
Die Landschaft der künstlichen Intelligenz verändert sich ständig, wobei Large Language Models (LLMs) immer ausgefeilter werden und in unser digitales Leben integriert werden. Während Cloud-basierte KI-Dienste Komfort bieten, wendet sich eine wachsende Anzahl von Benutzern dem Ausführen dieser leistungsstarken Modelle direkt auf ihren eigenen Computern zu. Dieser Ansatz bietet verbesserten Datenschutz, Kosteneinsparungen und mehr Kontrolle. Diesen Wandel erleichtert Ollama, ein revolutionäres Tool, das entwickelt wurde, um den komplexen Prozess des Herunterladens, Konfigurierens und Betreibens modernster LLMs wie Llama 3, Mistral, Gemma, Phi und viele andere lokal drastisch zu vereinfachen.
Dieser umfassende Leitfaden dient als Ausgangspunkt für die Beherrschung von Ollama. Wir werden von den ersten Installationsschritten und grundlegenden Modellinteraktionen zu fortgeschritteneren Anpassungstechniken, API-Nutzung und wesentlichen Fehlerbehebungen übergehen. Egal, ob Sie ein Softwareentwickler sind, der lokale KI in Ihre Anwendungen einbinden möchte, ein Forscher, der mit verschiedenen Modellarchitekturen experimentieren möchte, oder einfach ein KI-Enthusiast, der das Potenzial des Ausführens leistungsstarker Modelle offline erkunden möchte, Ollama bietet ein außergewöhnlich optimiertes und effizientes Gateway.
Want an integrated, All-in-One platform for your Developer Team to work together with maximum productivity?
Apidog delivers all your demands, and replaces Postman at a much more affordable price!
Warum Ollama wählen, um KI-Modelle lokal auszuführen?
Warum sollten Sie sich für diesen Ansatz entscheiden, anstatt sich ausschließlich auf die verfügbaren Cloud-APIs zu verlassen? Nun, hier sind die Gründe:
The beauty of having small but smart models like Gemma 2 9B is that it allows you to build all sorts of fun stuff locally.
— Pietro Schirano (@skirano) July 12, 2024
Like this script that uses @ollama to fix typos or improve any text on my Mac just by pressing dedicated keys.
A local Grammarly but super fast. ⚡️ pic.twitter.com/lv15CRmUMv
- Ollama bietet Ihnen die beste Privatsphäre und Sicherheit für das lokale Ausführen von LLMs, Sie haben die volle Kontrolle: Wenn Sie ein LLM mit Ollama auf Ihrem Rechner ausführen, bleiben alle Daten – Ihre Eingabeaufforderungen, die von Ihnen bereitgestellten Dokumente und der vom Modell generierte Text – auf Ihrem lokalen System. Es verlässt niemals Ihre Hardware. Dies gewährleistet ein Höchstmaß an Privatsphäre und Datenkontrolle, ein entscheidender Faktor im Umgang mit sensiblen persönlichen Daten, vertraulichen Geschäftsdaten oder proprietärer Forschung.
- Es ist einfach günstiger, mit lokalen LLMs zu arbeiten: Cloud-basierte LLM-APIs arbeiten oft mit Pay-per-Use-Modellen oder erfordern laufende Abonnementgebühren. Diese Kosten können sich schnell summieren, insbesondere bei intensiver Nutzung. Ollama eliminiert diese wiederkehrenden Ausgaben. Abgesehen von der Anfangsinvestition in geeignete Hardware (die Sie möglicherweise bereits besitzen), ist das lokale Ausführen von Modellen effektiv kostenlos, was unbegrenzte Experimente und Generierung ohne die drohende Sorge um API-Rechnungen ermöglicht.
