies text and vision tokens in model backbone
Dieser Early-Fusion-Ansatz ermöglicht das Vortraining auf über 30 Billionen Tokens gemischter Text-, Bild- und Videodaten, was zu deutlich kohärenteren multimodalen Fähigkeiten führt als Retrofit-Ansätze.
iRoPE-Architektur für erweiterte Kontextfenster
Das 10M-Token-Kontextfenster von Llama 4 Scout nutzt die innovative iRoPE-Architektur:
# Pseudocode for iRoPE architecture
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Even layers: Interleaved attention without positional embeddings
return attention_no_positional(tokens)
else:
# Odd layers: RoPE (Rotary Position Embeddings)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# Temperature scaling during inference improves length generalization
return scale_attention_scores(tokens, temperature_factor)
Diese Architektur ermöglicht es Scout, Dokumente von beispielloser Länge zu verarbeiten und gleichzeitig die Kohärenz beizubehalten, mit einem Skalierungsfaktor, der etwa 80-mal größer ist als die Kontextfenster der vorherigen Llama-Modelle.
Umfassende Benchmark-Analyse
Standard-Benchmark-Leistungsmetriken
Detaillierte Benchmark-Ergebnisse über wichtige Evaluierungssuiten hinweg zeigen die Wettbewerbspositionierung der Llama 4-Modelle:
| Category | Benchmark | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Image Reasoning | MMMU | 73.4 | 69.1 | 71.7 | No multimodal support |
| MathVista | 73.7 | 63.8 | 73.1 | No multimodal support | |
| Image Understanding | ChartQA | 90.0 | 85.7 | 88.3 | No multimodal support |
| DocVQA (test) | 94.4 | 92.8 | - | No multimodal support | |
| Coding | LiveCodeBench | 43.4 | 32.3 | 34.5 |


