Metas Llama 4 Modelle, nämlich Llama 4 Maverick und Llama 4 Scout, stellen einen Sprung nach vorn in der multimodalen KI-Technologie dar. Veröffentlicht am 5. April 2025, nutzen diese Modelle eine Mixture-of-Experts (MoE)-Architektur, die eine effiziente Verarbeitung von Text und Bildern mit bemerkenswerten Leistungs-Kosten-Verhältnissen ermöglicht. Entwickler können diese Fähigkeiten über APIs nutzen, die von verschiedenen Plattformen bereitgestellt werden, wodurch die Integration in Anwendungen nahtlos und leistungsstark wird.
Verständnis von Llama 4 Maverick und Llama 4 Scout
Bevor Sie in die API-Nutzung eintauchen, erfassen Sie die Kernspezifikationen dieser Modelle. Llama 4 führt native Multimodalität ein, was bedeutet, dass es Text und Bilder von Grund auf zusammen verarbeitet. Darüber hinaus aktiviert sein MoE-Design nur eine Teilmenge von Parametern pro Aufgabe, was die Effizienz steigert.
Llama 4 Scout: Das effiziente multimodale Arbeitstier
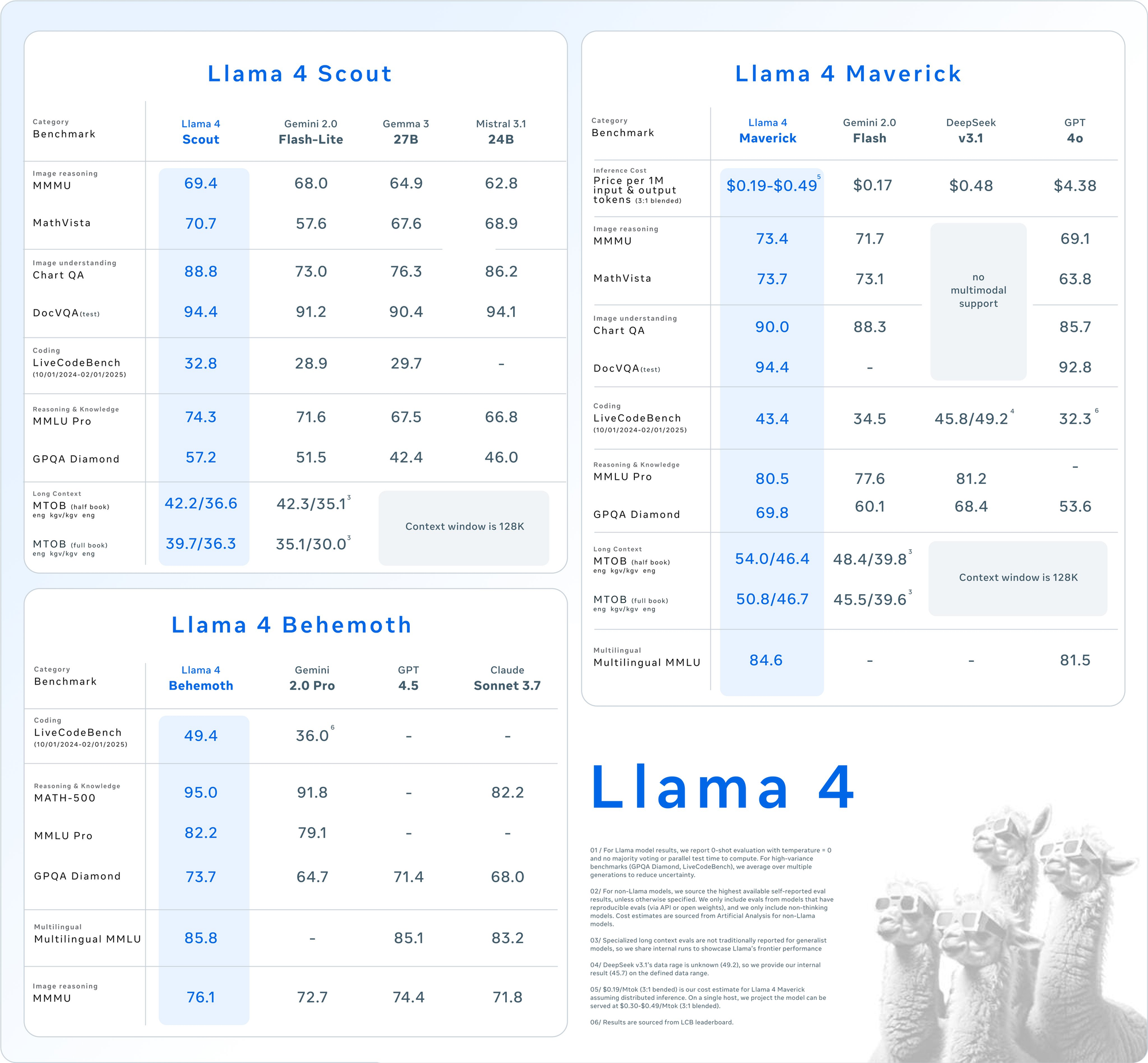
- Parameter: 17 Milliarden aktiv, 109 Milliarden gesamt, 16 Experten.