- Mit Ollama können Sie LLM offline ausführen, ohne sich auf kommerzielle APIs verlassen zu müssen: Sobald ein Ollama-Modell auf Ihren lokalen Speicher heruntergeladen wurde, können Sie es jederzeit und überall verwenden, unabhängig von einer Internetverbindung. Dieser Offline-Zugriff ist von unschätzbarem Wert für Entwickler, die in Umgebungen mit eingeschränkter Konnektivität arbeiten, für Forscher im Feld oder für alle, die unterwegs einen zuverlässigen KI-Zugang benötigen.
- Mit Ollama können Sie angepasste LLMs ausführen: Ollama zeichnet sich durch sein leistungsstarkes
Modelfile-System aus. Dies ermöglicht es Benutzern, das Modellverhalten einfach zu ändern, indem sie Parameter (wie Kreativitätsstufen oder Ausgabelänge) anpassen, benutzerdefinierte Systemaufforderungen definieren, um die Persona der KI zu gestalten, oder sogar spezialisierte, fein abgestimmte Adapter (LoRAs) integrieren. Sie können auch Modellgewichte direkt aus Standardformaten wie GGUF oder Safetensors importieren. Dieses detaillierte Maß an Kontrolle und Flexibilität wird von Closed-Source-Cloud-API-Anbietern selten angeboten. - Mit Ollama können Sie LLM auf Ihrem eigenen Server ausführen: Abhängig von Ihrer lokalen Hardwarekonfiguration, insbesondere dem Vorhandensein einer leistungsfähigen Grafikverarbeitungseinheit (GPU), kann Ollama im Vergleich zu Cloud-Diensten, die möglicherweise von Netzwerk-Latenz, Ratenbegrenzung oder variabler Auslastung gemeinsamer Ressourcen betroffen sind, deutlich schnellere Reaktionszeiten (Inferenzgeschwindigkeit) liefern. Die Nutzung Ihrer dedizierten Hardware kann zu einer viel reibungsloseren und interaktiveren Erfahrung führen.
- Ollama ist Open Source: Ollama selbst ist ein Open-Source-Projekt, das Transparenz und Community-Beiträge fördert. Darüber hinaus dient es in erster Linie als Gateway zu einer riesigen und schnell wachsenden Bibliothek frei zugänglicher LLMs. Durch die Verwendung von Ollama werden Sie Teil dieses dynamischen Ökosystems und profitieren von gemeinsamem Wissen, Community-Unterstützung und der ständigen Innovation, die durch offene Zusammenarbeit vorangetrieben wird.
Ollamas wichtigste Leistung ist die Maskierung der inhärenten Komplexität, die mit der Einrichtung der erforderlichen Softwareumgebungen, der Verwaltung von Abhängigkeiten und der Konfiguration der komplizierten Einstellungen verbunden ist, die für die Ausführung dieser hochentwickelten KI-Modelle erforderlich sind. Es verwendet geschickt hochoptimierte Backend-Inferenz-Engines, insbesondere die renommierte llama.cpp-Bibliothek, um eine effiziente Ausführung auf Standard-Consumer-Hardware zu gewährleisten und sowohl CPU- als auch GPU-Beschleunigung zu unterstützen.
Ollama vs. Llama.cpp: Was sind die Unterschiede?
Es ist nützlich, die Beziehung zwischen Ollama und llama.cpp zu verdeutlichen, da sie eng miteinander verbunden sind, aber unterschiedlichen Zwecken dienen.
llama.cpp: Dies ist die grundlegende, hochleistungsfähige C/C++-Bibliothek, die für die Kernaufgabe der LLM-Inferenz verantwortlich ist. Sie verarbeitet das Laden von Modellgewichten, die Verarbeitung von Eingabe-Tokens und die effiziente Generierung von Ausgabe-Tokens mit Optimierungen für verschiedene Hardwarearchitekturen (CPU-Befehlssätze wie AVX, GPU-Beschleunigung über CUDA, Metal, ROCm). Es ist der leistungsstarke Motor, der die Rechenarbeit leistet.
Ollama: Dies ist eine umfassende Anwendung, die um llama.cpp (und möglicherweise andere zukünftige Backends) herum aufgebaut ist. Ollama bietet eine benutzerfreundliche Ebene darüber und bietet:
- Eine einfache Befehlszeilenschnittstelle (CLI) für eine einfache Interaktion (
ollama run,ollama pullusw.). - Einen integrierten REST-API-Server für die programmatische Integration.
- Optimiertes Modellmanagement (Herunterladen aus einer Bibliothek, lokaler Speicher, Updates).
- Das
Modelfile-System zur Anpassung und Erstellung von Modellvarianten. - Plattformübergreifende Installer (macOS, Windows, Linux) und Docker-Images.
- Automatische Hardwareerkennung und -konfiguration (CPU/GPU).
Im Wesentlichen könnten Sie zwar technisch gesehen llama.cpp direkt verwenden, indem Sie es kompilieren und seine Befehlszeilentools ausführen, dies erfordert jedoch einen deutlich höheren technischen Aufwand in Bezug auf Einrichtung, Modellkonvertierung und Parameterverwaltung. Ollama verpackt diese Leistung in eine zugängliche, benutzerfreundliche Anwendung, wodurch lokale LLMs für ein viel breiteres Publikum, insbesondere für Anfänger, praktikabel werden. Stellen Sie sich llama.cpp als die Hochleistungskomponenten des Motors und Ollama als das vollständig montierte, benutzerfreundliche Fahrzeug vor, das fahrbereit ist.
So installieren Sie Ollama auf Mac, Windows, Linux
Ollama ist auf Barrierefreiheit ausgelegt und bietet unkomplizierte Installationsverfahren für macOS-, Windows-, Linux- und Docker-Umgebungen.
Allgemeine Systemanforderungen für Ollama:
RAM (Arbeitsspeicher): Dies ist oft der kritischste Faktor.
- Mindestens 8 GB: Ausreichend für kleinere Modelle (z. B. 1B, 3B, 7B Parameter), obwohl die Leistung möglicherweise langsam ist.
- Empfohlen 16 GB: Ein guter Ausgangspunkt für das komfortable Ausführen von 7B- und 13B-Modellen.
- Ideal 32 GB oder mehr: Erforderlich für größere Modelle (30B, 40B, 70B+) und ermöglicht größere Kontextfenster. Mehr RAM führt im Allgemeinen zu einer besseren Leistung und der Fähigkeit, größere, leistungsfähigere Modelle auszuführen.
Festplattenspeicher: Die Ollama-Anwendung selbst ist relativ klein (ein paar hundert MB). Die von Ihnen heruntergeladenen LLMs benötigen jedoch erheblichen Speicherplatz. Die Modellgrößen variieren stark:
- Kleine quantisierte Modelle (z. B. ~3B Q4): ~2 GB
- Mittlere quantisierte Modelle (z. B. 7B/8B Q4): 4-5 GB
- Große quantisierte Modelle (z. B. 70B Q4): ~40 GB
- Sehr große Modelle (z. B. 405B): Über 200 GB!
Stellen Sie sicher, dass Sie über ausreichend freien Speicherplatz auf dem Laufwerk verfügen, auf dem Ollama Modelle speichert (siehe Abschnitt unten).
Betriebssystem:
- macOS: Version 11 Big Sur oder neuer. Apple Silicon (M1/M2/M3/M4) wird für die GPU-Beschleunigung empfohlen.
- Windows: Windows 10 Version 22H2 oder neuer oder Windows 11. Sowohl Home- als auch Pro-Editionen werden unterstützt.
- Linux: Eine moderne Distribution (z. B. Ubuntu 20.04+, Fedora 38+, Debian 11+). Kernel-Anforderungen können gelten, insbesondere für die Unterstützung von AMD-GPUs.