- Context Window: Bis zu 10 Millionen Tokens.
- Key Features: Übertrifft sich bei Aufgaben mit langem Kontext wie Multi-Dokument-Zusammenfassungen und der Argumentation über große Codebasen. Es passt auf eine einzelne NVIDIA H100 GPU mit INT4-Quantisierung.
- Use Case: Ideal für Entwickler, die eine schnelle, ressourceneffiziente multimodale Verarbeitung benötigen.
Llama 4 Maverick: Das vielseitige Kraftwerk
- Parameter: 17 Milliarden aktiv, 400 Milliarden gesamt, 128 Experten.
- Context Window: Bis zu 1 Million Tokens.
- Key Features: Bietet hochwertiges Text- und Bildverständnis und unterstützt 12 Sprachen (z. B. Englisch, Spanisch, Hindi). Es ist für Chat und kreatives Schreiben optimiert.
- Use Case: Geeignet für Assistenten auf Unternehmensebene und mehrsprachige Anwendungen.
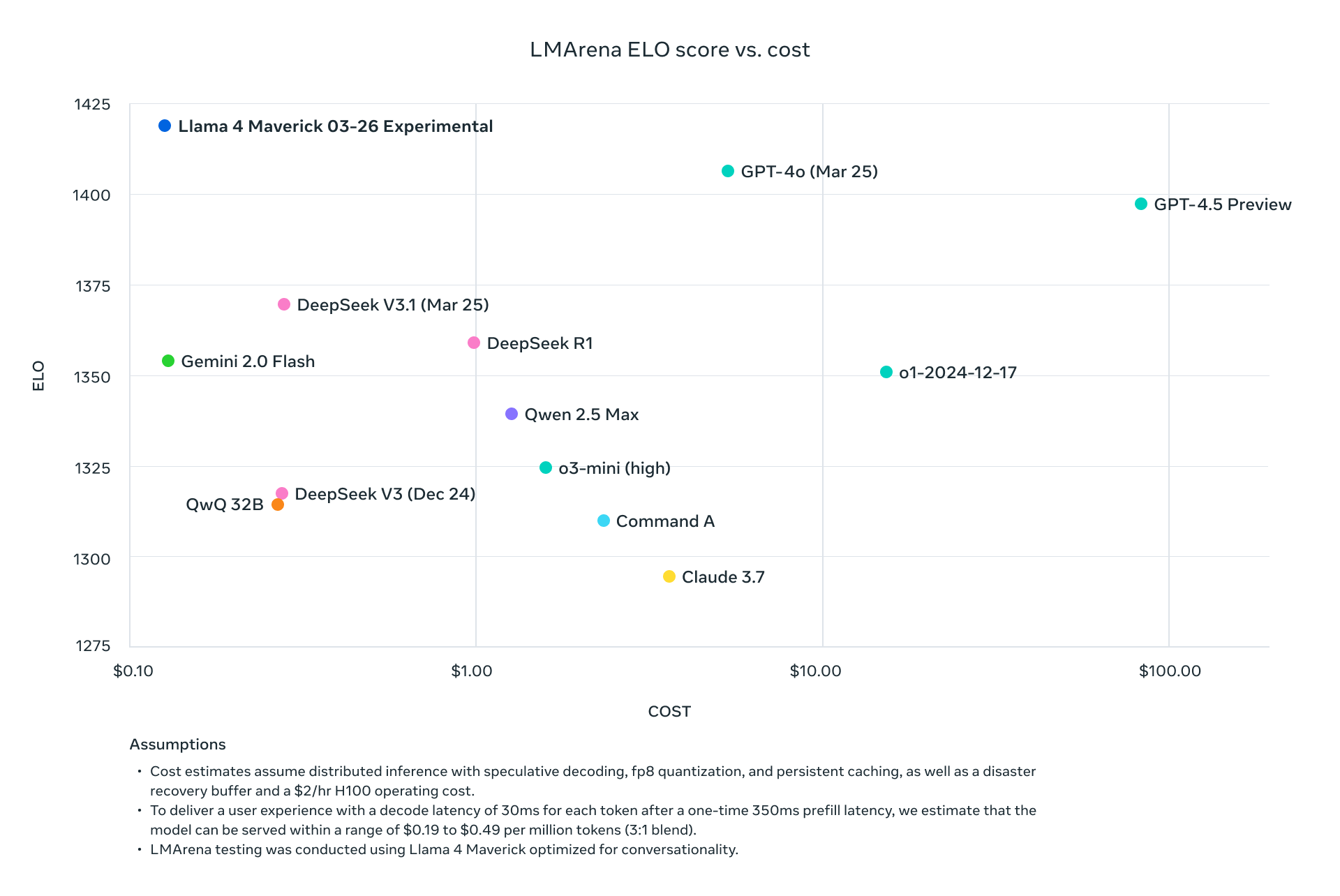
Beide Modelle übertreffen Vorgänger wie Llama 3 und konkurrieren mit Branchenriesen wie GPT-4o, was sie zu überzeugenden Optionen für API-gesteuerte Projekte macht.