Installieren von Ollama auf macOS
- Herunterladen: Laden Sie die Ollama macOS-Anwendungs-DMG-Datei direkt von der offiziellen Ollama-Website herunter.
- Mounten: Doppelklicken Sie auf die heruntergeladene
.dmg-Datei, um sie zu öffnen. - Installieren: Ziehen Sie das Symbol
Ollama.appin Ihren OrdnerApplications. - Starten: Öffnen Sie die Ollama-Anwendung aus Ihrem Ordner "Anwendungen". Möglicherweise müssen Sie ihr beim ersten Ausführen die Berechtigung erteilen.
- Hintergrunddienst: Ollama wird als Hintergrunddienst ausgeführt, der durch ein Symbol in Ihrer Menüleiste angezeigt wird. Durch Klicken auf dieses Symbol erhalten Sie Optionen zum Beenden der Anwendung oder zum Anzeigen von Protokollen.
Durch das Starten der Anwendung wird automatisch der Ollama-Serverprozess gestartet und das Befehlszeilentool ollama zum PATH Ihres Systems hinzugefügt, wodurch es sofort in der Terminalanwendung (Terminal.app, iTerm2 usw.) verfügbar ist. Auf Macs, die mit Apple Silicon (M1-, M2-, M3-, M4-Chips) ausgestattet sind, nutzt Ollama nahtlos die integrierte GPU für die Beschleunigung über Apples Metal-Grafik-API, ohne dass eine manuelle Konfiguration erforderlich ist.
Installieren von Ollama unter Windows
- Herunterladen: Laden Sie die Installationsdatei
OllamaSetup.exevon der Ollama-Website herunter. - Installer ausführen: Doppelklicken Sie auf die heruntergeladene
.exe-Datei, um den Setup-Assistenten zu starten. Stellen Sie sicher, dass Sie die Mindestanforderung für die Windows-Version (10 22H2+ oder 11) erfüllen. - Den Anweisungen folgen: Fahren Sie mit den Installationsschritten fort, akzeptieren Sie die Lizenzvereinbarung und wählen Sie den Installationsort, falls gewünscht (obwohl die Standardeinstellung normalerweise in Ordnung ist).
Das Installationsprogramm konfiguriert Ollama so, dass es automatisch als Hintergrunddienst ausgeführt wird, wenn Ihr System startet. Außerdem wird die ausführbare Datei ollama.exe zum PATH Ihres Systems hinzugefügt, sodass Sie den Befehl ollama in Standard-Windows-Terminals wie Eingabeaufforderung (cmd.exe), PowerShell oder dem neueren Windows Terminal verwenden können. Der Ollama-API-Server startet automatisch und lauscht auf http://localhost:11434.
Windows-GPU-Beschleunigung für Ollama:
- NVIDIA: Installieren Sie die neuesten GeForce Game Ready- oder NVIDIA Studio-Treiber von der NVIDIA-Website. Die Treiberversion 452.39 oder neuer ist erforderlich. Ollama sollte kompatible GPUs automatisch erkennen und verwenden.
- AMD: Installieren Sie die neuesten AMD Software: Adrenalin Edition-Treiber von der AMD-Support-Website. Kompatible Radeon-GPUs (typischerweise RX 6000-Serie und neuer) werden automatisch verwendet.
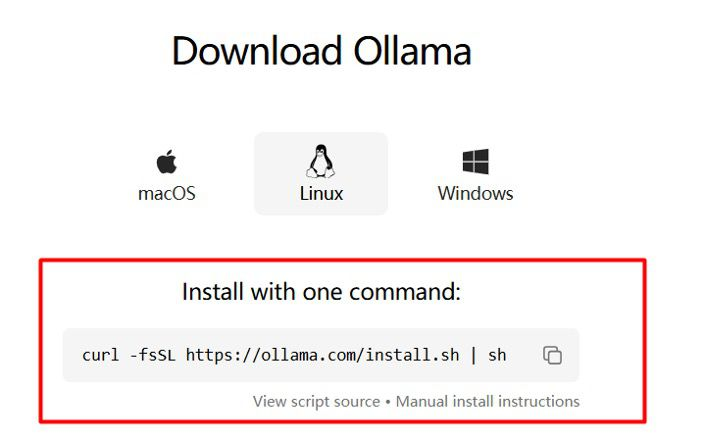
Installieren von Ollama unter Linux
Die bequemste Methode für die meisten Linux-Distributionen ist die Verwendung des offiziellen Installationsskripts:
curl -fsSL https://ollama.com/install.sh | sh
Dieser Befehl lädt das Skript herunter und führt es mit sh aus. Das Skript führt die folgenden Aktionen aus:
- Erkennt Ihre Systemarchitektur (x86_64, ARM64).
- Lädt die entsprechende Ollama-Binärdatei herunter.
- Installiert die Binärdatei unter
/usr/local/bin/ollama. - Überprüft auf erforderliche GPU-Treiber (NVIDIA CUDA, AMD ROCm) und installiert gegebenenfalls Abhängigkeiten (dieser Teil kann je nach Distribution variieren).
- Erstellt einen dedizierten
ollama-Systembenutzer und eine Gruppe. - Richtet eine Systemd-Dienstdatei (
/etc/systemd/system/ollama.service) zur Verwaltung des Ollama-Serverprozesses ein. - Aktiviert und startet den
ollama-Dienst, sodass er automatisch beim Booten und im Hintergrund ausgeführt wird.
Manuelle Linux-Installation & Systemd-Konfiguration für Ollama:
Wenn das Skript fehlschlägt oder wenn Sie die manuelle Steuerung bevorzugen (z. B. die Installation an einem anderen Ort, die unterschiedliche Verwaltung von Benutzern, die Sicherstellung bestimmter ROCm-Versionen), lesen Sie die detaillierte Linux-Installationsanleitung im Ollama-GitHub-Repository. Die allgemeinen Schritte umfassen:
- Herunterladen der richtigen Binärdatei für Ihre Architektur.
- Ausführen der Binärdatei (
chmod +x ollama) und Verschieben an einen Ort in Ihrem PATH (z. B./usr/local/bin). - (Empfohlen) Erstellen eines Systembenutzers/einer Systemgruppe:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollamaundsudo groupadd ollama, dannsudo usermod -a -G ollama ollama. Fügen Sie Ihren eigenen Benutzer zur Gruppe hinzu:sudo usermod -a -G ollama $USER. - Erstellen der Systemd-Dienstdatei (
/etc/systemd/system/ollama.service) mit den entsprechenden Einstellungen (Benutzer, Gruppe, Pfad der ausführbaren Datei, Umgebungsvariablen, falls erforderlich). Beispiel-Snippets werden normalerweise in der Dokumentation bereitgestellt. - Neuladen des Systemd-Daemons:
sudo systemctl daemon-reload. - Aktivieren des Dienstes zum Starten beim Booten:
sudo systemctl enable ollama. - Sofortiges Starten des Dienstes:
sudo systemctl start ollama. Sie können seinen Status mitsudo systemctl status ollamaüberprüfen.
Wesentliche Linux-GPU-Treiber für Ollama:
Für eine optimale Leistung wird die Installation von GPU-Treibern dringend empfohlen:
- NVIDIA: Installieren Sie die offiziellen proprietären NVIDIA-Treiber für Ihre Distribution (z. B. über den Paketmanager wie
aptoderdnfoder heruntergeladen von der NVIDIA-Website). Überprüfen Sie die Installation mit dem Befehlnvidia-smi. - AMD (ROCm): Installieren Sie das ROCm-Toolkit. AMD stellt offizielle Repositories und Installationsanleitungen für unterstützte Distributionen (wie Ubuntu, RHEL/CentOS, SLES) bereit. Stellen Sie sicher, dass Ihre Kernel-Version kompatibel ist. Das Ollama-Installationsskript kann einige ROCm-Abhängigkeiten verarbeiten, aber die manuelle Installation garantiert die korrekte Einrichtung. Überprüfen Sie mit
rocminfo.