Warum die Llama 4 API verwenden?
Die Integration von Llama 4 über API macht es überflüssig, diese massiven Modelle lokal zu hosten, was oft erhebliche Hardware erfordert (z. B. NVIDIA H100 DGX für Maverick). Stattdessen bieten Plattformen wie Groq, Together AI und OpenRouter verwaltete APIs an, die Folgendes bieten:
- Skalierbarkeit: Bewältigen Sie unterschiedliche Lasten ohne Infrastrukturaufwand.
- Kosteneffizienz: Zahlen Sie pro Token, mit Tarifen ab 0,11 $/M Eingabe-Tokens (Scout auf Groq).
- Benutzerfreundlichkeit: Greifen Sie mit einfachen HTTP-Anfragen auf multimodale Funktionen zu.
Als Nächstes richten wir Ihre Umgebung ein, um diese APIs aufzurufen.
Einrichten Ihrer Umgebung für Llama 4 API-Aufrufe
Um über API mit Llama 4 Maverick und Llama 4 Scout zu interagieren, bereiten Sie Ihre Entwicklungsumgebung vor. Befolgen Sie diese Schritte:
Schritt 1: Wählen Sie einen API-Anbieter
Mehrere Plattformen hosten Llama 4 APIs. Hier sind beliebte Optionen:
- Groq: Bietet kostengünstige Inferenz (Scout: 0,11 $/M Eingabe, Maverick: 0,50 $/M Eingabe).
- Together AI: Bietet dedizierte Endpunkte mit benutzerdefinierter Skalierung.
- OpenRouter: Kostenlose Stufe verfügbar, ideal zum Testen.
- Cloudflare Workers AI: Serverlose Bereitstellung mit Scout-Unterstützung.
Für diesen Leitfaden verwenden wir Groq und Together AI als Beispiele, da sie über eine robuste Dokumentation und Leistung verfügen.
Schritt 2: API-Schlüssel abrufen
- Groq: Melden Sie sich unter groq.com an, navigieren Sie zur Developer Console und generieren Sie einen API-Schlüssel.
- Together AI: Registrieren Sie sich unter together.ai und greifen Sie dann über das Dashboard auf Ihren API-Schlüssel zu.