So verwenden Sie Ollama mit Docker-Image
Docker bietet eine plattformunabhängige Möglichkeit, Ollama in einem isolierten Container auszuführen, wodurch die Abhängigkeitsverwaltung vereinfacht wird, insbesondere für komplexe GPU-Setups.
CPU-Only Ollama-Container:
docker run -d \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama \
ollama/ollama
-d: Führt den Container im getrennten (Hintergrund-)Modus aus.-v ollama_data:/root/.ollama: Erstellt ein benanntes Docker-Volume namensollama_dataauf Ihrem Host-System und ordnet es dem Verzeichnis/root/.ollamainnerhalb des Containers zu. Dies ist entscheidend für die Beibehaltung Ihrer heruntergeladenen Modelle. Wenn Sie dies weglassen, gehen Modelle verloren, wenn der Container entfernt wird. Sie können einen beliebigen Namen für das Volume wählen.-p 127.0.0.1:11434:11434: Ordnet Port 11434 auf der Loopback-Schnittstelle Ihres Host-Rechners (127.0.0.1) Port 11434 innerhalb des Containers zu. Verwenden Sie0.0.0.0:11434:11434, wenn Sie von anderen Rechnern in Ihrem Netzwerk auf den Ollama-Container zugreifen müssen.--name my_ollama: Weist dem laufenden Container einen benutzerdefinierten, einprägsamen Namen zu.ollama/ollama: Gibt das offizielle Ollama-Image von Docker Hub an.
NVIDIA GPU Ollama-Container:
- Stellen Sie zunächst sicher, dass das NVIDIA Container Toolkit ordnungsgemäß auf Ihrem Host-Rechner installiert ist und dass Docker für die Verwendung der NVIDIA-Laufzeit konfiguriert ist.
- Führen Sie den Container aus und fügen Sie das Flag
--gpus=allhinzu:
docker run -d \
--gpus=all \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama_gpu \
ollama/ollama
Dieses Flag gewährt dem Container Zugriff auf alle kompatiblen NVIDIA-GPUs, die vom Toolkit erkannt werden. Sie können bei Bedarf bestimmte GPUs angeben (z. B. --gpus '"device=0,1"').
AMD GPU (ROCm) Ollama-Container:
- Verwenden Sie das ROCm-spezifische Image-Tag:
ollama/ollama:rocm. - Ordnen Sie die erforderlichen ROCm-Geräteknoten vom Host in den Container ein:
docker run -d \
--device /dev/kfd \
--device /dev/dri \
-v ollama_data:/root/.ollama \
-p 127.0.0.1:11434:11434 \
--name my_ollama_rocm \
ollama/ollama:rocm
/dev/kfd: Die Kernel-Fusion-Treiber-Schnittstelle./dev/dri: Direct Rendering Infrastructure-Geräte (umfasst oft Renderknoten wie/dev/dri/renderD128).- Stellen Sie sicher, dass der Benutzer, der den Befehl
dockerauf dem Host ausführt, über die entsprechenden Berechtigungen für den Zugriff auf diese Gerätedateien verfügt (die Mitgliedschaft in Gruppen wierenderundvideokann erforderlich sein).
Sobald der Ollama-Container ausgeführt wird, können Sie mit dem Befehl docker exec interagieren, um ollama-CLI-Befehle innerhalb des Containers auszuführen:
docker exec -it my_ollama ollama list
docker exec -it my_ollama ollama pull llama3.2
docker exec -it my_ollama ollama run llama3.2
Wenn Sie den Port zugeordnet haben (-p), können Sie alternativ direkt von Ihrem Host-Rechner oder anderen Anwendungen mit der Ollama-API interagieren, die auf http://localhost:11434 (oder die IP/Port, die Sie zugeordnet haben) verweisen.