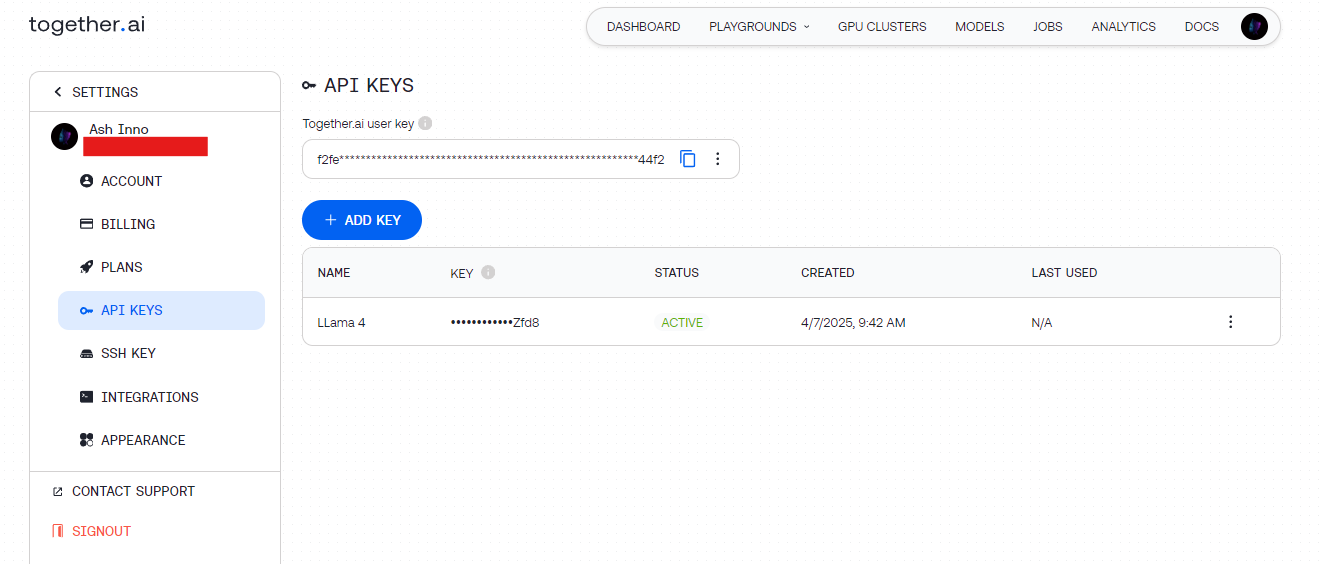
Speichern Sie diese Schlüssel sicher (z. B. in Umgebungsvariablen), um zu vermeiden, dass sie fest codiert werden.
Schritt 3: Abhängigkeiten installieren
Verwenden Sie Python zur Vereinfachung. Installieren Sie die erforderlichen Bibliotheken:
pip install requests
Zum Testen ergänzt Apidog dieses Setup, indem es Ihnen ermöglicht, API-Endpunkte visuell zu debuggen.
Ihren ersten Llama 4 API-Aufruf tätigen
Wenn Ihre Umgebung bereit ist, senden Sie eine Anfrage an die Llama 4 API. Beginnen wir mit einem einfachen Textgenerierungsbeispiel.
Beispiel 1: Texterstellung mit Llama 4 Scout (Groq)
import requests
import os
# Set API key
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Define payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Write a short poem about AI."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Ein kurzes Gedicht, das von Scout generiert wurde und seine effiziente MoE-Architektur nutzt.
Beispiel 2: Multimodaler Input mit Llama 4 Maverick (Together AI)
Maverick glänzt bei multimodalen Aufgaben. So beschreiben Sie ein Bild:
import requests
import os
# Set API key
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Define payload with image and text
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Describe this image."
}
]
}
],
"max_tokens": 200
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Eine detaillierte Beschreibung des Bildes, die die Bild-Text-Ausrichtung von Maverick zeigt.
Optimieren von API-Anfragen für die Leistung
Um die Effizienz zu maximieren, optimieren Sie Ihre Llama 4 API-Aufrufe. Berücksichtigen Sie diese Techniken:
Kontextlänge anpassen
- Scout: Verwenden Sie das 10M-Token-Fenster für lange Dokumente. Setzen Sie
max_model_len(falls unterstützt), um große Eingaben zu verarbeiten. - Maverick: Begrenzen Sie sich auf 1M Tokens für Chat-Anwendungen, um Geschwindigkeit und Qualität auszugleichen.
Parameter optimieren
- Temperatur: Niedriger (z. B. 0,5) für faktische Antworten, höher (z. B. 1,0) für Kreativität.
- Max Tokens: Begrenzen Sie die Ausgabelänge, um unnötige Berechnungen zu vermeiden.
Stapelverarbeitung
Senden Sie mehrere Prompts in einer Anfrage (wenn die API dies unterstützt), um die Latenz zu reduzieren. Überprüfen Sie die Anbieterdokumente auf Batch-Endpunkte.
Erweiterte Anwendungsfälle mit der Llama 4 API
Erkunden Sie nun erweiterte Integrationen, um das volle Potenzial von Llama 4 auszuschöpfen.
Anwendungsfall 1: Mehrsprachiger Chatbot
Maverick unterstützt 12 Sprachen. Erstellen Sie einen Kundensupport-Bot:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Eine spanische Antwort, die die mehrsprachige Sprachkompetenz von Maverick nutzt.
Anwendungsfall 2: Dokumentenzusammenfassung mit Scout
Das 10M-Token-Fenster von Scout zeichnet sich durch die Zusammenfassung großer Texte aus:
long_text = "..." # Insert a lengthy document here
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Summarize this: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Eine prägnante Zusammenfassung, die von Scout effizient verarbeitet wird.
Debugging und Testen mit Apidog
Das Testen von APIs kann knifflig sein, insbesondere bei multimodalen Eingaben. Hier glänzt Apidog:
- Visuelle Oberfläche: Erstellen und senden Sie Anfragen ohne Programmierung.
- Fehlerverfolgung: Identifizieren Sie Probleme wie Ratenbegrenzungen oder fehlerhafte Payloads.
- Mock-Antworten: Simulieren Sie Llama 4-Ausgaben für die Frontend-Entwicklung.
So testen Sie die obigen Beispiele in Apidog:
- Öffnen Sie Apidog und erstellen Sie eine neue Anfrage.
- Legen Sie die URL fest (z. B.
https://api.groq.com/v1/chat/completions).

- Fügen Sie Header hinzu (
Authorization,Content-Type).
- Fügen Sie die JSON-Payload ein.

- Senden und überprüfen Sie die Antwort.

Dieser Workflow stellt sicher, dass Ihre Llama 4 API-Integration reibungslos abläuft.
Vergleich von API-Anbietern für Llama 4
Die Wahl des richtigen Anbieters wirkt sich auf Kosten und Leistung aus. Hier ist eine Aufschlüsselung:
| Anbieter | Modellunterstützung | Preise (Eingabe/Ausgabe pro M) | Kontextlimit | Hinweise |
|---|---|---|---|---|
| Groq | Scout, Maverick | 0,11 $/0,34 $ (Scout), 0,50 $/0,77 $ (Maverick) | 128K (erweiterbar) | Niedrigste Kosten, hohe Geschwindigkeit |
| Together AI | Scout, Maverick | Benutzerdefiniert (dedizierte Endpunkte) | 1M (Maverick) | Skalierbar, auf Unternehmen ausgerichtet |
| OpenRouter | Beide | Kostenlose Stufe verfügbar | 128K | Ideal zum Testen |
| Cloudflare | Scout | Nutzungsbasiert | 131K | Serverlose Einfachheit |
Wählen Sie basierend auf der Größe und dem Budget Ihres Projekts aus. Beginnen Sie für das Prototyping mit der kostenlosen Stufe von OpenRouter und skalieren Sie dann mit Groq oder Together AI.
Best Practices für die Llama 4 API-Integration
Um eine robuste Integration zu gewährleisten, befolgen Sie diese Richtlinien:
- Ratenbegrenzung: Beachten Sie die Anbieterlimits (z. B. die 100 Anfragen/Minute von Groq). Implementieren Sie einen exponentiellen Backoff für Wiederholungen.
- Fehlerbehandlung: Erfassen Sie HTTP-Fehler (z. B. 429 Too Many Requests) und protokollieren Sie sie.
- Sicherheit: Verschlüsseln Sie API-Schlüssel und verwenden Sie HTTPS-Endpunkte.
- Überwachung: Verfolgen Sie die Token-Nutzung, um die Kosten zu verwalten, insbesondere bei den höheren Tarifen von Maverick.
Behebung häufiger API-Probleme
Treten Probleme auf? Beheben Sie sie schnell:
- 401 Unbefugt: Überprüfen Sie Ihren API-Schlüssel.
- 429 Ratenlimit überschritten: Reduzieren Sie die Anfragenhäufigkeit oder aktualisieren Sie Ihren Plan.
- Payload-Fehler: Stellen Sie sicher, dass das JSON-Format den Anbieterspezifikationen entspricht (z. B.
messages-Array).
Apidog hilft, diese Probleme visuell zu diagnostizieren und spart Zeit.
Fazit
Die Integration von Llama 4 Maverick und Llama 4 Scout über API ermöglicht es Entwicklern, hochmoderne Anwendungen mit minimalem Aufwand zu erstellen. Egal, ob Sie die Effizienz von Scout mit langem Kontext oder die mehrsprachige Kompetenz von Maverick benötigen, diese Modelle liefern erstklassige Leistung über zugängliche Endpunkte. Wenn Sie dieser Anleitung folgen, können Sie Ihre API-Aufrufe effektiv einrichten, optimieren und Fehler beheben.
Bereit, tiefer einzutauchen? Experimentieren Sie mit Anbietern wie Groq und Together AI und nutzen Sie Apidog, um Ihren Workflow zu verfeinern. Die Zukunft der multimodalen KI ist da – beginnen Sie noch heute mit dem Bau!