Wo speichert Ollama Modelle?

Zu wissen, wo Ollama seine heruntergeladenen Modelle speichert, ist für die Verwaltung des Festplattenspeichers und der Backups unerlässlich. Der Standardspeicherort variiert je nach Betriebssystem und Installationsmethode:
- Ollama unter macOS: Modelle befinden sich im Home-Verzeichnis Ihres Benutzers unter
~/.ollama/models. Das~steht für/Users/<IhrBenutzername>. - Ollama unter Windows: Modelle werden in Ihrem Benutzerprofilverzeichnis unter
C:\Users\<IhrBenutzername>\.ollama\modelsgespeichert. - Ollama unter Linux (Benutzerinstallation / Manuell): Ähnlich wie bei macOS werden Modelle typischerweise unter
~/.ollama/modelsgespeichert. - Ollama unter Linux (Systemd-Dienstinstallation): Bei der Installation über das Skript oder der Konfiguration als systemweiter Dienst, der als
ollama-Benutzer ausgeführt wird, werden Modelle oft unter/usr/share/ollama/.ollama/modelsgespeichert. Überprüfen Sie die Konfiguration oder Dokumentation des Dienstes, wenn Sie ein nicht standardmäßiges Setup verwendet haben. - Ollama über Docker: Innerhalb des Containers ist der Pfad
/root/.ollama/models. Wenn Sie jedoch das Flag-vkorrekt verwendet haben, um ein Docker-Volume zu mounten (z. B.-v ollama_data:/root/.ollama), werden die eigentlichen Modelldateien innerhalb des verwalteten Volume-Bereichs von Docker auf Ihrem Host-Rechner gespeichert. Der genaue Speicherort von Docker-Volumes hängt von Ihrem Docker-Setup ab, aber sie sind so konzipiert, dass sie unabhängig vom Container bestehen bleiben.
Sie können den Speicherort des Modells mit der Umgebungsvariablen OLLAMA_MODELS umleiten, die wir im Konfigurationsabschnitt behandeln werden. Dies ist nützlich, wenn Ihr primäres Laufwerk nur wenig Speicherplatz hat und Sie große Modelle auf einem sekundären Laufwerk speichern möchten.
Ihre ersten Schritte mit Ollama: Ausführen eines LLM
Nachdem Ollama installiert ist und der Server aktiv ist (über die Desktop-App, den Systemd-Dienst oder den Docker-Container ausgeführt wird), können Sie mithilfe des unkomplizierten ollama-Befehls in Ihrem Terminal mit LLMs interagieren.
Herunterladen von Ollama-Modellen: Der pull-Befehl
Bevor Sie ein bestimmtes LLM ausführen, müssen Sie zuerst seine Gewichte und Konfigurationsdateien herunterladen. Ollama bietet eine kuratierte Bibliothek beliebter offener Modelle, auf die über den Befehl ollama pull leicht zugegriffen werden kann. Sie können die verfügbaren Modelle auf der Bibliotheksseite der Ollama-Website durchsuchen.
# Beispiel 1: Das neueste Llama 3.2 8B Instruct-Modell abrufen
# Dies wird oft als 'latest' oder einfach nach dem Basisnamen getaggt.
ollama pull llama3.2
# Beispiel 2: Eine bestimmte Version von Mistral abrufen (7 Milliarden Parameter, Basismodell)
ollama pull mistral:7b
# Beispiel 3: Das Gemma 3 4B-Modell von Google abrufen
ollama pull gemma3
# Beispiel 4: Das kleinere Phi-4 Mini-Modell von Microsoft abrufen (effizient)
ollama pull phi4-mini
# Beispiel 5: Ein Vision-Modell abrufen (kann Bilder verarbeiten)
ollama pull llava
Hier ist der Link für Ollama library, wo Sie alle verfügbaren und trendigen Ollama-Modelle durchsuchen können:
Verständnis der Ollama-Modell-Tags:
Modelle in der Ollama-Bibliothek verwenden eine model_family_name:tag-Namenskonvention. Das Tag gibt Variationen an wie:
- Größe:
1b,3b,7b,8b,13b,34b,70b,405b(Angabe von Milliarden von Parametern). Größere Modelle haben im Allgemeinen mehr Wissen, benötigen aber auch mehr Ressourcen. - Quantisierung:
q2_K,q3_K_S,q4_0,q4_K_M,q5_1,q5_K_M,q6_K,q8_0,f16(float16),f32(float32). Die Quantisierung reduziert die Modellgröße und den Rechenbedarf, oft mit einem geringen Kompromiss bei der Präzision. Kleinere Zahlen (z. B.q4) bedeuten mehr Komprimierung.K-Varianten (_K_S,_K_M,_K_L) gelten im Allgemeinen als gute Ausgewogenheit von Größe und Qualität.f16/f32sind unquantisiert oder minimal komprimiert und bieten die höchste Wiedergabetreue, erfordern aber die meisten Ressourcen. - Variante:
instruct(für das Befolgen von Anweisungen optimiert),chat(für Konversationen optimiert),code(für Programmieraufgaben optimiert),vision(multimodal, verarbeitet Bilder),uncensored(weniger Sicherheitsfilterung, verantwortungsvoll verwenden). latest: Wenn Sie ein Tag weglassen (z. B.ollama pull llama3.2), verwendet Ollama standardmäßig das Taglatest, das normalerweise auf eine häufig verwendete, gut ausbalancierte Version (oft ein mittelgroßes, quantisiertes, instruct-abgestimmtes Modell) verweist.
Der Befehl pull lädt die erforderlichen Dateien (die mehrere Gigabyte groß sein können) in Ihr festgelegtes Ollama-Modellverzeichnis herunter. Sie müssen nur einmal eine bestimmte Modell:Tag-Kombination abrufen. Ollama kann Modelle auch aktualisieren; Wenn Sie pull erneut für ein vorhandenes Modell ausführen, werden nur die geänderten Ebenen (Diffs) heruntergeladen, wodurch Updates effizient werden.
So chatten Sie lokal mit LLMs mit dem Ollama run-Befehl
Der direkteste Weg, sich mit einem heruntergeladenen Modell zu unterhalten, ist die Verwendung des Befehls ollama run:
ollama run llama3.2
Wenn das angegebene Modell (in diesem Fall llama3.2:latest) noch nicht heruntergeladen wurde, löst ollama run praktischerweise zuerst ollama pull aus. Sobald das Modell bereit ist und in den Speicher geladen wurde (was einige Sekunden dauern kann, insbesondere bei größeren Modellen), wird Ihnen eine interaktive Eingabeaufforderung angezeigt:
>>> Nachricht senden (/? für Hilfe)
Jetzt können Sie einfach Ihre Frage oder Anweisung eingeben, die Eingabetaste drücken und darauf warten, dass die KI eine Antwort generiert. Die Ausgabe wird typischerweise Token für Token gestreamt und bietet ein reaktionsschnelles Gefühl.
>>> Erklären Sie das Konzept der Quantenverschränkung in einfachen Worten.
Okay, stellen Sie sich vor, Sie haben zwei spezielle Münzen, die auf magische Weise miteinander verbunden sind. Nennen wir sie Münze A und Münze B. Bevor Sie sie betrachten, ist keine der Münzen Kopf oder Zahl – sie befinden sich in einer unscharfen Mischung aus beiden Möglichkeiten.
Nun geben Sie Münze A einem Freund und reisen mit Münze B Lichtjahre weit weg. In dem Moment, in dem Sie Ihre Münze B betrachten und sehen, dass sie, sagen

